md5碰撞
md5算法具有压缩性、容易计算、抗修改性和强抗碰撞的特点。
并不是给一个md5加密后的密文,就能算出一个原文来。从密文推算出明文理论上是不可能的,所以并不能通过 MD5 的散列值逆向推算出明文。
即给定 Hash 值,不能逆向计算出 M
MD5(M)=Hash
其中 M 指密码的明文,Hash 表示密码散列后的密文。
MD5(M1)=MD5(M2)
即给定消息 M1,能够计算获取 M2,使得 M2 产生的散列值与 M1 产生的散列值相同。但是m1和m2却是两个不同的值。
如此,MD5 的抗碰撞性就已经不满足了,使得 MD5 不再是安全的散列算法。这样一来,MD5 用于数字签名将存在严重问题,因为可以篡改原始消息,而生成相同的 Hash 值。
王小云教授的研究报告表明,MD4,MD5,HAVAL-128,RIPEMD 和 SHA-1 均已被证实存在上面的漏洞,即给定消息 M1,能够找到不同消息 M2 产生相同的散列值,即产生 Hash 碰撞。
总而言之,MD5 算法里面有很多不可逆的运算,会丢失很多原文的信息,无法找回,所以是不可逆的。
“md5碰撞”,即对一个确定的md5值,找到一个输入,使得计算出的MD5值和之前确定的md5值一样。
简而言之就是:先得出一个字符串的MD5值,再根据这个值,逆算出另外一个不同的字符串——但是它们的MD5值是一致的
常见的碰撞方法:
1.暴力碰撞:穷举法、字典法
穷举法就是不停地尝试各种字符的排列组合,看哪一个组合的MD5码能对上。缺点是太耗费时间。举个例子,假设我们要破解一个6位大小写字母和数字混合的密码,那么一共有 (26 + 26 + 10) ^ 6 种组合。这个数的大小超过500亿。
字典法就是把计算结果以映射表的形式存放起来,一个原文对应着一个MD5值。将已知的MD5码查表,就可直接反查出原文。字典法体现了算法设计的“以空间换时间”的思想。缺点是比较耗费空间,而且实际上还是要穷举一遍所有的输入,只不过把穷举的结果存了起来
2.快速 MD5 碰撞生成器使用方法
相关扩展:MD5碰撞及SHA1碰撞-CSDN博客
打开cmd控制台,到fastcoll程序所在的目录,运行fastcoll程序,运行时添加 -p 参数,参数后跟要构造的原文件的文件名,会生成两个功能和原文件一样且md5也一样的文件
与输入的文件的区别是:生成的两个文件后方跟了一堆乱码后缀,但执行或读取程序时,文件格式一般都在最前面,这也是为什么生成的文件还能正常执行或读取的原因。
3.构造前缀碰撞法
构造前缀碰撞法,由密码学家:Marc Stevens等人提出。
在他们的网站上给出了两个程序,它们的MD5一致,却又都能正常运行,并且可以做完全不同的事情
http://www.win.tue.nl/hashclash/SoftIntCodeSign/HelloWorld-colliding.exe
http://www.win.tue.nl/hashclash/SoftIntCodeSign/GoodbyeWorld-colliding.exe
这两个程序会在屏幕上打印出不同的字符,但是它们的MD5都是一致的。
这几位密码学家编写的“快速 MD5 碰撞生成器”
http://www.win.tue.nl/hashclash/fastcoll_v1.0.0.5.exe.zip
源代码:http://www.win.tue.nl/hashclash/fastcoll_v1.0.0.5_source.zip
这个生成器需要一个输入来生成两个md5相同的文件,输入可以是可执行文件,还可是pdf文档等,生成的两个文件都可以打开或执行
参考文章:【精选】md5碰撞介绍及工具,并对百度网盘进行碰撞-CSDN博客
时间和空间的折中:哈希链表 / 彩虹表法
如果说穷举法太耗费时间,字典法太耗费存储空间的话,我们能不能考虑在时间消耗和空间消耗之间折中呢?我们可以考虑用链表将一系列有意义的原文和MD5码串起来。要构造这样的链表,我们需要两个函数:哈希函数H(x)和衰减函数R(x)。哈希函数可以是MD5,也可以是其他的消息摘要算法。H(x)的值域是R(x)的定义域,R(x)的值域是H(x)的定义域。R(x)不是H(x)的反函数。
