《操作系统》by李治军 | 实验4 - 进程运行轨迹的跟踪与统计
目录
一、实验目的
二、实验内容
三、实验准备
1、process.c 下载
2、stat_log.py 下载
四、实验过程
(一)编写样本程序 process.c
1、什么是样本程序
2、process.c
3、修改 process.c
4、编译并运行 process.c
(二)在 Linux 0.11 上实现进程运行轨迹的跟踪
1、尽早打开 log 文件
2、写 log 文件
3、jiffies,滴答
4、寻找状态切换点
5、task_struct 结构体
6、记录进程的状态变化
7、在 Linux 0.11 上编译运行 process.c
(三)分析 log 文件,统计数据
1、下载 python 解释器
2、给 stat_log.py 加上执行权限
3、运行统计程序,分析 log 文件
4、统计结果
(四)修改时间片
1、时间片
2、时间片轮转调度算法
3、schedu() 函数
4、如何修改时间片
5、修改时间片
6、重新编译运行 process.c
7、运行结果
8、不同时间片效果
一、实验目的
1、掌握 Linux 下的多进程编程技术。
2、通过对进程运行轨迹的跟踪来形象化进程的概念。
3、在进程运行轨迹跟踪的基础上进行相应的数据统计,从而能对进程调度算法进行实际的量化评价,更进一步加深对调度和调度算法的理解,获得能在实际操作系统上对调度算法进行实验数据对比的直接经验。
什么是进程的运行轨迹?
进程从创建到结束( Linux 下调用 fork 创建进程)的整个过程就是进程的生命期。而进程在其生命期中进程状态的多次切换就是其运行轨迹。
如进程创建以后会成为就绪态;当进程被调度以后会切换到运行态;进程在运行的过程中如果启动了一个文件读写操作,操作系统会将该进程切换到阻塞态(等待态)从而让出 CPU ;当文件读写完毕以后,操作系统会再将其切换成就绪态,等待进程调度算法来调度该进程执行……
【注】等待态和就绪态并不一样,等待态要先转换为就绪态才能切换运行态
二、实验内容
(一)基于模板 process.c 编写多进程的样本程序,实现如下功能:
- 所有子进程都并行运行,每个子进程的实际运行时间一般不超过 30 秒
- 父进程向标准输出打印所有子进程的 ID ,并在所有子进程都退出后才退出
(二)在 Linux 0.11 上实现进程运行轨迹的跟踪:
- 在 Linux 0.11 内核中维护一个日志文件 /var/process.log ,将操作系统从启动到系统关机过程中所有进程的运行轨迹都记录在该 log 文件中
(三)在修改过的 Linux 0.11 上运行样本程序,通过分析 log 文件,统计该程序建立的所有进程的等待时间、完成时间(周转时间)、运行时间,然后计算平均等待时间,平均完成时间和吞吐量。
- 可以自己编写统计程序,也可以使用 python 脚本程序 stat_log.py 进行统计
(四)修改 Linux 0.11 进程调度的时间片,然后再运行相同的样本程序,统计修改后得到的时间数据,和原有的情况对比,体会不同时间片带来的差异。
【注】 日志文件 process.log 必须为如下格式:
pid X time| pid | 进程的 ID |
| X | 可以是 N、J、R、W、E 中的任意一个, 分别表示进程新建(N)、进入就绪态(J)、进入运行态(R)、进入阻塞态(W) 、退出(E) |
| time | X 发生的时间,但这个时间不是物理时间,而是系统的滴答时间(tick) |
三个字段间用制表符(Tab)分隔,例如:
12 N 1056
12 J 1057
4 W 1057
12 R 1057
13 N 1058
13 J 1059
14 N 1059
14 J 1060
15 N 1060
15 J 1061
12 W 1061
15 R 1061
15 J 1076
14 R 1076
14 E 1076
......三、实验准备
1、process.c 下载
https://download.csdn.net/download/Amentos/87793004?spm=1001.2014.3001.5503
2、stat_log.py 下载
https://download.csdn.net/download/Amentos/87799003?spm=1001.2014.3001.5503
四、实验过程
(一)编写样本程序 process.c
- 所有子进程都并行运行,每个子进程的实际运行时间一般不超过 30 秒
- 父进程向标准输出打印所有子进程的 ID ,并在所有子进程都退出后才退出
1、什么是样本程序
这里需要的样本程序,就是一个生成各种进程的程序。
我们对 Linux 0.11 进行修改,将操作系统对这些进程的调度情况都记录到 process.log 中。接着修改系统的调度算法或调度参数,然后再运行一次这个样本程序,得到修改后新的 log 文件。通过比较修改前后的 log 文件,可以比较调度算法的优缺点。
process.c 还可以用来检验有关 log 文件的修改是否正确,同时还是数据统计工作的基础。
理论上,此样本程序可以在任何 Unix/Linux 系统上运行,这里建议先在 Ubuntu 上调试通过后,再拷贝到 Linux 0.11 下运行。
2、process.c
process.c 是本次实验所需样本程序的模板,主要实现了一个函数—— cpuio_bound
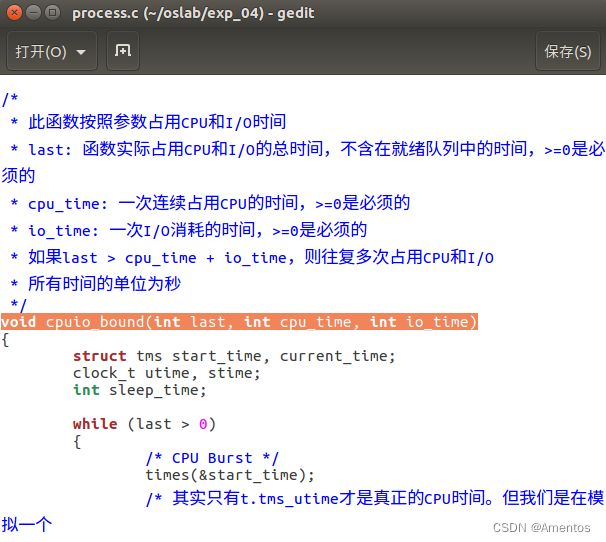
【函数解释】
/*
* 此函数按照参数占用CPU和I/O时间
* last: 函数实际占用CPU和I/O的总时间,不含在就绪队列中的时间,>=0是必须的
* cpu_time: 一次连续占用CPU的时间,>=0是必须的
* io_time: 一次I/O消耗的时间,>=0是必须的
* 如果last > cpu_time + io_time,则往复多次占用CPU和I/O,直到总运行时间超过last为止
