算法基础课:第二讲——数据结构
文章目录
- 单链表
-
-
- 算法思想:
- 注意点:
- 模板:
- 例题:
-
- AC代码:
-
- 双链表
-
-
- 算法思想:
- 注意点:
- 模板:
- 例题:
-
- AC代码:
-
- 栈
-
-
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- 队列
-
-
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- 单调栈
-
-
- 作用:
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- 单调队列
-
-
- 作用:
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- KMP
-
-
- 作用:
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- Trie
-
-
- 作用:
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- 并查集
-
-
- 作用:
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- 堆
-
-
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
-
- 哈希表
-
- 基础哈希
-
- 作用:
- 算法思想:
- 模板:
- 注意点:
- 例题:
-
- AC代码:
- 字符串哈希
-
- 作用:
- 算法思想:
- 模板:
- 例题:
-
- AC代码:
- STL简介
-
- 1.Vector
-
- 1.1 介绍
- 1.2 定义方式
- 1.3 支持函数
- 1.4 其他
- 2.Pair
-
- 2.1 介绍
- 2.2 定义方式
- 2.3 支持函数
- 2.4 其他
- 3.String
-
- 3.1 介绍
- 3.2 定义方式
- 3.3 支持函数
- 3.4 其他
- 4.Queue
-
- 4.1 介绍
- 4.2 定义
- 4.3 支持函数
- 5.Priority_queue
-
- 5.1 介绍
- 5.2 定义
- 5.3 支持函数
- 6.Stack
-
- 6.1 介绍
- 6.2 定义
- 6.3 支持函数
- 7.Deque
-
- 7.1 介绍
- 7.2 支持函数
- 8.Set
-
- 8.1 介绍
- 8.2 支持函数 (复杂度都为O(logn))
- 9.Map
-
- 9.1 介绍
- 9.2 定义
- 9.3 支持函数
- 10.Unordered_set
-
- 10.1 介绍
- 11.Bitset
-
- 11.1 介绍
- 11.2 定义
- 11.3 支持函数
单链表
算法思想:
使用结构体链表每次new一个新结点将耗费大量时间,所以采用数组模拟链表,虽然会造成空间浪费(比赛中可以忽视),但速度很快。
主要的就是插入和删除两个操作
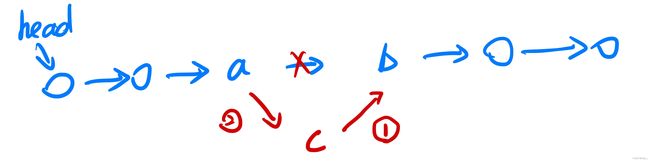
插入:要在a -> b间插入c
(1)先将 c 的 next 指向 b
(2)再将 a 的 next 指向 c
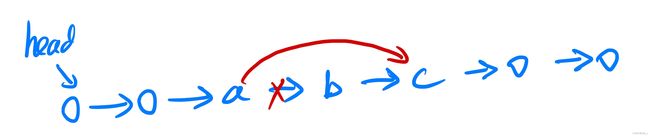
删除:要在 a -> b -> c 中删除 b
(1)直接将 a 的next 指向 c
(2)不必管 b -> c ,由于是单链表,从头向后进行遍历时会跳过b直接从a遍历到c
注意点:
(1)head并不是真正的一个结点,而是类似一个标签指向一个结点,告诉你这个结点是头结点,head没有数据域,仅仅存储当前头结点的下标
(2)idx的作用是记录当前要插入新结点时,会用到数组中哪一块,每次只需往后使用即可,不必考虑前面用过的某个数组块被删除了的回收问题
模板:
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 头插法
void add_to_head(int x)
{
e[idx] = x;
ne[idx] = head;
head = idx;
idx ++;
}
// 在下标为k的结点后面插入一个结点
void insert(int k, int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx;
idx ++;
}
// 删除下标为k的结点后面的一个结点
void remove(int k)
{
ne[k] = ne[ne[k]];
}
例题:
AcWing 826. 单链表
AC代码:
#include 双链表
算法思想:
与单链表不同,双链表会存左右两个指针分别指向左右两个结点
插入操作: 在下标 k 的结点后面插入一个 x
(1)先将idx的左右分别指向两边
(2)接着先将右边结点的左指针指向idx
(3)最后再将k结点的右指针指向idx
注意2、3顺序不能换

删除操作:删除下标为k的结点
