Android IO、序列化、dex加密
IO
原理:实际是调用系统内核的函数库,进行数据同步后,由内核将数据写入磁盘;
页
4K数据为一页,一页数据是IO操作的基本单位;
在空间局部性原理下,为了优化,如果数据量较大的情况下,可能会出现预占位4~16K的情况;实际还没写数据,只是提前先多开辟空间,减少了多次开辟空间的操作;
基础IO
FileInputSteam inputSteam/FileOutSteam outSteam:
并没有实现inputSteam.flush(), 实际每次调用inputSteam.write()都会同步写数据;
设置缓冲区:
java自己缓冲区默认大小为8K;
FileInputSteam inputSteam/FileOutSteam outSteam
BufferedOutputStream(outSteam) bos/BufferedIntputStream(inputSteam) bis:
在没有主动调用bosflush()时,每次调用bos.write(),而数据没写满缓存(8K),并不会将数据同步写入文件中;
只有写满缓存8K或者主动调用bos.flush()才会同步将数据写入文件;
对象序列化:
后面讲;
RandomAccessFile:
作用:断点续传、大数据分析;
属于基础流,每次write就会写数据;
提供了定位处理,可以移动起始位置和设置读取偏移量;
如seek(10):从第10位开始;
配合MappedByteBuffer:读写一体的缓冲区,用到了映射,读写大文件时理论速度比普通buffer快3倍;
缓存区:
由于基础IO的相关处理方案,每一次写入都会直接调用复制(比较频繁),将用户空间的数据复制到内核空间,性能不高;
所以有了缓冲区,在当前用户空间,将数据缓存起来,到达8k时一次性写入或读出;
IO模型:
读数据时:
阻塞IO:
在应用层调用内核函数后,如果内核没准备好数据,则应用层会阻塞,等内核准备好数据后,内核进行复制数据操作,处理完返回状态值;
非阻塞IO:
应用层隔断时间查询内核准备好数据没,不等待,查询到准备好时,内核进行复制数据操作,处理完返回状态值;
IO复用:
应用层找了个中间层,让中间人查询准备没,查询到准备好,通知应用层,内核进行复制数据操作,处理完返回状态值;
信号驱动IO:
应用层和内核层建立链接,内核准备好后,通知应用层,内核进行复制数据操作,处理完返回状态值;
异步IO:
应用层和内核层建立链接,内核准备好后,直接将数据进行复制,处理完返回状态值;
Okio:
专门针对网络使用的。是Okhttp内部的IO实现;
将普通的读/写IO的Buffer, 合并为一个双向链表,可以用来从头读,从尾部写;节省了两次开辟IO的Buffer;
序列化
什么是序列化?
- 目的是为了进行数据传输;计算机底层数据传输是二进制数据(010101)
- 序列化:将特定的数据对象(如User),转换为一组基本的二进制字节数据的实现(0101010);
- 反序列化:将基本的二进制字节数据转换为特定的数据对象的实现;
serialVersionUID
用来做版本管理;
当对象读写时,和当前版本不一样时(如增加减少字段),会报错;
建议自己写一个版本号;也可以不写,不写时会自动生成;
trasient瞬态变量
被trasient修饰的变量不参与序列化;
整个对象序列化后,再反序列化后,读取被trasient修饰的变量值是null;
实现序列化的对象Person有一个User变量(没有用trasient),构造中传入一个未实现序列化的对象User,会报错;
子类实现序列化,父类不实现序列化,会有问题吗?
- 子类需要提供无参构造方法;不提供会报错;因为java在反序列化时,会走无参的newInstances();
- 反序列化后,不实现序列化的父类中的变量为null或默认值0、false等;子类中的变量有值;
- 若想有值,需要定义实现两个固定的方法;反射会用到
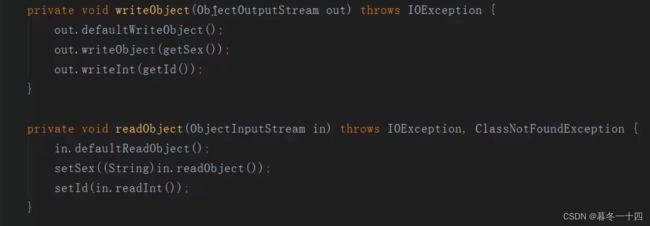
父类实现序列化,子类不实现序列化,会有问题吗?