* 所有时间的单位为秒
*/
cpuio_bound(int last, int cpu_time, int io_time);我们通过以下四个例子更好地理解 cpuio_bound 的使用方法。
① 比如一个进程要占用10秒的CPU时间,它可以调用:
cpuio_bound(10, 1, 0);
// 只要cpu_time>0,io_time=0,效果相同② 以I/O为主要任务,调用:
cpuio_bound(10, 0, 1);
// 只要cpu_time=0,io_time>0,效果相同③ CPU和I/O各1秒钟轮回,调用:
cpuio_bound(10, 1, 1);④ 较多的I/O,较少的CPU,调用:
// I/O时间是CPU时间的9倍
cpuio_bound(10, 1, 9);3、修改 process.c
我们要做的就是修改此模板,实现用 fork() 建立若干个同时运行的子进程,父进程等待所有子进程退出后才退出,并且打印子进程的ID,每个子进程按照我们的意愿做不同或相同的 cpuio_bound() ,从而完成一个个性化的样本程序。
- 对 fork 不熟悉可以先看看这篇文章:操作系统之 fork() 函数详解 - 简书
- 子进程通过 cpuio_bound 函数实现占用 CPU 和 I/O 时间的操作
- 实现让父进程等待子进程的退出可以使用 wait() 系统调用
【process.c 完整代码】
#include
#include
#include
#include
#define HZ 100
void cpuio_bound(int last, int cpu_time, int io_time);
int main(int argc, char * argv[])
{
pid_t n_proc[10]; /* 数组存放10个子进程的 PID */
int i;
for(i=0;i<10;i++)
{
n_proc[i] = fork();
/* 子进程 */
if(n_proc[i] == 0)
{
cpuio_bound(20,2*i,20-2*i); /* 每个子进程都占用20s */
return 0; /* 执行完cpuio_bound 以后,结束该子进程 */
}
/* fork 失败 */
else if(n_proc[i] < 0 )
{
printf("Failed to fork child process %d!\n",i+1);
return -1;
}
/* 父进程继续fork */
}
/* 打印所有子进程PID */
for(i=0;i<10;i++)
printf("Child PID: %d\n",n_proc[i]);
/* 等待所有子进程完成 */
wait(&i); /* Linux 0.11 上 gcc要求必须有一个参数, gcc3.4+则不需要 */
return 0; /* 结束父进程 */
}
/*
* 此函数按照参数占用CPU和I/O时间
* last: 函数实际占用CPU和I/O的总时间,不含在就绪队列中的时间,>=0是必须的
* cpu_time: 一次连续占用CPU的时间,>=0是必须的
* io_time: 一次I/O消耗的时间,>=0是必须的
* 如果last > cpu_time + io_time,则往复多次占用CPU和I/O
* 所有时间的单位为秒
*/
void cpuio_bound(int last, int cpu_time, int io_time)
{
struct tms start_time, current_time;
clock_t utime, stime;
int sleep_time;
while (last > 0)
{
/* CPU Burst */
times(&start_time);
/* 其实只有t.tms_utime才是真正的CPU时间。但我们是在模拟一个
* 只在用户状态运行的CPU大户,就像“for(;;);”。所以把t.tms_stime
* 加上很合理。
*/
do
{
times(¤t_time);
utime = current_time.tms_utime - start_time.tms_utime;
stime = current_time.tms_stime - start_time.tms_stime;
} while ( ( (utime + stime) / HZ ) < cpu_time );
last -= cpu_time;
if (last <= 0 )
break;
/* IO Burst */
/* 用sleep(1)模拟1秒钟的I/O操作 */
sleep_time=0;
while (sleep_time < io_time)
{
sleep(1);
sleep_time++;
}
last -= sleep_time;
}
} 4、编译并运行 process.c
理论上,此样本程序可以在任何 Unix/Linux 系统上运行,但建议先在 Ubuntu 上调试通过后,再拷贝到 Linux 0.11 下运行。
// process.c 所在目录下
// 编译
gcc -o process process.c
// 运行
./process【运行结果】
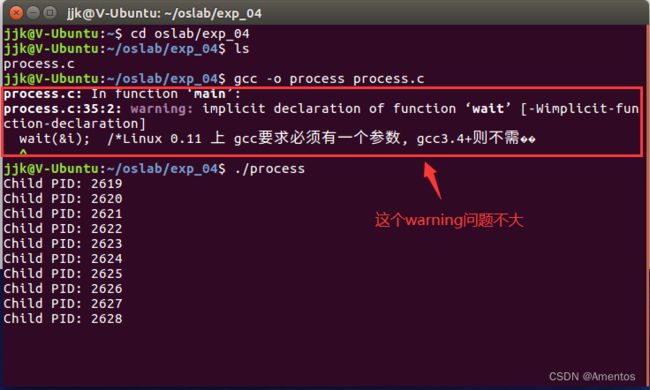
编译时可能会出现一个 warning ,但不会影响后续运行。如果想要解决这个警告,在 process.c 中添加以下头文件即可:
#include
#include 现在看来 process.c 在 Ubuntu 上运行没什么问题,之后就可以直接拷贝到 Linux 0.11 上运行了。
(二)在 Linux 0.11 上实现进程运行轨迹的跟踪
- 在内核中维护一个日志文件 /var/process.log ,把操作系统从启动到关机过程中所有进程的运行轨迹都记录在该 log 文件中
