论文阅读笔记:A survey of sketches in traffic measurement Design, Optimization, Application
论文阅读笔记:Information Fusion 2022: A survey of sketches in traffic measurement: Design, Optimization, Application and Implementation
文章目录
- 论文阅读笔记:Information Fusion 2022: A survey of sketches in traffic measurement: Design, Optimization, Application and Implementation
-
- I. Introduction
- II. 基于sketch的网络测量
-
- A. 被动测量挑战
- B. 网络测量性能需求
- C. sketch是完美选择
- D. Count-Min sketch作为举例
- III. 网络测量准备
-
- A. 测量环境准备
-
- 1) 监控器位置(Monitor Placement)
- 2) 流量重定向(Traffic Rerouting)
- 3) 流分布/分配(Flow Distribution/Allocation)
- B. 测量数据准备
-
- 1) 流量采样(Traffic Sampling)
- 2) 随机化处理(Randomization Processing)
- 3) 批处理(Batch Processing)
- IV. sketch结构的优化
-
- A. 哈希策略(Hashing strategy)
-
- 1)传统的基于哈希的数据结构
- 2) 基于学习的映射(Learning-based mapping)
- B. 计数器层优化(Counter level optimization)
-
- 1) 小计数器用于更大范围(Small counter for lager range)
- 2) 虚拟寄存器用于基数估计(Virtual register for spread estimation)
- 3) 偏度流量的分层计数器共享(Hierarchical counter-sharing for skewed traffic)
- 4) 可变宽度计数器为空间效率(Variable-width counters for space efficiency)
- 5) 为更少的内存访问进行的优化(Optimization for less memory access)
- 6)计数器更新策略为了更好的准确性(Counter update strategies for higher accuracy)
- 7) 为各种功能增加插槽(Slot enforcement for various functionalities)
- C. Sketch层优化(Sketch level optimization)
-
- 1) Multi-layer composition
- 2) 多个sketch组合(Multi-sketch composition)
- 3) 滑动窗口设计(Sliding window design)
- V. 后处理级别的优化(Optimization in Post-processing Stage)
-
- A. sketch压缩和合并技术
-
- 1) Sketch压缩(Sketch compression)
- 2) Sketch merging
- B. 流键提取技术(Techniques for information extraction)
-
- 1) 流键可逆技术(Flow key reversible techniques)
- 2) 基于概率理论的技术(Probability-theory-based techniques)
- 3) 机器学习技术(Machine learing techniques)
- VI. 应用和实现(Application and Implementation)
-
- A. 测量任务(Measurement tasks)
-
- B. 硬件或软件实现(Hardware or Software implement)
- VII. 开放问题(open issues)
这篇文章从网络测量的整个完整过程进行介绍,主要包括:网络测量的准备环节(监控器位置、流量重定向、流分布)、测量数据准备(流量采样、随机化处理、批处理)、sketch结构优化(传统基于哈希的结构、基于学习的映射、计数器层的优化、sketch层的优化)、后处理级别的优化(sketch压缩、sketch合并、信息提取、流键可逆、基于概率理论、机器学习)、应用和实现(13种测量任务、硬件和软件实现),每个过程中涉及到sketch结构的变种,覆盖多于90种sketch设计。
由于网络流的海量、高速、不可预测特征,sketch在测量节点中被广泛实现用于近似记录流的频率或基数。sketch维护一个或多个计数器数组,根据哈希函数将相应流映射到计数器。来自于分布式测量节点的sketch会被聚合以提供流统计信息。
I. Introduction
网络测量可应用场景:网络管理、网络更新、网络维护、网络防御、负载均衡、路由、公平性、指令检测、缓存、流量工程、性能诊断、策略执行。
有效网络测量既需要聚合的统计信息也需要单流统计信息,包括:
- 流基数(flow cardinality):不同流的数量。
- 流大小(flow size):一个流拥有的包数量。
- 流体积(flow volume):特定流量所贡献的流量体积。(不清楚)
- 时间信息。
有关网络流量测量方向的综述:

- G. Cormode and M. Hadjieleftheriou, “Methods for finding frequent items in data streams,” VLDB J., vol. 19, no. 1, pp. 3–20, 2010.
- G. Cormode, “Sketch techniques for approximate query processing,” in Synposes for Approximate Query Processing: Samples, Histograms, Wavelets and Sketches, Foundations and Trends in Databases. NOW publishers, 2011.
- Z. AP, C. G, and G. XJ, “High-speed network traffic measurement method,” Ruan Jian Xue Bao/Journal of Software, vol. 25, no. 1, pp. 135–153, 2014.
- A. Yassine, H. Rahimi, and S. Shirmohammadi, “Software defined network traffic measurement: Current trends and challenges,” IEEE Instrum. Meas. Mag., vol. 18, no. 2, pp. 42–50, 2015.
- P. B. Gibbons, “Distinct-values estimation over data streams,” in Data Stream Management - Processing High-Speed Data Streams, 2016, pp. 121–147.
- Q. Yan, F. R. Yu, Q. Gong, and J. Li, “Software-defined networking (SDN) and distributed denial of service (ddos) attacks in cloud computing environments: A survey, some research issues, and challenges,” IEEE Commun. Surv. Tutorials, vol. 18, no. 1, pp. 602–622, 2016
sketch是一种概要数据结构,近似记录流中项目频率或估计基数。sketch根据流键将每个包哈希到一组cell或计数器,为被动测量任务提供了一种记录活跃流存在和统计信息的有效方法。
sketch优势:1. 空间小 2. 时间少 3.准确高
问题1:flow volume到底是什么?流体积/流容量?是包含的字节数?
问题2:所谓的Collaborative traffic measuremnt是什么?是不是分布式测量节点多个节点进行协同呢?
问题3:per-flow measurement到底是什么?是单条流的测量吗?
论文框架
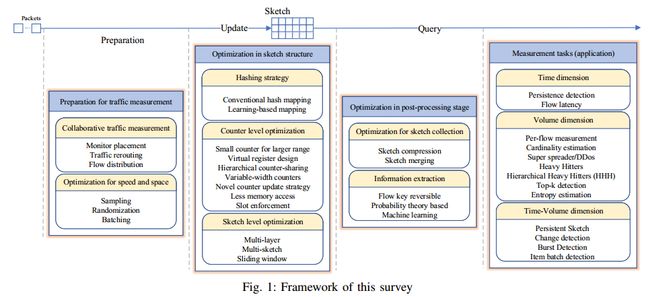
从数据记录层到信息提取层,sketch结构核心组件是更新策略、数据结构设计、查询策略、启用的功能。因此从3个维度:基于sketch网络测量的准备、sketch数据结构的优化、后处理级别的优化。
II. 基于sketch的网络测量
测量网络性能有两种方法:主动测量和被动测量。
- 主动测量:通过在网络路径上发送一系列探测报文连续测量网络流量。可测量单向延迟、往返时间RTT、平均丢包率、连接带宽、调整转发政策。主动测量优势:提供不同粒度端到端QoS测量并且是灵活的,可以测量想要的东西。缺陷:频繁发送探针可能导致巨大测量开销会扰乱关键流量。
- 被动测量:无需发送探针包,通过遍历测量节点监控流量收集统计信息。应用场景:总结流级或包级流量、估计流量/包大小分布、评价不同属性网络流量细粒度大小、基于使用的收费。优势:识别异常流量模式简化网络管理任务,例如:流量工程、负载均衡、入侵检测。无需创造或修改任何流量。
flowkey:流键、流标识符,一般用5元组定义。包括:源ip(32bits)、目的ip(32bits)、源端口(16bits)、目的端口(16bits)、协议类型(8bits)。即f=
A. 被动测量挑战
- 资源限制:主要是硬件资源的空间和速度的矛盾。关键挑战是如何在一个小型高速存储器上有效进行测量任务。现在路由器直接通过网卡进行转发包,速度很快,为了赶上这样的高速,测量任务被期待进行在SRAM上。然而SRAM空间有限,并且被所有线上网络功能所共享,例如:路由、管理、性能、安全。因此对于测量任务可获得的空间是有限的。
- 流不可预测性:流高速特征使得准确记录流量大小困难;流的不均匀分布和偏度特征进一步聚集测量任务。流大小/体积(size/volume)呈现齐夫分布(zipf)或幂律分布(power-law)。大多数流的大小是小的,称作鼠流。一小部分的流的大小非常大,称作大象流。对于网络测量任务而言,大象流比鼠流更重要。因此,每个计数器的大小应该能够准确记录最大流的大小,但网络管理员提前不知道大象流的大小,使得设置每个计数器的大小棘手的。
B. 网络测量性能需求
- 高准确性:现存方法提供近似结果,给出理论保证,估计结果有相对误差,置信概率。新的更新策略和多层sketch可提高准确性。
- 内存有效率性:巨大数量的流会通过网络设备,内存空间是重要因素,高内存使用量加重芯片占用、热量消耗,耗尽共存应用的内存。采样策略可减小空间开销。
- 实时响应:Counter Braids在查询特定流之前,必须提前获取所有流的信息,解码需要在线下以一种批处理方式执行。查询速度极大减慢。
- 快速单包处理:高处理速度的主要挑战来自高线路速率、现代网络的大规模和频繁的内存访问。硬件实现更喜欢在TCAM或SRAM中运行算法,而不是在DRAM中运行算法,以获得更好的高速处理。软件实现可基于SDN(软件定义网络)或NFV(网络功能虚拟化)。
- 分布式可拓展性:由于单台交换机的空间限制,建议部署协同流量测量系统,每台交换机只负责网络中一部分底层流量。
- 通用性:一个通用的基于sketch的测量方法意味着同时支持大多数的测量任务。
- 可逆性:传统sketch设计不能从计数器返回相应的流标签,想要使得sketch可逆,并且能够直接从sketch识别感兴趣的流。
C. sketch是完美选择
基于sketch的网络测量属于被动网络测量,不会导致网络的任何开销因为不发送探针包。分为两步:1. 分布式测量节点承接任务并被动收集相应流量统计信息。2.控制器从下属的监控器合并测量结果,并相应测量查询。

