日志&异常处理&errors学习笔记
与你相识

博主介绍:
– 本人是普通大学生一枚,每天钻研计算机技能,CSDN主要分享一些技术内容,因我常常去寻找资料,不经常能找到合适的,精品的,全面的内容,导致我花费了大量的时间,所以会将摸索的内容全面细致记录下来。另外,我更多关于管理,生活的思考会在简书中发布,如果你想了解我对生活有哪些反思,探索,以及对管理或为人处世经验的总结,我也欢迎你来找我。
– 目前的学习专注于Go语言,辅学算法,前端领域。也会分享一些校内课程的学习,例如数据结构,计算机组成原理等等,如果你喜欢我的风格,请关注我,我们一起成长。
Table of Contents
- 日志 & 异常处理 & error
-
- 日志框架
-
- Log (Go标准库)
-
- 定制
-
- 设置前缀
- 选项
- 自定义
- 实现
- uber-go Zap (必须掌握)
-
- 李文周博客:在Go语言中使用Zap日志库
-
- 介绍
- 默认的Go Logger
- 实现Go Logger
- Go Logger的优势和劣势
- Uber-go Zap
-
- 为什么选择Uber-go zap?
- Uber-go安装
- 配置Zap Logger
- 定制logger
- 使用Lumberjack(ˈlʌmbərdʒæk)进行日志切割归档
-
- 安装
- zap logger中加入Lumberjack
- 小结
- 李文周博客:在gin框架中使用Zap
-
- 基于Zap的中间件
- 在gin框架中使用Zap
- Logrus (了解)
-
- 快速使用
- 定制
- 重定向输出
- 自定义
- 日志格式
- 设置钩子
- 参考资料
-
- Log
- Zap
- Logrus
- 日志管理系统
-
- Sentry (了解)
-
- 基本概念
-
- DSN(Data Source Name)
- event
- issue
- Raven
- 注册与登录
- 获取项目DSN
- 在Go中安装
- 配置
- 验证
- 参考资料
- 异常处理
-
- 基本格式
- 不同级别的使用
-
- ERROR
- WARN
- INFO
- DEBUG
- TRACE
- 什么是良好的日志格式
-
- 建议
- 文章 | 我的编程习惯 - 日志建议
-
- 血泪史之一:业务逻辑太复杂,不加日志找不到
- 血泪史之二:涉及节点太多,日志没有定位到某个节点
- 最终建议
-
- 经验
- 参考资料
- Error
-
- 错误处理的历史
- Go2 Error的挣扎之路文章
-
- Go1 error的问题
- Go 1.13对error的改进
-
- warpping error嵌套概念
- Is/As/Unwarp方法
-
- Errors.Is
- Errors.As
- Errors.Unwarp
- 民间自救pkg/errors
- Go2 error
- Go语言的错误处理推荐方案文章
- 参考资料
- 本阶段学习总结
日志 & 异常处理 & error
在日志的学习中,主要是涉及到Zap框架,Logrus框架,ZeroLog框架,其中Zap框架最核心,其它两个都是参考着学习。
另外学习一个功能强大的日志管理系统Sentry。
然后就是异常处理这块,首先需要知道异常处理这一块在学什么,我们的目标是什么?然后去学习一些基本概念,以及在真正的使用中应该是什么样子的。
另外还要再了解一下errors这个库的用法。
日志框架
本来日志框架要了解Log,zap,logrus,ZeroLog,但是当我看完Zap和Log之后,就感觉有点累了,而且学习时间逾期了,因为ZeroLog的优先级是最低的,所以把ZeroLog去掉了。
Log (Go标准库)
Log是Go的标准库,也是日志的基础,虽然它功能很简单,但是我们仍要了解一下它的流程。
因为是Go标准库内的,不需要另外安装,可以直接使用。
Log会默认输出到标准错误(stderr),每条日志也会自动加上日期和时间。如果日志不是以换行符结尾,log会自动加上换行符。
package main
import (
"log"
)
type User struct {
Name string
Age int
}
func main() {
u := User{
Name: "dj",
Age: 18,
}
log.Printf("%s login, age:%d", u.Name, u.Age)
log.Panicf("Oh, system error when %s login", u.Name)
log.Fatalf("Danger! hacker %s login", u.Name)
}
log一共提供了三组函数:
Print/Printf/Println:正常输出日志/正常输出日志,可以使用格式化字符/正常输出日志带换行。Panic/Panicf/Panicln:输出日志后,以拼装好的字符串为参数调用panic。Fatal/Fatalf/Fatalln:输出日志后,调用os.Exit(1)退出程序。
定制
设置前缀
log.SetPrefix为每条日志文本前增加一个前缀。
package main
import (
"log"
)
type User struct {
Name string
Age int
}
func main() {
u := User{
Name: "dj",
Age: 18,
}
// 设置前缀Login:
log.SetPrefix("Login: ")
log.Printf("%s login, age:%d", u.Name, u.Age)
}
通过log.Prefix函数可以获取当前设置的前缀
选项
可以在每条输出的文本前添加一些附加信息,如日期时间,文件名
log库一共提供了6个选项:
// src/log/log.go
const (
Ldate = 1 << iota
Ltime
Lmicroseconds
Llongfile
Lshortfile
LUTC
)
Ldate:输出当地时区的日期,如2020/02/07;Ltime:输出当地时区的时间,如11:45:45;Lmicroseconds:输出的时间精确到微秒,设置了该选项就不用设置Ltime了。如11:45:45.123123;Llongfile:输出长文件名+行号,含包名,如github.com/darjun/go-daily-lib/log/flag/main.go:50;Lshortfile:输出短文件名+行号,不含包名,如main.go:50;LUTC:如果设置了Ldate或Ltime,将输出 UTC 时间,而非当地时区。
package main
import (
"log"
)
type User struct {
Name string
Age int
}
func main() {
u := User{
Name: "dj",
Age: 18,
}
// 通过这些来调用,设置
log.SetFlags(log.Lshortfile | log.Ldate | log.Lmicroseconds)
log.Printf("%s login, age:%d", u.Name, u.Age)
}
自定义
log库为我们定义了一个默认的Logger,名为std,意为标准日志,我们直接调用的log库方法,内部就是调用std的对应方法。
下面的代码将日志输出到一个bytes.Buffer,然后将这个buf打印到标准输出。
// src/log/log.go
var std = New(os.Stderr, "", LstdFlags)
func Printf(format string, v ...interface{}) {
std.Output(2, fmt.Sprintf(format, v...))
}
func Fatalf(format string, v ...interface{}) {
std.Output(2, fmt.Sprintf(format, v...))
os.Exit(1)
}
func Panicf(format string, v ...interface{}) {
s := fmt.Sprintf(format, v...)
std.Output(2, s)
panic(s)
}
于是我们可以定义自己的logger:
package main
import (
"bytes"
"fmt"
"log"
)
type User struct {
Name string
Age int
}
func main() {
u := User{
Name: "dj",
Age: 18,
}
buf := &bytes.Buffer{}
logger := log.New(buf, "", log.Lshortfile|log.LstdFlags)
logger.Printf("%s login, age:%d", u.Name, u.Age)
fmt.Print(buf.String())
}
log.New接受三个参数:
io.Writer:日志都会写到这个Writer中;prefix:前缀,也可以调用logger.SetPrefix方法设置flag:选项,也可以调用logger.SetFlag方法设置。
也可以通过下面的方式来同时把日志输出到标准输出,bytes.Buffer和文件中。
我们定义三个writer,然后使用io.MultiWriter来定义多个Writer。
如果你愿意,也可以输出到网络上。
writer1 := &bytes.Buffer{}
writer2 := os.Stdout
writer3, err := os.OpenFile("log.txt", os.O_WRONLY|os.O_CREATE, 0755)
if err != nil {
log.Fatalf("create file log.txt failed: %v", err)
}
logger := log.New(io.MultiWriter(writer1, writer2, writer3), "", log.Lshortfile|log.LstdFlags)
实现
log库的核心是Output方法。
// src/log/log.go
// calldepth参数表示获取调用栈向上多少层的信息,0代表当前层,1代表调用这个函数的那一行的信息。
func (l *Logger) Output(calldepth int, s string) error {
now := time.Now() // get this early.
var file string
var line int
// 上锁,保证输出内容的一致性
l.mu.Lock()
defer l.mu.Unlock()
// 如果设置了Lshortfile或Llongfile
if l.flag&(Lshortfile|Llongfile) != 0 {
// Release lock while getting caller info - it's expensive.
l.mu.Unlock()
var ok bool
// 通过runtime.Caller(calldepth)来获取文件名和行号,calldepth为0代表获取当前行和文件名,为1代表log.Printf内调用std.Output那一行的信息,为2代表程序中调用log.Printf的那一行的信息。
_, file, line, ok = runtime.Caller(calldepth)
if !ok {
file = "???"
line = 0
}
l.mu.Lock()
}
// 处理前缀和选项
l.buf = l.buf[:0]
l.formatHeader(&l.buf, now, file, line)
l.buf = append(l.buf, s...)
if len(s) == 0 || s[len(s)-1] != '\n' {
l.buf = append(l.buf, '\n')
}
_, err := l.out.Write(l.buf)
return err
}
uber-go Zap (必须掌握)
找了很多的教程,打算还是先从视频入手,然后再慢慢过渡到各种文章上。
首先zap是uber公司(美国一款打车应用)开源的go语言高性能日志库,支持不同的日志级别,能够打印基本信息,但是不支持日志分割,如果要使用日志分割,可以使用lumberjack库,也是zap官方推荐用于日志分割的第三方库,结合这两个库就能实现我们的日志功能。
另外,uber-go除了zap之外,还有很多其它的开源项目。
李文周博客:在Go语言中使用Zap日志库
介绍
一个好的日志记录器,需要提供下面这些功能:
- 能够将事件记录到文件中,而不是应用程序控制台。
- 日志切割-能够根据文件大小、时间或间隔等来切割日志文件。
- 支持不同的日志级别。例如INFO,DEBUG,ERROR等。
- 能够打印基本信息,如调用文件/函数名和行号,日志时间等。
默认的Go Logger
其实Go语言有自己的日志库,用来提供基本的日志功能,它就是log库。
实现Go Logger
实现Go语言的日志记录器比较简单——创建一个新的日志文件,然后设置它为日志的输出位置。
1、设置Logger
我们可以像下面这样的代码来设置日志记录器
func SetupLogger() { logFileLocation, _ := os.OpenFile("/Users/q1mi/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744) log.SetOutput(logFileLocation) }func SetupLogger() {
logFileLocation, _ := os.OpenFile("/Users/q1mi/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)
log.SetOutput(logFileLocation)
}
2、使用Logger
然后我们就可以在代码中输出到日志文件中
func simpleHttpGet(url string) {
resp, err := http.Get(url)
if err != nil {
log.Printf("Error fetching url %s : %s", url, err.Error())
} else {
log.Printf("Status Code for %s : %s", url, resp.Status)
resp.Body.Close()
}
}
3、运行Logger
func main() {
SetupLogger()
simpleHttpGet("www.google.com")
simpleHttpGet("http://www.google.com")
}
运行过之后会发现一个test.log文件被创建,下面的内容也会添加到日志中:
2019/05/24 01:14:13 Error fetching url www.google.com : Get www.google.com: unsupported protocol scheme ""
2019/05/24 01:14:14 Status Code for http://www.google.com : 200 OK
Go Logger的优势和劣势
最大的特点就是使用非常的简单。
劣势
- 仅限基本的日志级别,只有一个
Print选项,不支持INFO/DEBUG等多个级别 - 对于错误日志,它有Fatal和Panic
- Fatal日志通过调用os.Exit(1)来结束程序
- Panic日志在写入日志消息之后抛出一个panic,不过缺少ERROR日志级别,这个级别可以在不抛出panic或退出程序的情况下记录错误。
- 缺乏日志格式化的能力——调用者的函数名和行号,格式化日期和时间格式等
- 不提供日志切割的能力
Uber-go Zap
Zap是非常快的、结构化的,分日志级别的Go日志库。
为什么选择Uber-go zap?
- 它同时提供了结构化日志记录和printf风格的日志记录
- 它的性能很好,比标准库更快
Zap发布的基准测试信息:
记录一条消息和10个字段:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡️ zap | 862 ns/op | +0% | 5 allocs/op |
| ⚡️ zap (sugared) | 1250 ns/op | +45% | 11 allocs/op |
| zerolog | 4021 ns/op | +366% | 76 allocs/op |
| go-kit | 4542 ns/op | +427% | 105 allocs/op |
| apex/log | 26785 ns/op | +3007% | 115 allocs/op |
| logrus | 29501 ns/op | +3322% | 125 allocs/op |
| log15 | 29906 ns/op | +3369% | 122 allocs/op |
记录一个静态字符串,没有任何上下文或printf风格的模板:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡️ zap | 118 ns/op | +0% | 0 allocs/op |
| ⚡️ zap (sugared) | 191 ns/op | +62% | 2 allocs/op |
| zerolog | 93 ns/op | -21% | 0 allocs/op |
| go-kit | 280 ns/op | +137% | 11 allocs/op |
| standard library | 499 ns/op | +323% | 2 allocs/op |
| apex/log | 1990 ns/op | +1586% | 10 allocs/op |
| logrus | 3129 ns/op | +2552% | 24 allocs/op |
| log15 | 3887 ns/op | +3194% | 23 allocs/op |
Uber-go安装
go get -u go.uber.org/zap
配置Zap Logger
Zap 提供了两种类型的日志记录器——Sugared Logger和Logger。
SugaredLogger:在性能很好但不是很关键的上下文中进行使用,它比其它结构化日志记录包快4-10倍,并且支持结构化和printf风格的日志记录。Logger:在每一微秒和每一次内存分配都很重要的上下文中进行使用,它甚至比SugaredLogger更快,内存分配次数也更少,但是它只支持强类型的结构化日志记录。
Logger的配置
- 通过调用
zap.NewProduction()(生产环境)/zap.NewDevelopment()(开发环境)或者zap.Example()(例子)来创建Logger,它们的区别在于它记录的信息不同,例如production logger默认记录调用函数信息、日期和时间等。 - 默认情况下,日志都会打印到应用程序的console界面
下面的logger.Error和logger.Info还可以跟其它的logger.XXX,每个方法都接受一个消息字符串和任意数量的参数。
var logger *zap.Logger
func main() {
// 初始化logger
InitLogger()
defer logger.Sync()
simpleHttpGet("www.google.com")
simpleHttpGet("http://www.google.com")
}
func InitLogger() {
// 通过NewProduction()获得一个logger对象
logger, _ = zap.NewProduction()
}
func simpleHttpGet(url string) {
// 发送请求
resp, err := http.Get(url)
if err != nil {
// 通过logger对象发送一个Error级别的日志
logger.Error(
"Error fetching url..",
zap.String("url", url),
zap.Error(err))
} else {
// 通过logger对象发送一个Info级别的日志
logger.Info("Success..",
zap.String("statusCode", resp.Status),
zap.String("url", url))
resp.Body.Close()
}
}
结果:
{"level":"error","ts":1572159218.912792,"caller":"zap_demo/temp.go:25","msg":"Error fetching url..","url":"www.sogo.com","error":"Get www.sogo.com: unsupported protocol scheme \"\"","stacktrace":"main.simpleHttpGet\n\t/Users/q1mi/zap_demo/temp.go:25\nmain.main\n\t/Users/q1mi/zap_demo/temp.go:14\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:203"}
{"level":"info","ts":1572159219.1227388,"caller":"zap_demo/temp.go:30","msg":"Success..","statusCode":"200 OK","url":"http://www.sogo.com"
}
Sugared Logger
大部分的内容与上面的Logger配置相同,但是有部分不同。
var sugarLogger *zap.SugaredLogger
func main() {
// 初始化一个sugar logger对象
InitLogger()
defer sugarLogger.Sync()
simpleHttpGet("www.google.com")
simpleHttpGet("http://www.google.com")
}
func InitLogger() {
// 通过获取logger.Sugar来获取sugar logger对象
logger, _ := zap.NewProduction()
sugarLogger = logger.Sugar()
}
func simpleHttpGet(url string) {
sugarLogger.Debugf("Trying to hit GET request for %s", url)
resp, err := http.Get(url)
if err != nil {
sugarLogger.Errorf("Error fetching URL %s : Error = %s", url, err)
} else {
sugarLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)
resp.Body.Close()
}
}
结果:
{"level":"error","ts":1572159149.923002,"caller":"logic/temp2.go:27","msg":"Error fetching URL www.sogo.com : Error = Get www.sogo.com: unsupported protocol scheme \"\"","stacktrace":"main.simpleHttpGet\n\t/Users/q1mi/zap_demo/logic/temp2.go:27\nmain.main\n\t/Users/q1mi/zap_demo/logic/temp2.go:14\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:203"}
{"level":"info","ts":1572159150.192585,"caller":"logic/temp2.go:29","msg":"Success! statusCode = 200 OK for URL http://www.sogo.com"}
定制logger
我们总是将日志写入终端,它无法进行保存,如果你想知道之前的某个时候的日志,可能早就不知道去哪里了,那么我们需要自己定制一个符合自己需求的日志。
- 将日志写入文件:
我们将使用zap.New()方法来手动传递所有配置,而不是使用zap.NewProduction()这样的预置方法来创建logger.
// 第一个参数core需要三个配置——Encoder,WriteSyncer,LogLevel
func New(core zapcore.Core, options ...Option) *Logger
**Encoder:**编码器(如何写入日志)
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
**WriterSyncer:**指定日志将写到哪里去。我们使用zapcore.AddSync()函数将打开的文件句柄传进去。
file, _ := os.Create("./test.log")
writeSyncer := zapcore.AddSync(file)
**Log Level:**哪种级别的日志将被写入。
接下来我们就可以来创建自己的Logger了:
func InitLogger() {
writeSyncer := getLogWriter()
encoder := getEncoder()
core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)
logger := zap.New(core)
sugarLogger = logger.Sugar()
}
func getEncoder() zapcore.Encoder {
return zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
}
func getLogWriter() zapcore.WriteSyncer {
file, _ := os.Create("./test.log")
return zapcore.AddSync(file)
}
当把上面的代码应用过之后,test.log文件中会出现下面的内容。
{"level":"debug","ts":1572160754.994731,"msg":"Trying to hit GET request for www.sogo.com"}
{"level":"error","ts":1572160754.994982,"msg":"Error fetching URL www.sogo.com : Error = Get www.sogo.com: unsupported protocol scheme \"\""}
{"level":"debug","ts":1572160754.994996,"msg":"Trying to hit GET request for http://www.sogo.com"}
{"level":"info","ts":1572160757.3755069,"msg":"Success! statusCode = 200 OK for URL http://www.sogo.com"}
我们也可以把Json Encoder改为普通的Log Encoder
只需要修改Encoder函数中如下即可。
return zapcore.NewConsoleEncoder(zap.NewProductionEncoderConfig())
然后结果就变成了如下这样:
1.572161051846623e+09 debug Trying to hit GET request for www.sogo.com
1.572161051846828e+09 error Error fetching URL www.sogo.com : Error = Get www.sogo.com: unsupported protocol scheme ""
1.5721610518468401e+09 debug Trying to hit GET request for http://www.sogo.com
1.572161052068744e+09 info Success! statusCode = 200 OK for URL http://www.sogo.com
目前的问题:
- 时间是非人类可读的方式展示
- 调用方函数的详细信息没有显示在日志里
接下来我们需要覆盖默认的ProductionConfig(),然后:
- 修改时间编码器
- 在日志文件中使用大写字母记录日志级别
func getEncoder() zapcore.Encoder {
encoderConfig := zap.NewProductionEncoderConfig()
// 修改时间编码器
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder
// 在日志文件中使用大写字母记录日志级别
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
return zapcore.NewConsoleEncoder(encoderConfig)
}
// 添加一个option,来将调用函数信息记录到日志中
logger := zap.New(core, zap.AddCaller())
结果:
2019-10-27T15:33:29.855+0800 DEBUG logic/temp2.go:47 Trying to hit GET request for www.sogo.com
2019-10-27T15:33:29.855+0800 ERROR logic/temp2.go:50 Error fetching URL www.sogo.com : Error = Get www.sogo.com: unsupported protocol scheme ""
2019-10-27T15:33:29.856+0800 DEBUG logic/temp2.go:47 Trying to hit GET request for http://www.sogo.com
2019-10-27T15:33:30.125+0800 INFO logic/temp2.go:52 Success! statusCode = 200 OK for URL http://www.sogo.com
使用Lumberjack(ˈlʌmbərdʒæk)进行日志切割归档
安装
go get -u github.com/natefinch/lumberjack
zap logger中加入Lumberjack
在zap中加入Lumberjack支持,需要修改WriteSyncer代码。
func getLogWriter() zapcore.WriteSyncer {
lumberJackLogger := &lumberjack.Logger{
Filename: "./test.log", // 日志文件的位置
MaxSize: 10, // 在进行切割之前,日志文件的最大大小(以MB为单位)
MaxBackups: 5, // 保留旧文件的最大个数
MaxAge: 30, // 保留旧文件的最大天数
Compress: false, // 是否压缩 归档旧文件
}
return zapcore.AddSync(lumberJackLogger)
}
小结
下面是所有完整的功能
package main
import (
"net/http"
"github.com/natefinch/lumberjack"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
// 初始化一个logger对象
var sugarLogger *zap.SugaredLogger
// 程序入口
func main() {
// 初始化logger对象
InitLogger()
defer sugarLogger.Sync()
simpleHttpGet("www.sogo.com")
simpleHttpGet("http://www.sogo.com")
}
func InitLogger() {
// Logger的初始化需要core参数,core参数又需要Writer和Encoder,以及等级
// 获取Writer对象
writeSyncer := getLogWriter()
encoder := getEncoder() // 获取Encoder对象
// 获取core对象
core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)
// 获取logger对象,在后面加一个option用来在日志输出的时候加上调用者信息
logger := zap.New(core, zap.AddCaller())
// 通过logger对象的Sugar属性来获取sugarLogger对象
sugarLogger = logger.Sugar()
}
// 配置Encoder
func getEncoder() zapcore.Encoder {
// new一个EnconderConfig对象
encoderConfig := zap.NewProductionEncoderConfig()
// 设置一下时间的显示格式为我们能看懂的日期
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder
// 设置在日志文件中用大写字母记录日志级别
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
// 返回Encoder
return zapcore.NewConsoleEncoder(encoderConfig)
}
// 配置Writer
func getLogWriter() zapcore.WriteSyncer {
// 原来的writer用的是zapcore的AddSync方法,直接传入File来给文件写入日志
// 采用lumberjack之后,就要用下面的这种方式来进行配置使用了
lumberJackLogger := &lumberjack.Logger{
Filename: "./test.log", // 日志文件的位置
MaxSize: 10, // 在进行切割之前,日志文件的最大大小(以MB为单位)
MaxBackups: 5, // 保留旧文件的最大个数
MaxAge: 30, // 保留旧文件的最大天数
Compress: false, // 是否压缩 归档旧文件
}
// 传入lumberjack对象
return zapcore.AddSync(lumberJackLogger)
}
// 进行路由访问
func simpleHttpGet(url string) {
sugarLogger.Debugf("Trying to hit GET request for %s", url)
resp, err := http.Get(url)
if err != nil {
sugarLogger.Errorf("Error fetching URL %s : Error = %s", url, err)
} else {
sugarLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)
resp.Body.Close()
}
}
结果:
2019-10-27T15:50:32.944+0800 DEBUG logic/temp2.go:48 Trying to hit GET request for www.sogo.com
2019-10-27T15:50:32.944+0800 ERROR logic/temp2.go:51 Error fetching URL www.sogo.com : Error = Get www.sogo.com: unsupported protocol scheme ""
2019-10-27T15:50:32.944+0800 DEBUG logic/temp2.go:48 Trying to hit GET request for http://www.sogo.com
2019-10-27T15:50:33.165+0800 INFO logic/temp2.go:53 Success! statusCode = 200 OK for URL http://www.sogo.com
李文周博客:在gin框架中使用Zap
Gin框架是有自己默认的Logger和Recovery配置的,在使用Gin框架的时候,终端上输出的各种信息,就是这个logger做的工作。
Recovery的作用是程序出现panic的时候恢复现场并写入500响应。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NrU6Ix9T-1632383527677)(C:\Users\huyunfei\AppData\Roaming\Typora\typora-user-images\image-20210918144744800.png)]
如果我们要用zap来代替gin原来的Logger的话,我们就需要模仿Logger和Recovery函数来写一个自己的中间件函数。
基于Zap的中间件
// GinLogger 接收gin框架默认的日志
func GinLogger(logger *zap.Logger) gin.HandlerFunc {