process.log 格式:
pid X time1、尽早打开 log 文件
因为要记录系统从启动到关机间所有进程的运行轨迹,所以在系统启动后,就要立即打开 /var/process.log ,然后在每个进程发生状态切换的时候向 log 文件写入一条记录,其过程和用户态的应用程序没什么区别。但是由于内核状态的存在,过程中的很多细节变得完全不一样。
为了尽早开始记录,应当在内核启动时就打开 log 文件。
【内核入口】
内核的入口是 init/main.c 中的 main() 函数(Windows 下是 start() ),main() 中有一段代码:
// ……
move_to_user_mode();
if (!fork()) { /* we count on this going ok */
init();
}
// ……上面这段代码在 进程 0 中运行:
① 先切换到用户模式 move_to_user_mode();
② 然后全系统第一次调用 fork() 建立一个子进程—— 进程 1
③ fork 返回值为 0 的进程——即 进程 1 调用 init()
而在 init() 中,重点关注以下代码:
void init(void)
{
……
/* 加载文件系统 */
setup((void *) &drive_info);
/* 打开/dev/tty0,建立文件描述符0和/dev/tty0的关联 */
(void) open("/dev/tty0",O_RDWR,0);
/* 让文件描述符1也和/dev/tty0关联 */
(void) dup(0);
/* 让文件描述符2也和/dev/tty0关联 */
(void) dup(0);
……
}上面这段代码建立了文件描述符 0、1 和 2,它们其实就是 stdin、stdout 和 stderr 。这三者的值是系统标准(Windows 也是如此),不可改变。
怎么修改才能在内核启动时就打开 log 文件 ?
我们可以把 process.log 的文件描述符关联到 3 。当文件系统初始化,描述符 0、1 、2 关联之后,接着打开 process.log ,然会就开始记录进程的运行轨迹。
上述工作是在 进程 1 中完成的(因为是 进程 1 调用的 init() ),但为了能尽早访问 log 文件,需要在 进程 0 中就完成这部分工作。所以我们直接把这段代码从 init() 中移动到 main() 中:
……
move_to_user_mode();
/*
添加到这里!不能再靠前了
还要加上打开 log 文件的代码
*/
if (!fork()) { /* we count on this going ok */
init();
}
……
修改后的 main() :
……
move_to_user_mode();
/***************添加开始***************/
/* 加载文件系统 */
setup((void *) &drive_info);
/* 建立文件描述符0和/dev/tty0的关联 */
(void) open("/dev/tty0",O_RDWR,0);
/* 文件描述符1也和/dev/tty0关联 */
(void) dup(0);
/* 文件描述符2也和/dev/tty0关联 */
(void) dup(0);
/* 打开 log 文件 */
(void) open("/var/process.log",O_CREAT|O_TRUNC|O_WRONLY,0666);
/***************添加结束***************/
if (!fork()) { /* we count on this going ok */
init();
}
……其中第 19 行打开 log 文件的参数含义是:建立只写文件,如果文件已存在则清空已有内容;文件的权限是所有人可读可写。
这样一来,文件描述符 0、1、2 和 3 就都在 进程 0 中建立了。根据 fork() 的原理, 进程 1 会继承这些文件描述符,所以 init() 中就不用再 open() 它们了(相关代码注释掉即可)。
此后所有新建的进程都是 进程 1 的子孙,自然也会继承这些描述符。但实际上,init() 的后续代码和 /bin/sh 会重新初始化它们。所以其实只有 进程 0 和 进程 1 的文件描述符肯定关联着 process.log ,这一点在接下来的写 log 中很重要。
2、写 log 文件
process.log 将被用来记录进程的状态切换轨迹,而所有的状态切换都是在内核中进行的。
写 log 文件需要使用到相应的写文件函数,如C语言库函数 write() 。但在内核状态下,write() 功能失效,因为 write() 是位于用户态的库函数,是对系统调用的封装和扩展,在用户态为用户提供一个使用系统调用的接口,而在内核中是没有这个函数的。原理等同于《系统调用》实验中不能在内核状态调用 printf() ,而只能调用 printk() 。
如果想要在内核中使用标准C函数库,就必须先载入标准C函数库,而标准C函数库会占用大量的内存,这和注重效率的内核代码是相悖的。而且库函数的本质上就是个封装好的接口,方便用户使用内核中的系统调用。所以在内核中再载入C函数库没什么意义,有这精力还不如直接在内核中编写一个相同功能的函数。
编写可以在内核调用的 write() 难度较大,所以这里直接给出了另一个函数 fprintk() 的源码,主要参考 printk() 和 sys_write() 写成,也能实现对 process.log 的写入操作。
fprintk() 源码:
#include "linux/sched.h"
#include "sys/stat.h"
static char logbuf[1024];
int fprintk(int fd, const char *fmt, ...)
