Python武器库开发-高级特性篇(七)
高级特性篇(七)
装饰器
装饰器是给现有的模块增添新的小功能,可以对原函数进行功能扩展,而且还不需要修改原函数的内容,也不需要修改原函数的调用。这也称为元编程,因为程序的一部分试图在编译时修改程序的另一部分。Python中的所有内容都是对象。我们定义的名称只是绑定到这些对象的标识符。函数也不例外,它们也是对象(带有属性)。可以将各种不同的名称绑定到同一功能对象。
def first(msg):
print(msg)
first("Hello")
second = first
second("Hello")
当你运行代码时,这两个函数first和second给出相同的输出。在此,名称first和second指代相同的功能对象:

现在情况是不是感觉变复杂了点,可以将函数作为参数传递给另一个函数。这种以其他函数为参数的函数也称为高阶函数。这是这种函数的一个实例。
def inc(x):
return x + 1
def dec(x):
return x - 1
def operate(func, x):
result = func(x)
return result
print(operate(inc,3))
print(operate(dec,3))
程序的输出结果如下:

函数和方法被称为可调用的,因为它们可以被调用。
实际上,任何实现特殊方法__call __()的对象都称为可调用的。 因此,从最基本的意义上讲,装饰器是可调用的,可返回可调用的。
基本上,装饰器接受一个函数,添加一些功能并返回它。
def make_pretty(func):
def inner():
print("我被装饰了")
func()
return inner
def ordinary():
print("我是普通的函数")
print(ordinary())
print("-----------------------")
pretty = make_pretty(ordinary)
print(pretty())
程序的输出结果如下:

在上面显示的示例中,make_pretty()是一个装饰器,pretty = make_pretty(ordinary),函数ordinary()被修饰,返回的函数被命名为pretty。这是一个常见的构造,因此,Python具有简化此语法的语法。我们可以将@符号与装饰器函数的名称一起使用,并将其放置在要装饰的函数的定义上方。例如:
def make_pretty(func):
def inner():
print("我被装饰了")
func()
return inner
@make_pretty
def ordinary():
print("我是普通的函数")
print(ordinary())
就相当于
def make_pretty(func):
def inner():
print("我被装饰了")
func()
return inner
def ordinary():
print("我是普通的函数")
ordinary = make_pretty(ordinary)
print(ordinary())
在Python中,我们可以通过完成的function(*args, **kwargs)。这样,args是位置参数的元组,kwargs而是关键字参数的字典。这样的装饰器的一个实例是:
def works_for_all(func):
def inner(*args, **kwargs):
print("我可以装饰任何函数")
return func(*args, **kwargs)
return inner
@works_for_all
def test():
print("我被装饰了")
test()
程序的输出结果如下:

在Python中,我们还可以链接多个装饰器。一个函数可以用不同(或相同)的装饰器多次装饰。我们只需将装饰器放置在所需函数之上。
def star(func):
def inner(*args, **kwargs):
print("*" * 30)
func(*args, **kwargs)
print("*" * 30)
return inner
def percent(func):
def inner(*args, **kwargs):
print("%" * 30)
func(*args, **kwargs)
print("%" * 30)
return inner
@star
@percent
def printer(msg):
print(msg)
printer("Hello")
程序的输出结果如下:

链接装饰器的顺序很重要。如果我们按相反的顺序
def star(func):
def inner(*args, **kwargs):
print("*" * 30)
func(*args, **kwargs)
print("*" * 30)
return inner
def percent(func):
def inner(*args, **kwargs):
print("%" * 30)
func(*args, **kwargs)
print("%" * 30)
return inner
@percent
@star
def printer(msg):
print(msg)
printer("Hello")
执行的程序结果输出将如下:

迭代器
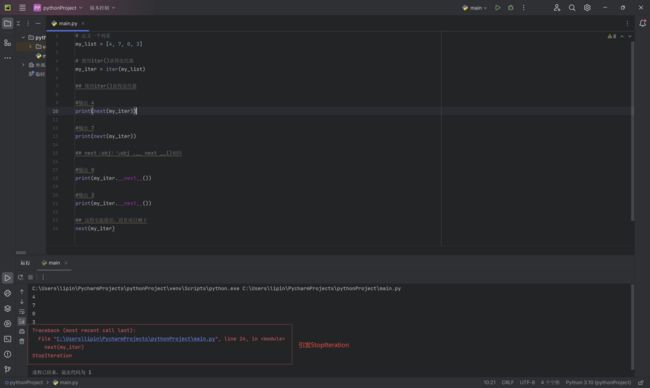
对于Python中的任意对象,只要它定义了可以返回一个迭代器的 _ iter_ 方法,或者定义了可以支持下标索引的 _ getitem_ 方法,那么它就是一个可迭代对象。对可迭代对象使用 _ iter_ 方法后,会返回一个迭代器。iter()函数(也就是__iter__()方法)从它们返回一个迭代器。我们使用该next()函数手动遍历迭代器的所有项目。 当我们到达末尾并且没有更多数据要返回时,它将引发StopIteration。 以下是一个示例:
# 定义一个列表
my_list = [4, 7, 0, 3]
# 使用iter()获得迭代器
my_iter = iter(my_list)
## 使用iter()获得迭代器
#输出 4
print(next(my_iter))
#输出 7
print(next(my_iter))
## next(obj)与obj .__ next __()相同
#输出 0
print(my_iter.__next__())
#输出 3
print(my_iter.__next__())
## 这将引起错误,没有项目剩下
next(my_iter)
以上实例输出的结果如下:
在Python中从头开始构建迭代器很容易。我们只需要实现这些方法__iter__()和__next__()。iter()方法返回迭代器对象本身。如果需要,可以执行一些初始化。next()方法必须返回序列中的下一项。在到达终点时,以及在随后的调用中,它必须引发StopIteration。这里,我们展示了一个示例,它将在每次迭代中为我们提供2的次幂。幂指数从0到用户设置的数字:
class PowTwo:
"""实现迭代器的类
二的幂"""
def __init__(self, max = 0):
self.max = max
def __iter__(self):
self.n = 0
return self
def __next__(self):
if self.n <= self.max:
result = 2 ** self.n
self.n += 1
return result
else:
raise StopIteration
a = PowTwo(4)
i = iter(a)
print(next(i))
print(next(i))
print(next(i))
print(next(i))
print(next(i))
以上实例输出的结果如下:

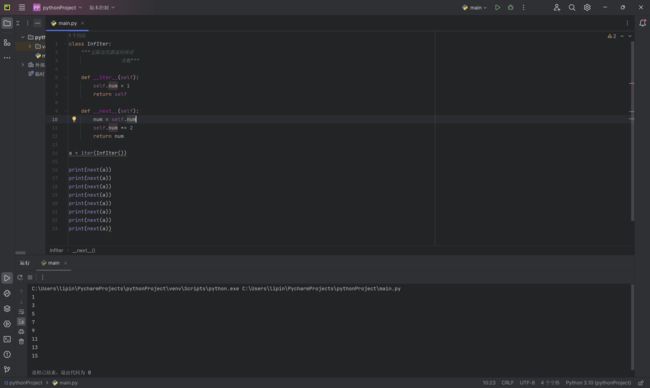
迭代器对象中的项不必耗尽。可能有无限的迭代器(永远不会结束)。在处理这样的迭代器时,我们必须小心。在这些类型的无限迭代器上进行迭代时,请小心包含终止条件。这是一个演示无限迭代器的简单示例:
class InfIter:
"""无限迭代器返回所有
奇数"""
def __iter__(self):
self.num = 1
return self
def __next__(self):
num = self.num
self.num += 2
return num
a = iter(InfIter())
print(next(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a))
运行结果如下:
生成器
用Python构建迭代器有很多开销; 我们必须使用__iter__()和__next__()方法实现一个类,跟踪内部状态,在没有要返回的值时触发StopIteration等等。这既冗长又违反直觉。生成器在这种情况下可以派上用场。Python生成器是创建迭代器的简单方法。我们上面提到的所有开销都由Python的生成器自动处理。
简而言之,生成器是一个函数,它返回一个对象(迭代器),我们可以对其进行迭代(一次一个值)。
生成器是动态生成的,当你要迭代的对象有非常多的元素时,使用生成器能为你节约很多内存
在Python中创建生成器非常简单。 就像使用yield语句而不是return语句定义普通函数一样容易。
如果一个函数包含至少一个yield语句(它可能包含其他yield或return语句),那么它就成为一个生成器函数。yield和return都将从函数返回一些值。
不同之处在于,当return语句完全终止一个函数时,yield语句会暂停该函数保存其所有状态,然后在后续调用时继续执行。
这是生成器函数与常规函数的不同之处:
-
生成器函数包含一个或多个yield语句。
-
调用时,它返回一个对象(迭代器),但不会立即开始执行。
-
像__iter__()和__next__()这样的方法会自动实现。因此,我们可以使用next()来遍历项目。
-
一旦函数产生了结果,函数就会暂停,控制就会转移给调用者。
-
局部变量及其状态在连续调用之间被记住。
-
最后,当函数终止时,在进一步调用时会自动引发StopIteration。
这是一个示例,用于说明上述所有要点。我们有一个my_gen()由几个yield语句命名的生成器函数:
# 一个简单的生成器函数
def my_gen():
n = 1
print('这是第一次打印')
# 生成器函数包含yield语句
yield n
n += 1
print('这是第二次打印')
yield n
n += 1
print('这是最后一次打印')
yield n
# 它返回一个对象,但不立即开始执行
a = my_gen()
# 我们可以使用next()遍历这些项.
next(a)
# 一旦函数产生了结果,函数就会暂停,控制就会转移给调用者。
# 局部变量及其状态在连续调用之间被记住。
next(a)
next(a)
# 最后,当函数终止时,在进一步调用时将自动引发StopIteration。
next(a)
这是以上实列的输出结果:
 我们可以直接将生成器与for循环一起使用。
我们可以直接将生成器与for循环一起使用。
这是因为,for循环接受一个迭代器,并使用next()函数对其进行迭代。当StopIteration被触发时,它会自动结束
# 一个简单的生成器函数
def my_gen():
n = 1
print('这是第一次打印')
# 生成器函数包含yield语句
yield n
n += 1
print('这是第二次打印')
yield n
n += 1
print('这是最后一次打印')
yield n
# 使用for循环
for item in my_gen():
print(item)
运行该程序时,输出为:
