word2vec及其优化
1.算法背景:
(1)N-gram:n-1阶的Markov模型,认为一个词出现的概率只与前面n-1个词相关;统计预料中各种词串(实际应用中最多采用n=3的词串长度)的出现次数,并做平滑处理(应对count=0和count=1的情况)。在预测一个句子的概率时,只需要找到相关的概率参数,将他们连乘起来。
(2)神经概率语言模型:将单词映射为embedding, 输入隐藏层,激活函数用tanh,输出层为一个softmax多分类器。得到的embedding可以体现单词之间的相似性,因为神经概率语言模型中假定了相似的词对应的词向量也是相似的,且概率函数关于词向量时光滑的。词向量模型自带平滑化功能,因为概率函数取值范围不包含边界值0,1。
(3)词向量的编码方式:one-hot representation(有维数灾难、词汇鸿沟和强稀疏性的问题),distributed representation。
2.网络结构:
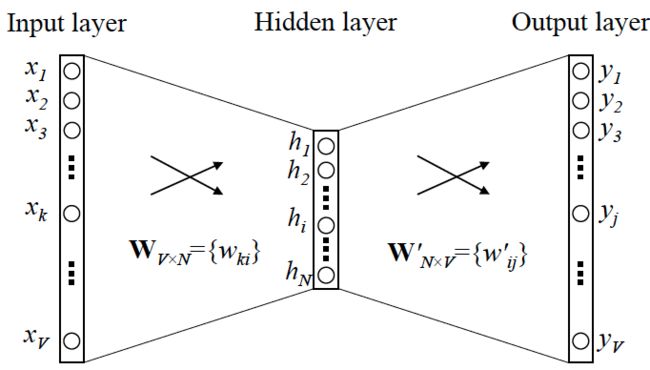
3.分类:
(1)crow:
one-hot格式的输入,乘以权重矩阵W,得到W的某一行h,多个h加和取平均输入隐藏层。
用一个词作为输入,来预测周围的上下文。
(2)skip-gram:
输入层到输出层的原理不变,但隐藏层到输出层,损失函数变成多个词损失函数之和。
拿一个词的上下文作为输入,来预测这个词。


4.算法流程:
(1)词向量预处理步骤:
对输入文本生成词汇表,统计词频,从高到低排序,取最频繁的V个词构成词汇表。确定词向量的维数,随机初始化每个词embedding。
(2)skip-gram / crow处理步骤:
确定窗口大小window,从(i-window)到(i+window)生成训练样本;确定batch_size,必须是2*window的整数倍,确保每个batch包含一个词对应的所有样本;用负采样或者层次softmax的方法训练模型;神经网络迭代训练到一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应的词向量。
5.参数设置:
- Skip-Gram 的速度比CBOW慢一点,小数据集中对低频次的效果更好;
- Sub-Sampling Frequent Words可以同时提高算法的速度和精度,Sample 建议取值为[10^-5, 10^-3] ;
- Hierarchical Softmax对低词频的更友好;
- Negative Sampling对高词频更友好;
- 向量维度一般越高越好,但也不绝对;
- Window Size,Skip-Gram一般10左右,CBOW一般为5左右。
- embedding_dimensions = number_of_categories**0.25,the embedding vector dimension should be the 4th root of the number of categories
6.优缺点:
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中
缺点/局限性:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
- Word2Vec只考虑到上下文信息,而忽略的全局信息;
- Word2Vec只考虑了上下文的共现性,而忽略的了彼此之间的顺序性;
7.优化方法:
- Negative Sample(随机负采样):本质是预测总体类别的一个子集;负采样定义:
 为什么采用负采样:(1)将多分类问题转化为K+1个二分类问题,从而减少计算量,加快训练速度;(2)保证模型训练效果,因为目标词只跟相近的词有关,没有必要使用全部的单词作为负例来更新权重;
为什么采用负采样:(1)将多分类问题转化为K+1个二分类问题,从而减少计算量,加快训练速度;(2)保证模型训练效果,因为目标词只跟相近的词有关,没有必要使用全部的单词作为负例来更新权重;
负采样的概率分布在tensorflow中实现的是:
其中,s(w_i)是词w_i在字典中根据词频逆排序的序号。 - Hierarchical Softmax:
利用了Huffman树依据词频建树,词频大的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多,在训练的过程中,低频词的路径上的参数能够得到更多的训练,所以效果会更好。本质是把N分类问题变成了log(N)次二分类; - 加入视频特征信息:
参考EGES的实现策略,训练视频特征embedding,辅助最终的vid相似度计算;博主在实际应用中使用了类别、kis、album、标签,这四个特征,有明显正向效果; - 训练数据中增加随机游走序列:
参考node2vec实现策略,可以增加模型的泛化性,探索更多隐藏的相似信息,但在实际应用中没有取得明显的正向效果; - 过热视频负采样:
为了避免哈利波特效应带来的噪声(过热视频可能会将毫无关联的视频联系起来,构成训练正样本),对于词频最高的头部n个视频做降采样,并在滑动窗口生成的过程中,遇到过热视频就截断窗口,实际应用中效果正向;
8.核心代码:
实际应用中可以直接调用gensim接口。初始化时为每个词随机生成一个N维向量,而不是one-hot格式,本质是一个意思。
首先读取观影历史数据:
def read_data(file_path, min_cnt, ROOT, param):
view_seqs = []
with open(file_path) as f:
for line in itertools.islice(f, 0, None):
view_seq = []
for token in line.strip().split(" "):
view_seq.append(int(token))
view_seqs.append(view_seq)统计词频,生成词典(词典包括视频及视频特征):
def build_vocab(view_seqs, min_cnt, ROOT, param):
dictionary = dict()
count = []
counter = Counter()
index_feat = {}
feature = np.load(ROOT + "/feat_6.npy", allow_pickle=True).item()
for view_seq in view_seqs:
counter.update(view_seq)
count.extend(counter.most_common())
tools.make_dir(os.path.join(ROOT, 'processed'))
with open(os.path.join(ROOT, 'processed/vocab_cnt.tsv'), "w") as f:
for vid, cnt in count:
temp = str(vid)
if cnt >= min_cnt and len(temp)==10 and temp[-1]=='2': #过滤脏数据
dictionary[vid] = len(dictionary)
f.write(str(vid) + "," + str(cnt) + "\n")
vid_dict = dict(zip(dictionary.values(), dictionary.keys()))
index_counter = {}
for key in counter:
if key in dictionary:
index_counter[dictionary[key]] = counter[key]
for vid in temp_dict:
vid_str = str(vid)+'t'
if vid_str in feature:
if feature[vid_str] not in dictionary:
dictionary[feature[vid_str]] = len(dictionary)
index_feat[str(dictionary[vid]) + 't'] = dictionary[feature[vid_str]]
temp_dict = copy.deepcopy(dictionary)
index_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
logging.info("build vocab success! vocab size is {}".format(len(dictionary)))
return dictionary, index_dictionary, counter, index_counter, index_feat, vid_dict根据词典把观影序列转化为index格式:
def convert_views_to_index(view_seqs, dictionary, counter, is_train=True):
index_view_seqs = []
for view_seq in view_seqs:
index_view_seq = []
for view in view_seq:
#负采样
if view in dictionary:
if counter[view] < 2000:
index_view_seq.append(dictionary[view])
else:
p = random.randint(0,counter[view])
if p<3000 + (math.log(counter[view]) - 8) * 1000:
index_view_seq.append(dictionary[view])
if len(index_view_seq) >= 2 or not is_train:
index_view_seqs.append(index_view_seq)
logging.info("convert to index success! index_view_seqs size is {}".format(len(index_view_seqs)))
return index_view_seqs初始化模型:
class SkipGramModel:
def __init__(self, index_dictionary, embed_size, num_sampled, learning_rate):
self.index_dictionary = index_dictionary
self.vocab_size = len(index_dictionary) + 1
self.embed_size = embed_size
self.num_sampled = num_sampled
self.lr = learning_rate
self.global_step = tf.Variable(0, dtype=tf.int32, trainable=False, name='global_step')
def _create_placeholders(self):
with tf.name_scope("data"):
self.context_words = tf.placeholder(tf.int32, shape=[None], name='context_words')
self.target_words = tf.placeholder(tf.int32, shape=[None, 1], name='target_words')
def _create_embedding(self):
with tf.name_scope("embed"):
self.embed_matrix = tf.Variable(tf.random_uniform([self.vocab_size,
self.embed_size], -1.0, 1.0),
name='embed_matrix')
def _create_loss(self):
with tf.name_scope("loss"):
self.embed_context = tf.nn.embedding_lookup(self.embed_matrix, self.context_words, name='embed')
self.nce_weight = tf.Variable(tf.truncated_normal([self.vocab_size, self.embed_size],
stddev=1.0 / (self.embed_size ** 0.5)),
name='nce_weight')
self.nce_bias = tf.Variable(tf.zeros([self.vocab_size]), name='nce_bias')
self.loss = tf.reduce_mean(tf.nn.nce_loss(weights=self.nce_weight,
biases=self.nce_bias,
labels=self.target_words,
inputs=self.embed_context,
num_sampled=self.num_sampled,
num_classes=self.vocab_size), name='loss')
def _create_optimizer(self):
self.optimizer = tf.train.GradientDescentOptimizer(self.lr).minimize(self.loss,
global_step=self.global_step)