{
va_list args;
int count;
struct file * file;
struct m_inode * inode;
va_start(args, fmt);
count=vsprintf(logbuf, fmt, args);
va_end(args);
/* 如果输出到stdout或stderr,直接调用sys_write即可 */
if (fd < 3)
{
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
/* 注意对于Windows环境来说,是_logbuf,下同 */
"pushl $logbuf\n\t"
"pushl %1\n\t"
/* 注意对于Windows环境来说,是_sys_write,下同 */
"call sys_write\n\t"
"addl $8,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (fd):"ax","cx","dx");
}
else
/* 假定>=3的描述符都与文件关联。事实上,还存在很多其它情况,这里并没有考虑。*/
{
/* 从进程0的文件描述符表中得到文件句柄 */
if (!(file=task[0]->filp[fd]))
return 0;
inode=file->f_inode;
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t"
"pushl %1\n\t"
"pushl %2\n\t"
"call file_write\n\t"
"addl $12,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (file),"r" (inode):"ax","cx","dx");
}
return count;
}如何添加 fprintk() ?
所有的状态切换都是在内核中进行的,所以这个函数也只在内核中使用,因此直接在内核中定义即可,不用添加系统调用号和修改系统调用总数,也不用建立用户态和它的连接等操作。
可以新建一个 fprintk.c 进行定义,但是之后还要修改 Makefile,将它和其它 Linux 代码编译链接到一起(具体操作见实验3),比较麻烦。鉴于该函数和 printk 的功能近相似,所以直接将以上源码放到 kernel/printk.c 中,就不用修改 Makefile 了。
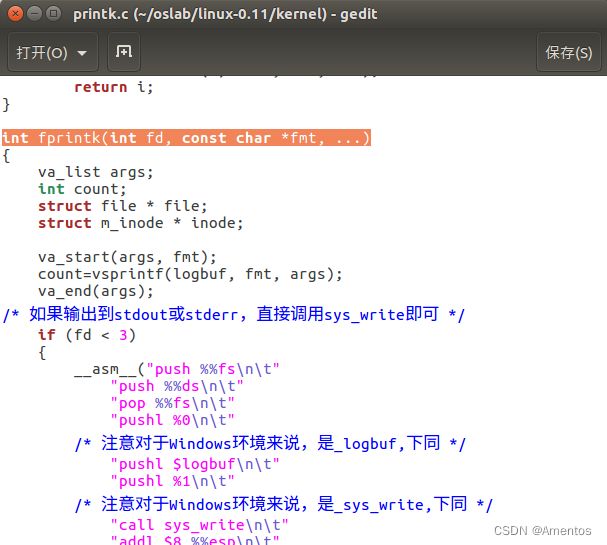
【函数解释】
fprintk() 的使用方式类似于C标准库函数的 fprintf() ,唯一的区别是 fprintk() 的第一个参数是文件描述符,而不是文件指针,例如:
/* 向 stdout 打印正在运行的进程的ID */
fprintk(1, "The ID of running process is %ld", current->pid);
/* 向 log 文件输出跟踪进程运行轨迹 */
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'R', jiffies);接下来系统向 process.log 记录进程切换的信息就可以直接使用这个 fprintk() 函数了。
3、jiffies,滴答
jiffies 在 kernel/sched.c 中定义为一个全局变量:
long volatile jiffies=0;它记录了从开机到当前时间的时钟中断发生次数。在 kernel/sched.c 中的 sched_init() 函数中,时钟中断处理函数被设置为:
set_intr_gate(0x20,&timer_interrupt);timer_interrupt 在 kernel/system_call.s 中定义为:
timer_interrupt:
! ……
! 增加jiffies计数值
incl jiffies
! ……这说明 jiffies 其实就表示从开机时到现在发生的时钟中断次数,这个次数也被称为——滴答数
另外,在 kernel/sched.c 中的 sched_init() 函数中,有以下代码:
// 设置8253模式
outb_p(0x36, 0x43);
outb_p(LATCH&0xff, 0x40);
outb_p(LATCH>>8, 0x40);以上三条语句用来设置每次时钟中断的间隔 —— LATCH,而 LATCH 是定义在 kernel/sched.c 中的一个宏:
// 在 kernel/sched.c 中
#define LATCH (1193180/HZ)
// 在 include/linux/sched.h 中
#define HZ 100加上 PC 机 8253 定时芯片的输入时钟频率为 1.193180MHz = 1193180Hz,也就是 1193180/s ,而 HZ = 100,所以 LATCH = 1193180/100,也就是说时钟每跳 11931.8 下会产生一次时钟中断,即每 1/100 s(10ms)会产生一次时钟中断,所以 jiffies 实际上记录了从开机以来共经过了多少个 10ms 。
4、寻找状态切换点
实现进程运行轨迹的跟踪,就是当一个进程发生状态切换时,将进程此刻的信息(pid、X、time)记录到 process.log 中。所以我们要做的就是找到所有发生进程状态切换的代码点,并在这些点添加适当的代码,将进程状态变化的情况输出到 log 文件中。