(1)将k的右指针指向 k右边再右边的结点
(2)将k右边再右边的左指针指向k

注意点:
(1)r[0] 才是真正的头结点,同样l[1]才是真正的尾结点
(2)0为头指针,1为尾指针,idx 从 2 开始
(3)若要实现在 k 的左边插入 => 在 l[k] 的右边插入
模板:
// 初始化
void init()
{
r[0] = 1;
l[0] = 0;
idx = 2;
}
// 在下标k的点右边插入x
void insert(int k, int x)
{
e[idx] = x;
r[idx] = r[k];
l[idx] = k;
l[r[k]] = idx;
r[k] = idx;
idx ++;
}
// 删除下标为k的点
void remove(int k)
{
r[l[k]] = r[k];
l[r[k]] = l[k];
}
例题:
AcWing 827. 双链表
AC代码:
#include 栈
算法思想:
先进后出
模板:
// 入栈
stk[++ tt] = x;
// 出栈
tt --;
// 栈顶元素
stk[tt];
// 判断栈空
if (tt > 0) 非空
else 空
例题:
AcWing 828. 模拟栈
AC代码:
#include 队列
算法思想:
先进先出
模板:
// 入队
q[++ tt] = x;
// 出队
hh ++
// 判断队空
if (h <= tt) 非空;
else 空;
// 取队头元素
q[hh];
例题:
AcWing 829. 模拟队列
AC代码:
#include 单调栈
作用:
常见模型:找出每个数左边离它最近的比它大 / 小的数
算法思想:
对于一般的做法,我们可以采用双重for循环
for (int i = 0; i < n; i ++)
for (int j = i - 1; j >= 0; j --)
if (a[j] < a[i])
。。。
或者用一个栈,将a[i]左边所有的数依次存放进去,再将a[i]与栈顶进行比较,找到第一个小于a[i]的数
所以我们可以思考,能否找到一个性质,对栈进行优化
假定我们栈里面有一个 a[3] >= a[5] 那么对于a[6]以后的所有数来说, a[3]将永远用不到了,因为如果a[5]不但更小,而且离后面的数更近,所以栈里完全没有必要存a[3],所以对于每一个a[i],我们可以从栈顶进行判断,如果栈顶元素>= a[i] 就说明栈顶元素不会再被用到,弹出即可,直到栈顶元素 < a[i] 或者栈空,最后我们再将a[i]入栈,保证我们的栈是单调递增的
模板:
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}
例题:
AcWing 830. 单调栈
AC代码:
#include 单调队列
作用:
常见模型:找出滑动窗口中的最大值/最小值
算法思想:
维护一个队列,使得队列中的元素具有单调性,并在需要的时候将队头元素输出
单调性:对于一个未入队的新元素,将其不断和队尾元素进行比较,若不符合,则弹出队尾元素,直到找到新元素的合适位置
模板:
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
例题:
AcWing 154. 滑动窗口
AC代码:
#include KMP
作用:
字符串吗,模式匹配
算法思想:
判断s串中是否有p串对于常规做法,每当我们判断两个字符不相等时,就从第二个位置开始继续往后判断,这其中有很多浪费,所以我们要理解next数组的意义:让每次失败后,p串能够尽可能向后多移一点如红色方式,abab已经与前面判断相同了,可以直接往后移两个位置,节省时间

模板:
// 求next数组
void get_next() {
ne[1] = 0; //我们的下标从1开始, 题目中的下标从0开始
for (int i = 2, j = 0; i <= n; i++) {
while (j && p[i] != p[j + 1]) {
j = ne[j];
}
if (p[i] == p[j + 1]) {
j++;
}
ne[i] = j;
}
}
// kmp 匹配
for (int i = 1, j = 0; i <= m; i++) {
while (j && s[i] != p[j + 1]) {
j = ne[j];
}
if (s[i] == p[j + 1]) {
j++;
}
if (j == n) {
cout << i - n << " ";
j = ne[j];
}
}
例题:
AcWing 831. KMP字符串
AC代码:
#include Trie
作用:
快速存储和查找字符串或者数字集合的数据结构
算法思想:
按照每一位构造树的分支,进行存储,例如:

用idx唯一标识每一个结点(绿色部分),并在结尾处做标记,表示这是一个单词的结尾(红色部分),我们可以用cnt数组来记录,表示以该结点结尾的字符串的个数
模板:
// 插入一个新字符串
void insert(string str)
{
int p = 0;
