深度解析“IBM大型机”。全球云化的背景下,它如何运行的及为何能存活?

在这个深度解析中,我们将探讨一个大型企业的支柱。
前言
大型计算机通常被视为古老的机器,几乎是恐龙。但是,专门用于处理大量数据的主机今天仍然非常重要。如果它们是恐龙,那么它们是霸王龙,而台式机和服务器计算机是微不足道的灵长动物。
据估计,今天仍有10,000台主机在使用。它们几乎只被世界上最大的公司使用,包括财富500强公司的三分之二、全球前50大银行中的45家、前10家保险公司中的8家、全球前10大零售商中的7家以及前10家电信公司中的8家。而其中大部分主机来自IBM。
在这篇文章中,我们将会了解IBM主机电脑——它是什么,怎么工作,以及为什么在50多年后仍然非常强大。
舞台背景
主机是直接从20世纪50年代的第一批计算机技术中衍生出来的。然而,与被简化为低成本桌面或服务器使用的技术不同,它们发展成了能够处理大量数据工作负载的系统,比如批量数据处理和高交易量的金融交易。
真空管、磁芯存储器、磁鼓存储、磁带驱动器和打孔卡片是IBM 701(1952年),IBM 704(1954年)和IBM 1401(1959年)的基础。从今天的标准来看,这些机器还很原始,但它们提供了科学计算和数据处理的功能,否则这些工作需要手工完成或使用机械计算器。这些机器有一个成熟的市场,IBM尽可能地卖出了它们生产的机器。
在计算机的早期年代,IBM有许多竞争对手,包括Univac,Rand,Sperry,Amdahl,GE,RCA,NEC,Fujitsu,Hitachi,Unisys,Honeywell和CDC。当时,其他所有这些公司组合在一起占据了大约20%的主机市场,而IBM则占据了剩下的市场份额。今天,IBM是唯一重要的主机制造商,也是唯一在规模上做任何业务的制造商。它的实际竞争对手现在是云和集群,但正如我们将看到的,切换到这些平台并不总是划算的,它们也无法提供主机的可靠性。
高可靠性
按任何标准,大型机都非常庞大。现今的大型机可拥有多达240个服务器级CPU、40TB的纠错RAM和数PB的冗余基于闪存的二级存储。它们被设计用于处理大量关键数据,同时保持99.999%的正常运行时间,这相当于每年停机时间略超过五分钟。中型银行可能使用大型机运行50个或更多的财务应用程序和支持流程,并雇佣数千名支持人员,以确保运营平稳。
大多数大型机处理高交易量的金融交易,包括收银机上的信用卡购买、自动取款机上的取款或互联网上的股票购买。
银行的命脉不是金钱,而是数据。每笔银行交易都涉及必须处理的数据。例如,一笔借记卡交易涉及以下必须处理的数据:
- 1、获取用户的借记账户信息
- 2、验证用户ID和PIN
- 3、检查资金可用性
- 4、从用户账户中扣除交易金额
- 5、将款项转入卖方账户
所有这些必须在几秒钟内完成,银行必须确保它们可以在高交易量的活动期间(例如购物节)保持快速响应。主机是从头开始设计为提供冗余和高吞吐量。如果处理在营业时间停止,高速处理是无用的,如果人们必须等待几分钟才能处理事务,可靠的处理是无用的。
当您处理金融交易时,这意味着您正在赚钱。如果您要处理大量交易,则需要花费大量资金来保持运行平稳。当部件不可避免地损坏时,表演必须继续进行,这就是主机内置的冗余处理的作用。
RAM、CPU和硬盘都支持热插拔,因此如果组件出现故障,可以将其拔出并更换,而无需将主机关闭电源。事实上,主机被分成独立的分区,每个分区都有单独的RAM、存储、CPU,甚至不同的操作系统,允许应用程序在某些分区接收OS补丁、硬件修复和升级的维护的同时继续运行。
而与此不同的是,基于英特尔的服务器可以支持纠错码(ECC)内存,可以纠正RAM中的坏存储位,而Telum CPU可以纠正坏RAM位和更多。
IBM 研究员 Christian Jacobi 向我解释了这个过程:
当我们在CPU核心的处理中检测到错误时,该核心可以进行透明恢复操作。这是完全的核心重置,几乎像核心的小型重新启动,但程序状态、程序位置和所有寄存器内容都将恢复。因此,在恢复后,我们可以在程序的任何地方继续运行。这对软件层完全透明。这就是“核心恢复”。如果一个核心经历了太多重新启动,核心的内容可以移动到备用核心。这就是“大脑移植”。
大型机CPU可以从坏掉的内存位、内存通道、存储器芯片和CPU中恢复,所有这些对操作系统和软件来说都是透明的。