基于sketch的网络测量关注的是在一个通道中使用小的工作内存处理长流量数据包,以近似地估计流量/数据包的特定统计信息。用估计的计数器代替精确的数字是基于sketch的测量的固有特征,在内存占用和估计准确性间权衡。
直接计数和记录活跃流会导致高内存访问和计算开销,基于sketch的方法通常在固定时间内将流键映射到具有多个桶/单元格的表中。相应的桶/单元将存储有关流的相关信息,以便在常量时间内进行后续查询。
基于sketch算法有两个基本操作:更新和查询。以及合并操作。测量的时候更新流的计数器,后面的查询用于更高层的网络分析。不同的sketch提供不同的更新和查询策略。
D. Count-Min sketch作为举例
Count-Min sketch应用最广,可用来进行per-flow measurement, heavy hitter detection, entropy estimate, inner-product estimation, privacy preserve, clustering over a high-dimensional space, personalized page rank。支持查询有:heavy hitters, flow size distribution, top-k detection。
CM sketch优势:可以表示高维数据(如5元组流键空间),并在恒定时间内响应点查询,具有很强的精度保证,有效地处理插入或删除形式的更新,能够在流量下以高速率工作。增加哈希函数的范围或哈希函数的数量可以提高摘要的准确性。由于这种线性,CM草图可以缩放、添加和减去,以生成相应缩放的网络流量的摘要。**劣势:**由于哈希的不可逆过程,CM sketch不支持流键的可逆性。
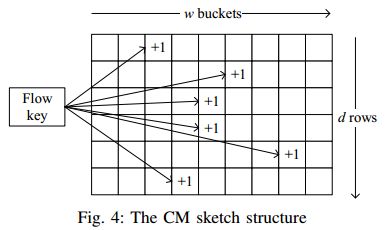
CM sketch哈希任一个流到哈希表的每一行,利用相应的计数器记录流大小信息。它由d个数组组成A1,A2,…Ad; 每个数组包含w个计数器。当测量网络流时,每个流键从包报头提取出来,通过d个独立哈希函数进行哈希h1,h2…hd, 后面d个相应的计数器添加相应的流大小。查询一个流f的大小,CM sketch返回d个计数器中最小值作为估计值。
时间复杂度:因为计算每个哈希函数花费O(1)常数时间,进行一次更新的总时间是O(d),跟宽度w独立。在精度保证情况下,CM sketch产生高估误差。

III. 网络测量准备
测量模块作为软件被集成在交换机内部,或者部署作为一个独立的测量硬件嵌入在通信链路中。由于每个监视器的每包操作成本主要取决于线路速度,因此在有限的资源下对高速流量进行网络测量是非常重要的。为了减少计算和存储开销,有必要对流量数据包进行预处理。
A. 测量环境准备
1) 监控器位置(Monitor Placement)
为了保证全网覆盖,以往的工作主要集中在监控器在全网的优化部署上,目标是最大化测量效用,例如:被测流量的覆盖和测量功能效率,最小化测量成本。最优策略包括流量路由路径或整个测量网络中测量点的最优分配。

