java系列
1 基础
1 相关开发包
1 时间类
(1)java.util.Date:表示日期和时间的类; 类Date表示特定的瞬间,精确到毫秒
时间原点:(0毫秒)1970年1月1日00:00:00(英国格林威治)
注意:中国属于东八区,会把时间增加8小时
1970年1月1日08:00:00
sout(system.currentTimeMillis());//获取当前系统时间到1970年1月1日经历了多少毫秒
一天=86400秒=86400000毫秒
【使用 SimpleDateFormat 格式化日期】
SimpleDateFormat ft = new SimpleDateFormat ("yyyy-MM-dd hh:mm:ss");
System.out.println("当前时间为: " + ft.format(dNow))
【使用printf格式化日期】
System.out.printf("年-月-日格式:%tF%n",date);
【Java 休眠(sleep)】
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CPU的使用、目的是不让当前线程 独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会。
2 java多线程
1.相关概念:
(1)CPU执行代码都是一条一条顺序执行的,,但是,即使是单核cpu,也可以同时运行多个任务。因为操作系统执行多任务实际上就是让CPU对多个任务轮流交替执行。例如,假设我们有语文、数学、英语3门作业要做,每个作业需要30分钟。我们把这3门作业看成是3个任务,可以做1分钟语文作业,再做1分钟数学作业,再做1分钟英语作业:这样轮流做下去,在某些人眼里看来,做作业的速度就非常快,看上去就像同时在做3门作业一样
类似的,操作系统轮流让多个任务交替执行,例如,让浏览器执行0.001秒,让QQ执行0.001秒,再让音乐播放器执行0.001秒,在人看来,CPU就是在同时执行多个任务。
即使是多核CPU,因为通常任务的数量远远多于CPU的核数,所以任务也是交替执行的。
(2)进程:计算机中,运行的浏览器就是一个进行,运行的qq就是一个进程。
(3)线程:某个进程里面还需要同时执行多个子任务,例如,我们在使用Word时,Word可以让我们一边打字,一边进行拼写检查,同时还可以在后台进行打印,我们把子任务称为线程。
(4)一个进程可以包含多个线程,但至少会有一个线程。
2.java中的多线程:
(1)一个java程序实际上就是一个JVM进程
(2)JVM进程用一个主线程来执行main()主方法,在main()方法内部,我们又可以启动多个线程。此外,JVM还有负责垃圾回收的其他工作线程等。
(3)对于大多数java程序来说,我们说多任务,实际上是说如何使用多线程实现多任务
(4)和单线程相比,多线程编程的特点在于:多线程经常需要读写共享数据,并且需要同步。例如,播放电影时,就必须由一个线程播放视频,另一个线程播放音频,两个线程需要协调运行,否则画面和声音就不同步。因此,多线程编程的复杂度高,调试更困难。
(5)线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)
(6)线程和进程一样分为五个阶段:创建、就绪、运行、阻塞、终止。
3.java中线程的实现方式:
(1)一种是继承Tread类
package com.example.demo.Tread;
class User extends Thread{
private String name;
public User(String name) {
this.name = name;
}
public void run(){
for (int i = 0; i < 5; i++) {
System.out.println(name+"运行"+i);
try {
sleep((int) (Math.random()*10));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Main {
public static void main(String[] args) {
User a = new User("a");
User b = new User("b");
a.start();
b.start();
}
}
打印结果:
a运行0
b运行0
a运行1
b运行1
a运行2
b运行2
a运行3
a运行4
b运行3
b运行4
总结:
程序启动运行main时候,java虚拟机启动一个进程,主线程main在main()调用时候被创建。随着调用a、b的两个对象的start方法,另外两个线程也启动了,这样,整个应用就在多线程下运行。
Thread.sleep()方法调用目的是不让当前线程独自霸占该进程所获取的CPU资源,以留出一定时间给其他线程执行的机会。
(2)另一种是实现Runable接口
package com.example.demo.Runnable;
class User2 implements Runnable{
private String name;
public User2(String name){
this.name=name;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(name +"运行"+i);
try {
Thread.sleep((int) (Math.random()*10));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Main{
public static void main(String[] args) {
new Thread(new User2("c")).start();
new Thread(new User2("d")).start();
}
}
运行结果:
c运行0
d运行0
d运行1
d运行2
c运行1
d运行3
c运行2
d运行4
c运行3
c运行4总结:
不管是继承Tread类还是实现Runnable接口,都是通过Tread.strat()方法开启多线程。
(3)Tread和Runnable的区别:
如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
(4)Runnable的优势:
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
2):可以避免java中的单继承的限制
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
4):线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类
4.线程中·状态的转换:
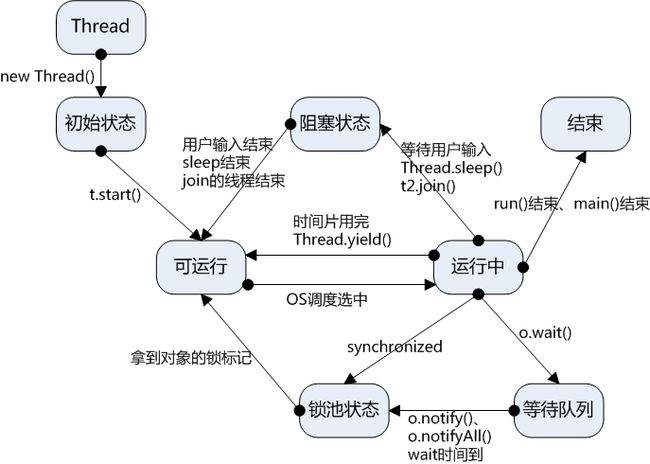
5.线程中的相关方法:
(1)sleep():线程睡眠:Thread.sleep(long millis)方法,使线程转到阻塞状态。millis参数设定睡眠的时间,以毫秒为单位。当睡眠结束后,就转为就绪(Runnable)状态。sleep()平台移植性好。
(2)
参考博客:
(1)多线程基础 - 廖雪峰的官方网站 (liaoxuefeng.com)
(2)Java多线程学习(吐血超详细总结)_Evankaka的博客-CSDN博客_java 多线程
(3)Java多线程学习(吐血超详细总结)_Evankaka的博客-CSDN博客_java 多线程
3 java文件上传
1.相关方法:
(1)后端用MutipartFile类来接受前台传过来的文件
public R upFile(HttpServletResponse res, HttpServletRequest req, @RequrstParam("file") MultipertFile file){
} (2)使用transferTo()方法将接收到的文件存储到相应路径:
file.transferTo(new File(path,filename));(3)获取上传的文件名:
String fileName = file.getOriginalFilename;(4)new File生成的对象:我们可以对对象进行解析和删除:
toFile = new File(path,file.getOriginalFilename());
//可以对toFile对象进行文件上传、删除、解析文件内容等操作
//删除
toFile.delete();
//上传
file.tansferTo(toFile);
//解析
xxxUtils.xxxparse(toFile);(5)指定文件上传的路径:
String path = request.getSession().getServletContext().getRealPath("C://dengsir");参考博客:SpringMVC之 实现文件上传 - 简书
4 Java中的long类型和Long类型比较大小问题
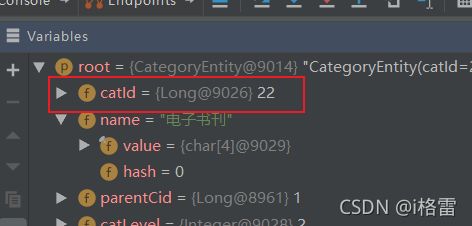
1.做谷粒商城项目新增菜单的时候遇到了这个问题:
这里会有一个bug:
return categoryEntity.getParentCid() == root.getCatId();新建层级不能显示是因为递归filter过滤的时候catId和父id是Long对象,所以==不行要用equils
两个Long对象值超过127的时候就不能用== 号来进行比较了,必须使用equals。
在后台debug可以看到catId的类型:
2.Integer包装类型与Long类型一样,不在赘述
参考博客:
(1)Java中的long类型和Long类型比较大小_有梦想的攻城狮的博客-CSDN博客_java long比较大小
(2)Long类型数据比较_小白找大神的博客-CSDN博客_long比较
5 java中解析json时parse()和parseObject()和parseArray()的区别
1.JSON.parseArray()和JSON.parseObject都是讲json字符串转为实体类的方法
(1)JSON.parseArray用于json是[]包裹的。
(2)JSON.parseObject用于json是{}包裹的。
(3)用JSON.toJSONString()来解析对象。
2.JSON.parse()与JSON.parseObject()的区别:
package com.example.demo.JSON;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
public class json1 {
public static void main(String[] args) {
String json = "{\"name\": \"张三\",\"age\": 27,\"address\": \"北京市 朝阳区\",\"phone\": \"15326564587\"}";
Object obj = JSON.parse(json);
JSONObject jsonObject = JSON.parseObject(json);
String name = jsonObject.getString("name");
System.out.println(obj);
System.out.println(jsonObject);
System.out.println(name);
}
}
输出结果:
{"address":"北京市 朝阳区","phone":"15326564587","name":"张三","age":27}
{"address":"北京市 朝阳区","phone":"15326564587","name":"张三","age":27}
张三二者转化的结果都是一个json对象,没有区别。
但是JSON.parseObject()生成的对象有许多可以操作的方法,所以后端一般都用JSON.parseObject()来解析json字符串:

6 java中常见的json格式以及不同格式json的解析
参考博客:
Java常见的Json格式_王玉见的博客-CSDN博客_java json格式
7 java中JSONObject和JSONArray的区别:
1.JSONObject表示对象json:{"name":"tom"}
JSONObject jsonObject = new JSONObject(json);2.JSONArray表示数组json:["tom","kate"]
JSONArray jsonArray = new JSONArray(json);后端中想把一个json字符串(键值对形式)转化为对象的方法:
其中data是“键值对”形式的json字符串。
JSONObject jsonObject = JSON.parseObject(data);如果想从刚刚获得的jsonObject对象中获取对象里面的数组:可以用JSONArray:
JSONArray jsonArray = jsonObject.getJSONArray("arrays");如果刚刚获得的数组对象里面还包含的有很多对象,并且对象里还包含数组:如何获得里面的数组
for(int i = 0;i参考博客:
(1)JSON.parseObject(String str)与JSONObject.parseObject(String str)的区别 - 每一天,为明天 - 博客园
(2)秒懂JSONArray和JSONObject的区别和使用_倩女有文的博客-CSDN博客_jsonarray jsonobject
8java8新特性
1.sream()流:
2.lambda表达式:
3.optionnal:
9java常见异常
1.空指针异常:NullPointerException
2.
10 Java的List集合判断是否存在某个元素常用的方法
参考此博客:
(29条消息) Java的List集合判断是否存在某个元素常用的几种方法_东哥_Jeffery的博客-CSDN博客_java判断集合是否包含某个元素
1.可以用contains方法判断
2.如果需要忽略大小写或者做其他操作,则用steam().anyMatch()
public class List1 {
public static void main(String[] args) {
List name = Arrays.asList("A_B_C","sadsa","dasd");
List list = new ArrayList<>();
list.add("a_b_c");
list.add("dd");
list.add("fg");
list.add("fx");
for (String d: name) {
boolean flag = list.stream().anyMatch(t -> t.equalsIgnoreCase(d));
System.out.println(flag);
}
}
}
11 number类
1.valueOf():我目前理解他的作用时对象转换,不过String转Int时,如果String不是纯数字则无法转换
![]()
![]()
2 关键字和函数
1 关键字
(1)final关键字
final关键字代表最终的,不可改变的。
常见的四种用法:
修饰一个类、方法、局部变量、成员变量
final关键字用于修饰类
当final关键字用来修饰一个类的时候,格式:
public final class 类名称{}
含义:当前这个类不能有任何子类(太监类)
注意:一个类如果是final的,那么其中所有的成员方法都无法进行覆盖重写。(因为没有子类)
final关键字修饰成员方法
当final关键字用来修饰一个方法的时候,这个方法就是最终方法,也就是不能被覆盖重写。
格式:
修饰符 final 返回值类型 方法名称(参数列表){}
注意:对于类,方法来说,abstract关键字和final关键字不能同时使用,因为矛盾。
因为abstract一定要被覆盖重写,他没有方法体,final不能被覆盖重写。
final关键字局部变量
final int num=20;
一旦使用final关键字修饰局部变量,那么这个变量就不能进行更改。(一次赋值,终身不变)
对于基本数据类型来说,不可变说的是变量当中的数据不可改变;
对于引用数据类型来说,不可变说的是变量当中的地址值不可改变。
final关键字修饰成员变量
1.由于成员变量具有默值,所以用了final关键字之后必须手动进行赋值,不会再给默认值了。
2.对于final得成员变量,要么使用直接复制,要么通过构造方法赋值。二者选其一。
3.必须保证类当中所有重载的构造方法,都会最终对final的成员变量进行赋值。
2 split方法
概念
1.split是java.Lang.String包下的方法,可以按照指定分隔符将字符串进行分割,然后会返回字符串数组
2.split函数:public String[] split(String regex, int limit)
(1)regix:正则表达式分隔符
(2)limit:分割份数
用法
1.(java)编程中用反斜杠 \ 加字符表示转义字符:如\0表示“空字符” \r表示回车 \n表示换行 。 而 \\来表示反斜杠\的转义字符。
具体转义字符可参照此博客:(22条消息) java中的转义字符_稻草人的格子衫-CSDN博客
(1)正斜杠:/
(2)反斜杠:\
(3)编程中 \\用来表示反斜杠 \不是普通字符,而是路径的分隔符。如用字符串保存文件存储路径:文件D:\jita\qingtian\img.jpg,字符串中应写为:String a = D:\\jita\\qingtian\\img.jpg。若不这样表示,则程序中会将反斜杠 \ 当作普通字符,而非路径的分隔符。
2.String a="hello.world"
String[] b = a.split("\\.")
因为java中 . * | \ { }为转义字符
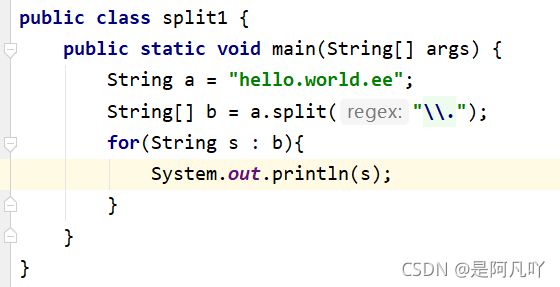

3. / 可以正常分割


4.\\用\\\\进行分割
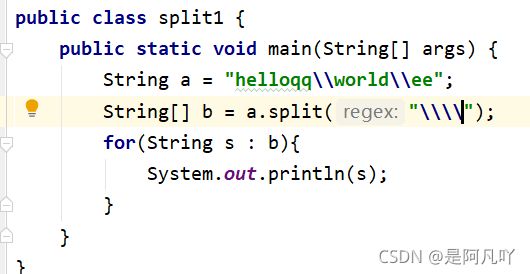

5.split分割多个字符,需要用 | 进行连接
6.用\\s来分割空格:
package com.example.demo.split;
import java.text.SimpleDateFormat;
import java.util.Date;
import static java.lang.Thread.sleep;
public class split1 {
public static void main(String[] args) throws InterruptedException {
String a = "20条/页";
String[] b = "20条/页".split("条");
System.out.println(b[0]);
sleep(2000);
for(String s : b){
System.out.println(s);
}
Date date = new Date();
SimpleDateFormat format=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String format1 = format.format(date);
System.out.println(format1);
String[] split = format1.split("\\s");
System.out.println(split[0]);
}
}
输出结果:
20
20
/页
2021-11-05 09:35:05
2021-11-05
Process finished with exit code 0
3 Java中文件上传的输入输出流,读取写入的文件内容
/*------------------------
FileOutputStream:
....//输出流,字节流
....//write(byte[] b)方法: 将b.length个字节从指定字节数组写入此文件输出流中
....//write(byte[] b, int off, int len)方法:将指定字节数组中从偏移量off开始的len个字节写入此文件输出流
-------------------------*/
package pack02;
import java.io.*;
public class Demo {
public static void main(String[] args) {
testMethod1(); //从程序中向一个文件写入数据
testMethod2(); //复制一个文件的内容到另一个文件
}
//从程序中向一个文件写入数据
public static void testMethod1() {
File file1 = new File( "d:/TEST/MyFile1.txt" );
FileOutputStream fos = null ;
try {
fos = new FileOutputStream(file1); //将FileOutputStream流对象连接到file1代表的文件
fos.write( new String( "This is MyFile1.txt" ).getBytes() );
//使用方法write(byte[] b),即向文件写入一个byte数组的内容
//这里创建一个字符串对象,并调用方法getBytes(),将其转换成一个字符数组作为write(byte[] b)的形参
//当文件MyFile1.txt不存在时,该方法会自动创建一个这个文件;当文件已经存在时,该方法会创建一个新的同名文件进行覆盖并写入数组内容
} catch (IOException e) {
e.printStackTrace();
} finally {
if ( fos != null )
try {
fos.close(); //关闭流
} catch (IOException e) {
e.printStackTrace();
}
}
}
//从一个文件读取数据,然后写入到另一个文件中;相当于内容的复制
public static void testMethod2() {
File fileIN = new File( "d:/TEST/MyFile2.txt" ); //定义输入文件
File fileOUT = new File( "d:/TEST/MyFile3.txt" ); //定义输出文件
FileInputStream fis = null ;
FileOutputStream fos = null ;
try {
fis = new FileInputStream(fileIN); //输入流连接到输入文件
fos = new FileOutputStream(fileOUT); //输出流连接到输出文件
byte [] arr = new byte [ 10 ]; //该数组用来存入从输入文件中读取到的数据
int len; //变量len用来存储每次读取数据后的返回值
while ( ( len=fis.read(arr) ) != - 1 ) {
fos.write(arr, 0 , len);
} //while循环:每次从输入文件读取数据后,都写入到输出文件中
} catch (IOException e) {
e.printStackTrace();
}
//关闭流
try {
fis.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}4 《java开发手册》阅读笔记
命名风格:
1.代码中的命名均不能以下划线或$开头或结尾。_和$
2.类名使用大驼峰风格(UpperCamelCase)
方法名,参数名,局部变量,成员变量使用小驼峰风格(LowerCamelCase)
3.常量命名全部大写,单词之间使用_分隔。
4.设计模式:他不是语法规定,而是一套用来提高代码复用性,,可维护性,可读性,以及安全性的解决方案。(95年,Gof四人组出版了包含23钟设计模式的书,所以人称Gof设计模式)
5.设计模式的六大原则:
总原则:开闭原则:一个软件的实体,如类、模块、函数应对扩展开放,对修改关闭(想要达到这样的效果,我们需要使用接口和抽象类)
(1)单一职责原则:每个类应该实现单一的职责,否则就应该把类拆分
(2)里氏替换原则:子类对父类的方法尽量不要重载和重写;而是在父类的基础上增加新的行为
(3)依赖倒置原则:面向接口编程时,依赖于抽象而不依赖于具体。写代码时用到具体类时,不与具体类交互,而与具体类的上层接口接触
(4)接口隔离原则:每个接口中不存在子类用不到却必须实现的方法,如果不然,就要将接口拆分
(5)迪米特法则(最少知道原则):一个类对自己依赖的类知道的越少越好。无论被依赖的类多么复杂,都应将逻辑封装在方法的内部,通过public方法提供给外部这样当被依赖的类变化时,才能最小影响该类。
(6)合成复用规则:尽量使用对象的组合或聚合,而不是继承达到复用的目的。(合成或聚合可以将已有的对象纳入到新对象中,使之成为新对象的一部分,因此新对象可以调用已有对象的功能)
设计模式的三大类:
1.创建型模式:对类的实例化过程进行了抽象,能够将软件模块中对象的创建和使用分离
5种:工厂模式,抽象工厂模式,单例模式,建造者模式,原型模式
2.结构型模式:关注于对象的组成以及对象之间的依赖关系,描述如何将类或者对象结合在一起形成更大的结构,就像搭积木,可以通过简单积木的组合形成复杂的,功能更为强大的结构。
7种:适配器模式,装饰着模式,代理模式,外观模式,桥接模式,组合模式,享元模式
3.行为型模式:关注于对象的行为问题,是对在不同的对象之间划分责任和算法的抽象化;不仅仅关注类和对象的结构,而且重点关注它们之间的相互作用。
11种:策略模式,模板方法模式,观察者模式,迭代器模式,责任链模式,命令模式,备忘录模式,状态模式,访问者模式,中介者模式,解释器模式。
参考文章:快速记忆23种设计模式 - 知乎 (zhihu.com)
缓存击穿
1.什么样的数据适合缓存:访问频率高,读多写少,一致性要求低。
2.什么是缓存击穿:在高并发下,多线程同时查询同一个资源,如果缓存中没有这个资源,那么这些线程都会区数据库查找,对数据库造成很大的压力,缓存失去存在的意义。打个比方,数据库是人,缓存是防弹衣,子弹是线程,本来防弹衣是防止子弹打到人身上的,但是当防弹衣里面没有了防弹的材料时,子弹就会穿过他打到人身上。
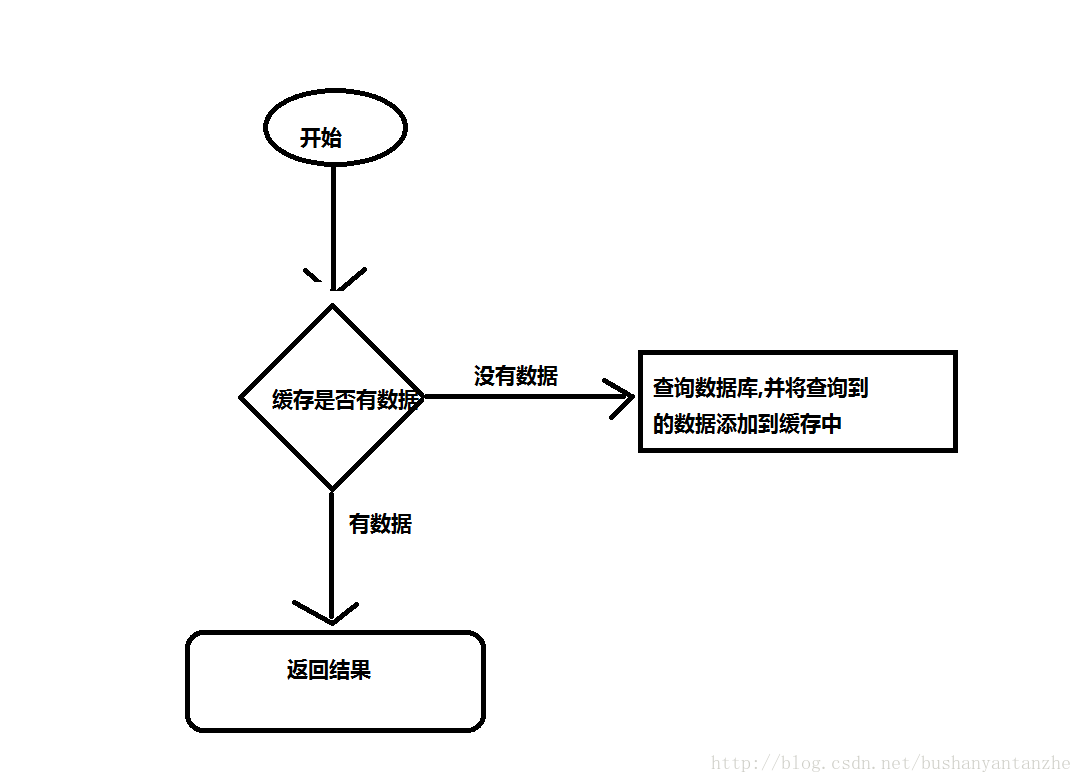
3.缓存击穿解决方案:
(1)设置热点数据永不过期
(2)接口的限流与熔断,降级:重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备当接口中的某些服务不可用的时候,进行熔断,失败快速返回机制。
(3)布隆过滤器:bloomfilter就类似于一个hash set,用于快速判断
某个元素是否存在于 集合中,某典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回 。布隆过滤器的关键就在于hash算法和容器大小。
(4)加互斥锁:
public static String getData (String key) throws InterruptedException{
//从缓存中获取数据
String result =getDataFromRedis(key);
//缓存中不存在数据
if (result==null){
//去获取锁,获取成功,去数据库取数据
if(reenLock.tryLock()){
//从数据库获取数据
result=getDataFromMysql(key);
//更新缓存数据
if(result!=null){
setDataToCache(key,result);
}
//释放锁
reenLock.uplock();
}
//获取锁失败
else{
//暂停100ms在重新去获取数据
Thread。sleep(100);
result=getData(key);
}
}
return result;
}
1.Object的equals方法容易抛空指针异常,应使用常量或有确定值的对象来调用equals.
例如:"dengsir".equals(object);
而不能object.equals("dengsir");
2.java数据类型:
基本数据类型:4类8种
整型:分为字节型(byte,一字节,范围:-128~127),整型(int,4字节),长整型(long,8字节),短整型(short,2字节)
字符型:char,2字节
浮点型:分为单精度浮点型(float,4字节),双精度浮点型(double,8字节)
布尔型:boolean,1字节
引用数据类型:类,接口,数组
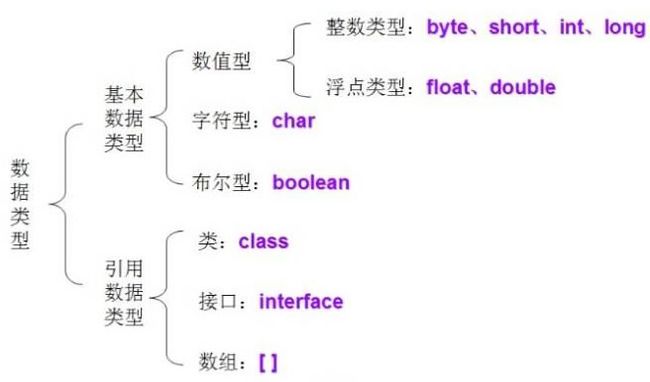
3.所有整型包装对象之间值得比较,全部使用equals方法比较,对于Integer var=?,在-128~127范围内的赋值,可以直接使用==进行判断。
4.浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用equals来判断。
float a = 1.0f-0.9f;
float b = 0.9f-0.8f;
if(a==b){
//预期进入此代码块,执行其他业务逻辑
//但事实上a==b的结果为false
}
Float x =Float.valueOf(a);
Float y = Float.valueOf(b);
if(x.equals(y)){
// 预期进入此代码块,执行其他业务逻辑
// 但事实上equals的结果为false
}
5java中常用的正则表达式
1.日期(yyyy-mm-dd): /^\d{4}-\d{2}-\d{2}$/
2.手机号码(11位数字): /^1\d{10}$/
3.真实姓名(非空):/^[\s\S]*.*[^\s][\s\S]*$/
6 Map集合转换为List集合的方法
1、方法一
List result = new ArrayList(map.keySet());
List result2 = new ArrayList(map.values()); 2、方法二
List result = map.keySet().stream().collect(Collectors.toList());
List result2 = map.values().stream().collect(Collectors.toList()); 参考博客:Java 8 将Map转换为List_HD243608836的博客-CSDN博客_map转list
2 框架
1.AOP
名称:面向切面编程.
一句话总结: 在不改变原有代码的条件下,对功能进行扩展.
公式: AOP = 切入点表达式 + 通知方法.
专业术语:
1.连接点: 在执行正常的业务过程中满足了切入点表达式时进入切面的点.(织入) 多个
2.通知: 在切面中执行的具体的业务(扩展) 方法
3.切入点: 能够进入切面的一个判断 if判断 一个
4.目标方法: 将要执行的真实的业务逻辑.
2 springbootjpa
1.创建一个springboot工程,选择Spring Initializr工程,选择Spring Boot DevTools,Lombok,Spring Web,JDBC API,Spring Data JPA ,Spring Data JDBC,MySQL Driver驱动等相关依赖。
1.在application.properties配置数据库,配置好后jpa工程便可正常启动。
(1)appilication.properties写法:
# 服务端口
server.port=8003
# 服务名
spring.application.name=service-cms
# mysql数据库连接
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/travels?serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=woaini560
#nacos服务地址
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
#返回json的全局时间格式
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
spring.jackson.time-zone=GMT+8
#配置mapper xml文件的路径
mybatis-plus.mapper-locations=classpath:com/bianchengguo/cmsservice/mapper/xml/*.xml
spring.redis.host=175.24.2.183
spring.redis.port=6379
spring.redis.database= 0
spring.redis.timeout=1800000
spring.redis.lettuce.pool.max-active=20
spring.redis.lettuce.pool.max-wait=-1
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-idle=5
spring.redis.lettuce.pool.min-idle=0
#mybatis日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl(2)application.yml写法
server:
port: 8086
spring:
#通用的数据源配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8&userSSL=true&serverTimezone=UTC
username: root
password: 123456
jpa:
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
show-sql: true
hibernate:
2.先创建User实体类,跟数据库表字段保持一致
jpa的两个注解:
(1)@Entity:表示这是一个实体类
(2)@Id:表示这人是主键
两个注解完成了实体类User和数据库表的映射。
3.写具体操作数据库类JpaRepository接口(创建固定的接口,需要继承JpaRepository。参数为
public interface UserRepository extends JpaRepository
4.创建controller类,展示数据。
拓展:
(1)select:查询user表中的所有数据:select * from user;
(2)insert into:向user表中插入数据的SQL语句insert into user(id,name,tid) values(3,"dengsir",2);
(3)replace into:向user表中插入数据,如果表中已存在插入的数据(通过主键判断),则覆盖表中原来的数据:
replace into user(id,name,tid) values(3,"wangwu",2);
(4)insert ignore into:向user表中插入数据,如果表中已经存在此条数据(通过主键判断),则忽略不插入,如果不存在,则插入:
insert ignore into user(id,name,tid) values(3,"wangwu",2);
(5)insert批量插入:insert into user(id,name,tid) values(4,"dengsir",2),(5,"haiqin",2);
(6)数据迁移插入:将student表中查出来的数据插入到user表中实现数据迁移:
insert into user(id,name,tid) select id,name from student;
(7)update:更改user表中的数据:
update user set name="dengsir" where id=1;(如果不加where条件,将会更改user表中所有的数据)
(8)delete:删除user表中的数据:delete from user where name="dengsir";(如果不加where条件,将会删除user表中所有的数据)
控制台报DataSource相关错误,原因基本是数据库没配,或者数据库用户名密码错误等问题。
参考视频资料:10分钟从0搭建项目写java接口,基于spring boot jpa框架,手把手教你敲代码_哔哩哔哩_bilibili
3 java操作redis
1.jedis和lettuce的区别:
(1)jedis是直连连接redis服务器。在多个线程之间共享一个jedis实例,线程不安全的,并发不安全。(如果想要在多线程的场景下使用jedis需要使用jedis连接池,此时每个线程都会使用自己的jedis的实例,当连接数增多时,会消耗比较多的物理资源。)
(2)lettuce是线程安全的,是基于Netty的连接方式,支持同步异步响应式操作,多个线程可以共享同一个连接实例,不用担心多线程的并发问题。并发安全
2.
(1)当spring版本为1.x时,springboot-data-redis默认集成的是jedis的客户端
(2)当spring版本为2.0以上时,springboot-data-redis默认集成的是lettuce的客户端
如果需要采用jedis,需要排除lettuce的依赖:
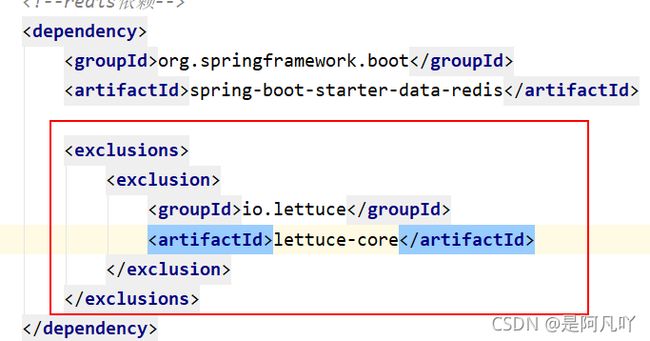
移除之后然后引入jedis依赖:

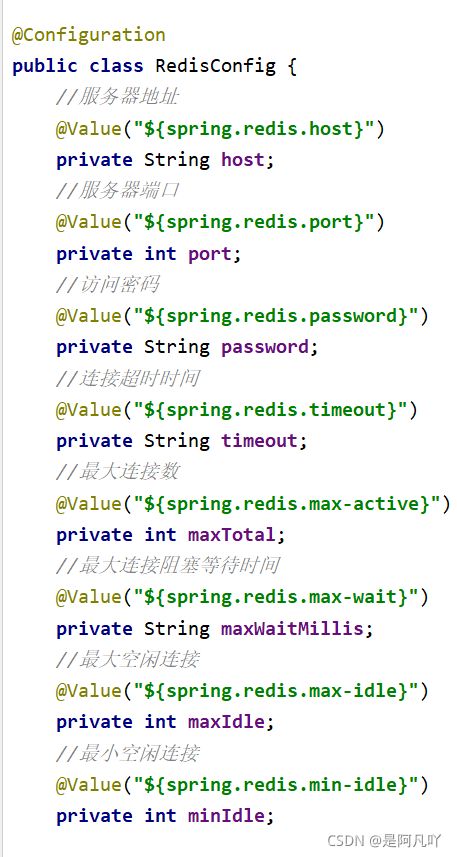
3.创建工程
(1)配置yml文件:

(2)jedis对象连接redis
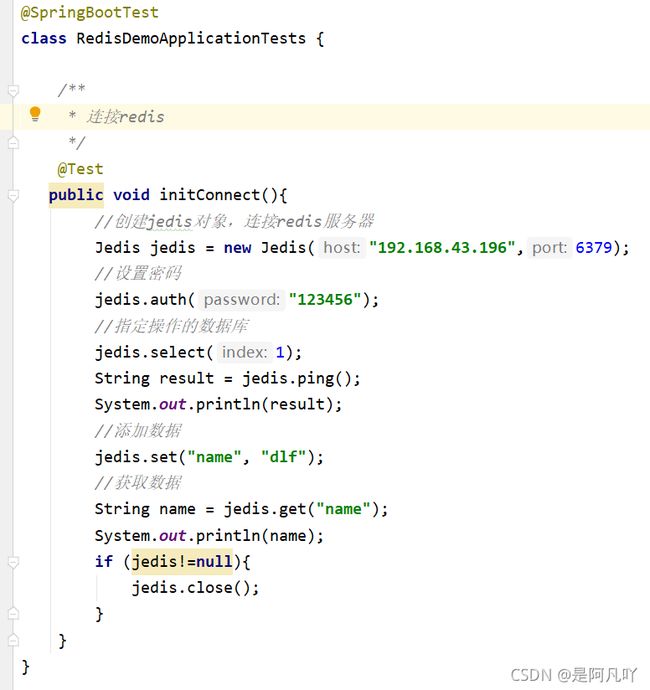
输出结果:

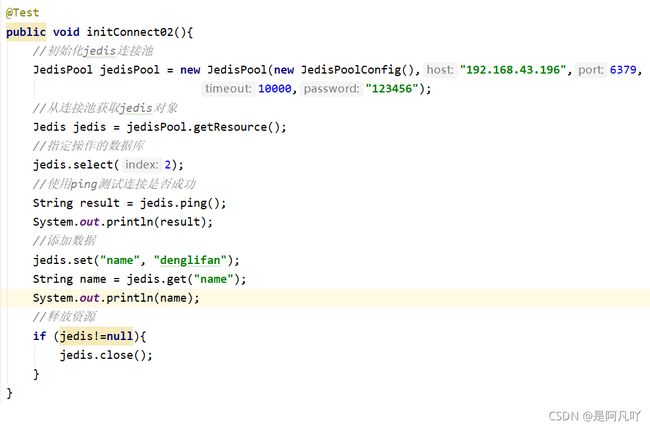
4.jedis连接池连接redis:
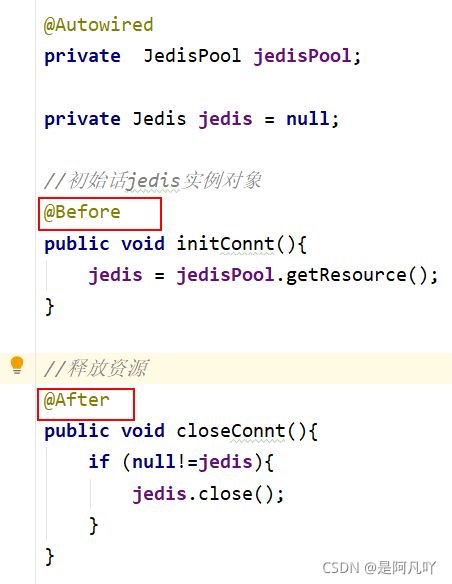
5.如果按4中操作redis每次都要新建连接池,造成资源浪费
实际开发中:当项目启动时,线程池自动新建(一次),不会频繁创建,jedis从线程池拿对象,使用完后释放资源,下次需要使用直接从线程池拿就行

