渗透测试 ( 0 ) --- XSS、CSRF、文件上传、文件包含、反序列化漏洞
漏洞数据库:https://www.exploit-db.com/google-hacking-database
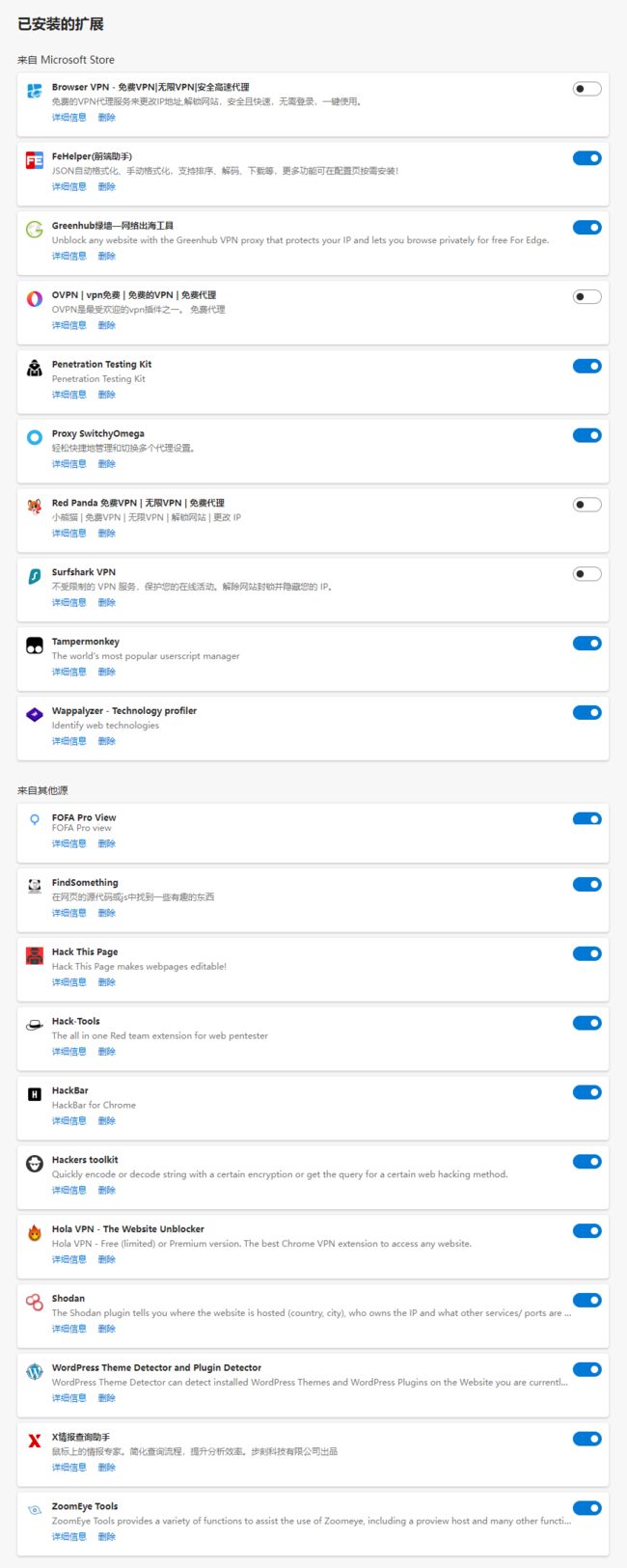
1、渗透测试 实用 浏览器插件
chrome、edge 插件:搜索 cookie,安装 cookie editor,打开插件,可以 导出 cookie
- HackBar :Hackbar是网络安全学习者常备的工具 ( https://www.fujieace.com/hacker/tools/hackbar.html )。
解决Firefox插件-Hackbar的许可证问题:https://blog.csdn.net/qq_45755030/article/details/119515945
hackbar-2.3.1-学习版:https://fengwenhua.top/index.php/archives/43/ - retire.js :扫描 Web 应用程序以使用易受攻击的JavaScript库。retire.js的目标是帮助检测具有已知漏洞的版本的使用。
- Wappalyzer:能够分析目标网站所采用的平台构架、网站环境、服务器配置环境、JavaScript框架、编程语言等参数的chrome网站技术分析插件。网站分析工具 Wappalyzer 使用教程:https://zhuanlan.zhihu.com/p/460078142
- Proxy SwitchyOmega:自动切换代理
- FoxyProxy:firefox 自动切换代理
- d3coder:可以点击右键快速进行相应字符的解码操作,减少了辗转各个解码网站的时间。
- OneTab:在平时的渗透测试过程中常常会打开大量的网页 ,此工具可以将网页聚合在一个标签列表下
- cookie editor:导出和导入 cookie
- Penetration Testing Kit:PTK仪表盘允许您分析客户端/服务器端技术并检查任何第三方库以获取现有的CVE,例如已知的漏洞。同时,它使您可以在浏览应用程序时快速访问有关所有框架和请求的信息。
- Quick Javascript Switcher:一键 开启 / 关闭 js
- Hack-Tools:是一款针对Web应用程序渗透测试的Web扩展,其中包含了大量测试工具,比如说XSS Payload和反向Shell等等。
- Shodan:显示网站在哪(国家、城市)、谁拥有 IP 以及哪些其他服务/端口是开放的。
对于 Chrome 下载插件,有 3 种方法:
- 方法 1:直接通过 chrome 插件商店安装,google 插件商店因为 "都懂的" 原因无法访问,如果会 "高科技" 上网可以忽略下面的方法。直接通过插件商店安装
- 方法 2:如果不会 "高科技" 上网,就只能曲线下载:通过 Edge下载插件,找到 Edge 插件位置,然后开启 Chrome 开发者模式,加载Edge 的插件。Edge 插件默认位置在:C:\Users\你的用户名\AppData\Local\Microsoft\Edge\User Data\Default\Extensions
- 方法 3:Chrome 插件商店 --- 镜像 插件 商店
Cxrdl:https://crxdl.com/
极简插件:https://chrome.zzzmh.cn/
扩展迷:https://www.extfans.com/
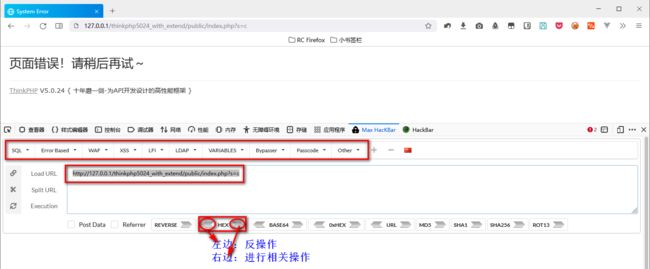
HackBar、Max HackBar
Max HackBar 示例:
常见 web 攻击