现在部署在运营网络中的路由器已经装备了测量模块(例如:Netflow, Openflow)。测量点放置问题主要研究测量功能无动力情况下的最优放置策略或测量有动力情况下的测量激活问题。作为协同测量的核心,这些工作对于建立基于sketch的测量环境至关重要。聚焦于在网络中最优的测量点放置问题。
现有的解决方法有:Minimum Edge Cost Flow(MECF)[47], OpenTM[36]等。
2) 流量重定向(Traffic Rerouting)
存在问题:流量特征和测量任务都可以随着时间的推移而动态变化,因此,对于当前网络状态来说,先前最优的测量点位置可能不是最优的。现有解决方法有:MeasuRouting[38], Measurement-aware Monitor Placement and Routing(MMPR)[37], Dynamic Measurement aware Routing(DMR)[50]。
问题4:Traffic rerouting到底是什么?是不是重新选择路由路径的意思
3) 流分布/分配(Flow Distribution/Allocation)
流分布/分配问题是如何分配流到测量节点或者交换机以确保负载均衡和测量完成度。DCM[44]、OpenWatch[39]和LEISURE[40]侧重于测量负载平衡策略的制定。而基于哈希的工作[41][42][46]则致力于策略的轻量级实现。
现存方法有:Distributed and Collaborative Monitoring system(DCM)[44]、OpenWatch[39]、Load-EqualIzed meaSUREment(LEISURE),利用哈希函数平衡分配流时的计算和空间开销的方法有:cSamp[41]、cSamp-T[42]、DECOR[43]。Probability Assignment for Ingress Switches(PAIS)、Network-wide Switch Probability Assignment(NSPA)不清楚是什么。
参考文献[46]中提出的方法是完成流量分配问题的最轻量级策略。通过将不同的哈希范围分配给一系列交换机,NSPA可以在链路上将责任优雅地分配给交换机。处理开销最多为每个数据包执行一次哈希操作实现采样,空间开销仅为单个采样概率值p。
H. Xu, S. Chen, Q. Ma, and L. Huang, “Lightweight flow distribution for collaborative traffic measurement in software defined networks,” in Proc. of IEEE INFOCOM, April 29 - May 2, 2019 Paris, France, pp. 1108–1116.
B. 测量数据准备
存在问题:在高速网络中对每个数据包进行测量是一项巨大开销的任务,有3种方法可减小处理开销:采样(sampling), 批处理(batch processing), 随机化(randomization)。
1) 流量采样(Traffic Sampling)
网络测量工具**NetFlow[48], sFlow[52]**对网络流采样以节省资源和快速处理。问题:因为许多流丢失了导致低的估计精度。如果记录每条流,为每条流保持信息,可以获得所有流的准确大小,但处理、空间开销巨大。流采样(flow sampling):给定采样概率p(0
为了实现恒定的相对误差,小的流量值以高概率递增,大的流量值以低概率递增。(小的流量数量多,采样率高;大的流量数量少,采样率小)。参考文献[53] 设置包采样率是流大小的递减函数,增加了小流的包采样率,降低大流包采样率。Sketch guided sampling(SGS) 采用counting sketch估计所有流近似大小。Adaptive Random Sampling[54] 将抽样误差(相对估计误差)限制在预先规定的容差范围内,提出一种自适应随机抽样技术调整抽样概率并最小化样本数量。Adaptive Non-Linear Sampling(ANLS)[55] 以采样概率函数p©更新sketch的计数器,给出如何选择p©原则。ANLS初衷是对小流量实现大采样率,而对大流量实现小采样率。Self-tuning ANLS[56] 根据ANLS原则选了一个特定的采样函数。DISCO[16] 扩展了ANLS,将计数器值调节为实际流量长度的实递增凹函数,以同时支持流量大小计数、流量体积计数和流量字节计数。Independent Counter Estimation Buckets(ICE-Buckets)[57]提出一个优化估计函数用于确定概率和估计计数器真实值,将流量分成不同的桶,并根据每个桶的计数范围配置最优估计函数,从而有效利用多个计数器,显著降低整体误差。SketchFlow[51] 通过识别流的sketch饱和事件并仅对饱和数据包进行采样来实现,只是一个通用的采样器策略,不能用于单独测量流量。
采样是减少每流测量(per-flow measurement)的最佳策略,从均匀采样(uniform sampling)、自适应采样(adaptive sampling)到分离估计桶策略(separated estimated-bucket strategy),估计精度在上升。
2) 随机化处理(Randomization Processing)
随机化处理是一种减少包处理开销的替代方法,其中只更新采样计数器。Randomized HHH(Hierarchical Heavy Hitters) 使用其各自的heavy hitter实例随机采样仅更新单个前缀,而不是为每个传入数据包更新所有前缀。NitroSketch通过几何采样只对一小部分数据包进行采样,并且采样的数据包需要进行一次哈希计算,更新到一行计数器,有时还需要更新到top-k结构。优势:为了赶上线路速率并减少处理开销,RHHH[58]和NitroSketch[59]都采用随机化策略来更新其sketch中的采样计数器。劣势:但相应的查询处理不完整的记录信息比较复杂,并且需要最小的数据包量来达到期望的准确性保证。
问题5:这个随机化处理原理没搞明白
3) 批处理(Batch Processing)
批处理的灵感是将同一流的数据包聚集在一起,然后将它们作为一个整体更新,以减少总体计算开销。Randomized DRAM-based counter scheme:通过查找缓存来查看是否已经有一个等待更新请求到相同的计数器来获取新的计数器更新。Agg-Evict利用缓存优势,提出了一种底层机制来提高各种方案的效率。

Skimmed Sketch和Augmented Sketch(ASketch) 专注于聚合过滤器中最频繁的项目,并将不频繁的项目驱逐到第二层。Cold filter在第一个过滤器捕捉cold items, 驱逐hot items到第二层。
批处理的核心思想是将特定流的入站数据包分批处理,然后将其整体更新到概要数据结构中。优势:对草图的内存访问就大大减少。劣势:该策略需要增加一个额外的缓存来维护以前数据包流的信息。
综上,通过准备环境,在考虑测量成本的情况下,将每个监测器最佳地放置或激活在相应的测量点,以获得最佳的测量性能,并且他们都被分配了度量任务的责任。通过数据准备,各测量点在原始流量流上执行相应的策略,减少测量开销。抽样和随机化都必须在准确性和处理开销之间取得平衡。
IV. sketch结构的优化
sketch负责记录活动流和相应的大小或体积信息。将流信息记录在sketch中,以便后续在更新阶段进行信息检索和提取。sketch优化包括3方面:1)hashing strategy, 2)counter level optimization, 3)sketch level optimization。
A. 哈希策略(Hashing strategy)
sketch算法需要一个可行的空间来存储计数器和一个流到计数器的关联规则,以便到达的数据包能够以线速(line speed)更新相应的计数器。哈希策略包含传统的基于哈希的数据结构和基于学习的哈希策略。
1)传统的基于哈希的数据结构
基于哈希的频率估计: CM Sketch、Bloom Filter、Cuckoo filter可作为频率估计的哈希基础。CM Sketch包含d个数组,每个数组包含w个计数器,哈希即将到来的包到哈希表的每一行,在每一行定位到一个计数器更新多重性或大小信息。Bloom Filter利用向量中的k位来表示集合中元素的隶属关系,具有常数的时间复杂度和空间效率,不支持流的删除和记录流的多重性(size)。Counting Bloom Filter(CBF) 将向量中的每个位替换为多个位的计数器。当将流映射到单元格中时,k个计数器按流大小增加。通过减少k个对应计数器直接实现元素的删除。Cuckoo filter(CF) 是一个有b个桶的哈希表,每个桶有w个槽,最多容纳w个元素。在cuckoo filter中记录其fingerprint进一步表示元素,应用部分键策略在插入阶段确定候选桶,并在重新分配阶段定位候选桶。Group Testing将多个项目组合成一组,找出活跃项目。它首先决定项目属于哪个组,然后更新这些组计数器。Fast Sketch它将每个传入的数据包散列到几个预定义的行中,并将其大小添加到每行中的第一个计数器中。之后,相应的计数器还根据流量商的位表示来添加流量大小。SketchLearn采用位映射策略从多级sketch中提取大流量,并为小流量留下剩余计数器,形成高斯分布。XY-Sketch研究了分解重组框架,将项目频率估计问题转化为概率估计问题。