def _create_summaries(self):
with tf.name_scope("summaries"):
tf.summary.scalar("loss", self.loss)
tf.summary.histogram("histogram loss", self.loss)
self.summary_op = tf.summary.merge_all()
def _create_top_k(self):
self.nemb = tf.nn.l2_normalize(self.embed_matrix, 1)
self.seq = tf.placeholder(shape=[1, None], dtype=tf.int32)
self.rating = tf.placeholder(shape=[1, None], dtype=tf.float32)
mean_vec = self.weight_mean(self.seq, self.rating)
dist = tf.matmul(mean_vec, self.nemb, transpose_b=True)
self.top_val, self.top_idx = tf.nn.top_k(dist, k=TOP_K)
def _create_nn_top(self):
self.seqs = tf.placeholder(shape=[None], dtype=tf.int32)
seq_embed = tf.nn.embedding_lookup(self.nemb, self.seqs)
dist = tf.matmul(seq_embed, self.nemb, transpose_b=True)
self.top_vals, self.top_idxs = tf.nn.top_k(dist, k=TOP_K)
def weight_mean(self, seq, rating):
seq_embed = tf.nn.embedding_lookup(self.nemb, seq)
weight_mul = tf.multiply(seq_embed, tf.transpose(rating))
weight_sum = tf.reduce_sum(weight_mul, axis=1)
return weight_sum / tf.reduce_sum(rating)
def build_graph(self):
self._create_placeholders()
self._create_embedding()
self._create_loss()
self._create_optimizer()
self._create_summaries()
self._create_top_k()
self._create_nn_top()训练模型:
def train_model(model, index_view_seqs, index_dictionary, counter):
saver = tf.train.Saver()
tools.make_dir(ROOT + '/checkpoints')
with tf.Session(config=tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=True,
gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.5))) as sess:
sess.run(tf.global_variables_initializer())
total_loss = 0.0
for i in range(EPOCH):
logging.info("batch data building!")
context_batches, target_batches = generate_epoch_skipgram(index_view_seqs, BATCH_SIZE, CONTEXT_SIZE, counter)
all = len(context_batches)
logging.info("current EPOCH is %d" % i)
batch_cnt = 0
k = 0
for context_batch, target_batch in zip(context_batches, target_batches):
feed_dict = {model.context_words: context_batch,
model.target_words: target_batch}
loss_batch, _ = sess.run([model.loss, model.optimizer],
feed_dict=feed_dict)
total_loss += loss_batch
batch_cnt += context_batch.shape[0]
k += 1
if k % 10000 == 0:
logging.info('Average loss {:5.8f}, epoch {}, {}/{}, batch cnt {}, '\
.format(total_loss / batch_cnt, i, k, all, batch_cnt))
logging.info('Average loss at epoch {} batch cnt {}, cur loss: {:5.5f}, '.format(i, batch_cnt, total_loss / batch_cnt))
total_loss = 0.0
top_idx, top_val = sess.run([model.top_idx, model.top_val],\
{model.seq: [[1]], model.rating:[[1]]})
if (i + 1)% 4 == 0:
saver.save(sess, ROOT + '/checkpoints/dl', i)
matrix = sess.run([model.embed_matrix])生成推荐结果:
def predict(index_dictionary, model):
output = open(ROOT + "/video_embed.vec", "w")
for i, video in enumerate(index_dictionary.values()):
value = []
for dim in matrix[0][i]:
value.append(str(dim))
output.write(str(video) + "#" + " ".join(value) + "\n")
logging.info("tf model init successfully!")
