synchronized 的锁类型
之前的文章有讲过对同步锁的理解,实现同步锁的方式无非是多个线程抢占一个互斥变量,如果抢占成功则表示获得了锁,而没有获得锁的线程则阻塞等待,直到获得锁的线程释放锁
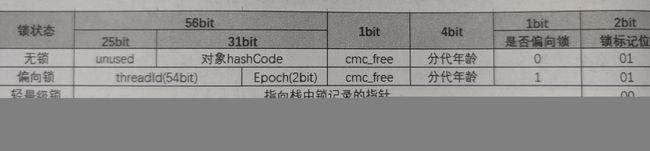
如图所示,在Mark Word中,我们发现锁的类型有偏向锁、轻量级锁、重量级锁,那么
其实,在JDK 1.6之前,synchronized只提供了重量级锁的机制,重量级锁的本质就是我们前面对于锁的认知,也就是没有获得锁的线程会通过park方法阻塞,接着被获得锁的线程唤醒后再次抢占锁,直到抢占成功。
重量级锁依赖于底层操作系统的Mutex Lock来实现,而使用Mutex Lock需要把当前线程挂起,并从用户态切换到内核态来执行,这种切换带来的性能开销是非常大的。因此,如何在性能和线程安全性之间做好平衡,就是一个值得探讨的话题了。
在JDK1.6之后,synchronized做了很多优化,其中针对锁的类型增加了偏向锁和轻量级锁,这两种锁的核心设计理念就是如何让线程在不阻塞的情况下达到线程安全的目的。
偏向锁的原理分析
偏向锁其实可以认为是在没有多线程竞争的情况下访问synchronized修饰的代码块的加锁场景,也就是在单线程执行的情况下。
很多读者可能会有疑问,没有线程竞争,那为什么要加锁呢?实际上对程序开发来说,加锁是为了防范线程安全性的风险,但是是否有线程竞争并不由我们来控制,而是由应用场景来决定。假设这种情况存在,就没有必要使用重量级锁基于操作系统级别的Mutex Lock来实现锁的抢占,这样显然很耗费性能。
所以偏向锁的作用就是,线程在没有线程竞争的情况下去访问synchronized 同步代码块时。会尝试先通过偏向锁来抢占访问资格,这个抢占过程是基于CAS来完成的,如果抢占锁成功,则直接修改对象头中的锁标记。其中,偏向锁标记为1,锁标记为01,以及存储当前获得锁的线程ID。而偏向的意是就是,如果线程X获得了偏向锁,那么当线程x后续再访问这个同步方法时,只需要判断对象头中的线程ID和线程X是否相等即可。如果相等,就不需要再次去抢占锁,直接获得访问资格即可,其实现原理如图所示,

结合前面关于对象头部分的说明及偏向锁的原理,我们通过一个例子来看一下偏向锁的实现。
public class BiasedLockExample {
public static void main(String[] args) {
BiasedLockExample example=new BiasedLockExample();
System.out.println("加锁之前");
System.out.println(ClassLayout.parseInstance(example).toPrintable());
synchronized (example){
System.out.println("加锁之后");
System,out.print1n(ClassLayout .parseInstance(example).toPrintable());
}
}
}在上述代码中,BiasedLockExample演示了针对example这个锁对象,在加锁之前和加锁之后分别打印对象的内存布局的过程,来看一下输出结果。