问题6:fingerprint到底是什么,他和flow key有什么区别?
基于哈希的基数估计:基数:统计流中不同元素的数量。Bitmap将所有流均匀地映射到位数组中,通过将每个元素编码为位数组的索引,可以自动过滤重复元素。然而,该策略的空间与基数是线性的。其他方法:PCSA、LogLog、HyperLogLog、HLL-TailCut+、Sliding HyperLogLog。
Zhou等人提出一个广义的sketch框架,包括bSketch(基于counting bloom filter)、cSketch(基于CountMin)和vSketch(基于内存共享机制),旨在将sketch设计纳入一个通用的实现结构下,具有即插即用的灵活性和多种权衡选择。
2) 基于学习的映射(Learning-based mapping)
结合基于学习的方法例如:k均值聚类和神经网络与哈希表可以降低空间开销,提高精度。
Bertsimas等人提出混合整数线性优化公式和一种高效的块坐标下降算法,计算所见流的接近最优散列方案。Fu等人通过建立k-means聚类的sketching误差与近似误差之间的理论等价关系,提出了一类位置敏感sketch(locality-sensitive sketch, LSS)。Hsu等人结合了神经网络来预测每个流的数据包计数日志。该算法将heavy flow与non-heavy flow分开记录,以减少它们之间的干扰。Aamand提供了CM Sketch产生的预期误差的简单严密分析,以及标准版本和学习版本的CSketch的第一个误差界限。
基于学习的sketch展现了测量的新趋势,未来将有很大一部分这样工作。**优势和劣势:**尽管基于学习的映射导致较少的空间开销,但这种设计的实现需要大量的计算资源,这对于计算稀缺的情况可能不可取。
B. 计数器层优化(Counter level optimization)
由于片上内存有限,如果sketch中的计数器使用很多位,则计数器的数量会少,导致估计精度差。在这种情况下,由于鼠流数量占据优势,大多数计数器只记录鼠标流;因此,那些未使用的比特就被浪费了。如果计数器只使用很少的位,sketch就不能去存储大象流了。
1) 小计数器用于更大范围(Small counter for lager range)
使用一个小计数器来保持大数的近似计数是节省空间的,因为由此产生的预期误差可以相当精确地控制。基于此的方法有:Approximate Counting, Count-Min-Log Sketch, SAC, SA。
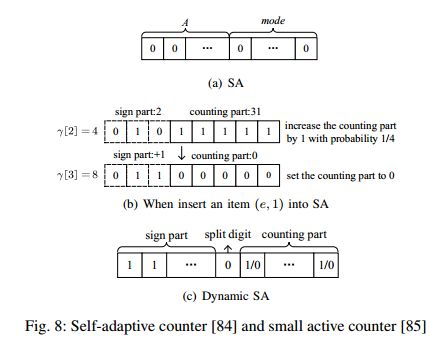
传统的草图使用基于二进制的计数器来记录流的频率。一旦收到相应的数据包,计数器就增加1。CML Sketch用基于对数的计数单元取代了经典的基于二进制的计数器,基于log的计数器以预定义的概率x^−c增加,其中x是对数基数,c是当前估计,不支持删除。**Small active counters(SAC)**将单元分为两部分:k位估计部分a和l位指数部分mode。ActiveCM使用了压缩计数器的一种变体,并扩大了32位计数器的最大计数范围,远远大于2^32。Self-Adaptive counters(SA) 是一种更加通用的适应不同计数范围的技术。Dynamic SA(DSA) 增加一个分割位并且动态调整标志位。DSA可以准确地记录鼠流,同时能够处理象流。
2) 虚拟寄存器用于基数估计(Virtual register for spread estimation)
聚焦于基数估计,旨在记录与主机的不同连接,并采用基数估计寄存器(cardinality estimation register)来解决DDos,端口扫描(port scan)和超级传播器检测(super spreader detection)。
寄存器共享(register-sharing): Virtual HyperLogLog Counter(VHC) 在一个共享池中共享HLL寄存器来测量流大小。VHC包含在线编码模块,用于实时记录数据包,离线估计模块根据在线模块记录的计数器对所有流的大小进行测量。Virtual Register Sharing:通过从多比特寄存器池中随机选择几个寄存器来动态地为每个流创建一个估计器,以估计大象流的基数。寄存器空间得到充分利用,寄存器数组是物理的,而估计器是逻辑的,并且是动态创建的,没有额外的内存分配。
问题7:super spreader怎么翻译啊,超级传播者?

比特共享(bits-sharing). Compact spread estimator(CSE) 通过从可用的共享比特池中获取比特,为每个源创建一个虚拟比特向量。它计算每个SrcIP的不同DstIP的数量,可以抽象为线性计数的多集版本。
寄存器共享和位共享都使用公共内存空间构造虚拟估计器。使用紧凑的内存空间可以在较大的范围和合理的精度保证下估计基数。
3) 偏度流量的分层计数器共享(Hierarchical counter-sharing for skewed traffic)
在传统的sketch中,所有的计数器都被分配了相同的大小,并进行了定制,以适应最大的流量。然而,大象流只占流量的一小部分。因此,传统sketch中大多数计数器的高阶位都被浪费了,这种浪费导致空间效率低下。Counter Braids、Counter Tree、Pyramid Sketch、One memory access Sketch (OM Sketch)和Diamond Sketch设计了hierarchicla counter sharing方案来记录流量大小。将计数器组织成一个层次结构,其中较高层拥有较少的内存。底层计数器主要记录鼠流的信息,高层计数器记录底层溢出的次数(大象流大小的有效位)。