没有;子类在继承父类时,将序列化权限也继承了;
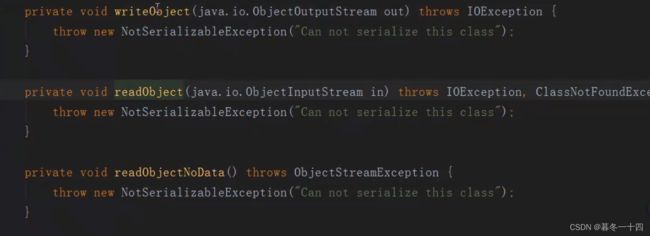
若不想子类实现序列化,需重新一下任意一个方法:
Dex
App打包流程:
java->.class->.dex->Apk;
- 把R.java、自己写的.java、aidl生成的接口文件使用javac编译为一个个的class文件
- 把一个个的class文件使用dx工具编译为一个个的dex文件
- 再将一个个的dex文件,打包为一个dex文件
- 再将dex文件、AndroidMnifist.xml、其他三方jar、so使用aapt打包为apk
- 再将APK使用签名工具进行签名得到新的可以上架的apk;
加密本质:
按照固定的逻辑算法将文件的二进制数据进行重新打乱排序;
解密时,按照规定的逻辑反向恢复原有的二进制数据;
加壳思路:
- 将Application放在其他model中(不放在主app,如:fix_module),Application放解密代码
- 打包工程生成apk;
- 将打包的apk解压;
- 分别对将解压后的classes.dex、classes2.dex、classes3.dex等等的dex中的byte数据进行加密;
- 将加密后的classes.dex、classes2.dex、classes3.dex重命名为classes_sign.dex、classes2_sign.dex、classes3_sign.dex...;
- 将fix_module生成的aar使用Dx工具转换为dex,命名为classes.dex;注意这个classes.dex没加密,之前的classes.dex已加密并且重命名为classes_sign.dex;
- 创建一个文件夹newApkFile;
- 将classes.dex和加密的classes_sign.dex、classes2_sign.dex、classes3_sign.dex...和原APK中的lib、AndroidMinist.xml等资源放入到newApkFile中;
- 将newApkFile压缩为apk文件:newApkFile.apk
- 将newApkFile.apk使用签名工具签名得到能够上架的apk;

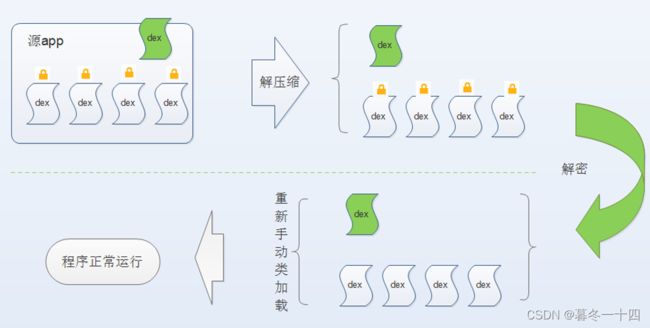
脱壳思路:
- 程序运行时只会自动加载主包dex:classes.dex; 分包classes_sign.dex都不会被自动加载;
- 注意Application是在classes.dex中的,且没有被加密
- App进程启动时,从主包classes.dex中查找并创建Application;
- 在attachBaseContext中解压安装的apk文件;
- 将带_sign.dex后缀的dex进行解密;
- 将解密完的每个dex,使用dexClassLoad进行手动加载;
- 脱壳完成
注意:其中加密算法,最好用c、c++写,打包成so库;因为我们的Application所在的包是没有被加密的,容易被破解;