将一个原文不停地使用H(x)和R(x)交替进行运算k次,再将原文本身和运算结果以链表的形式串接起来,就可以得到结点个数为2k+1的链表。实际存放的时候只存放首端和末端两个原文即可。这种链表叫做“哈希链表”,体现了算法设计的“时空权衡”(Space and Time Tradeoffs)。
举个例子,假设原文s=abcabc,经过2次交替运算,得到以下的链表:
abcabc->H(x)->3C8B0D7A->R(x)->eopmca->H(x)->7E9F216C->R(x)->rapper
假设我们要破解的摘要值(哈希链表的H(x)不一定是MD5算法,这里用更准确的说法代替MD5码)是7E9F216C,经过R(x)运算得到rapper,说明我们要寻找的原文就在以rapper为末端的哈希链表中。从首端开始经过多次运算,我们发现eopmca的摘要值就是7E9F216C。于是就反查出7E9F216C对应的原文是eopmca。
如果在生成哈希链表的时候依次使用多个不一样的R(x),此时的哈希链表就是“彩虹表”。
已经计算好的彩虹表:http://project-rainbowcrack.com/table.htm
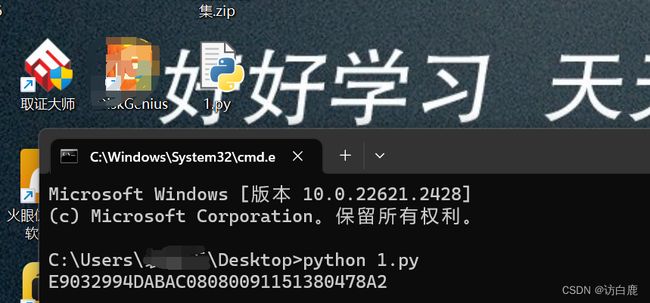
例题:buuctf 还原大师

已知的线索,就是神秘字符串经过md5(32位)编码后的前几位字符是E903,因为完整的密文中间有不止一个?
破解的思路就是用不同的字母替换?,再对已知的密文进行md5加密,使加密后的字符串前几位为“E903”
import hashlib
m='TASC?O3RJMV?WDJKX?ZM'
for i in range(26):
t1 = m.replace('?',str(chr(65+i)),1)
for j in range(26):
t2 = t1.replace('?',str(chr(65+j)),1)
for h in range(26):
t3 = t2.replace('?',str(chr(65+h)),1)
s = hashlib.md5(t3.encode('utf8')).hexdigest().upper()
if s[:4] == 'E903':
print(s)代码审计:
在这段代码中,
str(chr(65+j))是将ASCII码值转换为对应的字符。ASCII码值65对应字母’A’,ASCII码值66对应字母’B’,以此类推。chr()函数将ASCII码值转换为对应的字符,而str()函数将字符转换为字符串。
replace('?',str(chr(65+j)),1)是将字符串中的第一个问号’?'替换为对应的字符。其中的参数1表示只替换第一个匹配到的问号,而不是替换所有的问号。这样做是为了避免重复替换导致的结果错误。通过循环嵌套,这段代码会尝试将字符串中的三个问号分别替换为A-Z的字母,然后计算MD5哈希值并与预设的哈希值进行比较。如果匹配成功,则打印出哈希值。
hashlib.md5(t3.encode('utf8')).hexdigest().upper()这行代码的作用是对字符串t3进行MD5哈希计算,并将结果转换为大写的十六进制字符串。具体解释如下:
t3.encode('utf8')将字符串t3编码为UTF-8格式的字节串。hashlib.md5()创建一个MD5哈希对象。hexdigest()方法返回哈希对象的十六进制表示形式。upper()方法将十六进制字符串转换为大写形式。然后,
if s[:4] == 'E903':是一个条件判断语句,用于判断MD5哈希值的前四位是否等于字符串’E903’。如果匹配成功,则执行下一行代码,即print(s),打印出匹配成功的哈希值。
利用cmd即可得到python运算代码结果