return func(c *gin.Context) {
// 获取当前时间
start := time.Now()
// 从上下文中获取url
path := c.Request.URL.Path
// 从上下文中获取字符串中的参数
query := c.Request.URL.RawQuery
c.Next()
// 和start比对,获取运行时间
cost := time.Since(start)
// 使用logger打印信息
logger.Info(path, // 打印url路径
zap.Int("status", c.Writer.Status()), // 状态码
zap.String("method", c.Request.Method), // 方法参数(Get Post)
zap.String("path", path), // 路径
zap.String("query", query), // 参数
zap.String("ip", c.ClientIP()), // ip
zap.String("user-agent", c.Request.UserAgent()), // 访问者
zap.String("errors", c.Errors.ByType(gin.ErrorTypePrivate).String()), // 错误
zap.Duration("cost", cost), // 运行花费的时间
)
}
}
// GinRecovery recover掉项目可能出现的panic
func GinRecovery(logger *zap.Logger, stack bool) gin.HandlerFunc {
return func(c *gin.Context) {
defer func() {
if err := recover(); err != nil {
// Check for a broken connection, as it is not really a
// condition that warrants a panic stack trace.
var brokenPipe bool
if ne, ok := err.(*net.OpError); ok {
if se, ok := ne.Err.(*os.SyscallError); ok {
if strings.Contains(strings.ToLower(se.Error()), "broken pipe") || strings.Contains(strings.ToLower(se.Error()), "connection reset by peer") {
brokenPipe = true
}
}
}
httpRequest, _ := httputil.DumpRequest(c.Request, false)
if brokenPipe {
logger.Error(c.Request.URL.Path,
zap.Any("error", err),
zap.String("request", string(httpRequest)),
)
// If the connection is dead, we can't write a status to it.
c.Error(err.(error)) // nolint: errcheck
c.Abort()
return
}
if stack {
logger.Error("[Recovery from panic]",
zap.Any("error", err),
zap.String("request", string(httpRequest)),
zap.String("stack", string(debug.Stack())),
)
} else {
logger.Error("[Recovery from panic]",
zap.Any("error", err),
zap.String("request", string(httpRequest)),
)
}
c.AbortWithStatus(http.StatusInternalServerError)
}
}()
c.Next()
}
}
但其实如果不想自己实现的话,github上也有别人已经封装好的,直接用也是可以的。
https://github.com/gin-contrib/zap
这样就可以在gin框架中使用我们自己的logger和recovery了
r := gin.New()
r.Use(GinLogger(), GinRecovery())
在gin框架中使用Zap
main:
package main
import (
"fmt"
"gin_zap_demo/config"
"gin_zap_demo/logger"
"net/http"
"os"
"go.uber.org/zap"
"github.com/gin-gonic/gin"
)
func main() {
// load config from config.json
if len(os.Args) < 1 {
return
}
if err := config.Init(os.Args[1]); err != nil {
panic(err)
}
// init logger 将日志配置结构体作为参数
if err := logger.InitLogger(config.Conf.LogConfig); err != nil {
fmt.Printf("init logger failed, err:%v\n", err)
return
}
gin.SetMode(config.Conf.Mode)
r := gin.Default()
// 注册zap相关中间件
r.Use(logger.GinLogger(), logger.GinRecovery(true))
r.GET("/hello", func(c *gin.Context) {
// 假设你有一些数据需要记录到日志中
var (
name = "q1mi"
age = 18
)
// 记录日志并使用zap.Xxx(key, val)记录相关字段
zap.L().Debug("this is hello func", zap.String("user", name), zap.Int("age", age))
c.String(http.StatusOK, "hello liwenzhou.com!")
})
addr := fmt.Sprintf(":%v", config.Conf.Port)
r.Run(addr)
}
日志结构体:
type LogConfig struct {
Level string `json:"level"`
Filename string `json:"filename"`
MaxSize int `json:"maxsize"`
MaxAge int `json:"max_age"`
MaxBackups int `json:"max_backups"`
}
logger.go:
package logger
import (
"gin_zap_demo/config"
"net"
"net/http"
"net/http/httputil"
"os"
"runtime/debug"
"strings"
"time"
"github.com/gin-gonic/gin"
"github.com/natefinch/lumberjack"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
// 定义一个全局logger对象
var lg *zap.Logger
// InitLogger 初始化Logger
func InitLogger(cfg *config.LogConfig) (err error) {
// 获取Writer,将cfg结构体内的内容作为参数
writeSyncer := getLogWriter(cfg.Filename, cfg.MaxSize, cfg.MaxBackups, cfg.MaxAge)
// 获取Encoder
encoder := getEncoder()
var l = new(zapcore.Level)
err = l.UnmarshalText([]byte(cfg.Level))
if err != nil {
return
}
// 初始化core对象
core := zapcore.NewCore(encoder, writeSyncer, l)
// 初始化logger对象
lg = zap.New(core, zap.AddCaller())
zap.ReplaceGlobals(lg) // 替换zap包中全局的logger实例,后续在其他包中只需使用zap.L()调用即可
return
}
// 获取Encoder
func getEncoder() zapcore.Encoder {
// 配置Encoder需要EncoderConfig,所以我们需要先配置EncoderConfig
// new一个EncoderConfig
encoderConfig := zap.NewProductionEncoderConfig()
// 更改默认的时间格式显示
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder
encoderConfig.TimeKey = "time"
// 在日志文件中用大写字母来记录日志级别
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
encoderConfig.EncodeDuration = zapcore.SecondsDurationEncoder
encoderConfig.EncodeCaller = zapcore.ShortCallerEncoder
return zapcore.NewJSONEncoder(encoderConfig)
}
// 获取Writer
func getLogWriter(filename string, maxSize, maxBackup, maxAge int)
// 接收参数后配置lumberjack
zapcore.WriteSyncer {
lumberJackLogger := &lumberjack.Logger{
Filename: filename, // log输出文件路径
MaxSize: maxSize, // 日志最大大小 M为单位
MaxBackups: maxBackup, // 保留旧文件的最大个数
MaxAge: maxAge, // 保留旧文件的最大天数
}
return zapcore.AddSync(lumberJackLogger)
}
// GinLogger 接收gin框架默认的日志
func GinLogger(logger *zap.Logger) gin.HandlerFunc {
return func(c *gin.Context) {
// 获取当前时间
start := time.Now()
// 从上下文中获取url
path := c.Request.URL.Path
// 从上下文中获取字符串中的参数
query := c.Request.URL.RawQuery
c.Next()
// 和start比对,获取运行时间
cost := time.Since(start)
// 使用logger打印信息
logger.Info(path, // 打印url路径
zap.Int("status", c.Writer.Status()), // 状态码
zap.String("method", c.Request.Method), // 方法参数(Get Post)
zap.String("path", path), // 路径
zap.String("query", query), // 参数
zap.String("ip", c.ClientIP()), // ip
zap.String("user-agent", c.Request.UserAgent()), // 访问者
zap.String("errors", c.Errors.ByType(gin.ErrorTypePrivate).String()), // 错误
zap.Duration("cost", cost), // 运行花费的时间
)
}
}
// GinRecovery recover掉项目可能出现的panic,并使用zap记录相关日志
func GinRecovery(stack bool) gin.HandlerFunc {
return func(c *gin.Context) {
defer func() {
if err := recover(); err != nil {
// Check for a broken connection, as it is not really a
// condition that warrants a panic stack trace.
var brokenPipe bool
if ne, ok := err.(*net.OpError); ok {
if se, ok := ne.Err.(*os.SyscallError); ok {
if strings.Contains(strings.ToLower(se.Error()), "broken pipe") || strings.Contains(strings.ToLower(se.Error()), "connection reset by peer") {
brokenPipe = true
}
}
}
httpRequest, _ := httputil.DumpRequest(c.Request, false)
if brokenPipe {
lg.Error(c.Request.URL.Path,
zap.Any("error", err),
zap.String("request", string(httpRequest)),
)
// If the connection is dead, we can't write a status to it.
c.Error(err.(error)) // nolint: errcheck
c.Abort()
return
}
if stack {
lg.Error("[Recovery from panic]",
zap.Any("error", err),
zap.String("request", string(httpRequest)),
zap.String("stack", string(debug.Stack())),
)
} else {
lg.Error("[Recovery from panic]",
zap.Any("error", err),
zap.String("request", string(httpRequest)),
)
}
c.AbortWithStatus(http.StatusInternalServerError)
}
}()
c.Next()
}
}
Logrus (了解)
Logrus完全兼容标准的log库,支持文本、JSON两只日志输出格式。Docker使用了这个库。
快速使用
安装
go get github.com/sirupsen/logrus
使用
logrus在log的基础上支持了更多的功能,也支持更多的日志级别
package main
import (
"github.com/sirupsen/logrus"
)
func main() {
// logrus有一个日志级别,高于这个级别的日志不会输出,默认是InfoLevel
logrus.SetLevel(logrus.TraceLevel)
// 日志级别从上向下依次增加,Trace最大,Panic最小
// Trace表示很细粒度的信息,一般用不到
logrus.Trace("trace msg")
// 一般程序中输出的调试信息
logrus.Debug("debug msg")
// 关键操作,核心流程的日志
logrus.Info("info msg")
// 警告信息,提醒要注意
logrus.Warn("warn msg")
// 错误日志,需要查看原因
logrus.Error("error msg")
// 致命错误,出现错误时程序无法正常运转。输出日志后,程序退出
logrus.Fatal("fatal msg")
// 记录日志 然后Panic 也会退出程序
logrus.Panic("panic msg")
}
输出:
time:输出日志的时间;
level:日志级别;
msg:日志信息;
$ go run main.go
// time
time="2020-02-07T21:22:42+08:00" level=trace msg="trace msg"
time="2020-02-07T21:22:42+08:00" level=debug msg="debug msg"
time="2020-02-07T21:22:42+08:00" level=info msg="info msg"
time="2020-02-07T21:22:42+08:00" level=info msg="warn msg"
time="2020-02-07T21:22:42+08:00" level=error msg="error msg"
time="2020-02-07T21:22:42+08:00" level=fatal msg="fatal msg"
exit status 1
定制
输出文件名
通过logrus.SetReportCaller(true)方法在输出日志中添加文件名和方法信息:
logrus.SetReportCaller(true)
logrus.Info("info msg")
此时我们运行程序:
会发现多了两个字段,一个是func,显示相关方法名,一个是file表示调用logrus相关方法的文件名
$ go run main.go
time="2020-02-07T21:46:03+08:00" level=info msg="info msg" func=main.main file="D:/code/golang/src/github.com/darjun/go-daily-lib/logrus/caller/main.go:10"
添加字段
如果我们有在默认字段上添加自己想要的字段的需求,可以通过调用logrus.WithField和logrus.WithFields实现。logrus.WithFields接受一个logrus.Fields类型的参数,其底层实际上为map[string]interface{}:
// github.com/sirupsen/logrus/logrus.go
type Fields map[string]interface{}
下面的程序会在输出中添加两个字段name和age:
func main() {
logrus.WithFields(logrus.Fields{
"name": "dj",
"age": 18,
}).Info("info msg")
}
上面这种方式只会输出一次,如果你想让一个函数的所有日志都添加某个字段,可以使用WithFields的返回值:
func main() {
requestLogger := logrus.WithFields(logrus.Fields{
"user_id": 10010,
"ip": "192.168.32.15",
})
// 通过返回值来调用信息,就会带我们要加的字段了
requestLogger.Info("info msg")
requestLogger.Error("error msg")
}
WithFields返回一个logrus.Entry类型的值,它将logrus.Logger和设置的logrus.Fields保存下来。调用Entry相关方法输出日志时,保存下来的logrus.Fields也会随之输出。
重定向输出
默认情况下日志输出到io.Stderr,也就是控制台(标准输出),我们可以通过logrus.SetOutput来传入一个io.Writer,后续日志将写到这个io.Writer中。
当然,我们也可以像log库一样,传入一个io.MultiWriter,同时将日志写到多个Writer中。
package main
import (
"bytes"
"io"
"log"
"os"
"github.com/sirupsen/logrus"
)
func main() {
writer1 := &bytes.Buffer{}
writer2 := os.Stdout
writer3, err := os.OpenFile("log.txt", os.O_WRONLY|os.O_CREATE, 0755)
if err != nil {
log.Fatalf("create file log.txt failed: %v", err)
}
logrus.SetOutput(io.MultiWriter(writer1, writer2, writer3))
logrus.Info("info msg")
}
自定义
很多的库一般都会用默认值创建一个对象,然后包的最外层方法一般都是操作这个默认对象,我们可以看到下面logrus的做法
// github.com/sirupsen/logrus/exported.go
var (
std = New()
)
func StandardLogger() *Logger {