for (int i = 0; str[i]; i ++)
{
int x = str[i] - 'a';
if (!trie[p][x]) trie[p][x] = ++ idx;
p = trie[p][x];
}
cnt[p] ++;
}
// 查询字符串个数
int query(string str)
{
int p = 0;
for (int i = 0; str[i]; i ++)
{
int x = str[i] - 'a';
if (!trie[p][x]) return 0;
p = trie[p][x];
}
return cnt[p];
}
例题:
AcWing 835. Trie字符串统计
AC代码:
#include 并查集
作用:
- 将两个集合合并
- 判断两个点是否在同一集合内
算法思想:
每个集合用一颗树来表示,树根的编号就是整个集合的编号,每个结点存储他的父结点,p[x] 表示 x 的父结点,px 为 x 的根结点。
如何判断树根: if (p[x] == x) x为树根
如何求 x 的树根: while (p[x] != x) x = p[x];
如何合并集合: px 为 x 的根,py 为 y 的根,则 p[px] = py,将 px 变成 py 的子树即可
如何判断两点是否在同一集合内: if (px = py) 则在一个集合内
find函数: 寻求根节点 + 路径优化(找根结点的时候,顺便将当前集合所有的点的父节点直接指向根节点)
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
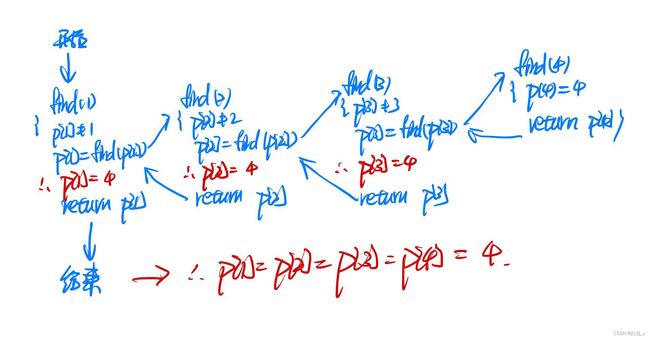
模板:
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
例题:
AcWing 836. 合并集合
AC代码:
#include 堆
算法思想:
堆的本质上是一棵完全二叉树,以小根堆为例,保证每个结点都 <= 它的两个子结点,所以根结点为所有结点的最小值
数组模拟堆支持以下五种操作:其中 h[N] 为数组,size为结点个数,对于结点 x,其左儿子的结点下标为 2x,右儿子结点下标为 2x + 1
插入一个数: heap[++ size] = x; up(size);
求当前集合最小值: heap[1];
删除最小值: heap[1] = heap[size]; size --; down(1);
删除任一元素: heap[k] = heap[size]; size --; down(k); up(k);
修改任一元素: heap[k] = x; down(k); up(k);
其中up函数为向上维护,down函数为向下维护,保证堆的性质。
down函数: 比较当前结点和他的两个儿子,选取最小的与当前结点的值交换,然后继续向下比较
up函数: 当前结点修改后小于根结点时,将当前结点与根节点进行交换,继续向上比较
模板:
// up函数
void up(int u)
{
while (u / 2 && h[u / 2] > h[u])
{
heap_swap(h[u / 2], h[u]);
u /= 2;
}
}
// down函数
void down(int u)
{
int t = u; // 记录最小值的下标
if (u * 2 <= cnt && h[t] > h[u * 2]) t = u * 2;
if (u * 2 + 1 <= cnt && h[t] > h[u * 2 + 1]) t = u * 2 + 1;
if (t != u)
{
swap(h[t], h[u]);
down(t);
}
}
// 建堆
for (int i = n / 2; ~ i; i --) down(i);
例题:
AcWing 838. 堆排序
AC代码:
#include 哈希表
基础哈希
作用:
对于一个集合的元素,添加元素或判断元素是否出现过
算法思想:
将若干元素经过hash函数处理后映射存到存储结构中,便于快速查找
hash函数一般取模如
int k = x % p
主要有两种存储结构:拉链法和开放寻址法
拉链法:当元素经过hash函数处理后,存入数组中时,若当前位置有元素在,则利用链表进行头插法,挂在下面,如图
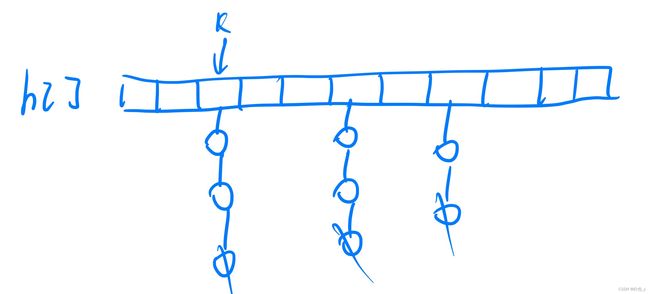
开放寻址法:当元素经过hash函数处理后,存入数组中时,若当前位置有元素在,则继续向后找,直到找到一个空位为止
模板:
// 拉链法
void insert(int x)
{
int k = (x & N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx;
idx ++;
}
bool query(int x)
{
int k = (x & N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
// 开放寻址法
int query(int x)
{
int k = (x % N + N) % N;
while (h[k] != null && h[k] != x)
{
k ++;
if (k == N) //查到底
k = 0;
}
return k;
}
注意点:
- 开放寻址法查询函数,若查找到元素即返回所在下标,未查到的话返回空位下标
- 离散化是一种特别的哈希方式
- 模数的取值,拉链法一般取大于数据范围的质数,开放寻址法要取2~3倍才能避免死循环
例题:
AcWing 840. 模拟散列表
AC代码:
// 开放寻址法
#include 字符串哈希
作用:
算法思想:
类比前缀和的思想,处理字符串的每一位,通过字符串前缀哈希法将字符串前缀转为一个P进制的数存储,每个前缀都对应唯一一种字符串
h[N] 存放字符串的前缀值
p[N]存放各个位数的相应权值
步骤 1 : 把字符串看作是P进制数 (P一般取131或者13331(经验值))

注:不能把字母 映射成0 ( 从1开始 )
步骤 2 : 预处理字符串所有的前缀hash值 h [ i ] = h [ i - 1 ] * P + str [ i ] ; str[i]这儿相当于str[i] * P^0
步骤 3 : 计算子串hash值公式 h [ r ] - h [ l - 1 ] * p [ r - l + 1 ] ;
模板:
// hash值计算公式
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
// 预处理
p[0] = 1;
for (int i = 1; i <= n; i ++)
{
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + str[i];
}
例题:
AcWing 841. 字符串哈希
AC代码:
#include STL简介
1.Vector
1.1 介绍
vector是变长数组,数组长度可以动态地变化,基本思想是倍增的思想:vector自动变长,但由于C++的特点,当系统为某一个程序分配空间时,所需的时间基本上与空间大小无关,与申请次数有关,所以变长数组要尽量减少申请次数
1.2 定义方式
vector<int> a; //定义vector
vector<int> a(N,X); //定义vector使其长度为N,每一个元素为X
vector<int> a[10]; //定义vector数组(10个vector)
1.3 支持函数
a.size() //返回vector里元素个数 时间复杂度为O(1)
a.empty() //判断vector是否为空,空返回True,非空返回False
a.clear() //清空vector
a.front() //返回第一个数
a.back() //返回最后一个数
a.push_back() //向vector最后插入一个数
a.pop_back() //把vector最后一个数删掉
a.begin() //迭代器,vector的第0个数
a.end() //迭代器,vector最后一个数的后面一个数
1.4 其他
- 遍历方法(三种)
//方法一:直接遍历
for(int i=0;i<a.size();i++) cout<<a[i]<<' ';
cout<<endl;
//方法二:迭代器(可以看成指针)
for(vector<int>::iterator i=a.begin();i!=a.end();i++ ) cout<<*i<<' ';
//a.begin()其实就是a[0] a.end()其实就是a[a.size()]
//其中vector::iterator可以直接写成auto
//auto是C++的关键字,可以让系统自动推断类型的关键字,当类型名较长时写auto会特别省事
//方法三:C++的范围遍历,C++使用的一种新的语法,代码会短一些,效率会快一些
for(auto x:a) cout<<x<<' ';
- 黑科技
vector支持比较运算,vector可以按照字典序进行比较运算,如vector a(4,3),b(3,4)中,a
2.Pair
2.1 介绍
pair的作用是存储一个二元组,前后两个变量类型是任意的,假设某一个东西有两种不同的属性,我们就可以用pair来存,也可以用来存储三个属性,可以看成帮我实现了一个结构体,并且自带了比较函数
2.2 定义方式
pair<int,string> p;
pair<int,pair<int,int>> p; //存储三个属性
//初始化
p=make_pair(10,"yzl");
p={10,"yzl"}
2.3 支持函数
p.first //取第一个元素
p.second //取第二个元素
2.4 其他
- 支持比较运算,以first为第一关键字,以second为第二关键字(字典序)
3.String
3.1 介绍
string其实是C++把字符串进行了封装,用string来存很方便
3.2 定义方式
string s;
string s="abc"; //定义字符串
3.3 支持函数
s.size();
s.empty();
s.clear();
