Unicode标准-编码格式-UTF-8-16-32
Unicode标准-编码格式-UTF-8-16-32
UnicodeStandard-15.0-pdf下载地址
该文章描述了Unicode标准的字符编码格式,包括UTF-8、UTF-16、UTF-32,它们的各自的特征与区别。
计算机系统中的实际实现表示特定大小的特定代码单位的整数,通常为8位(=字节)、16位或32位。在Unicode字符编码模型中,精确定义的编码形式指定如何将Unicode字符的每个整数(码点)表示为一个或多个代码单元的序列。Unicode标准为Unicode字符提供了三种不同的编码形式,分别使用8位、16位和32位单位。它们分别命名为UTF-8、UTF-16和UTF-32。“UTF”是早期术语“Unicode(或UCS)转换格式”的延续。这三种编码形式中的每一种都是表示Unicode字符的同等合法机制;每种方法在不同的环境中都有优势。
这三种编码形式都可以用来表示Unicode标准中的全部编码字符;因此,对于可能出于各种原因选择不同编码形式的实现,它们是完全可互操作的。这三种Unicode编码形式中的每一种都可以有效地转换为另外两种形式,而不会丢失任何数据。
在图2-11中,UTF-32行显示每个示例字符可以用一个32位代码单元表示。这些代码单元的值与字符的代码点的值相同。对于UTF-16,大多数字符可以用一个16位代码单元表示,其值与字符的代码点相同,但具有高代码点值的字符需要一对16位代理代码单元。在UTF-8中,字符可以用一个、两个、三个或四个字节表示,这些字节值和码位值之间的关系更复杂。
Unicode的3种编码格式的差异:

UTF-32
UTF-32是最简单的Unicode编码形式。每个Unicode码位直接由一个32位代码单元表示。因此,UTF-32在编码字符和编码单元之间有一对一的关系;它是一种固定宽度的字符编码形式。
通常使用UTF-8或UTF-16的实现有时会临时将字符串转换为UTF-32,以便于处理。
在某些用例中,多代码点序列作为处理单元是有用的或必要的;例如,字素簇或具有非零组合类的字符序列。这可能会限制每码位固定宽度编码的实用性。
像UTF-32或UTF-8这样的字符串编码形式与传递单个字符值的API无关:它们通常接受或返回简单的码位整数。
对于所有Unicode编码形式,UTF-32仅限于表示范围为0…D7FF16和E00016…10FFFF16的代码点,即Unicode标量值。这保证了与UTF-16和UTF-8编码形式的互操作性。
固定宽度。每个UTF-32代码单元的值与Unicode代码点值完全对应。这种情况与UTF-16尤其是UTF-8的情况有很大的不同,UTF-8中的代码单位值通常会与代码点值发生无法识别的变化。例如,U+10000在UTF-32中表示为<00010000>,在UTF-8中表示为
首选用法。UTF-32可能是一种首选的编码形式,其中字符的内存或磁盘存储空间不是特别重要,但需要固定宽度、单个代码单元访问字符。例如,Python3字符串是Unicode代码点的序列。
UTF-16
在UTF-16编码形式中,范围为U+0000…U+FFFF的非代理码点表示为单个16位代码单元;在U+10000…U+10FFFF范围内,补充平面中的码点表示为一对16位码单元。这些特殊代码单元对称为代理项对(surrogate pairs)。用于包围门对的代码单元的值与用于单个代码单元表示的代码单元完全分离,因此UTF-16中的所有代码点表示保持不重叠。有关代理的正式定义,请参阅第3.8节“代理”。
针对BMP优化。UTF-16优化了基本多语言平面(BMP)中字符的表示,即U+0000…U+FFFF范围内的字符,不包括包围码点。该范围包含世界上所有现代脚本的绝大多数常用字符,每个字符只需要一个16位代码单元,因此只需要UTF-32编码形式一半的内存或存储空间。对于BMP,UTF-16可以有效地视为固定宽度的编码形式。
补充字符和代理。对于补充字符,UTF-16需要两个16位代码单元。用一个与两个16位代码单元表示的字符之间的区别意味着UTF-16是一种可变宽度的编码形式。如果不仔细考虑,这一事实可能会给实现带来困难;UTF-16比UTF-32要复杂一些。
首选用法。UTF-16可能是许多环境中的首选编码形式,这些环境需要在高效访问字符和节约使用存储之间取得平衡。它结构紧凑,所有常用字符都可以放入一个16位代码单元。
起源。UTF-16是最早的Unicode形式的历史后代,最初的设计是专门使用固定宽度的16位编码形式。添加代理项是为了在超过U+FFFF的代码点处为补充字符提供编码形式。代理项的设计使它们成为一种简单高效的扩展机制,可以与旧的Unicode实现很好地配合,并避免了其他可变宽度字符编码的许多问题。有关代理及其处理的更多信息,请参阅第5.4节UTF-16中的代理对处理。