return std
}
func SetOutput(out io.Writer) {
std.SetOutput(out)
}
func SetFormatter(formatter Formatter) {
std.SetFormatter(formatter)
}
func SetReportCaller(include bool) {
std.SetReportCaller(include)
}
func SetLevel(level Level) {
std.SetLevel(level)
}
这样的话,我们就可以创建自己的Logger对象了:
我们只需要自己用New方法来获得一个对象,然后通过这个对象来调用SetOutput/SetFormatter/SetReportCaller/SetLevel这些方法来达到我们想要的效果即可。
package main
import "github.com/sirupsen/logrus"
func main() {
log := logrus.New()
log.SetLevel(logrus.InfoLevel)
log.SetFormatter(&logrus.JSONFormatter{})
log.Info("info msg")
}
日志格式
支持文本和JSON两种日志格式,默认为文本可是。 可以通过logrus.SetFormatter设置日志格式。
设置好日志格式之后,如下:
$ go run main.go
{"level":"trace","msg":"trace msg","time":"2020-02-07T21:40:04+08:00"}
{"level":"debug","msg":"debug msg","time":"2020-02-07T21:40:04+08:00"}
{"level":"info","msg":"info msg","time":"2020-02-07T21:40:04+08:00"}
{"level":"info","msg":"warn msg","time":"2020-02-07T21:40:04+08:00"}
{"level":"error","msg":"error msg","time":"2020-02-07T21:40:04+08:00"}
{"level":"fatal","msg":"fatal msg","time":"2020-02-07T21:40:04+08:00"}
exit status 1
除了以上两种格式之外,还支持很多的第三方格式,比如nested-logrus-formatter,可以以键值对的形式来输出日志。
设置钩子
logrus可以通过设置钩子来做到每条日志输出前都会执行钩子的特定方法,可以添加输出字段,也可以根据级别来将日志输出到不同的目的地。
logrus还有很多第三方的Hook:
-
mgorus:将日志发送到 mongodb;
-
logrus-redis-hook:将日志发送到 redis;
-
logrus-amqp:将日志发送到 ActiveMQ。
参考资料
Log
- 个人博客 | Go每日一库之log
Zap
- 李文周博客:在Go语言中使用Zap日志库
- 李文周博客:在gin框架中使用Zap
- go中文文档Logger、Zap Logger、日志切割文档
Logrus
- 个人博客 | Go每日一库之logrus
日志管理系统
Sentry (了解)
Sentry 是一个开源的实时错误报告工具,支持 web 前后端、移动应用以及游戏,支持 Python、OC、Java、Go、Node、Django、RoR 等主流编程语言和框架 ,还提供了 GitHub、Slack、Trello 等常见开发工具的集成。
基本概念
DSN(Data Source Name)
Sentry 服务支持多用户、多团队、多应用管理,每个应用都对应一个 PROJECT_ID,以及用于身份认证的 PUBLIC_KEY 和 SECRET_KEY。由此组成一个这样的 DSN:
{PROTOCOL}://{PUBLIC_KEY}:{SECRET_KEY}@{HOST}/{PATH}{PROJECT_ID}
DSN是项目和sentry服务端两者之间通信的钥匙,每当我们在sentry服务端创建一个新的项目,都会得到一个独一无二的DSN,也就是密钥,在客户端初始化的时候会用到这个密钥,这样客户端报错,服务端就能抓到对应项目的错误。
event
每当项目产生一个错误,sentry服务端日志就会产生一个event,记录此次报错的具体信息,一个错误一个event.
issue
同一类event的集合,一个错误可能会重复产生多次,sentry服务器会将这些错误聚焦在一起,这个集合就是一个issue
Raven
在项目中初始化,链接sentry的前提就是引入了Raven js
注册与登录
Sentry服务我们以使用官方服务器为例,所以我们需要先注册登录,也可以使用github登录。
创建一个新的项目

点击右上角添加功能,添加project,然后选择语言,比如你的项目是angular语言,就选择angular。
项目project,组team,成员member的关系,你可以在不同的组创建不同的项目,只有加入了该组的成员才能看到组内已拥有的项目错误采集信息。
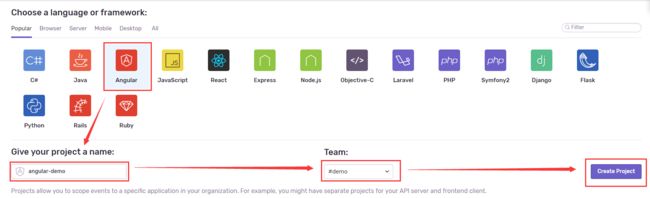
然后此时项目就创建完成了。
获取项目DSN
进入到我们刚才创建的项目中,然后点击settings设置或者issue旁边的小箭头,再点击manage管理
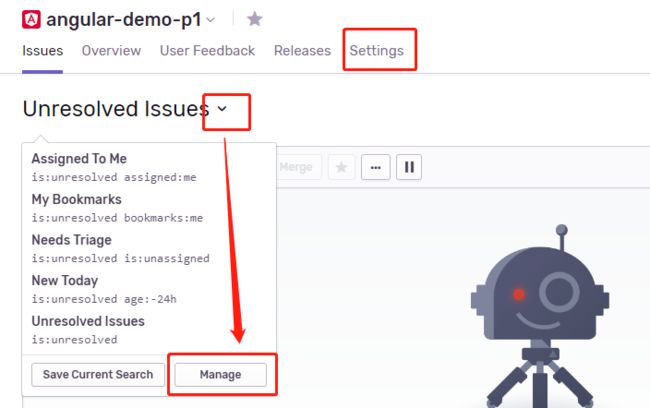
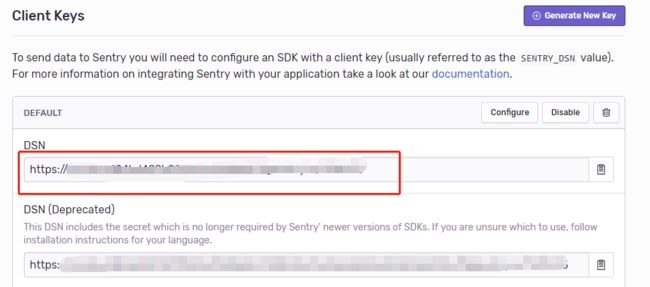
此时点击左侧的DSN,在右边我们就可以看到项目的DSN,复制。

在Go中安装
当有Go Modules时,直接import引入即可,go tool会自动下载最新版本的SDK。
import (
"github.com/getsentry/sentry-go"
)
不使用Go Modules或者没有Go Modules时,请运行:
go get github.com/getsentry/sentry-go
配置
此配置应在应用程序的生命周期中尽早进行
package main
import (
"log"
"time"
"github.com/getsentry/sentry-go"
)
func main() {
err := sentry.Init(sentry.ClientOptions{
// 在此处设置您的 DSN 或设置 SENTRY_DSN 环境变量。
Dsn: "https://[email protected]/0",
// 可以在这里设置 environment 和 release,
// 也可以设置 SENTRY_ENVIRONMENT 和 SENTRY_RELEASE 环境变量。
Environment: "",
Release: "",
// 允许打印 SDK 调试消息。
// 入门或尝试解决某事时很有用。
Debug: true,
})
if err != nil {
log.Fatalf("sentry.Init: %s", err)
}
// 在程序终止之前刷新缓冲事件。
// 将超时设置为程序能够等待的最大持续时间。
defer sentry.Flush(2 * time.Second)
}
- 在Gin中使用Sentry
验证
下面的代码带有一个故意的错误,我们可以在sentry.io打开我们的项目,查看和解决记录的错误。
package main
import (
"log"
"time"
"github.com/getsentry/sentry-go"
)
func main() {
err := sentry.Init(sentry.ClientOptions{
Dsn: "https://[email protected]/0",
})
if err != nil {
log.Fatalf("sentry.Init: %s", err)
}
defer sentry.Flush(2 * time.Second)
sentry.CaptureMessage("It works!")
}
参考资料
- 官方说明文档
- Sentry-Go SDK 中文实践指南
- 使用Docker部署Sentry服务器进行使用
异常处理
我感觉异常处理和日志是分不开的,因为出现异常需要把异常反馈给日志,让我疑惑的是我们学习异常处理在学习什么?