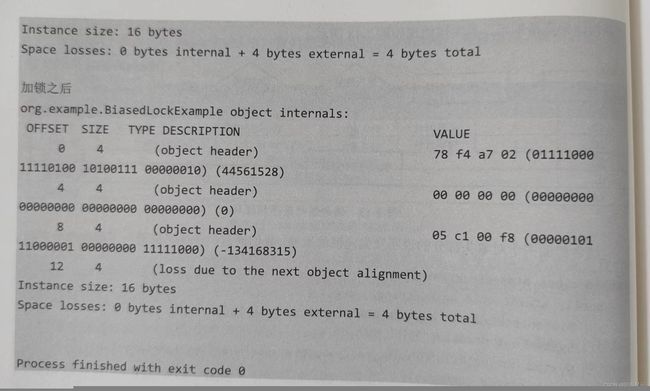
从上述输出结果中我们发现:
- 在加锁之前,对象头中的第一个字节00000001最后三位为[001],其中低位的两位表示锁标记,它的值是[01],表示当前为无锁状态。
- 在加锁之后,对象头中的第一个字节01111000最后三位为[000],其中低位的两位是[00],对照前面介绍的MarkWord中的存储结构的含义,它表示轻量级锁状态。
当前的程序并不存在锁竞争,基于前面的理论分析,此处应该是获得偏向锁,但是为什么变成了轻量级锁呢?
原因是,JVM在启动的时候,有一个启动参数-XX:BiasedLockingStartupDelay,这个参数表示偏向锁延迟开启的时间,默认是4秒,也就是说在我们运行上述程序时,偏向锁还未开启,导致最终只能获得轻量级锁。之所以延迟启动,是因为JVM在启动的时候会有很多线程运行,也就是说会存在线程竞争的场景,那么这时候开启偏向锁的意义不大。
如果我们需要看到偏向锁的实现效果,那么有两种方法:
- 添加JVM启动参数-XX:BiasedLockingStartupDelay=0,把延迟启动时间设置为0。
- 抢占锁资源之前,先通过Thread.sleep)方法睡眠4秒以上。
最终得到如下输出结果。
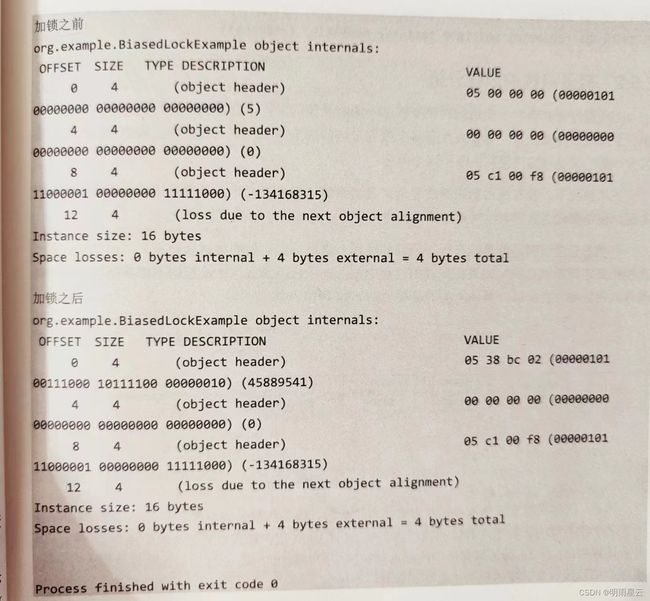
从上面输出结果我们发现,加锁之后,第一个字节低位部分的3位变成了[101],高位[1]表示当前是偏向锁状态,低位[01]表示当前是偏向锁状态,这显然达到了我们的预期效果。细心的读者会发现,加锁之前的锁标记位也是[101] -------- 这里并没有加偏向锁呀?
我们来分析一下,加锁之前并没有存储线程ID,加锁之后才有一个线程ID(45889541)。因此,在获得偏向锁之前,这个标记表示当前是可偏向状态,并不代表已经处于偏向状态。
05 00 00 00 (00000101 000000000000000000000000) (5)
05 38 bc 02 (00000101 001110001011110000000010) (45889541)
轻量级锁的原理分析
在线程没有竞争时,使用偏向锁能够在不影响性能的前提下获得锁资源,但是同一时刻只允许一个线程获得锁资源,如果突然有多个线程来访问同步方法,那么没有抢占到锁资源的线程要怎么办呢?很显然偏向锁解决不了这个问题。
正常情况下,没有抢占到锁的线程肯定要阻塞等待被唤醒,也就是说按照重量级锁的逻辑来实现,但是在此之前,有没有更好的平衡方案呢?于是就有了轻量级锁的设计。
所谓的轻量级锁,就是没有抢占到锁的线程,进行一定次数的重试(自旋)。比如线程第一次没抢到锁则重试几次,如果在重试的过程中抢占到了锁,那么这个线程就不需要阻塞,这种实现方式我们称为自旋锁,具体的实现流程如图所示。

当然,线程通过重试来抢占锁的方式是有代价的,因为线程如果不断自旋重试,那么CPU会一直处于运行状态。如果持有锁的线程占有锁的时间比较短,那么自旋等待的实现带来性能的提升会比较明显。反之,如果持有锁的线程占用锁资源的时间比较长,那么自旋的线程就会浪费CPU资源,所以线程重试抢占锁的次数必须要有一个限制。
在JDK1.6中默认的自旋次数是10次,我们可以通过-XX:PreBlockSpin参数来调整自旋次数。同时开发者在JDK1.6中还对自旋锁做了优化,引入了自适应自旋锁,自适应自旋锁的自旋次数不是固定的,而是根据前一次在同一个锁上的自旋次数及锁持有者的状态来决定的。如果在同一个锁对象上,通过自旋等待成功获得过锁,并且持有锁的线程正在运行中,那么JVM会认为此次自旋也有很大的机会获得锁,因此会将这个线程的自旋时间相对延长。反之,如果在一个锁对象中,通过自旋锁获得锁很少成功,那么JVM会缩短自旋次数。
轻量级锁的演示在上面中有,默认不修改偏向锁的延期开启参数,加锁得到的锁状态就是轻量级锁。