fork.c、sched.c 和 exit.c 这三个内核文件就是切换进程状态的对应文件,它们都在 kernel 目录下,我们要做的就是修改这三个文件。
这里给出两个例子描述这个工作该怎么做,其他情况可仿照完成:
【例 1】记录一个进程生命期的开始
第一个例子是如何记录一个进程生命期的开始,这个事件就是进程的创建函数 fork() ,根据《系统调用》实验可知,fork() 功能在内核中实现为 sys_fork() 。
sys_fork() 在 kernel/system_call.s 中实现:
sys_fork:
call find_empty_process
! ……
! 传递一些参数
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
! 调用 copy_process 实现进程创建
call copy_process
addl $20,%esp可以看出其中真正实现进程创建的函数是 copy_process() ,它在 kernel/fork.c 中定义:
int copy_process(int nr,……)
{
struct task_struct *p;
……
/* 获得一个 task_struct 结构体空间 */
p = (struct task_struct *) get_free_page();
……
p->pid = last_pid;
……
/* 设置 start_time 为 jiffies */
p->start_time = jiffies;
……
/* 设置进程状态为就绪
* 所有就绪进程的状态都是TASK_RUNNING(0)
* 被全局变量 current 指向的是正在运行的进程
*/
p->state = TASK_RUNNING;
return last_pid;
}要完成进程运行轨迹的记录,就要在 copy_process() 中添加相应的输出语句。这里要输出两种状态 —— N(新建)和 J(就绪)。
【例 2】记录进入睡眠态的时间
第二个例子是记录进程进入睡眠态的时间。sleep_on() 和 interruptible_sleep_on() 都可以让当前进程进入睡眠状态,这两个函数在 kernel/sched.c 中定义:
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
……
tmp = *p;
// 仔细阅读,实际上是将 current 插入“等待队列”头部,tmp 是原来的头部
*p = current;
// 切换到睡眠态
current->state = TASK_UNINTERRUPTIBLE;
// 让出 CPU
schedule();
// 唤醒队列中的上一个(tmp)睡眠进程。0 换作 TASK_RUNNING 更好
// 在记录进程被唤醒时一定要考虑到这种情况,实验者一定要注意!!!
if (tmp)
tmp->state = 0;
}
/* TASK_UNINTERRUPTIBLE和TASK_INTERRUPTIBLE的区别在于不可中断的睡眠
* 只能由wake_up()显式唤醒,再由上面的 schedule()语句后的
*
* if (tmp) tmp->state=0;
*
* 依次唤醒,所以不可中断的睡眠进程一定是按严格从“队列”(一个依靠
* 放在进程内核栈中的指针变量tmp维护的队列)的首部进行唤醒。而对于可
* 中断的进程,除了用wake_up唤醒以外,也可以用信号(给进程发送一个信
* 号,实际上就是将进程PCB中维护的一个向量的某一位置位,进程需要在合
* 适的时候处理这一位。感兴趣的实验者可以阅读有关代码)来唤醒,如在
* schedule()中:
*
* for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
* if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
* (*p)->state==TASK_INTERRUPTIBLE)
* (*p)->state=TASK_RUNNING;//唤醒
*
* 就是当进程是可中断睡眠时,如果遇到一些信号就将其唤醒。这样的唤醒会
* 出现一个问题,那就是可能会唤醒等待队列中间的某个进程,此时这个链就
* 需要进行适当调整。interruptible_sleep_on和sleep_on函数的主要区别就
* 在这里。
*/
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
……
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
schedule();
// 如果队列头进程和刚唤醒的进程 current 不是一个,
// 说明从队列中间唤醒了一个进程,需要处理
if (*p && *p != current) {
// 将队列头唤醒,并通过 goto repeat 让自己再去睡眠
(**p).state=0;
goto repeat;
}
*p=NULL;
//作用和 sleep_on 函数中的一样
if (tmp)
tmp->state=0;
}5、task_struct 结构体