Counter Braids通过将随机图的计数器分层“编织”,将计数器压缩成多层。Counter tree是一种二维计数器共享方案,包括水平计数器共享和垂直计数器共享。物理计数器在逻辑上以多层树形结构组织,组成一个新的大型虚拟计数器。在垂直计数器共享中,不同的子计数器可以共享相同的父计数器。在水平计数器共享中,虚拟计数器在不同的流之间共享。Pyramid Sketch设计了一个框架,在不需要提前知道最热门项目的频率的情况下,既可以防止计数器溢出,又可以同时实现高精度、更新速度和查询速度。它由多个计数器层组成,每层都有上一层的一半计数器。第一层只有记录多重性的纯计数器,其他层由混合计数器组成。OM Sketch有多层,计数器数量递减。当第一次发生溢出时,将设置底层计数器中的标志。为了缓解最坏情况下的速度下降,OM sketch只需要一个两层计数器数组来记录多重信息。OM Sketch利用word constraint在一个或几个机器字中约束相应的散列计数器。Cold Filter包括两个计数器层。当下层计数器溢出时,Cold fitlet不会改变下层计数器,并且不取标志位。Cold Filter采用one-memory-access strategy来处理内存访问瓶颈。
4) 可变宽度计数器为空间效率(Variable-width counters for space efficiency)
Counter resizablity. Spectral bloom filters(SBF) 将BF的位向量扩展为计数器向量。计数器一个接一个地打包,通过分层索引结构定位,以便快速访问内存。导致计数器i宽度增长的更新将导致计数器i+1, i+2,···的移位,这可能具有全局级联效应,当可能有数百万个计数器时,这会使其成本过高。Bucketized Rank Indexed Counters (BRICK) 采用了一种复杂的变宽计数器编码,它使用固定大小的bucket和Rank Indexing Technique来支持限制计数器总和的变长计数器。
Bucket Expandability. TinyTable将空间重新组织为链接的fingerprints和计数器。对于fingerprints和计数器使用相同的块,Tinytable链将计数器和fingerprints关联起来,其中每个链总是以一个fingerprints开始。Counting Quotient Filter(CQF) 在商过滤器(quotient filter)中增加了可变大小的计数器。使用一个“escape sequence”来确定一个slot是否包含计数器的剩余部分或一部分,以及该计数器使用了多少个slot。
Bits borrow or combination. Adjacent Borrow and Carry(ABC) 可以通过借用相邻计数器的位或者将映射的计数器与其相邻计数器组合成一个大计数器来提高内存效率,但代价是3位来标记组合计数器。Self-Adjusting Lean Streaming Analytics (SALSA) 通过合并邻居以表示更大的数字来动态地重新调整计数器的大小。与ABC相比,SALSA只需要一个比特就可以标记组合计数器,编码效率更高。其他的技术:bit-shifting expansion、rank-index-technique、bit-borrowing/combination、fingerprint-counter chain均提供可变大小计数器。
5) 为更少的内存访问进行的优化(Optimization for less memory access)
虽然sketch可以提供多个共享计数器的估计,但它们不能同时实现高精度和线速。访问多个计数器需要多次内存访问和哈希计算。频繁的内存访问可能成为基于sketch的测量的瓶颈。
OM Sketch利用word acceleration策略将相应的计数器限制在一个或多个机器字中,并为每次插入实现近一次内存访问。Cold filter提出one-memory-access策略来访问底层L1。Recyclable Counter with Confinement (RCC) 将虚拟向量限制在一个内存块上,因此只需要访问一个内存块就可以读写虚拟向量。Cuckoo counter将每个桶配置为64位。此外,为了有效地处理偏度数据流,Cuckoo counter实现了长度不等的entries,以隔离老鼠流和大象流。
6)计数器更新策略为了更好的准确性(Counter update strategies for higher accuracy)
CM-Sketch variants. Conservative update尽可能少地增加计数器,由于点查询返回所有d值中的最小值,CM应该只在必要时更新计数器,避免了不必要的计数器值更新,以减少高估问题。CM-CU sketch也应用了保守更新方法。SBF使用minimum increase方案进行优化,更倾向于保守插入,即只增加最小的计数器。Count Sketch(CSketch) 为第k个数组引入了另外一个哈希函数g()映射流到{+1,-1}。Count Sum estimation Method(CSM sketch) 将hot items分割成小块存储到小计数器中。流被散列到l个计数器中,流大小被划分为l个大致相等的份额,每个份额存储在一个计数器中。
Top-k detection. Randomized admission policy (RAP)和Frequent通过一个随机方法更新固定的键值表用于top-k识别和频率估计。当表已满时,RAP以1 /(cm+1)的概率踢出有最小计数器值cm的项目c。Frequent减少所有计数器并驱逐零数流,为新元素腾出空间。Space Saving总是直接剔除有最小计数的项目。Unbiased space saving有比Sample and Hold更加鲁棒的频率项估计性能,可以对任意子集和(subset-sum)给出无偏估计。CountMax和MV-sketch采用the majority vote algorithm多数投票算法(MJRTY)来跟踪每个bucket中的候选heavy flow。当收到的数据包与记录的相同时,相应的计数器将增加;否则,降低。HeavyKeeper和HeavyGuardian利用一种叫做exponential-weakening decay的概率方法。当到来的项目不匹配存储的项目时,流大小将以一定概率衰减。因此,大象将被储存在桶中,而鼠流将以高概率衰减并被替换。核心思想是将每个元素视为hot items,并将它们插入top-k数据结构中。数据结构空间用完后,以一定的概率逐步剔除cold elements。
Various-hash design. Weighted Bloom Filter根据查询频率及其作为成员的可能性为每个元素分配ke散列函数。Frequency-aware Counting(FCM)解决了低频流不准确的问题。FCM通过动态识别低频率和高频流项目,为每个项目使用许多散列函数。低频率和高频率项目由MG counter分类,该计数器跟踪唯一项目的计数。
7) 为各种功能增加插槽(Slot enforcement for various functionalities)
通过增加时间戳、数据包报头字段计数器(packet-header field counter)或键异或单元格(key-XOR cell),sketch可以支持延迟检测(latency detection)、heavy hitter traction和键枚举(key-enumeration)功能。
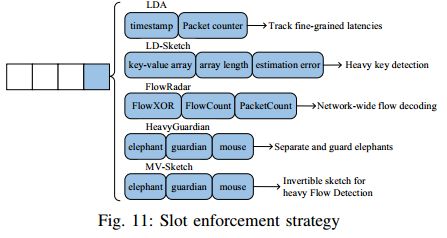
Latency detection. Lossy Difference Aggregator(LDA) 被设计用于测量短时间尺度上的数据包丢失和延迟。LDA在数组中维护时间戳累加器-计数器对。根据hash函数将报文分组。对于每个组,发送给接收者的是时间戳的总和和数据包的总数。优势: LDA通过只传输时间戳和数据包计数器的总和,大大降低了测量开销。劣势: 当数据包丢失或在一个组中重新排序时,整个组应该被丢弃;因此,这样一个群体的延迟无法估计。
Heavy hitter traction. LD-Sketch为每个桶Si,j增加了一个额外的组件: Ai,j,一个关联数组,用于跟踪散列后的heavy键候选项,以及三个参数:Vi,j按每个传入流的大小递增; Li,j,数组的最大长度; ei,j,哈希到桶的键的真实和的最大估计误差。RL-Sketch使用强化学习来剔除琐碎的流,同时留下heavy key候选流。MV-Sketch用三个组件增加每个桶: Vi,j,散列到桶的所有流的值的总和; Ki,j当前候选heavy flow key在桶中;Ci,j,表示是否应保留或替换候选heavy flow。HeavyGuardian将每个桶扩大以存储多个键值对作为heavy part,几个小的计数器作为light part。heavy part用于精确存储hot items的频率,light part用于近似存储cold items的频率。
Key-reversible functionality. FlowRadar拓展了Invertible Bloom Filter(IBF) 使用3个字段:FlowXOR,PacketCount,FlowCount。它记录流的数量和已散列到的数据包的数量,并将相应的流标识符xor在一个单元中一起记录。通过用其他字段增加计数器,sketch可以支持各种功能。
问题8:Slot enforcement是什么?是提供更多的插槽进而sketch可以提供更多的功能吗
C. Sketch层优化(Sketch level optimization)
sketch层优化可分为multi-layer composition、multi-sketch composition、sliding window design。通过将多个基本单元或不同的sketch巧妙地组合在一起来扩大sketch功能。
1) Multi-layer composition
For entropy estimation. Defeat利用流量特征经验分布的熵来检测异常的流量模式。它将异常视为这些特征的异常分布。Intersection Measurable Property (IMP Sketch) 指出OD流的熵可以通过OD流的两个不同Lp范数(Lp1, Lp2,)的函数来估计。IMP可以从A和B的sketch中推导出A和B两条流相交的熵。

For more accurate. Diamond Sketch将原子sketches(计数器数组)分为递增部分(increment part)、进位部分(carry part)和删除部分(deletion part)三部分。增量部分记录流的大小。进位部分记录每个流的溢出深度。删除部分用于支持删除。Slim-Fat(SF sketch) 在本地监视器向远程控制器传输信息时,采用小-大sketch组合来放松带宽需求。大sketch用于在插入和删除时辅助小sketch,以提高在有限空间内的准确性。Multi-Resolution Space-Code Bloom Filter (MRSCBF) 采用多个scbf,但在不同的采样分辨率下工作。SCBF可以将流量流近似地表示为一个多集。在不同的采样概率下,高分辨率SCBF对低多重度元素进行估计,而低分辨率SCBF对高多重度元素进行估计。
For reversible design. SketchLearn维护了l +1层sketch,每一层对应一个由r行c列的计数器矩阵组成的sketch。0层sketch记录所有包的统计信息,k层记录流键的第k个比特的信息。Reversible connection degree (RCD Sketch) 是定位大连接度主机的一种新的数据流方法。利用数论的余数特性,可以准确地估计给定主机的入度/出度。Sequential Hashing构建可逆的多级哈希数组,用于快速准确地检测heavy items。思想是将key的heavy sub-bits组合起来可以有效地发现完整的heavy items’ key。Reversible Sketch和Sequential Hashing的更新成本都随着key长度的增加而增加。他们都利用位置信息来恢复他们sketch中的keys。
For universal sketching. Univmon维护了一个“L2-heavy hitter”(L2-HH)sketch实例的log(n)个并行副本,其中n是流量流中的唯一元素。Univmon创建长度递减的子流,因为第j个实例期望所有哈希函数的采样频率是第(j−1)个sketch的一半。ActiveCM+ 提出了渐进式采样技术,它只更新流f采样的最后一个sketch,而不是可变的多个子sketch。此外,渐进式采样还将矩估计误差降低了UnivMon的一半以上。
2) 多个sketch组合(Multi-sketch composition)
For memory efficiency. Dynamic count filters(DCF) 扩展了SBF的概念,并通过使用两个过滤器提高了SBF的内存效率。它捕获了SBF和CBF的优点,SBF的动态计数器,CBF的快速内存访问。
For hot-cold separation. Probabilistic Multiplicity Counting(PMC)利用FM Sketch测量hot items,利用modified HitCounting估计cold items。Count-Min Heap为CM Sketch增加了一个堆结构,用来追踪所有heavy flows和他们估计的频率。如果到来的流的估计频率超过了阈值,他会被添加到堆里,或者当堆满了替换最小流。ActiveCM+ 也增加了一个最小堆(min-heap)来追踪top-k heavy hitters with each sub-sketch。

