C语言中字符串和字符数组的区别
参考:C语言中字符串和字符数组的区别
参考:字符数组和字符串的区别,C语言字符数组和字符串区别详解
这里写目录标题
- 区别
- 代码分析一
- 代码分析二
- 总结
区别
- (1)C语言中,没有字符串类型但可以用字符数组模拟字符串。
- (2)C语言中,字符串是以’\0’作结尾字符。
- (3)C语言中,字符串常量本质上是一个无名的字符数组
字符串和字符数组很相似,但是有本质上的区别。
(1) C语言中,字符串是双引号括起来的单个或多个字符的集合,编译器自动在结尾加上’\0’字符。字符串常量存储在只读数据段,无法通过指针进行修改字符串中的某个字符。
(2)C语言中,不能定义字符串(没有string关键字,C++才有),但是在C语言中使用字符串,通常会用字符数组来模拟字符串,必须是’\0’结尾的字符数组,这个字符数组存储通常会分配在栈区,也可以被称为字符串,且该字符串中的字符是可以修改的。
如果字符数组中没有’\0’结尾,那该字符数组就是普通的字符数组,不是字符串。
C 语言中并不存在字符串这个数据类型,而是使用字符数组来保存字符串。那么,字符数组就一定是字符串吗?
不一定。字符串是一种特殊的字符数组,并且C语言提供了大量适用于字符串的工具。字符串和字符数组相比,字符串作为一种末尾带有’\0’ 结束符的特殊字符数组,更贴合于日常对于字符数组的使用需求:有明确的“自定义”结尾,摆脱了数组长度的限制,就可以更方便的应用于长度千变万化的日常语言中,只需要定义一个很长的字符数组,然后用’\0’控制使用区域,配合专门适用于字符串的一系列函数,使得字符串可以看做一种“变长字符数组”,使用的灵活性大大增加。 但是还远不到改变物种的程度。比如说定义一个字符数组Arr={‘h’,‘e’,‘l’,‘l’,‘o’,‘\0’},它应该是一个字符串还是一个字符数组呢?很显然字符串和字符数组并没有区分得那么干净利落一刀两断,而是一个大集合中的一部分特殊情况成为了小集合而已。
代码分析一
分析如下所示的示例代码。
#include 运行结果为:
cArr的长度=6
sArr的长度=7
cArr的长度=6
sArr的长度=6
cArr的内容=ILOVEC
sArr的内容=ILOVEC
从代码及其运行结果中可以看出如下几点。
首先,从概念上讲,cArr 是一个字符数组,而 sArr 是一个字符串。
因此,对于 sArr,编译时会自动在末尾增加一个 null 字符(也就是’\0’,用十六进制表示为 0x00);而对于 cArr,则不会自动增加任何东西。
记住,这里的 sArr 必须是char sArr[7]=“ILOVEC”,而不能够是char sArr[6]=“ILOVEC”。
其次,sizeof()运算符求的是字符数组的长度,而不是字符串长度。因此,对于sizeof(cArr),其运行结果为 6;而对于 sizeof(sArr),其运行结果为 7(之所以为 7,是因为 sArr 是一个字符串,编译时会自动在末尾增加一个 null 字符)。因此,对于以下代码:
/*字符数组赋初值*/
char cArr[] = {'I','L','O','V','E','C'};
/*字符串赋初值*/
char sArr[] = "ILOVEC";
也可以写成如下等价形式:
/*字符数组赋初值*/
char cArr[6] = {'I','L','O','V','E','C'};
/*字符串赋初值*/
char sArr[7] = "ILOVEC";
最后,对于字符串 sArr,可以直接使用 printf 的 %s 打印其内容;而对字符数组,很显然使用 printf 的 %s 打印其内容是不合适的。
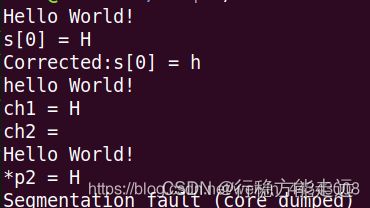
代码分析二
#include 运行结果
总结
通过对以上代码的分析,现在我们可以很简单地得出字符数组和字符串二者之间的区别:
- 字符数组长度是固定的,其中任何一个数组元素都可以为 null 字符。因此,字符数组不一定是字符串。
- 字符串必须以 null 结尾,其后的字符不属于该字符串。字符串一定是字符数组,它是最后一个字符为 null 字符的字符数组。
- 数组的元素可以是任意一种类型,而字符串是一种特殊的数组,它使用了一种众所周知的确定其长度的规则。