我觉得日志只是一个工具,而异常处理学习的却是一种如何在程序中捕获到错误并处理错误最终解决问题的一套解决方案和思维。
日志这个工具可以满足我们各种各样的需求,而到底怎么用日志,则需要依靠我们对于异常处理的理解,例如什么时候要打日志,要打什么样的日志等等。
另外异常并不是都要捕获,甚至是都不需要捕获,因为有的异常捕获了,打印了信息和日志,并没有多少人会去看日志的堆栈信息,这样表面上程序没有出现什么问题,健壮性很强,但实际上掩盖了很多的错误。
在学习这些内容的时候,我发现它是偏经验的,并没有找到一个比较好的资料,所以下面就把一些最基本的梳理了一下。
基本格式
建议使用参数化信息的方式
logger.debug("Processing trade with id:[{}] and symbol : [{}] ", id, symbol);
对于debug日志,可以先判断是否为debug级别后,再进行使用:
if (logger.isDebugEnabled()) {
logger.debug("Processing trade with id: " +id + " symbol: " + symbol);
}
另外不要进行字符串拼接,这样会产生很多String对象,占用空间影响性能,例如:
logger.debug("Processing trade with id: " + id + " symbol: " + symbol);
对于参数变量,可以使用[]来进行隔离:
这样的写法可读性更好,对于排查问题更有帮助。
logger.debug("Processing trade with id:[{}] and symbol : [{}] ", id, symbol);
不同级别的使用
ERROR
当影响到程序或当前请求正常运行的异常情况:
- 打开配置文件失败
- 所有第三方对接的异常
- 所有影响功能使用的异常,包括SQLException
WARN
不应该出现,但是不影响程序,当前请求正常运行的异常情况:
- 有容错机制的时候出现的错误情况
- 找不到配置文件,但是系统能自动创建配置文件
或者即将接近临界值的时候:
- 缓存池占用达到警戒线
INFO
系统运行信息
-
Service方法中对于系统/业务状态的变更
-
主要逻辑中的分布步骤
-
客户端请求参数
-
调用第三方时的调用参数和调用结果
- 对于复杂的业务逻辑,需要进行日志打点,以及埋点记录,比如电商系统的下订单逻辑,以及OrderAction操作。
- 对于整个系统提供出去的接口,使用INFO记录入参
- 调用其他第三方服务时,所有的出餐和入参是必须要记录的。
DEBUG
- 可以填写所有的想知道的相关信息
- 生产环境需要关闭DEBUG信息
- 如果在生产情况下需要开启DEBUG,需要使用开关进行管理,不能一直开启
如果代码中出现以下代码,可以进行优化:
//1. 获取用户基本薪资
//2. 获取用户休假情况
//3. 计算用户应得薪资
优化后的代码:
logger.debug("开始获取员工[{}] [{}]年基本薪资",employee,year);
logger.debug("获取员工[{}] [{}]年的基本薪资为[{}]",employee,year,basicSalary);
logger.debug("开始获取员工[{}] [{}]年[{}]月休假情况",employee,year,month);
logger.debug("员工[{}][{}]年[{}]月年假/病假/事假为[{}]/[{}]/[{}]",employee,year,month,annualLeaveDays,sickLeaveDays,noPayLeaveDays);
logger.debug("开始计算员工[{}][{}]年[{}]月应得薪资",employee,year,month);
logger.debug("员工[{}] [{}]年[{}]月应得薪资为[{}]",employee,year,month,actualSalary);
TRACE
特别详细的系统运行完成信息,业务代码中,不要使用。 (除非有特殊用意,否则请使用DEBUG级别替代)
什么是良好的日志格式
最早学习编程的时候,可能是下面这样的方式:



上面的方式也不是不可以,只要你能看得懂就可以,只不过这样的日志会让人感觉非常的不专业。
建议
1、 日志有分明的错误等级

因为的环境我们会关注不同的信息,如果在生产环境出现了一些调试的信息,总感觉比较奇怪。
也会降低性能和增加日志的大小。
2、 日志要进行分组
我们可以通过某种方式来快速的找到某一个模块的日志。
我们会通过一个固定的字符串来表达模块的名字

3、 日志要记录对应的时间
日志的时间也就是故障或行为发生的时间,是一个很直接的证据。
4、 记录文件名和行号
![]()
除了时间外,通常还会记录文件名和行号
5、 链路追踪系统
也可以加上链路追踪系统,它可以让我们有某一种方式来找到一个请求所对应的日志信息。
它的实现思路是采用一个自定义的Header头来表达这个信息

文章 | 我的编程习惯 - 日志建议
血泪史之一:业务逻辑太复杂,不加日志找不到
开发中关于日志这个问题,每个公司都强调,也制定了一大堆规范,但是实际情况效果并不乐观,原因是这个东西不好测试和考核,即便没有日志,功能也可以跑起来。
但是开发久了总会遇到"这个问题生产环境上能重现,但是没有日志,业务很复杂,不知道哪一步出错了?"这个时候没有其它办法,只能给程序加上日志,再发一版,让客户重现一下,那行日志再看看就知道问题在哪里了。
血泪史之二:涉及节点太多,日志没有定位到某个节点
还有一种情况,我们系统有3*5=15个节点,出了问题找日志真是痛苦,一个一个机器翻,N分钟后终于找到了,找到了后发现好多相似日志,一个一个排查;日志有了,发现逻辑很复杂,不知道走到那个分支,只能根据逻辑分析,半天过去了,终于找到了原因。。。一个问题定位就过去了2个小时,变更时间过去了一半。。。
由上,我们得出两条要求:
- 能找到哪个机器
- 能找到用户做了什么
针对第一点可以修改nginx配置文件,使用add_header返回头信息中添加是哪个机器处理的。
这样的话我们就可以指定是哪个机器了。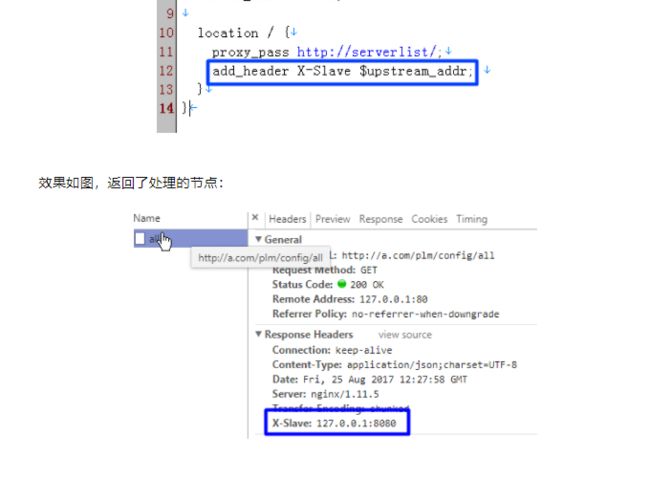
针对第二点,需要知道用户做了什么,用户信息是很重要的信息,但是在实际的公司环境中,发现这个落地并不容易,因为开发人员打印日志都经常忘记,更别说再打印日志的时候加上用户信息了。
最终建议
- 修改(包括新增)操作必须打印日志
大部分问题都是修改导致的,数据修改必须有据可查。
可以打印结果和参数。
- 条件分支必须打印条件值,重要参数必须打印
比如下面代码的userType就必须要打印值,因为它决定了代码走哪个分支,这样打印出来就不需要我们再分析和猜测代码走向了。

- 数据量大的时候需要打印数据量
主要用于分析性能,例如查询了多少数据,用了多久。

经验
- 不要依赖Debug,多依赖日志
Debug可以帮助我们快速的定位代码问题,这样就可以偷懒不打日志,但是等项目上线了之后,我们又该如何去Debug程序呢?这个时候我们还是要去打日志,来重现用户的行为。
既然这样,不如我们在开发的时候就更多的使用日志来反映问题。
- 代码开发测试完成之后,不要着急提交,可以先跑一遍看看日志是否能看得懂
日志是给人看的,不要匆匆忙忙把功能写完测试ok就提交代码。
只有精益求精才能在这条路走的更远。
参考资料
- 基本格式和不同级别的概念](https://zhuanlan.zhihu.com/p/66936941)
- 如何设计一个良好的日志格式 | bilibili
- 我的编程习惯 - 日志建议
- 我的编程习惯 - 异常处理
Error
关于Error这个模块,主要是学习在实际的使用中如何使用Error来进行错误处理,以及error标准库的使用。
错误处理的历史
我直接引用相关信息了。
在很早很早以前的C语言时代,函数只支持单个值返回,所以对于错误处理特别不方便。一种常见的错误处理方式是设置函数的返回值为 1 或者 NULL,然后函数的调用方通过读取全局的 errno 来知道具体的错误是什么。复杂一些的情况则可以通过传递一个 struct,在这个结构体中设置具体的错误信息。
然后 C++ 出现了,引入了抛出异常(try … catch…)的机制。这样的好处是不用在返回的数据结构中传递错误信息了,上层的函数可以通过 catch 来捕获这个异常。如果上层的函数不知道怎么处理这个问题,可以直接忽略,让再上层的函数 catch 这个问题。但是这个方式也有个问题:每个函数都能抛出异常。所以凡是出现调用,都要捕获异常。特别是在做事务之类的操作时,都要考虑实现对应的回滚逻辑。