上述代码中都出现了 task_struct 结构体,task_struct 其实就是 Linux 下的进程控制块 PCB(包含了一个进程的所有信息),task_struct 在 include/linux/sched.h 中定义:
struct task_struct {
/* these are hardcoded - don't touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};可以看出 task_struct 包含的成员非常多,这里我们只需关注 state(进程状态)和 pid(进程ID)即可。
- 建议先看这篇文章了解 task_struct 结构体成员:task_struct结构体成员详解_taskstruct结构体详解__stark的博客-CSDN博客
6、记录进程的状态变化
Linux 0.11 支持四种进程状态的转换(此外还有新建和退出两种情况):① 就绪到运行;② 运行到就绪;③ 运行到睡眠;④ 睡眠到就绪。其中就绪到运行通过 schedule() 完成( schedule 亦是调度算法所在);运行到睡眠通过 sleep_on() 和 interruptible_sleep_on() 完成,还有进程主动睡觉的系统调用 sys_pause() 和 sys_waitpid();睡眠到就绪通过 wake_up() 完成。
在本次实验中,进程状态包括以下五种:
新建态(N) 就绪态(J) 运行态(R) 阻塞态(W) 退出(E)
以下是 Linux 0.11 中实现这些状态切换的对应函数,它们都在之前提到的 fork.c、sched.c 和 exit.c 中定义( kernel 目录下)。
| 状态 | 对应函数 |
|---|---|
| 新建 - N | copy_process() |
| 就绪 - J | copy_process()、schedule()、sleep_on()、interruptible_sleep_on()、wake_up() |
| 运行 - R | schedule() |
| 等待 - W | sys_pause()、sleep_on()、interruptible_sleep_on()、sys_waitpid() |
| 退出 - E | do_exit() |
我们要做的就是在这些函数的适当位置插入适当的处理语句,将相关信息写入 process.log 中,以完成对进程运行轨迹的全面跟踪。
【1】修改 fork.c
修改 fork.c 中的 copy_process 函数,添加情况如下:
【第一处】
/* 新增修改,新建进程 */
fprintk(3,"%d\tN\t%d\n",p->pid,jiffies);
【第二处】
/* 新增修改,进程就绪 */
fprintk(3,"%d\tJ\t%d\n",p->pid,jiffies);
【2】修改 sched.c
① 修改 sched.c 中的 schedule 函数,添加情况如下:
【第一处】
/* 新增修改,进程就绪 */
fprintk(3,"%d\tJ\t%d\n",(*p)->pid,jiffies);
【第二处】
/* 切换到相同的进程不输出 */
if(current->pid != task[next] ->pid)
{
/* 新建修改--时间片到时程序 => 就绪 */
if(current->state == TASK_RUNNING)
fprintk(3,"%d\tJ\t%d\n",current->pid,jiffies);
fprintk(3,"%d\tR\t%d\n",task[next]->pid,jiffies);
}
② 修改 sched.c 中的 sys_pause 函数,添加情况如下:
/* 修改--当前进程 运行 => 可中断睡眠 */
if(current->pid != 0)
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
③ 修改 sched.c 中的 sleep_on 函数,添加情况如下:
/* 修改--当前进程进程 => 不可中断睡眠 */
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
/* 修改--原等待队列 第一个进程 => 唤醒(就绪)*/
fprintk(3,"%d\tJ\t%d\n",tmp->pid,jiffies);
④ 修改 sched.c 中的 interruptible_sleep_on 函数,添加情况如下:
/* 修改--唤醒队列中间进程,过程中使用Wait */
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
/* 修改--当前进程 => 可中断睡眠 */
fprintk(3,"%d\tJ\t%d\n",(*p)->pid,jiffies);
/* 修改--原等待队列 第一个进程 => 唤醒(就绪)*/
fprintk(3,"%d\tJ\t%d\n",tmp->pid,jiffies);
⑤ 修改 sched.c 中的 wake_up 函数,添加情况如下:
/* 修改--唤醒 最后进入等待序列的 进程 */
fprintk(3,"%d\tJ\t%d\n",(*p)->pid,jiffies);
【3】修改 exit.c