For filtering packets. Filtered Space-Saving(FSS)为Space Saving增加了一个预过滤方法。位图(bitmap)用于过滤和最小化测量列表上的更新。当一个新项目进入时,位图计数器(bitmap counter)首先检查位图中是否已经有测量过的项目;然后搜索测量表,看看这个元素是否已经存在。ASketch增加了一个预过滤级(pre-filtering)来识别大象流,并留下鼠流到sketch。基于底层流的偏度,ASketch通过更早地过滤掉最频繁的项目来提高频率估计的准确性。Bloom Sketch是由多层sketch+BF组成。低层负责低频项目,高层处理那些不能被低层sketch计数的项目。Sketctree包含多个过滤器,每个过滤器都与一个特定的任务相关联,以有效地测量大象流和汇总鼠流。
3) 滑动窗口设计(Sliding window design)
传统的基于sketch的方法侧重于从流量流开始估计流量大小/体积 (landmark window model) ,随着时间的推移,通过监视器的数据包越来越多,sketch空间不足,需要定期重置,这是该模型固有的缺点。对于许多实时应用程序,流的最新元素比很久以前到达的元素更重要。这一要求产生了滑动窗口sketch模型(sliding window sketch-model)。滑动策略基于基于sektch的方法,当新元素到来时将旧元素移除,从而始终保持数据流中最近的W个元素。
First-in-first-out design. Sliding HyperLogLog旨在估计最后w单位时间内不同流的数量,其小于时间窗口w。维护到达时间戳列表以及与数据包相关的散列值的二进制表示中最左边1bit的位置,以记录w时间单位内最近数据包的信息。Sliding Window Approximate Measurement Protocol(SWAMP) 将flow fingerprints存储在循环缓冲区中,频率保存在TinyTable[101]中,周期对应于一个测量窗口W。
Partitioned blocks design. 通过使用分区块来记录信息,sketch可以在最老的块中随机执行老化操作,并在最新的块中更新操作。Hokusai在不同的时间间隔使用了一系列CM Sketch。它对最近的间隔使用大sketch,对较早的间隔使用小sketch,以便在有限的空间内适应误差。Window Compact Space-Saving(WCSS) 将流量分成大小为W的帧,它为与当前窗口重叠的每个块维护一个队列。当一个块不再与窗口重叠时,相关的队列将被删除。Segment Aging Counter Estimation(S-ACE) 使用多个数据概要来存储到达不同窗口段的元素。该设计可以保持窗口段之间的相对顺序和数据概要,提高删除正确过时元素的概率。HyperSight还应用了一个分区的Bloom过滤器来维护测试数据包行为变化的粗粒度时间顺序。然而,这种策略保留了太多的sketch,从而导致昂贵的内存开销。
Randomized aging design. Aging Counter Estimation(ACE) 保留最新的W元素,并对滑动窗口模型采用计数器共享思想。Memento是一组滑动窗口算法,用于解决单设备和全网设置下的HH和HHH问题。对于每个数据包,Memeto以一定的概率执行Full update operation(删除过时数据并添加新数据)或进行窗口更新(删除过时数据)。
Time adaptive updating. Ada-Sketch提出了一种时间自适应方案,其灵感来自于著名的数字杜比降噪过程(digital Dolby noise reduction procedure)。
Scanning aging design. Sliding sketch在每个单元格中维护多个计数器,并更新最新的计数器。与上述策略不同,滑动sketch采用扫描操作,通过在sketch上使用扫描指针来删除过时的内容。
在未来,我们相信基于学习的哈希映射(learned hash-map) 将在 流到计数器规则设计(flow-to-counter rules design) 中发挥重要作用,因为它具有更少的空间开销和哈希冲突错误。
V. 后处理级别的优化(Optimization in Post-processing Stage)
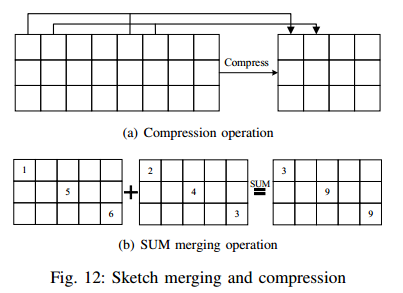
将流量数据记录在sketch后,还需要进行一些操作,才能从sketch中获得有价值的信息,如sketch压缩(sketch compression)、sketch合并(sketch merging) 等。此外,还提出了一些新的信息提取技术(information extraction techniques) 来丰富sketch的功能。
A. sketch压缩和合并技术
两个要求:(1)每个测量节点发送给采集器的填充sketch(filled sketch)的大小应该非常小; (2)压缩或合并的sketch应该包含足够的信息,使远程采集器能够准确地回答查询。
1) Sketch压缩(Sketch compression)
Compression for cardinality estimation. Arithmetic-coding-based compression使用算术编码分别以位和寄存器方式压缩FM sketch和HyperLogLog。压缩方案可以理解为表示值和显著较大的重复不敏感信息的分离。此方法仅适用于基数估计sketch,不满足压缩CM Sketches需要。
Compression for transformation. SF-sketch在单个测量点上保持一个fat sketch和一个slim sketch。fat sketch负责准确记录流量流,并允许slim sketch以更少的空间开销提高准确性。Elastic Sketch首先将CM草图中的计数器分组,然后将同一组中的计数器压缩为单个计数器。Cluster-reduce也基于邻接性将计数器划分为组。之后,将附近具有相似值的组中的计数器重新排列成簇。
Compression for time-adaptive updating. Hokusai维持了一系列不同间隔的CM草图,以估计给定时间或间隔内任何项目的频率。最近区间的sketch空间比旧区间的sketch空间大,从而使sketch具有时间适应性。
2) Sketch merging
对于协作测量(collaborative measurement),分布式的sketch必须合并成一个大的摘要。
Merging for CM-based sketches. SketCh REsource Allocation for Measurement (SCREAM) 在每个交换机处分配不同的sketch大小,使得每个sketch可能有不同宽度的数组,不能直接求和。通过为每个流找到相应的计数器,SCREAM将每个sketch中的最小值求和,从而在分布式测量中形成合并的sketch。
Merging for top-k summary. 可合并摘要,如MG summary和Space Saving是可合并和同构的。受In-band Network Telemetry(INT) 的启发,LightGuardian将sketch划分为sketchlets,sketchlets可以编码为packet headers,以便在终端主机中进一步聚合、重建和分析。
B. 流键提取技术(Techniques for information extraction)
1) 流键可逆技术(Flow key reversible techniques)
传统方法仅根据流键(flow key)的哈希结果将流量的体积信息记录到sketch中,并提供一种快速的流量插入和查询方案。问题: 然而,除了枚举流键空间之外,没有一种方案可以有效地从sketch本身恢复流键。由于空间限制和实时响应要求,流键的直接记录和枚举对于流量测量都是低效的。存在3种解决方案:using bit count, sub-key count, IBF-based。
Direct key recording. 方案有:LD-sketch和MV-sketch都通过直接记录候选流键来检测heavy key。然而,直接记录并不是一种理想的逐流测量策略(per-flow measurement) 。
Bit reversibility. 方案有:BitCount、Deltoid、Fast Sketch、SketchLearn
Sub-key reversibility. 方案有:Reversible Sketch、Sequential Hashing
IBF variants. 方案有:FlowRadar、IBF
Deltoid、Reversible Sketch、Sequential Hashing、Fast Sketch、SketchLearn和BitCount都是位级(bit-level)或子键(多比特)级sketches( sub-key(multi-bit)-level sketches ),设计用于可逆性,直接推断流键。他们首先迭代地检查收集到的sketch中的位或子键,以确定用于度量任务的候选流子键。候选流键然后由这些子键组成,并与整个sketch记录的信息进一步检查,以形成最终的测量结果。
2) 基于概率理论的技术(Probability-theory-based techniques)
与传统的计数器估计技术相比,一些方法将计数器抽象为随机变量,并利用基于概率理论的技术,如最大似然估计和贝叶斯估计,来获得流量的估计计数器。
贝叶斯理论(Bayes’ Theorem.) 方法有:Multi-Resolution Array of Counters(MRAC) 首先使用计数算法和贝叶斯估计来精确估计流量大小分布。SketchLearn是第一个建立在sketch固有统计特性表征上的近似测量方法。
最大似然估计(Maximum likelihood estimation). 方法有:MLM Sketch、Persistent items Identification and Estimation(PIE)、Space-Time Bloom Filter(STBF)。
3) 机器学习技术(Machine learing techniques)
统计流量属性是不定时变化的。由于这种不确定性,传统的sketch设计和优化不适合各种测量任务,这给sketch设计的重新设计和调整带来了相当大的负担。一些研究将机器学习(ML)技术与测量框架相结合,以减轻或消除流量流特征与sketch设计的绑定。通过从sketch本身选择一组特征,其中每个特征都是有助于估计的数据的属性,ML技术可以用这些特征而不是测量的sketch来重新制定测量任务,从而大大降低设计复杂性。
ML Sketch framework. MLsketch提出了一种广义的ML框架,以减少sketch精度对网络流量特征的依赖。它使用来自相同流量的少量样本不断地重新训练ML模型,这些样本的信息存储在sketch中。
Learning assistant parameter setting. 为了准确评估top-k hot items的频率和排名,应该动态调整用于确定每个项目类型(cold items、potential hot items或hot items)的阈值,以适应流量分布。方法有:SSS、intelligent SDN-based Traffic (de)Aggregation and Measurement Paradigm(iSTAMP).
Learning cardinality estimation. Learning frequency estimation. Learning membership testing. 方法有:The sandwiched LBF、The Partitioned Learned Bloom Filter(PLBF)、the Stable Learned Bloom Filter(SLBF).
VI. 应用和实现(Application and Implementation)
A. 测量任务(Measurement tasks)
-
持续性检测(Persistence detection):与频繁项(frequent items)相比,持久项(persistent items) 在短时间内不一定比其他项出现得更频繁。相反,它会持续存在,并且只在很长一段时间内比其他项目发生得更频繁。持久性是Internet上许多隐蔽类型的流量的典型特征。例如:正常用户断断续续(间歇性的)地连接到服务器,而攻击主机不断地向服务器发送报文。通过识别持久项,运营商可以检测潜在的恶意流量行为。方法分为两类:1)Multi-layer design: Long-Duration Flows(LDFs)、PIE、On-off sketch。 2) k out of t persistence: k-persistent spread estimation、Long-tail Replacement technique、modified CLOCK algorithm。