s.length(); //返回字符串长度,与size作用相同
s.substr(st,l); //返回子串,从下标st开始返回长度为l的子串
//当l省略时,直接返回从下标st开始的整个子串
//当l长度过大,超过字符串本身时,就会输出到字符串结尾为止
s.c_str(); //返回string s存储字符数组的起始地址
printf("%s\n",a.c_str());
3.4 其他
- 字符串的添加
string a="abc";
a+="def"; //添加一个字符串
a+='g'; //添加字符
此时a的内容为abcdefg
4.Queue
4.1 介绍
队列
4.2 定义
queue<int> q;
q=queue<int>();
4.3 支持函数
q.size();
q.empty();
//无clear函数,若想清空,可以重新构造一个队列
q.push() //向队尾插入一个元素
q.front() //返回队头元素
q.back() //返回队尾元素
q.pop() //弹出队头元素
5.Priority_queue
5.1 介绍
注意:默认是大根堆!!!
5.2 定义
//大根堆:
priority_queue <类型> 变量名;
//小根堆:
priority_queue <类型,vecotr <类型>,greater <类型>> 变量名
5.3 支持函数
size(); 这个堆的长度
empty(); 返回这个堆是否为空
push();往堆里插入一个元素
top(); 返回堆顶元素
pop(); 弹出堆顶元素
注意:堆没有clear函数!!!
6.Stack
6.1 介绍
栈
6.2 定义
stack<int> stk;
6.3 支持函数
stk.size();
stk.empty();
//无clear函数
stk.push() //向栈顶插入一个元素
stk.top() //返回栈顶元素
stk.pop() //弹出栈顶元素
7.Deque
7.1 介绍
双端队列
7.2 支持函数
size(); 这个双端队列的长度
empty(); 返回这个双端队列是否为空
clear(); 清空这个双端队列
front(); 返回第一个元素
back(); 返回最后一个元素
push_back(); 向最后插入一个元素
pop_back(); 弹出最后一个元素
push_front(); 向队首插入一个元素
pop_front(); 弹出第一个元素
begin(); 双端队列的第0个数
end(); 双端队列的最后一个的数的后面一个数
8.Set
8.1 介绍
set分为set和multiset,set不能有重复元素,multiset可以有重复元素
8.2 支持函数 (复杂度都为O(logn))
set.size();
set.empty();
set.clear();
set.begin();
set.end(); //支持++,--操作,返回前驱和后继
set.insert(); //插入一个数
set.find(); //查找一个数,若不存在返回end迭代器
set.count(); //返回某一个数的个数
set.erase(); //删除操作
set.erase(x); //输入一个数,删除所有x; O(k+logn);
set.erase(迭代器); //输入一个迭代器,删除这个迭代器
set.lower_bound(x); //返回大于等于x的最小的数的迭代器
set.upper_bound(x); //返回大于x的最小的数的迭代器
9.Map
9.1 介绍
可以像用数组一样使用map,但时间复杂度为logn
9.2 定义
map<string,int> a;
a["yzl"]=1;
cout<<a["yzl"]<<endl;
9.3 支持函数
map.size();
map.empty();
map.clear();
map.begin();
map.end(); //支持++,--操作,返回前驱和后继
map.insert(); //插入的是一个pair
map.erase(); //输入的参数是pair或者迭代器
map.find();
map.lower_bound(x); //返回大于等于x的最小的数的迭代器
map.upper_bound(x); //返回大于x的最小的数的迭代器
10.Unordered_set
10.1 介绍
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
- 和上面类似,增删改查的时间复杂度是 O(1)
- 不支持 lower_bound()/upper_bound(), 迭代器的++,–
11.Bitset
11.1 介绍
压位
11.2 定义
bitset<10000> s;
11.3 支持函数
~, &, |, ^
>>, <<
==, !=
[]
count() 返回有多少个1
any() 判断是否至少有一个1
none() 判断是否全为0
set() 把所有位置成1
set(k, v) 将第k位变成v
reset() 把所有位变成0
flip() 等价于~
flip(k) 把第k位取反