![]()
6.jedis操作redis中String类型数据:


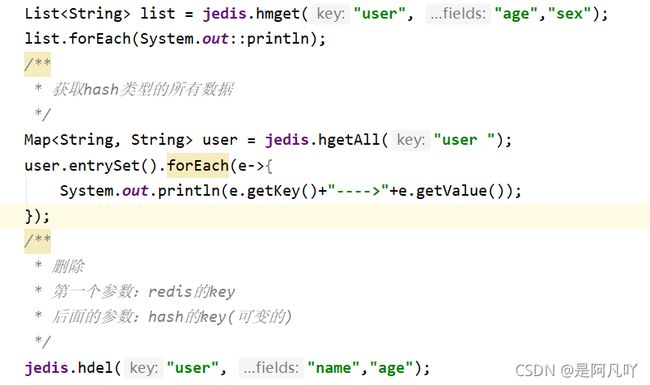
7.jedis操作redis中hash类型数据:


8..jedis操作redis中list类型数据:




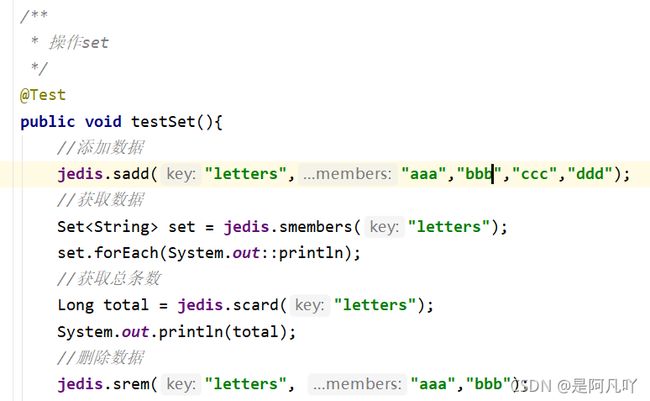
9.jedis操作redis中set类型数据:
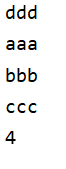
10.jedis操作redis中soted set类型数据:

11.(1)层级目录形式存储数据:

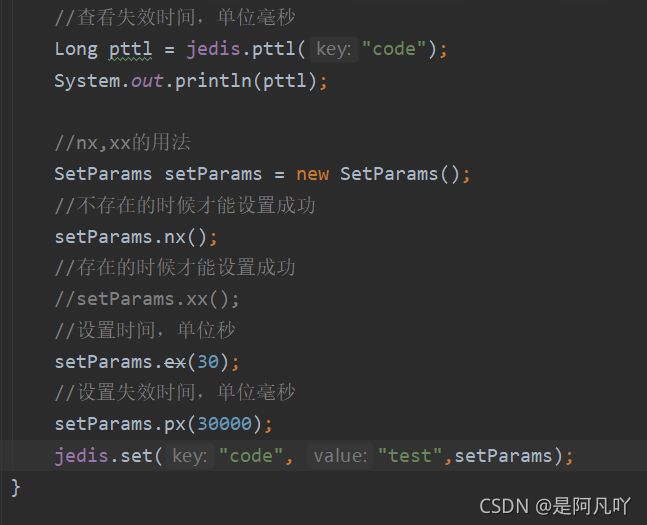
(2)设置key的失效时间
nx是key不存在的时候才生效
xx是key存在的时候才生效

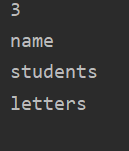
12.(1)查询所有key:

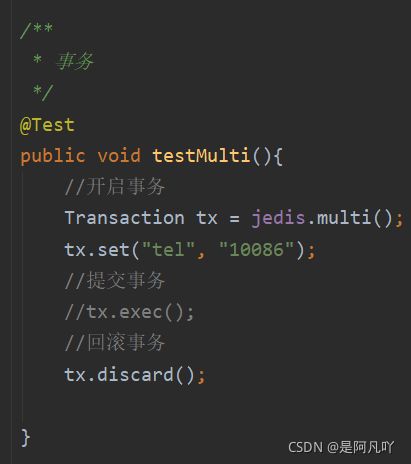
(2)redis是非关系型数据库,它不像mysql等关系型数据库一样有很强的事务性,mysql在多表(8张)操作时,如果一张表出现错误,其余7张表都会回滚到原来状态;而redis只有出错的那张表会回滚,其余表正常跟新(出错表前面的表更新,出错表后面的表不更新,中止在出错表处)
13.redis操作byte数组
![]()
至此,jedis操作redis相关知识点已完结!
4 单点登录
1.单一服务器登录:(没有集群,没有分布式)
(1)使用session对象实现
登陆成功后。把用户数据放在session里面。session.setAttribute(“name”,user)
判断是否登录,从session获取数据,可以获取到登录。Session.getAttribute(“name”)
Session默认过期时间:30分钟
2.SSO模式(单点登录):
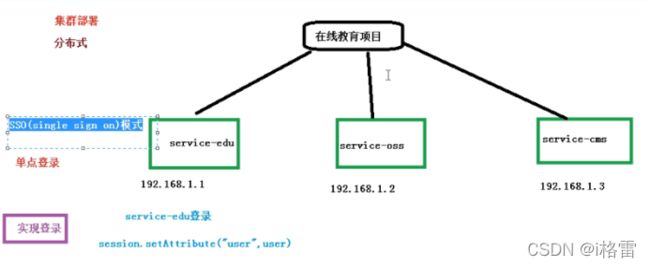
单点登录三种常见的方式:
Session广播机制实现:session复制,将session复制到其他模块中。(如果项目中模块太多,session复制消耗资源,所以此方式已经被淘汰)
使用cookie+redis实现(redis过期时间):在项目任何一个模块登录,登录之后,把数据放到两个地方。
Redis:---key:生成唯一随机值(ip、用户id等等) -----value:用户数据
Cookie:把redis生成的key的值放到cookie中。
访问项目中其他模块,发送请求带着cookie进行发送,获取cookie值,拿着cookie做事情:
把cookie获取的值,到redis中进行查询,根据key进行查询,如果查询到数据就是登录状态。
使用token实现:(Token可以称为令牌)
token是按照一定的规则生成的字符串,字符串可以包含用户信息-----进行base64编码,然后进行加密。所以token几乎不能进行破解。
在项目中的某个模块进行登录,登录之后,按照规则生成字符串,把用户登录信息包含到字符串里面,把字符串返回:
把字符串通过cookie返回
把字符串通过地址栏返回
再去访问项目中的其他模块,每次访问在地址栏带着生成的字符串,在访问模块里面获取地址栏字符串,根据字符串获取用户登录信息,如果可以获取到,就是登录。
3.JWT
Token术语:自包含令牌
JWT与token的关系:
JWT就是一种规则:生成token字符串的规则。(我们也可以自定义规则。JWT是一种通用的规则)