-
流延迟(Flow latency):延迟是理解和提高系统性能的重要指标。在管理对时延要求严格的网络时,运营商需要测量两个观测点之间的时延,例如中间盒的一个端口和终端主机的一张网卡。在性能测量、系统诊断、流量工程有重要意义。方法分为两类:1) For per-flow latency measurement: MAPLE、Reference Latency Interpolation(RLI)、Colate。2) For aggregation latency: 聚合时延是指经过两个观察点的所有报文所经历的时延的平均值和偏差。有LDA、FineComb、Order Preserving Aggregator(OPA)方法。

-
单流测量(Per-flow measurement):作为一种概率数据结构,sketch已经被广泛研究用于每流测量(per-flow measurement),包括流大小flow size(一条流中的数据包数量)和流体积flow volume(一条流中的字节数)。方法包括CM Sketch及其变种,大多聚焦于流量流的偏度特征。

-
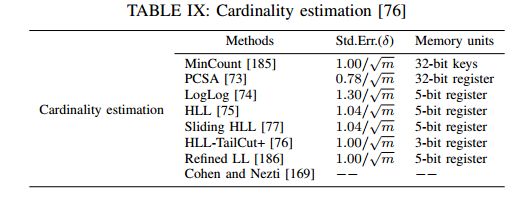
基数估计(Cardinality estimation): 估计不同流的数量(或基数)在测量和异常检测中很有用。方法有:Linear Counting 、PCSA、LogLog、HLL、Sliding HLL、HLL-TailCut+、Refined LogLog。
-
超级传播者(Super spreader): spreader estimation的目的是识别与超过阈值数量的不同目的IP/端口通信的源IP。在这种情况下,流由源地址标识。测量的元素是包头中的目的地址。特定流基数的增加可能是针对该流目标地址的DDoS攻击的信号。DDoS是一种恶意攻击,目的是破坏目标服务器、服务或网络的正常流量,使目标或其周围的基础设施陷入瘫痪。在这种情况下,流由目的地址标识,我们必须计算每个流中不同源地址的数量。Super spreader与ddos相反,super spreader是一个源地址向许多不同目的地址连续发送报文;ddos是许多不同源地址向一个目的地址连续发报文。 方法有:One-level filtering、Two-level filtering、multiple Spreader Sketch、MultiResBitmap、OSM、CSE、Virtual Register Sharing、RCD。

-
Heavy Hitters检测: 被识别为heavy hitter的流量是那些超过总流量指定量的流量。应用有拥塞和异常检测识别heavy-hitter flow是关键的。方法有:CM Sketch、Count-min heap、Lossy Counting、Probabilistic Lossy Counting(PLC)、Caching Heavy-hitter Flows with Replacement(CHHFR)、MV-sketch、LD-sketch、BitCount、IM-SUM。

-
Hierarchical Heavy Hitters(HHH): IP地址的结构是基于前缀的层次结构。通过流量聚合的5元组字段可以更好地呈现网络流量特征。这种策略使流量聚合成为流量测量的强大手段,也是异常检测识别攻击和扫描的重要组成部分。识别产生大量全局流量的源和目的前缀或其他属性对涉及一种新的测量任务,即多维分层heavy hitter(mHHH) 。方法有:Separator、Randomized HHH、Recursive Lattice Search、Z-ordering、TCAM-based HHH。