动态可重构系统分区
可以通过使用I/O控制器、主机权限和用户可配置的CPU来创建等效的单独主机单元或逻辑分区(LPAR)。每个LPAR可以运行一个分离的Z/OS实例,即主机操作系统。
这些实例可以用于开发、测试或运行不同的应用程序。LPARs还可以运行不同的操作系统,如Linux,并拥有完全独立的硬件资源。如果其中一个崩溃或需要进行维护,则其他分区不受影响。LPARs还根据权限进行分离;例如,一个用户组可以访问测试区域LPAR,但无法访问生产LPAR。
IBM使用一种高效且低延迟的协议,称为“并行sysplex”,来保持不同的主机(或同一主机上的不同LPARs)相互耦合,以实现工作负载分配、通信或恢复/故障转移。最多可以将32个CPU并行集群,以在负载下实现几乎线性加速,并且可以为性能或冗余分配CPU。使用数据锁定和排队方法来在处理时维护数据完整性,并在操作系统中实现并行sysplex需要一个整体的方法。
动态添加和删除容量的能力意味着当处理工作量激增时,主机可以做出响应。Jacobi表示,在疫情期间,IBM主机支持团队已经看到了处理供应链短缺所需处理的波动。
对于在主机上运行大负载的公司来说,灾难恢复并非后顾之忧。允许CPU动态添加到工作负载中的相同类型的操作系统支持,允许主机工作负载在地理上分离的数据中心之间进行迁移。因此,公司可以在风暴、恐怖袭击或基础设施故障等方面进行处理,这对于银行和保险等受监管行业的公司尤其有价值,因为联邦法律可能规定了灾难恢复。
CPU:Telum(英特尔公司的一种芯片架构)
IBM主机所使用的最新一代Z系列CPU被称为Telum。这是一款现代芯片,主频为5.2 GHz,采用三星7纳米制程,优化单线程性能。
Telum与Intel和AMD的其他性能CPU有什么不同之处?简而言之,它拥有更多的一切:更高的时钟速度、更多的缓存、更多的专门的CPU硬件和更多的PCI通道用于数据传输。
今天的IBM主机CPU基于IBM已经开发了30多年的POWER架构的高度演进版本。目前的Telum CPU非常强大。每个核心都是双向多线程的,拥有256KB的L1缓存和32MB的L2缓存,并支持超标量指令执行。Telum每个芯片有8个核心,每个插槽有2个芯片,每个抽屉有4个插槽;一个完全装配的主机可以支持250个核心,其中190个可以由用户控制。I/O由两个PCI Express 4.0控制器处理。

新的Telum缓存设计经过优化,针对异构单处理器性能,采用了新的独特的缓存管理策略。每个核心都有自己的32MB L2缓存。当一个缓存行被驱逐出L2缓存时,它会被移动到另一个L2缓存,并标记为L3缓存行。
这意味着八个L2缓存可以组合成一个256MB虚拟共享L3缓存,可以被任何一个八个核心访问。与AMD的Zen 3芯片相比,其中每个八个核心都有512KB的L2缓存和总共32MB的L3缓存。
当虚拟L3缓存中的缓存行被驱逐时,该行可以在系统中找到另一个核心的缓存,从而创建一个虚拟L4缓存。将系统中的L2缓存组合在一起,可以获得惊人的8192MB虚拟L4缓存。IBM声称,每个插座的总体性能提高超过40%,比上一代z15 CPU设计更好。
Jacobi告诉我:“缓存管理是新设计和投资的例子。整体非常成功,进展比预期顺利。我们始终知道,当每个核心执行相同的操作时,它使用相同的缓存。但是真正的工作并不是这样的。每个CPU使用缓存的方式略有不同。当我们运行实际的工作负载时,我们很高兴看到我们在L3和L4的测试结果中得到了完全的证实。Z16的性能已经成为一个新的平台,可以从中学习和发展。”
Telum还拥有一个芯片上的硬件AI加速器。当然,这部分针对的是大型企业数据任务,例如快速处理信用卡欺诈案件。 128个处理器瓷砖被组合在一起形成一个阵列,并由浮点矩阵数学函数支持。 AI功能支持推理处理和机器学习(或培训)。
这些芯片上的AI功能与L2缓存紧密耦合,以实现低延迟的数据预取和写回。虚拟L3和L4缓存管理系统帮助AI处理在主机抽屉中的多个CPU上实现几乎线性的扩展,使企业能够每秒处理数万个推理交易。
其他主机硬件加速功能包括:
- zEDC硬件支持无损压缩,CPU使用率最小。 Java Deflater类提供了比以前的Z实现高出15倍的吞吐量。