当一个进程运行结束或在运行过程中被中止,内核需要释放该进程所占用的系统资源(包括进程运行时打开的文件、申请的内存等)。
当一个用户程序调用 exit() 系统调用时,会执行内核函数 do_exit() 。该函数首先会释放进程代码段和数据段占用的内存页面,关闭进程打开着的所有文件,对进程使用的当前工作目录、根目录和运行程序的 i 节点进行同步操作。如果进程有子进程,则让 init 进程来作为其所有子进程的父进程。如果进程是一个会话头进程并且有控制终端,则释放控制终端(如果按照实验的数据,此时就应该打印了),并向属于该会话的所有进程发送挂断信号 SIGHUP,这通常会终止该会话中的所有进程。然后把进程状态置为僵死状态 TASK_ZOMBIE。并向其原父进程发送 SIGCHLD 信号,通知其某个子进程已经终止。最后 do_exit() 调用调度函数 schedule() 去执行其他进程。由此可见,在进程被终止时,它的任务数据结构仍然保留着,因为其父进程还需要使用其中的信息。
在子进程执行期间,父进程通常使用 wait() 或 waitpid() 等待其某个子进程终止。当等待的子进程被终止并处于僵死状态时,父进程就会把子进程运行所使用的时间累加到自己进程中。最终释放已终止子进程任务数据结构所占用的内存页面,并置空子进程在任务数组中占用的指针项。
① 修改 exit.c 中的 do_exit 函数,添加情况如下:
/* 修改--退出一个进程 */
fprintk(3,"%d\tE\t%d\n",current->pid,jiffies);
② 修改 exit.c 中的 sys_waitpid 函数,添加情况如下:
/* 修改--当前进程 => 等待 */
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
7、在 Linux 0.11 上编译运行 process.c
(1)我们修改了 Linux 0.11 的内核,所以要重新编译系统:
// linux-0.11 目录下运行
make all(2)将 process.c 从 Ubuntu 拷贝到 Linux 0.11 系统中(先挂载)
// oslab 目录下运行
// 先挂载,才能实现宿主机和虚拟机之间的文件交换
sudo ./mount-hdc
// 将 process.c 拷贝到bochs虚拟机的root目录下
cp ./exp_04/process.c ./hdc/usr/root/
// 拷贝完记得卸载
sudo umount hdc
(3)进入 Linux 0.11
// oslab 目录下
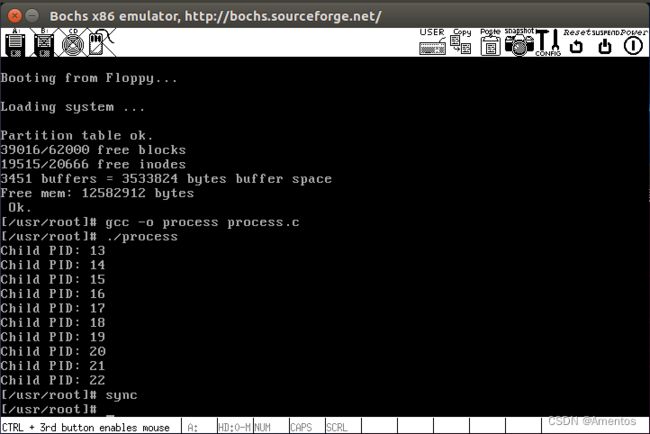
./run(4)编译并运行 process.c
gcc -o process process.c
./process运行结果:
(5)sync 刷新
使用 ./process 运行目标文件后,会在 /var 目录下生成 log 文件,记得退出 bochs 之前一定要使用 sync 命令,它会刷新 cache ,确保文件确实写入了磁盘。
【查看 log 文件】
Linux 0.11 下,可以使用 ls -l /var 或 ll /var 查看 process.log 是否建立,及它的属性和程度;用 vi /var/process.log 或 more /var/process.log 可以查看整个 log 文件;也可以用 tail -n NUM /var/process.log 查看最后 NUM 行。
虽然可以直接在 Linux 0.11 下查看,不过还是拷贝到 Ubuntu 系统下看更方便,另外后续 log 文件的数据分析也要在 Ubuntu 上进行,所以一定要能实现虚拟机和宿主机间的文件交换。
(6)将生成的 process.log 拷贝到 Ubuntu 宿主机(先挂载)
// oslab 目录下
//还是要先挂载
sudo ./mount-hdc
//拷贝到 exp_04 目录下
cp ./hdc/var/process.log ./exp_04/
//卸载
sudo umount hdc(7)查看 process.log
可以看到 exp_04 目录下多了一个 process.log ,双击打开即可


【注】每次关闭 bochs 前一定要执行 sync 命令,否则会导致 log 文件写入的进程不全
(三)分析 log 文件,统计数据
为了展示实验结果,需要编写一个数据统计程序,它从 log 文件读入原始数据,然后计算平均周转时间、平均等待时间和吞吐率等。
任何语言都可以编写这样的统计程序,实验者可自行设计,也可以直接使用 python 语言编写的统计程序 —— stat_log.py(这是 python 源程序,可用任意文本编辑器打开)。
【注】log 文件的数据分析是在 Ubuntu 下进行的,所以下面的命令也是在 Ubuntu 下进行
1、下载 python 解释器
如果是在自己的 Ubuntu 上实验,需要先执行以下命令下载 python 解释器:
sudo apt-get install python- 蓝桥云实验楼环境自带 python 解释器,无需下载
2、给 stat_log.py 加上执行权限
// stat_log.py 所在目录下执行
sudo chmod +x ./stat_log.py3、运行统计程序,分析 log 文件
// !注意文件路径,我的py文件和log文件都在exp_04目录下 !
