新版yolov8添加注意力机制(以NAMAttention注意力机制为例)
1.引言
之前写过yolov8如何添加注意力机制,可以看此贴
【YOLOv8添加注意力机制(ShuffleAttention为例)】
但是最近yolov8的代码结构有了一些改动,因此,这里使用较新的代码重新写一篇
此外,不同的注意力机制添加方法基本相同,因此,可以尝试不同的注意力机制,不同的注意力机制代码可以见此贴:
【常见注意力机制代码实现】
本文以NAMAttention注意力机制为例
2.添加方法
2.1 NAMAttention
以下是NAMAttention代码
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class NAMAttention(nn.Module):
def __init__(self, channels, out_channels=None, no_spatial=True):
super(NAMAttention, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out1
2.2 添加位置
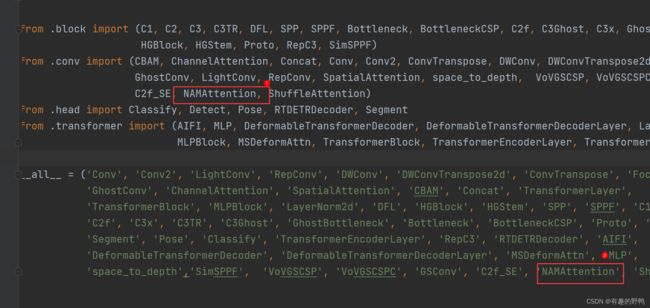
放到ultralytics/nn/modules/conv.py文件内的最后,并在文件最开头__all__中添加,如下所示

在ultralytics/nn/modules/__ init__.py文件中添加刚刚添加的NAMAttention
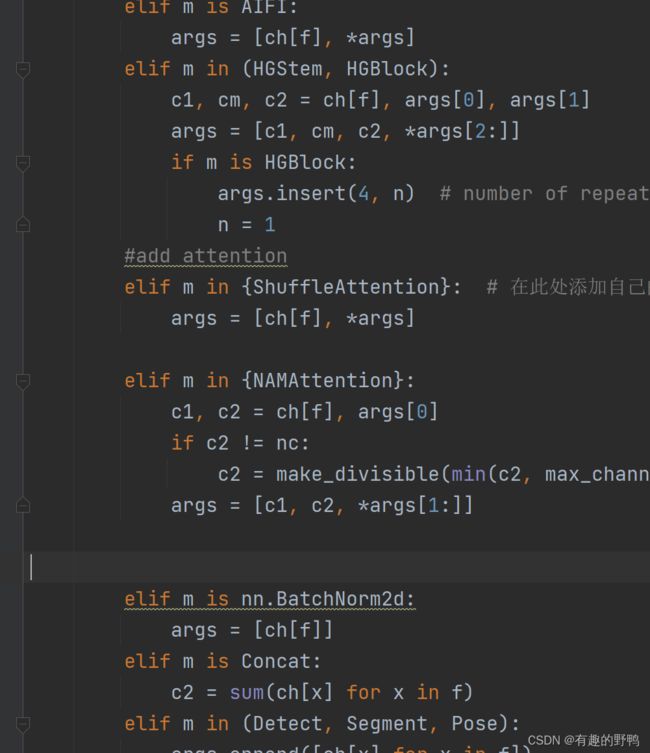
在ultralytics/nn/tasks.py中找到def parse_model(d, ch, verbose=True)方法,在一堆elif中找个位置添加
添加以下代码:
elif m in {NAMAttention}:
c1, c2 = ch[f], args[0]
if c2 != nc:
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
如下图所示
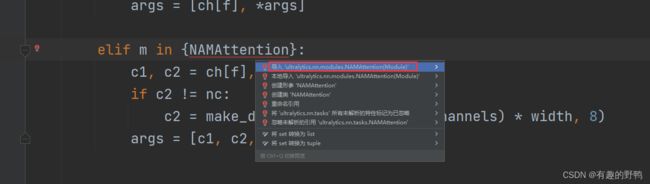
在前面导包

导包是有快捷键的,像下面这种情况,直接按alt+回车键是有提醒的,如下图:
2.3 ultralytics/cfg/models/v8
修改模型文件
在ultralytics/cfg/models/v8中,以yolov8n模型为例,新建一个yolov8n-NAMAttention.yaml文件,如下
# Ultralytics YOLO , GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.25 # scales convolution channels
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, NAMAttention, [1024]]
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
运行时将模型文件换为此文件即可。