- 集成排序加速器,提供硬件加速排序。 DB2数据库基准测试显示,经过时间减少了12%,CPU使用率减少了高达40%。
- Pervasive Encryption是广泛使用的高级加密标准(AES)的硬件加速实现。它可以仅增加3%的CPU开销就对企业数据进行加密。它被称为Pervasive Encryption,因为它可以作为任何工作流程中的一部分加密主机上的任何东西。还可以为SHA、DES、GHASH和CRC32算法提供硬件加速。
主机的二级存储非常巨大,这对于处理大量时间关键性数据的公司至关重要。您不需要将磁盘插入主机;您需要插入存储阵列。其中一个阵列是日立G1500虚拟存储平台。它可以配备旋转硬盘、固态硬盘或NVMes,并且其容量为6.7 PB,吞吐量为48 GBps。相比之下,单个快速NVMe驱动器的最大速度约为7 GBps。这些阵列可以配置在各种RAID配置中以实现冗余,并且典型的主机每个LPAR都会有多个存储阵列,备份也有单独的存储阵列。
多个专用I/O控制器和CPU支持PCIe 5.0总线,以确保主机的吞吐量快。主存储在SSD或NVMes阵列中。
操作系统:Z/OS
为了充分利用定制的CPU,您需要一个专门的操作系统。Z/OS是主机操作系统,发音为“zee/zed oh ess”,根据您的位置而定。这个64位的操作系统是由IBM为Z/Architecture系列的大型计算机开发的,并且与旧的MVS主机操作系统兼容。它于2000年发布,向后兼容旧的24位和31位应用程序。Z/OS是专有和闭源的,从IBM获得许可和租赁(公司还提供个人版本的Z/OS用于PC台式机)。
该操作系统本身支持COBOL、C、C++、Fortran和PL/1编译的应用程序,以及Java应用程序服务器中的Java应用程序。正如早些时候讨论的那样,Z/OS可以分成单独的逻辑分区,每个分区具有单独的硬件、权限、工作负载,甚至不同的操作系统。Red Hat Linux是受支持的客户机操作系统。
Z/OS提供了一个通过安全服务器、资源访问控制设施(RACF)和全面加密实现的安全系统。安全服务器控制用户访问并限制授权用户执行的功能。RACF控制对所有受保护的Z/OS资源的访问,包括对应用程序、数据文件、API和硬件设备的访问。全面加密提供了使用强大的AES加密加密任何数据文件的能力,当访问时,加密的文件会自动透明地解密和重新加密。加密是在硬件上完成的,对CPU的负载很小。对文件具有访问权限但没有解密访问权限的用户只能看到加密文件的随机字节。
在一个可能有1,000名支持人员的系统中,没有任何一个人或角色需要知道或运行整个操作系统。大型机支持通常分为许多部门,包括企业存储、权限和访问、加密、每日系统操作、应用软件支持、应用测试、应用部署、硬件支持和报告等。
文件系统
在主机上,文件被称为数据集。每个文件通过完整路径引用,该路径由最多八个“限定符”组成,每个限定符由最多八个字符组成。限定符可以包含数字、字母和符号@、#和$。
下面是一个完整的数据集路径示例:
TEST1.AREA1.GHCC.AMUST#.T345.INPUT.ACC$.FILEAA
在字节级别上,所有字符都采用扩展二进制编码十进制交换码(EBCDIC),这是一种8位字符编码,代替了ASCII。在EBCDIC中,小写字母排在大写字母前面,字母排在数字前面,与ASCII完全相反。
Z/OS还支持ZFS文件系统,并提供一个文件系统,让UNIX或Linux程序在Z/OS下运行。
尽管Z/OS包括X Windows系统,但应用程序没有位图窗口的概念。所有显示都通过基于字符的屏幕使用3270仿真终端。这就是古老的传统“绿色屏幕”。具有屏幕I/O的Z/OS应用程序通常编码为24行80列。
Z/OS在与UNIX和Linux相分离的进化过程中不断发展和成熟。您可以在此处看到两个系统之间的相似之处和差异的方便列表。
主机软件堆栈
主机的传统核心是COBOL程序、数据文件和JCL(作业控制语言)。大多数公司都运行着几十年开发的大型COBOL程序,程序在非交互式作业中运行,数据被处理。批处理计算机作业的概念可追溯到50年代和60年代,早于交互式、分时共享的小型计算机时代。一个基本的作业包括要运行的计算机代码、要处理的输入数据、如何处理输出数据的理解以及向Z/OS操作系统传递处理步骤的作业命令。大量的数据可以在非交互式的批处理中高效地处理。以下是一些JCL和COBOL代码的示例。