常见的 web 攻击及预防:https://cloud.tencent.com/developer/article/1592289
十种常见的 web 攻击:https://zhuanlan.zhihu.com/p/140932186
OWASP Top 10 官网:https://owasp.org/www-project-top-ten/
XSS
CSRF
SQL 注入
文件上传漏洞
命令行注入
DDoS 攻击
- SYN Flood 攻击、
- ACK Flood 攻击、
- UDP Flood 攻击、
- ICMP Flood 攻击、
- CC 攻击、
- DNS Flood、
- HTTP 慢速连接攻击
- 等等
流量劫持 --- DNS 劫持
流量劫持 --- HTTP 劫持
服务器漏洞 --- 越权操作漏洞
服务器漏洞 --- 目录遍历漏洞
服务器漏洞 --- 物理路径泄露
服务器漏洞 --- 源码暴露漏洞kali 内网穿透 横向渗透
网络服务:web、ftp、mysql、rdp、等
web 漏洞多,成功拿到权限几率更高一些
owasp top 10
网络服务:
1. 爆破 (administrator、linux、root) 密码
2. 漏洞利用 ( exp、msf )
3. 欺骗 ( DNS欺骗 )
4. 钓鱼
命令注入 之 命令连接符
; (英文分号)
命令按照顺序(从左到右)被执行,并且可以用分号进行分隔。
当有一条命令执行失败时,不会中断其它命令的执行。
ping -c 4 127.0.0.1;sleep 6 //两条都是有效命令
test;sleep 6 //test无效命令,即执行失败,sleep一样执行| (管道符)
通过管道符可以将一个命令的标准输出管道为另外一个命令的标准输入。
当第一条命令失败时,它仍然会执行第二条命令
ping -c 4 127.0.0.1|sleep 6
test|sleep 6& (后台任务符号)
命令按照顺序(从左到右)被执行,跟分号作用一样;
此符号作用是后台任务符号使shell在后台执行该任务,
这样用户就可以立即得到一个提示符并继续其他工作
root@ubuntu: d & e & f
[1] 14271
[2] 14272
后台执行任务d和e,而在前台执行任务f. shell将作业数目显示在方括号[ ]中,
同时还显示了在后台运行的每个进程的PID(process identification,进程标识)编号。
在f结束后就 会立即得到一个shell提示符&& (逻辑与)
前后的命令的执行存在逻辑与关系,只有【&&】前面的命令执行成功后,它后面的命令才被执行
ping -c 4 127.0.0.1&&sleep 6 //sleep不执行
test&&sleep 6 //test无效命令,则sleep执行|| (逻辑或)
前后命令的执行存在逻辑或关系,只有【||】前面的命令执行失败后,它后面的命令才被执行;
ping -c 4 127.0.0.1||sleep 6 //都执行
test||sleep 6 //test无效命令,则sleep不执行! (非操作符)
命令会执行除了提供的条件外的所有的语句。
rm -r !(*.html)(&& – ||) 与或操作符
实际上是 "与" 和 "或" 操作符的组合。它很像 "if-else" 语句。
如果成功打印 "已验证",否则打印 "主机故障"。
ping -c3 www.tecmint.com && echo "Verified" || echo "Host Down"{} 命令合并操作符
合并两个或多个命令,第二个命令依赖于第一个命令的执行。() 优先操作符
可以让命令以优先顺序执行。
(Command_x1 &&Command_x2) || (Command_x3 && Command_x4)($$) 连接符