重量级锁的原理分析
轻量级锁能够通过一定次数的重试让没有获得锁的线程有可能抢占到锁资源,但是轻量级锁
得销节省积巷有销的时间较短的情况下才能起到提升同步锁性能的效果。如果持有锁的线程占用锁资源的时间较长,那么不能让那些没有抢占到锁资源的线程不断自旋,否则会占用过多的CPU资源,这反而是一件得不偿失的事情。
如果没抢占到锁资源的线程通过一定次数的自旋后,发现仍然没有获得锁,就只能阻塞等待了,所以最终会升级到重量级锁,通过系统层面的互斥量来抢占锁资源。重量级锁的实现原理如图 所示。

整体来看,我们发现,如果在偏向锁、轻量级锁这些类型中无法让线程获得锁资源,那么这些没获得锁的线程最终的结果仍然是阻塞等待,直到获得锁的线程释放锁之后才能被唤醒。而在整个优化过程中,我们通过乐观锁的机制来保证线程的安全性。
下面这个例子演示了在加锁之前、单个线程抢占锁、多个线程抢占锁的场景中,对象头中的锁的状态变化。
public class HeavyLockExample {
public static void main(String[] args) throws InterruptedException {
HeavyLockExample heavy = newHeavyLockExample();
System,out.println("加锁之前");
System.out.println(ClassLayout.parseInstance(heavy),toPrintable());
Thread t1=new Thread(()->{
synchronized (heavy){
try{
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printstackTrace( );
}
}
});
t1.start();
//确保t1 线程已经运行
TimeUnit.MILLISECONDS.sleep(500);
system.out.println("t1 线程抢占了锁");
System.out,println(ClassLayout.parseInstance(heavy).toPrintable());
synchronized (heavy){
system.out.println("main 线程来抢占锁");
system. out.println(ClassLayout.parseInstance(heavy).toprintable());
}
}
}上述程序打印的结果如下:
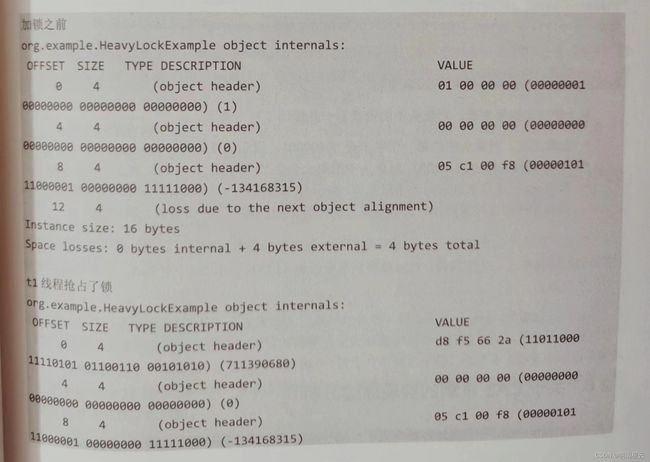

从上述打印结果来看,对象头中的锁状态一共经历了三个类型。
- 加锁之前,对象头中的第一个字节是00000001,表示无锁状态。
- 当t1线程去抢占同步锁时,对象头中的第一个字节变成了11011000,表示轻量级锁状态。
- 接着 main 线程来抢占同一个对象锁,由于t1线程睡眠了2秒,此时锁还没有被释放,main线程无法通过轻量级锁自旋获得锁,因此它的锁的类型是重量级锁,锁标记为10。
注意,在这个案例演示中,开发者并没有开启偏向锁的参数,如果开启了,那么第一个加锁之后得到的锁状态应该是偏向锁,然后直接到重量级锁(因为tI线程有一个sleep,所以轻量级锁肯
定无法获得)。
由此可以看到,synchronized同步锁最终的底层加锁机制是JVM层面根据线程的竞争情况逐步升级来实现的,从而达到同步锁性能和安全性平衡的目的,而这个过程并不需要开发者干预。