作业控制语言
JCL首次引入于1960年代中期,其语法自那时以来基本保持不变。对于不熟悉JCL的人来说,它就像是阅读象形文字一样晦涩难懂,但它非常强大,仍然是运行应用程序的首选方法。
对于在Z/OS上运行的每个作业,作业控制语言都会指定要运行哪些程序、在哪里找到输入数据、如何处理输入数据以及将输出数据放置在何处。JCL没有默认设置,因此每个步骤必须编写顺序作业控制语句。最初,JCL是在穿孔卡片上输入的,它保留了这种80列的格式。
以下是一个简单的JCL示例:
//EXAMPLE JOB 1 //MYEXAMPLE EXEC PGM=SORT //INFILE DD DISP=SHR,DSN=ZOSPROF.TEST.DATA //OUTFILE DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * SORT FIELDS=(1,3,CH,A)
每个JCL DD(数据定义)语句用于将一个z/OS数据集(文件)与ddname关联,程序将其识别为输入或输出。
在提交执行时,EXAMPLE是系统与此工作负载关联的作业名称。MYEXAMPLE是步骤名称,指示系统执行SORT程序。在DD语句上,INFILE是ddname。INFILE ddname在SORT程序中编码为程序输入。此DD语句中的数据集名称(DSN)为ZOSPROF.TEST.DATA。这是一个文件夹路径,也是文件名。数据集可以与其他系统进程共享(DISP = SHR)。ZOSPROF.TEST.的数据内容是SORT程序的输入。OUTFILE ddname是SORT程序的输出。
SYSOUT=*指定将系统输出消息发送到作业入口子系统(JES)打印输出区域。也可以将输出发送到数据集。SYSIN DD *是一个输入语句,它指定其后跟的是数据或控制语句。在这种情况下,它是排序指令,告诉SORT程序要排序SORTIN数据记录的哪些字段。
所有作业都需要三种主要类型的JCL语句:JOB、EXEC和DD。作业定义了z/OS要处理的特定工作负载。由于JCL最初是为穿孔卡而设计的,编写JCL语句的细节可能很复杂。然而,总体概念非常简单,大多数作业可以使用非常小的控制语句子集来运行。
COBOL语言
COBOL是一种早期的计算机语言,于1959年设计。与其同一代的其他计算机语言一样,它是命令式、过程式和面向行的。它被设计为自我记录,使用类似英语的语法,不幸的是这使得它非常冗长。它在商业和金融社区中的早期流行导致了庞大的专用代码库,这些库今天仍在广泛、每日使用中。
尽管COBOL代码可能与其他流行语言相比看起来冗长而笨重,但它不是一种运行缓慢的语言。IBM继续发布IBM Enterprise COBOL for Z/OS编译器的更新,该编译器的第6版提供了针对Telum架构的额外硬件优化和访问JSON和XML的扩展,同时提供Java/COBOL互操作性。有了这种支持,COBOL应用程序可以更好地与现代面向Web的服务和应用程序交互。还存在基础设施来运行COBOL程序在云应用程序中。
以下是一个以简单数据文件作为输入,对文件进行排序并输出结果的COBOL程序示例:
*注释以列7中的*开始
*COBOL程序具有Section、Paragraph、Sentence、Statements结构。
PROGRAM-ID. SORTEXAMPLE.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT INPUT ASSIGN TO INFILE.
SELECT OUTPUT ASSIGN TO OUTFILE.
SELECT WORK ASSIGN TO WORKFILE.
DATA DIVISION.
FILE SECTION.
FD INPUT.
*定义输入字段
01 INPUT-EMPLOYEE.
*定义EMPLOYEE-ID-INPUT字段的存储和类型,
*5位数字数据
05 EMPLOYEE-ID-INPUT PIC 9(5).
*定义EMPLOYEE-LAST-NAME字段的存储和类型,
*带25个字符的字母数字数据
05 EMPLOYEE-LAST-NAME PIC A(25).
*使用相同的输入字段作为输出字段
FD OUTPUT.