用于连接shell中那些太长而需要分成多行的命令。` (反引号)
当一个命令被解析时,它首先会执行反引号之间的操作。
例如执行echo `ls -a` 将会首先执行ls并捕获其输出信息。
然后再将它传递给echo,并将ls的输出结果打印在屏幕上,这被称为命令替换
ping -c 4 127.0.0.1`sleep 6`$(command)
这是命令替换的不同符号。当反引号被过滤或编码时,可能会更有效
ping -c 4 127.0.0.1 $(sleep 6)命令解析过程:https://blog.csdn.net/huayangshiboqi/article/details/80217150
windows 服务器
| & || && 跟linux一样
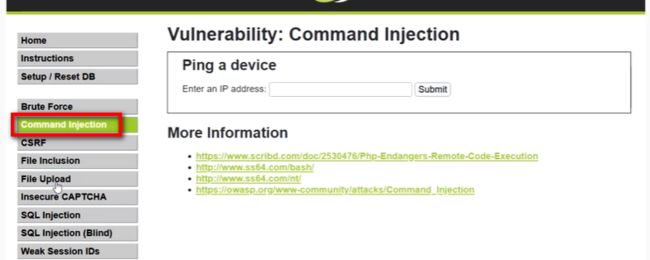
RCE ( run command exploit )

dvwa 靶场 命令注入
2、XSS : Cross Site Script
相关知识
http 协议
客户端的 cookie
服务端的 session
JavaScript 操作 cookie
脚本注入网页 xss
获得 cookie 发送邮件
xss 靶场练习
xss 平台搭建
xss 检测和利用
xss 防御方法
xss 闯关游戏
OWASP TOP 10(二)XSS漏洞(概述、PoC、分类、构造、变形绕过、XSS-Filter、xsser、xsstrike):https://blog.csdn.net/weixin_45677119/article/details/111164997
XSS 定义、原理
:https://www.bilibili.com/video/BV1jL4y1j7i6?p=7
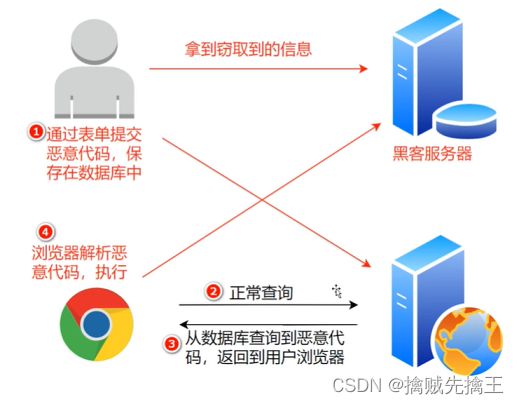
跨站脚本(英语:Cross-site scripting,通常简称为:XSS)是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。这类攻击通常包含了 HTML 以及用户端脚本语言。 XSS 攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是 JavaScript,但实际上也可以包括 Java,VBScript,ActiveX,Flash 或者甚至是普通的 HTML。攻击成功后,攻击者可能得到更高的权限(如执行一些操作)、私密网页内容、会话和 cookie 等各种内容。
简而言之,现在的网页基本是由 html+css+javascript 组成,普通用户输入的是文本信息,而黑客输入的内容则有可能是 javascript 代码,当用户访问页面的时候,代码就会执行,这个时候就达到了攻击的目的。
一句话概括:操纵用户客户端执行任意js脚本,脚本能实现什么功能,xss 就可以做什么。
注意:cookie 不能跨域名
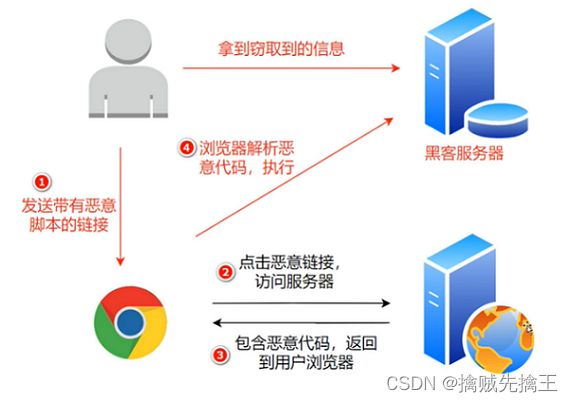
一个 XSS 攻击的示意:
上图先使用 Chrome 浏览器进行正常和非正常留言,Chrome 浏览器自动检测出 XSS 攻击,屏蔽了请求。然后打开 IE8,执行同样的操作,IE8 成功受到了攻击。
以上 GIF 所展示的,是一个用户将文本框的信息提交 form 表单到后台,后台反馈到前台进行留言展示的场景。表单提交代码如下:
{{text | safe}}
前台表单提交到后台服务器,可以直接使用 form 表单提交,也可以使用 ajax 提交的方式。后台代码可以选择任意语言实现( java、php 或者 nodejs 等均可 ),这里使用的 nodejs 代码,thinkjs3 的框架,后台代码如下:
//index.js