然后 Java 出现了,觉得问题并不是出现在了 exception 本身,而是 exception 不能随随便便被抛出。所以 Java 在抛出异常前一定要先声明会抛出异常。这个方式确实使错误处理大有改观,同时更加的安全。但是渐渐的 Java 的的错误处理被滥用了,更像是一种流程控制。无论大小的异常都被抛出,有些甚至都不算是异常,而真正的异常可能在这个过程中被忽略。比如出现了数组访问越界,或者空指针引用的问题都会被上游无脑 catch 住。
如今 Go 语言出现了,Go 解决这个问题的方式是 “没有异常”,而是通过多值返回 error 来表示错误。Go 语言把真正的异常叫做 panic,是指出现重大错误,比如数组越界之类的编程BUG或者是那些需要人工介入才能修复的问题,比如程序启动时加载资源出错等等。
Go2 Error的挣扎之路文章
Go1 error的问题
这篇文章分析了Go error的诸多问题,比如一句经典的if err != nil暗号就可以知道你是不是Go语言爱好者,因为在使用中,它常常是这样的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mZGSFvSF-1632383527699)(C:\Users\huyunfei\AppData\Roaming\Typora\typora-user-images\image-20210923145447243.png)]
上面代码的问题是Go代码里的if err != nil甚至会达到工程代码量的30%以上,而且还很影响代码的可读性,这就需要你经常折叠err代码,非常的麻烦。
而且既然是错误处理,你需要知道具体是哪里抛出了的错误信息,所以需要我们在err != nil中加上各种描述信息:
if err != nil {
logger.Errorf("err:%v", err)
return err
}
上面这种情况发展起来就变成了下面这样:
func main() {
err := bar()
if err != nil {
logger.Errorf("bar err:%v", err)
}
...
}
func bar() error {
_, err := foo()
if err != nil {
logger.Errorf("foo err:%v", err)
return err
}
return nil
}
func foo() ([]byte, error) {
s, err := json.Marshal("hello world.")
if err != nil {
logger.Errorf("json.Marshal err:%v", err)
return nil, err
}
return s, nil
}
会导致到处打错误日志,导致错误日志非常的多,另外Go还需要对各种错误进行判断和处理,比如首先我们需要判断err不等于nil,其次我们还得对自定义的错误类型进行断言。
整体来讲,Go1错误处理的问题有以下问题:
- 在工程实践中,
if err != nil写的烦,代码中一大堆错误处理的判断,占了相当的比例,不够优雅。 - 在排查问题时,Go 的
err并没有其他堆栈信息,只能自己增加描述信息,层层叠加,打一大堆日志,排查很麻烦。 - 在验证和测试错误时,要自定义错误(各种判断和断言)或者被迫用字符串校验。
Go 1.13对error的改进
引入了Wrapping Error的概念,增加了Is/As/Unwarp三个方法,可以对所返回的错误进行二次处理和识别。
warpping error嵌套概念
可以通过下面的方式进行error的嵌套
func main() {
e := errors.New("脑子进煎鱼了")
w := fmt.Errorf("快抓住:%w", e)
fmt.Println(w)
fmt.Println(errors.Unwrap(w))
}
输出结果:
$ go run main.go
快抓住:脑子进煎鱼了
脑子进煎鱼了
errors.Unwarp方法取出最外层次层嵌套,于是输出脑子进煎鱼了。
Is/As/Unwarp方法
Errors.Is
方法签名:
func Is(err, target error) bool
方法例子:
errors.Is 方法的作用是判断所传入的 err 和 target 是否同一类型,如果是则返回 true。
也就是说你可以判断当前获取的err是属于哪个自定义错误,然后就可以进入对应的分支进行处理。
func main() {
if _, err := os.Open("non-existing"); err != nil {
if errors.Is(err, os.ErrNotExist) {
fmt.Println("file does not exist")
} else {
fmt.Println(err)
}
}
}
Errors.As
方法签名:
func As(err error, target interface{}) bool
方法例子:
errors.As和errors.Is略微有不同,As就是像的意思,也就是说err和target只要像就可以了,那么言外之意就是说他们的类型只要相同就可以了。
即errors.Is是严格判断相等,而errors.As是只判断类型相同,errors.As可以用来判断某一类的错误。
返回的仍然是bool值
func main() {
if _, err := os.Open("non-existing"); err != nil {
var pathError *os.PathError
if errors.As(err, &pathError) {
fmt.Println("Failed at path:", pathError.Path)
} else {
fmt.Println(err)
}
}
}
Errors.Unwarp
方法签名:
func Unwrap(err error) error
方法例子:
func main() {
e := errors.New("脑子进煎鱼了")
w := fmt.Errorf("快抓住:%w", e)
fmt.Println(w)
fmt.Println(errors.Unwrap(w))
}
该方法的作用是将嵌套的 error 解析出来,若存在多级嵌套则需要调用多次 Unwarp 方法。
民间自救pkg/errors
这个库对Go1 error的上下文处理进行了优化和处理,Go1.13新增的Wrapping Error体系与pkg/errors有些像,这是因为Go team接纳了相关意见对Go1进行了调整。
我们可以看到,Go1发展到这个地步,已经相对来讲比较完善了,但是它依然没有解决if err != nil泛滥的问题。
Go2 error
2018年8月,官方正式公布了包含泛型和错误处理机制改进的初步草案。
可能后续会慢慢解决这些问题。
但是我刚才去看了一下Go的最新版本是1.17.1。
看来对于错误处理的改善,目前来讲还是遥遥无期的。

Go语言的错误处理推荐方案文章
在error标准库中,我们要实现一些功能,比如要加入堆栈信息,或者加上行号,文件名等附加信息,需要我们自己自定义的添加,而我们项目中使用的是/pkg/errors这个库,这个库的使用比较简单,也比较简洁,如果我们要新生成一个错误,可以使用New函数,生成的错误,自带调用堆栈信息。
func New(message string) error
如果有一个现成的error,我们需要对他进行再次包装处理,这时候有三个函数可以选择。
//只附加新的信息
func WithMessage(err error, message string) error
//只附加调用堆栈信息
func WithStack(err error) error
//同时附加堆栈和信息
func Wrap(err error, message string) error
参考资料
- golang如何正确使用error
- Go2 Error的挣扎之路
- Go语言错误处理的推荐方案
- Go错误处理
- Go语言panic与error最佳实践
本阶段学习总结
本阶段的学习已经逾期了三天的时间,这主要源于我比预期的计划中多学了一点点,花费的时间稍长了一些,另外就是恰逢中秋,各种事情让我的状态不是很好,就逾期了。
遗憾就是有时间的话可以研究一下/pkg/errors的源代码,还是比较感兴趣的,之后再去研究吧。
欢迎评论区讨论,或指出问题。 如果觉得写的不错,欢迎点赞,转发,收藏。