// 以下命令也在exp_04目录下执行
./stat_log.py ./process.log 13 14 15 16 17 18 19 20 21 22从之前的实验截图可以看出 process.c 创建了 10 个子进程,PID 从 13~22,我们就统计这 10 个进程,好控制变量
4、统计结果
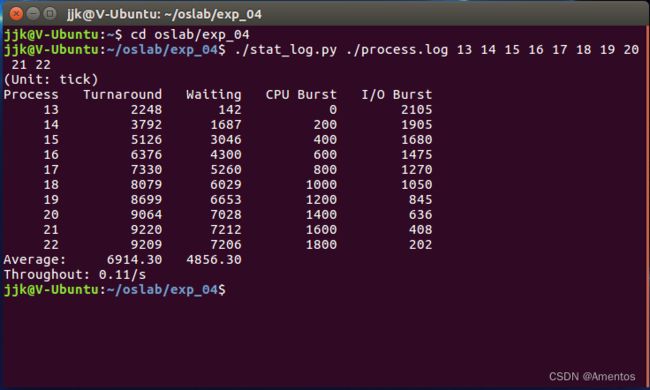
上图可以看到这 10 个进程的周转时间(Turnaround,指作业从提交到完成所用的总时间)、等待时间(Waiting)、CPU 使用时间(CPU Burst)、I/O 使用时间(I/O Burst)、所有进程平均周转时间、所有进程平均等待时间。
(四)修改时间片
修改 Linux 0.11 进程调度的时间片,然后再运行同样的样本程序。统计同样的时间数据,和原有的情况对比,体会不同时间片带来的差异。
1、时间片
Linux 学习笔记(七):时间片_Amentos的博客-CSDN博客
2、时间片轮转调度算法
Linux 学习笔记(八):时间片轮转调度_Amentos的博客-CSDN博客
3、schedule() 函数
Linux 0.11 采用的调度算法是一种综合考虑进程优先级并能动态反馈调整时间片的轮转调度算法。关于轮转调度算法,请看上一条 ☝ 。而综合考虑进程优先级,意思就是一个进程在阻塞队列中停留的时间越长,它的优先级就越大,下次被分配的时间片也就更大。
Linux 0.11 的进程调度函数是 schedule() ,在 kernel/sched.c 中定义:
void schedule(void)
{
……
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
/* 找到 counter 值最大的就绪态进程 */
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
/* 如果有 counter 值大于 0 的就绪态进程,则退出 */
if (c) break;
/*
* 如果没有:
* 所有进程的 counter 值除以 2 衰减后再和 priority 值相加,产生新的时间片
*/
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
/* 切换到 next 进程 */
switch_to(next);
}【代码分析】
分析上面的代码可知,Linux 0.11 的进程调度算法就是选取 counter 值最大的就绪进程进行调度。其中运行态进程(current)的 counter 数值会随着时钟中断而不断减 1(时钟中断 10ms/次),所以是一种比较典型的时间片轮转调度算法。
另外可以看出,当没有 counter 值大于 0 的就绪进程时,要对所有进程做:
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority
其效果就是对所有进程(包括阻塞态进程)都进行 counter 的衰减,并再累加 priority 值。这样一来,对正处于阻塞态的进程来说,在阻塞队列中停留的时间越长,其优先级越大,分配的时间片也就会越大。
4、如何修改时间片
要修改时间片,我们需要先知道两件事:
【1】进程的 counter 是如何初始化的?
【2】进程的时间片用完时,被重新赋成什么值?
【1】counter 的初始化
counter 的值是在 fork() 中设定的,而 fork() 会调用 copy_process() 完成父进程信息的拷贝(所以称为 fork ),来到 copy_process() ,会发现以下两条语句:
/* 用来复制父进程的PCB数据信息,包括 priority 和 counter */
*p = *current;
/* 初始化 counter */
p->counter = p->priority;
/*
* 因为父进程的 counter 数值已发生变化,而 priority 不会,
* 所以上面的第二句代码将 p->counter 设置成 p->priority
* 每个进程的 priority 都是继承自父亲进程的,除非它自己改变优先级。
*/查找内核中所有的代码,发现只有一个地方修改过 priority,那就是 nice 系统调用的 sys_nice() 函数(在 sched.c 中)

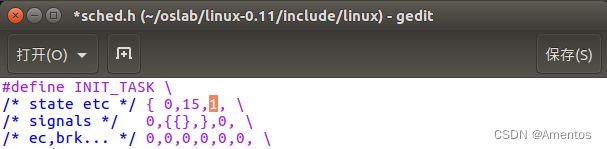
假设用户程序没有调用过 nice 系统调用,那么时间片的初值就是 进程 0 的 priority,即宏 INIT_TASK( linux-0.11/include/linux/sched.h )中定义的 15 (第三个值):
#define INIT_TASK \
{ 0,15,15,
/* 上述三个值分别对应 state、counter 和 priority */【2】时间片的赋值
当就绪进程的 counter 为 0 时,不会被调度(因为 schedule() 要选取 counter 最大、且大于 0 的进程),而当所有的就绪态进程的 counter 都为 0 时,会执行下面的语句:
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority
可以看出计算得到的新 counter 值就等于 priority ,即初始时间片的大小(宏 INIT_TASK 中定义的 第三个值)
5、修改时间片
现在我们应该清楚了,要修改时间片,就是修改宏 INIT_TASK( linux-0.11/include/linux/sched.h )中的第三个值 —— priority 。
这里我分别设置 priority 为 1 和 10000:
6、重新编译运行 process.c
修改完后重新编译一下 make all ,然后打开 bochs 模拟器重新编译运行样本程序 process.c ,得到新的 process.log ,接着运行统计脚本 stat_log.py 分析新的 log 文件(和之前一样的步骤)。
7、运行结果
(1)时间片修改为 1

(2)时间片修改为 10000

8、不同时间片效果

可以看出不同的时间片长度下,平均周转时间、平均等待时间等数据都差距蛮大的,关于造成这种结果的具体原因,可以看看这几篇文章:
Linux 学习笔记(八):时间片轮转调度_Amentos的博客-CSDN博客
MOOC哈工大操作系统实验3:进程运行轨迹的跟踪与统计_大剑蜥蜴的博客-CSDN博客