JWT生成的字符串包含三部分:
jwt头信息
有效载荷:用户信息
签名哈希:防伪标志(jwt字符串不能被修改)


Token和session的区别:
Session将用户信息存在服务端
Token将用户信息存在客户端。
客户端存储token,并在请求头中携带Token
token应该放在header中
需要将服务器设置为接收所有域的请求: Access-Control-Allow-Origin: *
用Token的好处
无状态和可扩展性
安全: 防止CSRF攻击;token过期重新认证
JWT特点:认串不认人。
举例:你买了彩票,中奖了,把彩票给你爸妈,爸妈也照样能兑奖,只要彩票是真的就行。
Go实现JWT代码:

此时得到未加密的token串:
![]()
5token鉴权
localStorage 和 sessionStorage 属性允许在浏览器中存储 key/value 对的数据。
sessionStorage 用于临时保存同一窗口(或标签页)的数据,在关闭窗口或标签页之后将会删除这些数据。
如果你想在浏览器窗口关闭后还保留数据,可以使用 localStorage 属性, 该数据对象没有过期时间,今天、下周、明年都能用,除非你手动去删除。
Cookie流程:浏览器发起http请求,服务器会进行cookie设置,也就是set-cookie。Cookie里面有名和值两个重要属性。服务器会把名和值属性里的内容填充完整。Cookie发给浏览器以后,浏览器会保存起来.。这样浏览器以后发送的每一个请求都会自动附上这个cookie。cookie就是存储在浏览器的数据。

因为cookie在浏览器能被看到。用户名密码保存在cookie里面是不安全的。
所以有了session(会话)机制:
浏览器访问服务器就是会话的开始,网站对每个用户的会话都设定了时间以及唯一的ID。这个ID就是SessionID。这个时间就是结束会话的时间。因为是服务器自己定义的东西。因此一般会保存在数据库里面。
有了用户名为什么还搞个SessionID?

用户登录网站。网站核实用户密码正确,则创建一个sessionID和会话结束时间
然后服务器SetCookie,将sessionID放到Cookie里面。再把会话结束时间,对应设置为这个Cookie的有效期。浏览器拿到cookie后进行保存。此时cookie中只有sessionID比较重要,也没有其他敏感信息。
SessionID是没有规律的字符串。服务器在发送cookie之前是会对这个含有SessionID的Cookie进行签名。就算是黑客修改了sessionID。sessionID就会变成服务器识别不了的字符串。
利用Cookie的特点,浏览器的每个请求,都会自动发送Cookie到服务器。即浏览器的任何访问都会发送sessionID给服务器。直到Cookie的有效期失效之后,浏览器就会自行删除这个Cookie。Cookie失效之后,用户就得重新输入用户名和密码才能进行会话。
在特定时间大量用户访问服务器时,需要创建存储大量SessionID,数据库如果宕机,会影响服务器拿到sessionID
这时就显示出token的作用了
JWT:全称JSON Web Token
不过在使用无状态 Token 的时候在服务端会有一些变化,服务端虽然不保存有效的 Token 了,却需要保存未到期却已注销的 Token。如果一个 Token 未到期就被用户主动注销,那么服务器需要保存这个被注销的 Token,以便下次收到使用这个仍在有效期内的 Token 时判其无效。有没有感到一点沮丧?
当 Token 无状态之后,单点登录就变得容易了。前端拿到一个有效的 Token,它就可以在任何同一体系的服务上认证通过——只要它们使用同样的密钥和算法来认证 Token 的有效性。就样这样
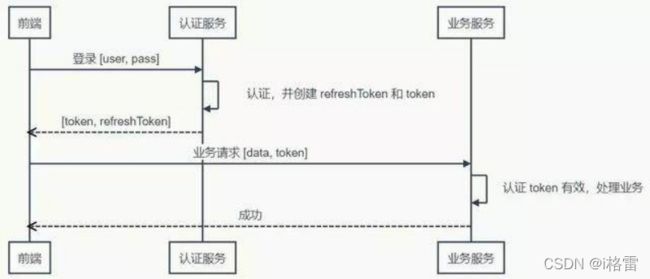
token的定义:Token是服务端生成的一串字符串,以作为客户端进行请求的一个令牌。
当然,如果 Token 过期了,前端仍然需要去认证服务更新 Token:
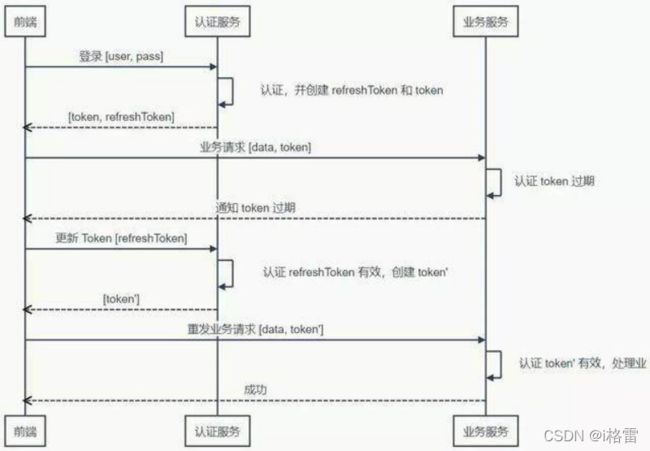
单点登录(SSO):
多系统只需要登陆一次:百度读书、百度新闻等等等产品(一处登录,多处可用)