01 EMPLOYEE-OUT.
05 EMPLOYEE-ID-OUTPUT PIC 9(5).
05 EMPLOYEE-FIRST-NAME PIC A(25).
*使用相同的输入字段作为临时工作数据
SD WORK.
01 WORK-EMPLOYEE.
05 EMPLOYEE-ID-WORK PIC 9(5).
05 EMPLOYEE-NAME-WORK PIC A(25).
*使用EMPLOYEE-ID-OUTPUT作为排序键,按升序排序
PROCEDURE DIVISION.
SORT WORK ON ASCENDING KEY EMPLOYEE-ID-OUTPUT
USING INPUT GIVING OUTPUT.
DISPLAY 'Finished Sorting'.
STOP RUN.
这个JCL示例将在编译示例COBOL程序之后运行它。请注意,JCL通常会引用定制为组织的系统配置,这些配置是不可移植的。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = SORTEXAMPLE
//IN DD DSN = INPUT-FILE-NAME,DISP = SHR
//OUT DD DSN = OUTPUT-FILE-NAME,DISP = SHR
//WRK DD DSN = &&TEMP
SORTEXAMPLE是COBOL数据处理的一个非常小的示例。一个典型的银行应用程序可能是用于处理活动贷款的。对于这样的程序,您需要有活动客户、贷款类型、月度贷款支付和利率的输入数据文件。您将创建输出数据,用于剩余本金余额、宽限期、拖欠通知、向信用监控公司的更新等等。
这种类型的应用程序的代码很容易超过一百万行。您需要业务分析师来理解和维护业务逻辑以及开发人员来实施代码更改。您需要系统设计人员来理解和管理数据文件和权限;他们将了解应用程序与其他系统的交互方式以及JCL如何配置以运行批处理作业。您还需要应用程序经理或所有者来决定如何以及何时对应用程序进行更改。
CICS
Mainframe还作为软件堆栈的一部分运行应用程序服务器。应用程序服务器就像全包式度假村一样运行您的应用程序代码,并为代码提供许多功能。例如,如果您需要数据,您的请求是在高级别上进行的。这相当于呼叫服务员点餐。在应用程序服务器的容器中编写代码有助于将开发工作集中在应用程序业务逻辑上,而不是系统级细节上,这些细节在批处理中需要。
CICS(客户信息控制系统)是一种混合语言应用服务器,可以运行COBOL、Java、PHP、C和其他第三方供应商语言。它提供高容量的在线事务处理,广泛应用于银行、保险公司、信用卡公司和航空公司等金融服务公司。虽然CICS是批处理的替代方案,但通常被设计为与批量数据文件一起运行。CICS提供基于API的高性能容器,可以在其中运行专用代码。
CICS提供以下功能:
- 处理入站和出站Web通信。
- 管理需要事务顺序的输入数据队列。
- 将输入数据格式(如JSON和XML)处理为本地应用程序输入数据。
- 提供安全功能,包括身份验证、授权和加密。
- 在同一服务器上运行多种语言,以提高性能并减少开销。
- 提供共享内存的常用CICS LINK API,用于应用程序之间的高性能通信。
- 在事务的某些部分失败并需要回滚时,提供处理的原子分离。
CICS可以处理来自Web和移动应用程序以及ATM的实时数据,并提供99.999%的正常运行时间,在购物节日和银行假日后的高峰事务期间具有高度可扩展性。
为什么大型机能够存活
大型计算机的所有权带来了不少挑战。只有最大的企业才会使用它们,因为它们的拥有和运行成本很高——价格介于250,000美元至4,000,000美元之间,而且每台都是定制的。它们需要一个庞大的支持团队,可能会有数百或数千人。精通COBOL、JCL、大型计算机存储、硬件维护、大型计算机操作和应用的技术支持人员正在退出劳动力市场。COBOL不再广泛教授,很少有大学在其课程中涉及大型计算机实践。