二进制排序。为了对文本进行排序,如果文本包含补充码位,则UTF-16编码形式中表示的数据的二进制顺序与码位顺序不同。这意味着代码点顺序需要稍微不同的比较实现。有关更多信息,请参阅第5.17节,二进制顺序。
UTF-8
为了满足面向字节、基于ASCII的系统的要求,Unicode标准指定了第三种编码形式:UTF-8。这种可变宽度编码形式通过使用8位代码单元来保持ASCII的透明度。
面向字节。信息技术中的许多现有软件和实践长期以来都依赖于将字符数据表示为字节序列。此外,许多协议不仅依赖于ASCII值保持不变,而且必须利用或避免可能具有相关控制功能的特殊字节值。使Unicode实现适应这种情况的最简单方法是使用一种编码形式,这种形式已经用8位代码单位定义,表示所有Unicode字符,同时不干扰或重用任何ASCII或C0控制代码值。这是UTF-8的功能。
可变宽度。UTF-8是一种可变宽度编码形式,使用8位代码单元,其中每个代码单元的高位表示每个字节所属的代码单元序列的一部分。为UTF-8码单元序列的第一个或前导元素保留一系列8位码单元值,为此类序列的后续或尾随元素保留一个完全分离的8位码单位值范围;此约定预先为UTF-8提供非重叠。表3-6显示了Unicode码位中的位如何在UTF-8编码形式的字节之间分布。有关UTF-8的完整正式定义,请参阅第3.9节“Unicode编码形式”。
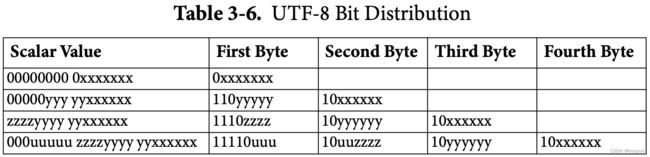
表3-6指定了UTF-8编码形式的位分布,显示了对应于一字节、二字节、三字节和四字节序列的Unicode标量值的范围。“x”表示分布在右-1(最低)字节上的值,“y”表示分布在右-2个字节上的值,“z”表示分布在右-3字节上的值,“u”表示分布在右-3字节上的值。疑问:最后一行的First和Second字节中的“u”和“z”并没有按照整个字节对齐,是哪里不对?
表3-7列出了UTF-8格式良好的所有字节序列。字节值范围(如A0…BF)表示A0到BF(包括A0和BF)的任何字节在该位置格式良好。任何超出所列范围的字节值都是格式错误的。例如:
- 字节序列
C0 AF格式错误,因为C0在“第一个字节”列中格式不正确。 - 字节序列
E0 9F 80格式错误,因为在E0作为第一个字节格式正确的行中,9F作为第二个字节格式错误。 - 字节序列
F4 80 83 92格式良好,因为该序列中的每个字节都与表中一行(最后一行)的字节范围相匹配。
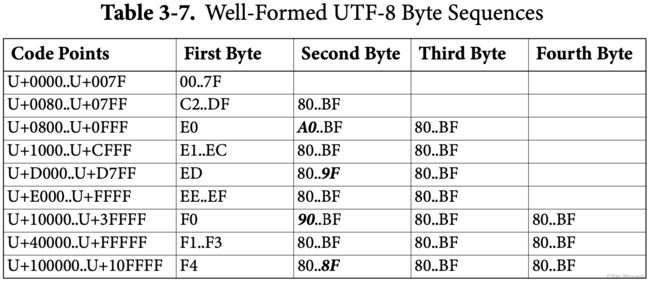
在表3-7中,尾随字节范围不是80…BF的情况以粗体斜体显示,以引起注意。一般模式的这些异常仅出现在序列的第二个字节中。
ASCII透明。UTF-8编码形式保持了所有ASCII码位(0x00…0x7F)的透明度。这意味着Unicode代码点U+0000…U+007F在UTF-8中转换为单字节0x00…0x7F,因此与ASCII本身无法区分。此外,对于任何其他Unicode代码点的表示,值0x00…0x7F不会出现在任何字节中,因此不会有歧义。除了Unicode的ASCII范围外,许多非表意文字脚本都是用UTF-8中每个码位两个字节表示的;U+0800和U+FFFF之间的所有非代理代码点由三个字节表示;U+FFFF以上的补充码位需要四个字节。
数据大小。就使用的字节数而言,UTF-8相当紧凑。与UTF-16相比,对于ASCII语法和西方语言,它要小得多,但对于亚洲书写系统,如印地语、泰语、汉语、日语和韩语,它要大得多。
首选用法。UTF-8通常是HTML和类似协议(尤其是Internet)的首选编码形式。ASCII透明性有助于迁移。UTF-8还有一个优点,即它本身就是字节序列化的,就像大多数现有的8位字符集一样;UTF-8的字符串很容易与C标准库一起工作,并且许多适用于典型东亚多字节字符集的现有API也可以适应UTF-8,几乎不需要更改。
自同步。在由于某种原因需要8位字符处理的环境中,与其他多字节编码相比,UTF-8具有以下吸引人的特性:
- UTF-8代码单元序列的第一个字节表示多字节序列后面的字节数。这允许非常高效的正向解析。
- 从UTF-8字节流中的任意位置开始查找字符的开头是有效的。程序最多需要向后搜索四个字节,通常要少得多。识别初始字节是一项简单的任务,因为初始字节被限制为固定的值范围。
- 与其他编码形式一样,字节值没有重叠。
二进制排序。UTF-8字符串的二进制排序给出的顺序与Unicode码位的二进制排序相同。这显然与UTF-32字符串的二进制排序的顺序相同。