input_batches, output_batches = build_batches(index_dictionary)
output_file = open(ROOT + "/nn_result", "w")
log_index = 0
all = len(index_dictionary)
for input_batch, output_batch in zip(input_batches, output_batches):
top_idx, top_val = sess.run([model.top_idxs, model.top_vals], {model.seqs:input_batch})
for inputs, outputs, values in zip(output_batch,top_idx,top_val):
result = []
for index, dist in zip(outputs, values):
if index_dictionary.get(index) is None:
continue
vid = index_dictionary[index]
result.append(str(int(vid/10))+"#"+str(vid % 10)+"#"+ str(dist))
str_result = ",".join(result[0:300])
video,site = int(inputs / 10), inputs % 10
output_file.write(str(video) + "#" + str(site)+ '\t' + str_result + '\n')
log_index += 1
if(log_index % 10000 == 0):
logging.info("video index: {}/{}".format(log_index, all))
完整代码附在文章最后。
9.相关问题:
(1)Word2Vec两个算法模型的原理是什么,网络结构怎么画?
(2)网络输入输出是什么?隐藏层的激活函数是什么?输出层的激活函数是什么?
(3)目标函数/损失函数是什么?
(4)Word2Vec如何获取词向量?
(5)推导一下Word2Vec参数如何更新?
(6)Word2Vec的两个模型哪个效果好哪个速度快?为什么?
(7)Word2Vec加速训练的方法有哪些?
(8)介绍下Negative Sampling,对词频低的和词频高的单词有什么影响?为什么?
(9)Word2Vec和隐狄利克雷模型(LDA)有什么区别与联系?
(10)FastText和Glovec原理:
FastText是将句子中每个词通过一个lookup层映射成词向量,对词向量叠加取平均作为句子的向量,然后直接用线性分类器进行分类,没有非线性的隐藏层,结构简单且模型训练更快。
Glovec融合了矩阵分解和全局统计信息的优势,统计语料库的词-词之间的共现矩阵,加快模型的训练速度且可以控制词的相对权重。
(11)softmax的原理、word2vec的公式:
参考Word2vec ------算法岗面试题 - 鸿钧道人 - 博客园
10.扩展算法:
(1)item2vec、struc2vec
(2)topic2vec:airbnb embedding
(3)DeepWalk——>Node2vec
DeepWalk:通过随机游走的方式提取点序列,再用word2vec模型根据顶点和顶点的共现关系,学习顶点的向量表示。训练时采用层次softmax优化算法,避免计算所有词的softmax。不适用于有权图,无法学习边的权重。
Node2vec:是DeepWalk的扩展。通过二阶随机游走提取点序列,转移概率受权值w的影响:

- q:控制“向内”还是“向外”游走。若q>1,倾向于访问与 t 接近的顶点,若 q<1 则倾向于访问远离 t 的顶点。
- p:控制重复访问刚刚访问过的顶点的概率。若设置的值较大,就不大会刚问刚刚访问过的顶点。若设置的值较小,那就可能回路返回一步。
(4)wav2vec
用于处理音频数据
参考:
【1】Word2vec详细整理(2)—优化方法和常见问题 - 知乎
【2】https://www.zhihu.com/question/60648826/answer/284809398
【3】深入浅出Word2Vec原理解析 - 知乎
【4】https://blog.csdn.net/mytestmy/article/details/26969149
【5】NLP 之 word2vec 以及负采样原理详解_周永行的博客-CSDN博客_word2vec负采样的原理