许多大型计算机应用程序现在已有数十年的历史,虽然COBOL运行效率高,但软件需要发展以应对客户不断变化的需求。维护“尘土飞扬”的应用程序需要大量的工作量,而老旧的银行和保险公司与灵活、年轻的金融科技公司相比处于竞争劣势。
尽管人们已经预测大型计算机会消失几十年了,但它们仍然存活,因为它们填补了处理高容量、业务关键的金融交易的重要领域。IBM大型计算机具有最终的客户“锁定”。财富500强公司已经使用同样的COBOL代码库数十年了。原始开发人员早已离开,甚至已因年迈而去世,重写数千万行使命关键型代码是一个非常困难、非常昂贵的建议。
许多公司尝试并失败了。但转换代码只是整个迁移过程的一部分。您还必须转换数据,在新应用程序周围开发新的流程和程序,对新流程和程序进行培训,对所有系统进行压力测试,然后进行生产切换。
所有这些都必须在规定的时间表和预算内完成。这相当于进行心脏移植手术,您的生存机会不到50%。这种迁移需要公司数年才能完成,并充满挑战。许多公司花费了数亿美元或数千万美元来尝试升级这些系统,但是失败了。更安全的选择是继续支付大型计算机硬件、操作系统和应用程序的许可费,并维护数百或数千名支持人员。
替代主机的选择确实存在。主要提供银行软件的FIS Global公司提供了一种迁移路径,即其FIS Modern Banking Platform。该公司构建了一堆云组件,以执行与其主机产品相同的功能,并将其COBOL主机应用程序重写为Java并将平面文件数据迁移到关系型数据库中。Java代码在JBOSS应用服务器中运行,该服务器部署在Docker容器中。容器在云服务器中由Kubernetes容器管理器管理,后者在云服务器中运行Linux或Windows。实时事件由Apache Kafka管理。
通信通过Kafka事件或Java消息服务进行,并且可以在AWS或Azure云中在几秒钟内启动新的服务器实例以提供所需的高容量处理。FIS Global可以提供与主机应用程序相同的功能,但其系统由通用云组件构成,并且具有极高的可伸缩性。转换到这种架构的投资相当高,而且平稳的转换并不是必然的,但一旦公司在现代银行平台上运行,年度运营成本预计会更低。
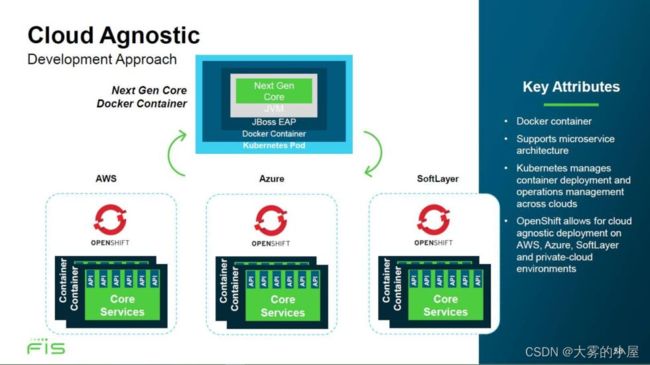
FIS Global维护了一套完整的银行产品套件,针对大型计算机,拥有分析师和开发人员团队,他们已将业务逻辑从COBOL转换为Java,并将数据从平面文件映射为关系数据库架构。其工程师已创建了Java和数据库容器,该公司已创建了从大型计算机向云平台迁移客户数据和服务的路线图。
那么,为什么银行不抓住机会摆脱它们的主机并转向云端呢?风险和转换成本。通常,银行很注重风险。他们通常在新技术方面落后,只有在竞争或监管压力下才会采用。
迁移许多关键任务应用程序的成本可能会轻易达到数亿美元,并需要三年或更长时间才能完成。在迁移过程中,很难添加新功能或对竞争做出反应。除了风险和成本之外,还需要聘请数百名高度专业化的技术顾问负责迁移工作。如果找不到这些人,你的项目计划就会受到瓶颈的影响。
主机继续适应
IBM的业务模式使其能够投资于主机基础设施。最新的主机CPU——Telum,在缓存管理方面取得了进展,并增加了内部AI处理功能,两者都带来了性能提升。主机COBOL已经扩展到支持JSON和XML,以便进行基于Web的开发,并针对Telum CPU架构进行了大量的优化。
IBM也正在适应行业变化,并将其混合云策略推向主机。这包括使用Red Hat Linux进行DevOps和使用Red Hat进行Linux工具链。Red Hat使节点.js、Python、Docker和Kubernetes在主机上可用。其他最近的Z/OS功能包括能够提取、管理和运行容器化的开源Linux图像。
因此,即使是COBOL程序员和主机支持人员逐渐退出劳动力市场,IBM仍在现代化主机基础设施和软件堆栈。虽然主机仍然面临来自云端的挑战,但它已经成功适应并存活下来。