-
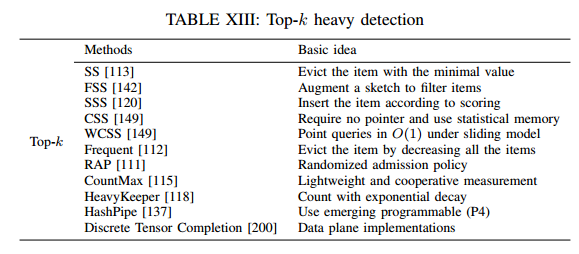
Top-k检测: 在拥塞控制、异常检测和流量工程中有许多应用,包括数据挖掘、数据库、网络流量测量和安全。方法有:CM Sketch、CSketch、MG counter、Space Saving、Frequent、FSS、SSS、CSS、WCSS、CountMax、MV-sketch、RAP、Heavy-Keeper、Discrete Tensor Completion、HashPipe。
-
熵估计(Entropy estimation): 利用流量分布的熵,我们可以执行各种各样的网络应用程序,如异常检测、聚类以揭示有趣的模式和流量分类。方法有: IMP、AMS-estimator、Defeat。
-
变化检测(Change detection): 由于大象流的出现而导致的网络流量的突然增加对于网络供应、管理和安全性是必不可少的,因为重要的模式通常意味着感兴趣的事件。例如,DDoS攻击的开始或由于链路故障导致的流量重路由将导致流量发生重大变化。heavy changer被定义为在连续两个时间间隔中,流量贡献超过总容量的阈值。方法有: Fast Sketch、MV-Sketch、LD-sketch、Modular Hashing、Deltoid、Reversible k-ary sketch、Group testing、HyperSight。

-
突变检测(Burst detection): burst被定义为所涉及事件的到来率的突然加速(the acceleration over the incoming rate of an event mentioning)。方法有: Persistent CM sketch(PCM)、BurstSketch、PBE。
-
持续的sketch(Persistent sketch): persistent sketch也被称为multi-version data structure,是一种随着时间的推移而更新时保留其所有以前版本的数据结构。方法有:Piecewise Linear Approximation、Persistent Bloom Filter。
-
项目批处理检测(Item batch detection): 将item batch定义为数据流中时间相近的相同项目的连续序列。item batch是一种有用的数据流模式,用于缓存、突发检测(burst detection)和APT检测。方法:ClockSketch。
B. 硬件或软件实现(Hardware or Software implement)
现代高速路由器转发数据包的速度为每秒数百千兆甚至数百太比特。通过核心路由器的流量可能达到数千万。此外,每个流的字节数也可能很大。同时跟踪如此大量的流量对流量测量硬件和软件来说是一个独特的挑战。
1. Implementation in SRAM. 如果测量是作为在线模块(online module)实现的,以实时处理数据包,一种方法是在输入/输出端口的网络处理器上实现它,并使用片上缓存存储器(on-chip cache memory)。然而,处理器芯片上常用的缓存是SRAM,通常具有有限的硬件资源,出于路由、性能和安全目的,可能必须在多个功能之间共享这些资源。这种情况下,分配给测量的内存量可能很小。方法有5类:1. Single counter compression: SA,SA Counter。 2. Sampling strategy: ANLS,DISCO,Counter Estimation Decoupling for Approximate Rates(CEDAR)、ICE-Buckets。 3. Bit-sharing strategy: ABC、Counter Tree、OM Sketch、Pyramid Sketch。 4. Counter-sharing strategy: CSM Sketch、Counter Braids。 5. Virtual estimators: Virtual HyperLogLog、Virtual Register Sharing、Cache-assisted Stretchable Estimator(CASE)
-
Implementation in DRAM. SRAM太昂贵,无法实现大型计数器数组,而DRAM太慢,无法提供线路速度更新,提出了混合SRAM和DRAM的架构。两种方法:one based on the replication of counters across memory banks,the other based on the randomized distribution of counters across memory banks to maintain wire-speed updates to large counter arrays.怎么翻译?
-
Implementation in hubrid SRAM-DRAM. 要解决per-flow measurement问题,必须满足两个要求:(1)存储大量的计数器;(2)每秒更新大量的计数器。DRAM可满足第一条要求,但50-100ns的访问时间不能快速处理更新。昂贵的SRAM访问时间2-6ns可满足第二个要求,但不是经济的对于第一个要求的大量计数器。方法有LCF (Largest Counter First) 、LR(T)(Largest Recent with threshold T) 、HAC、BCMA。
-
Implementation in FPGA. fpga可以编程为快速模式匹配,因为它们能够利用可重构硬件和并行性。Counter Braids ,HeavyKeeper , Reversible Sketch , CEDAR ,and elastic sketch。
-
Implementation in TCAM. 三元内容可寻址存储器(TCAM)是一种可以高速执行并行搜索的存储器。TCAM由一组条目组成。TCAM的顶部条目索引最小,而底部条目索引最大。
-
Implementation in Programmable Switch. P4是一种指定交换机如何处理数据包的语言。它提供了一个寄存器抽象,它提供了一种有状态内存的形式,可以存储用户定义的数据结构,并排列成用户定义长度的一维数组。方案有:Univmon、SketchLearn、FCM-Sketch、Elastic Sketch , HashPipe ,FlowRadar , HyperSight , HeavyKeeper , and Marple。
-
Implementation in Open vSwitch. Open vSwitch是在开源Apache 2.0许可下许可的生产质量的多层虚拟交换机。它的目的是允许大规模的网络自动化通过编程扩展,同时支持标准的管理接口和协议(例如,NetFlow, sFlow)。DREAM , FlowRadar , CounterMap , CO-FCS, Rflow , R-HHH , CountMax , NSPA, and NitroSketch。
-
Implementation in SDN. 由于软件定义网络(SDN)和网络功能虚拟化(NFV)这两个新的网络架构概念的兴起,软件网络设备越来越受欢迎。OpenSketch 、HyperSight、CO-FCS、FlowCover、 OmniMon、DREAM、DevoFlow、OblivSketch

VII. 开放问题(open issues)
- More adaptive to traffic characteristics. Elastic sketch的设计是为了适应流大小分布。然而,其只关注了heavy flow part,并提出了对heavy flow part的动态调整。未来需要设计更加灵活的sketch设计,更能适应各种流量轨迹偏度的情况。
- More adaptive to the evolution of the network. 随着IPv6协议部署的不断增加,网络出现了IPv4和IPv6双栈的局面。IPv6的发明和实施是为了解决IP地址短缺的问题,它提供了2^128个IP地址。尽管IPv6的使用不断增加,但IPv4仍然主导着网络。由于投资和兼容性,以及NAT和DHCP等新兴技术的采用,预计双栈环境将持续很长时间。
- More adaptive to SDN and programmable switch.SDN确保了控制单元与底层路由器和交换机的分离,并将可编程性引入网络。如何协调SDN下的网络管理和测量任务对网络的性能至关重要。许多网络功能正从硬件转移到软件,以更低的成本实现更好的可编程性。网络策略在控制平面定义;控制平面执行该策略,而数据平面通过相应地转发数据来执行该策略。同时,控制平面负责管理和监控逻辑,然后将这些逻辑分配到数据平面实现中,而数据平面对应于负责(有效)转发数据的网络设备。
- Enforce with ML. 利用机器学习模型来代替哈希函数以减少冲突的想法可能是一个更好的选择。将sketch与ML提取技术相结合,可以使测量任务更加准确。此外,在未来,研究人员可能会重点采用机器学习来解决一些任务,如频率估计和异常检测。