- 有两种类型的语言,一种简单地将字符串看作是一个字符数组,另一种将字符串看作是一种特殊的类型。C属于前一种,但有一点补充,即C字符串是以一个NUL字符结束的。数组的值和数组中第一个元素的地址(或指向该元素的指针)是相同的,因此通常一个C字符串和一个字符指针是等价的。
一个数组的长度可以是任意的。当数组名用作函数的参数时,函数无法通过数组名本身知道数组的大小,因此必须引入某种规则。对字符串来说,这种规则就是字符串的最后一个字符是ASCII字符NUL(‘\0’)。
在C中,int类型值的字面值可以是42这样的值,字符的字面值可以是‘*’这样的值,浮点型值的字面值可以是4.2el这样的单精度值或双精度值。
注意:实际上,一个char类型字面值是一个int类型字面值的另一种表示方式,只不过使用了一种有趣的句法,例如当42和’*'都表示char类型的值时,它们是两个完全相同的值。然而,在C++中情况有所不同,C++有真正的char类型字面值和char类型函数参数,并且通常会更仔细地区分char类型和int类型,整数数组和字符数组没有字面值。然而,如果没有字符串字面值,程序编写起来就会很困难,因此C提供了字符串字面值。需要注意的是,按照惯例C字符串总是以NUL字符结束,因此C字符串的字面值也以NUL字符结束,例如,“six times nine”的长度是15个字符(包括NUL终止符),而不是你看得见的14个字符。
关于字符串字面值还有一条鲜为人知但非常有用的规则,如果程序中有两条紧挨着的字符串字面值,编译程序会将它们当作一条长的字符串字面值来对待,并且只使用一个NUL终止符。也就是说,“Hello,”world”和“Hello,world”是相同的,而以下这段代码中的几条字符串字面值也可以任意分割组合:
char message[]=
”This is an extremely long prompt\n”
”How long is it?\n”
”It's so long,\n”
”It wouldn't fit On one line\n”;
在定义一个字符串变量时,你需要有一个足以容纳该字符串的数组或者指针,并且要保证为NUL终止符留出空间,例如,以下这段代码中就有一个问题:
char greeting[12];
strcpy(greeting,”Hello,world”); /*trouble*/
在上例中,greeting只有容纳12个字符的空间,而“Hello,world”的长度为13个字符(包括NUL终止符),因此NUL字符会被拷贝到greeting以外的某个位置,这可能会毁掉greetlng附近内存空间中的某些数据。再请看下例:
char greeting[12]=”Hello,world”;/*notastring*/
上例是没有问题的,但此时greeting是一个字符数组,而不是一个字符串。因为上例没有为NUL终止符留出空间,所以greeting不包含NUL字符。更好一些的方法是这样写:
char greeting[]=”Hello,world”;
这样编译程序就会计算出需要多少空间来容纳所有内容,包括NUL字符。
字符串字面值是字符(char类型)数组,而不是字符常量(const char类型)数组。尽管ANSIC委员会可以将字符串字面值重新定义为字符常量数组,但这会使已有的数百万行代码突然无法通过编译,从而引起巨大的混乱。如果你试图修改字符串字面值中的内容,编译程序是
不会阻止你的,但你不应该这样做。编译程序可能会选择禁止修改的内存区域来存放字符串字面值,例如ROM或者由内存映射寄存器禁止写操作的内存区域。但是,即使字符串字面值被存放在允许修改的内存区域中,编译程序还可能会使它们被共享。例如,如果你写了以下代码(并且字符串字面值是允许修改的):
char *p="message";
char *q="message";
p[4]='\0'; /* p now points to”mess”*/
编译程序就会作出两种可能的反应,一种是为p和q创建两个独立的字符串,在这种情况下,q仍然是“message”;一种是只创建一个字符串(p和q都指向它),在这种情况下,q将变成“mess”。
注意:有人称这种现象为“C的幽默”,正是因为这种幽默,绝大多数C程序员才会整天被自己编写的程序所困扰。