有头双向循环链表(详解)
有头双向循环链表
- 有头双向循环链表介绍和定义
- 初始化
- 创建节点
- 遍历
- 头插
- 尾插
- 头删
- 尾删
- 查找
- 任意位置删除
- 任意位置插入、
有头双向循环链表介绍和定义
有头:头结点存储的是垃圾数据,头结点的下一个节点,存储的是有效数据。
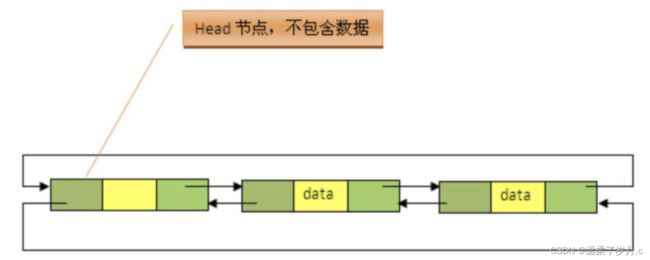
因为这个链表是双向,所以在这个链表中,会再定义两个指针,
一个是指向链表当前节点的前一个指针,
一个是指向链表当前节点的后一个指针
typedef int ListType;
struct DSqListNode
{
ListType date;
struct DSqListNode* pre;
struct DSqListNode* next;
};
typedef struct DSqListNode DSqList;
初始化
这里的话,多了一个初始化
因为有头节点的话,要存储一个垃圾数据,所以要先对其初始化
因为是循环链表,
初始化时,next指针和pre指针都指向头结点
DSqList* init()
{
DSqList* phead = creatNode(999);
phead->next = phead;
phead->pre = phead;
return phead;
}
创建节点
跟无头单向非循环链表的,创建方式基本一样
就多了一个指向链表当前节点的指针
用malloc开辟空间,创建节点,
next和pre指针都置为空
DSqList* creatNode(ListType date)
{
DSqList* node = (DSqList*)malloc(sizeof(ListType));
node->date = date;
node->next = NULL;
node->pre = NULL;
}
遍历
遍历链表的方式也很简单,找到遍历时,循环结束的时候就行
因为是循环链表,
当这个链表节点的下一个节点是头节点的时候,链表遍历结束
当然也要判断,头结点的下一个节点是否为空的情况,
’如果头结点的下一个节点为空的话,那么就退出这个函数
void printDate(DSqList* phead)
{
assert(phead);
assert(NULL != phead->next);
printf("头的垃圾数据为:%d 链表中的数据为:", phead->date);
DSqList* cur = phead->next;
while (phead != cur)
{
printf("%d ", cur->date);
cur = cur->next;
}
printf("\n");
}
头插
插入操作,也很简单,注意这里的头插,指的是在有效数据前面进行头擦,有头链表的头结点为无效数据,所以头插插入的位置是在头结点的下一个节点
1 .首先,创建一个节点
然后头结点的下一个节点指向这个节点
这个新节点指向头结点
新节点指向原来头结点的下一个节点
原来头结点的下一个节点指向新节点
注意:这里也有两种写法
区别是:
一种写法记录了头结点的下一个节点的位置
一种写法是,没有记录头节点下一个节点的位置
没有记录头节点下一个节点的位置的话,就要特别注意节点连接的顺序
记录了头结点的下一个节点,可以不必管连接顺序
这里,我个人建议,选择记录头节点的下一个节点的写法
记录了头结点的下一个节点的位置
void push_front1(DSqList* phead, ListType date)
{
DSqList* new = creatNode(date);
DSqList* first = phead->next;
//有了phead->next的地址,无需顺序
phead->next = new;
new->pre = phead;
new->next = first;
first->pre = new;
}
没有记录头节点下一个节点的顺序,
就要注意连接顺序,先连后面的节点,再连前面的节点
void push_front2(DSqList* phead, ListType date)
{
DSqList* new = creatNode(date);
//注意顺序,(先连后面的)
new->next = phead->next;
phead->next->pre = new;
phead->next = new;
new->pre = phead;
}
尾插
尾插的话,跟头插相似
先要找到尾节点
注意:
这里的话,尾结点的位置是已知的,
头节点的前一个节点是尾节点
然后创建新节点
尾结点的下一个节点是新节点
新节点的前一个节点是尾节点
新节点的下一个节点是头节点
头节点前一个节点是尾结点
void push_back(DSqList* phead, ListType date)
{
DSqList* tail = phead->pre;
DSqList* new = creatNode(date);
tail->next = new;
new->pre = tail;
new->next = phead;
phead->pre = new;
}
头删
头删的话,删除的同样是,第一个具有有效数据的节点以及头结点的下一个节点的位置
删之前,先记录头节点的下一个节点的下一个节点的位置
头节点指向原来头结点的下一个节点的下一个节点
原来头结点的下一个节点的下一个节点的前一个节点是头节点
void pop_front(DSqList* phead)
{
DSqList* first = phead->next;
DSqList* second = first->next;
phead->next = second;
second->pre = phead;
free(first);
first = NULL;
}
尾删
尾删的话,尾结点的位置已知,
尾结点的前一个节点就成为了新的尾节点
尾节点的下一个节点指向头节点
头结点的前一个节点指向尾节点的前一个节点
注意:
这里的判断条件,要能够尾删的话,链表里要有有效数据,这里是有头链表
1.头节点不为空
2.头节点的下一个节点不等于头节点
(如果等于,则表示头节点的下一个节点为空)
void pop_back(DSqList* phead)
{
assert(phead);
assert(phead != phead->next); //注意这个条件
DSqList* tail = phead->pre;
DSqList* tailPre = tail->pre;
tailPre->next = phead;
phead->pre = tailPre;
free(tail);
tail = NULL;
}
查找
查找功能的话,比较简单
就将链表依次遍历,找到这个数据,返回这它在链表中的地址不过,这里注意循环条件与单向非循环链表不一样
该节点的下一个节点,不是头节点
DSqList* find(DSqList* phead, ListType date)
{
assert(phead);
DSqList* cur = phead->next;
while(phead != cur)
{
if (date == cur->date)
{
return cur;
}
cur = cur->next;
}
}
void earse(DSqList* phead, DSqList * pos)
任意位置删除
通过find函数,找到该数据在链表的位置
任意位置删除的思路,其实跟尾删,差不多
这里需要注意的是,特殊情况的判断,
当然C语言中,用free删除数据
链表没有有效数据的情况
void earse(DSqList* phead, DSqList * pos)
{
assert(phead->next != NULL);
DSqList* second = pos->next;
DSqList* first = pos->pre;
first->next = second;
second->pre = first;
free(pos);
pos = NULL;
}
任意位置插入、
通过find函数,找到该数据在链表的位置
在这位置之后可以进行插入
任意位置插入的思路,其实跟头插,差不多
void insert(DSqList* phead, DSqList* pos, ListType date)
{
assert(phead);
DSqList* new = creatNode(date);
DSqList* first = pos->pre;
first->next = new;
new->pre = first;
new->next = pos;
pos->pre = new;
}