const Base = require('./base.js');
module.exports = class extends Base {
indexAction() {
if(this.isGet) {
//如果是Get请求,直接显示前台页面
return this.display();
} else if(this.isPost) {
//如果是Post请求,赋值nunjucks模板中的text变量,再进行页面展示
let post = this.post();
this.assign("text", post.text);
return this.display();
}
}
};这里只是一个比较轻微的弹出警告框的攻击,但如果攻击代码是:
则会将用户的 cookie 信息发送到黑客那里,而用户的 cookie 信息中很可能含有用户名和密码等重要信息,后果不堪设想。
XSS 基本分类
1. 存储型 xss
2. 反射型 xss
3. Dom 型 xss
4. Self 型 xss
存储型和反射型
- 存储型 XSS:存储型XSS,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,加入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie(虽然还有种DOM型XSS,但是也还是包括在存储型XSS内)。
- 反射型 XSS:非持久化,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面。
XSS 靶场 ( DVWA、pikachu、在线靶场 )
DVWA 靶场安装和设置:https://www.bilibili.com/video/BV1jL4y1j7i6?p=9
pikachu 靶场安装和设置 ( https://www.bilibili.com/video/BV1jL4y1j7i6?p=10 ),把 ip 地址改成自己服务器的 ip
在线 靶场 ( 网上有很多在线靶场 ):https://xss.angelo.org.cn/level1.php?name=test
xss 靶场大通关:https://www.cnblogs.com/cute-puli/p/10834954.html
XSS payload
关键字:xss payload
XSS payload:https://www.jianshu.com/p/0cb3d4354c85
XSS payload 大全:https://www.cnblogs.com/xiaozi/p/7268506.html
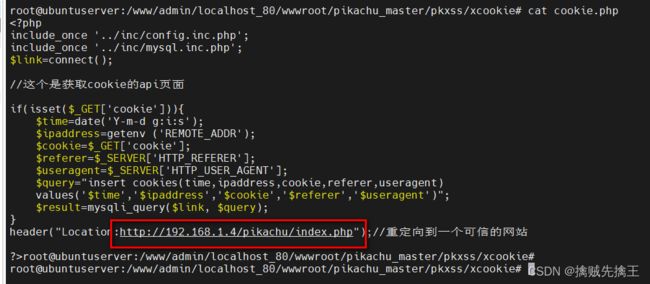
cookie 攻击 payload
钓鱼 攻击 payload
记录键盘 攻击 payload
长度限制
\...
jquery sourceMappingURL
图片名
">.gif
过期的 payload
- src=javascript:alert 基本不可以用
- css expression 特性只在旧版本 ie 可用
css
markdown
[a](javascript:prompt(document.cookie))
[a](j a v a s c r i p t:prompt(document.cookie))
<javascript:alert('XSS')>

[notmalicious](javascript:window.οnerrοr=alert;throw%20document.cookie)
[a](data:text/html;base64,PHNjcmlwdD5hbGVydCgveHNzLyk8L3NjcmlwdD4=)
iframe