windows平台使用Docker搭建分布式Spark 与 hadoop集群
若不关心具体搭建过程,只想运行分布式集群,请直接前往3.2开始
(本人已上传镜像至服务器)
续前节
windows平台使用Docker搭建分布式hadoop集群
安装分布式Spark篇
1. 运行windows平台使用Docker搭建分布式hadoop集群产生的镜像文件hadoop_centos
docker run -v E:\COURSE\spark:/home -itd --privileged --network hadoop -h "node01" --name "node01" -p 9870:9870 -p 8088:8088 -p 4040:4040 -p 8080:8080 -p 50070:50070 -p 9001:9001 -p 8030:8030 -p 8031:8031 -p 8032:8032 -p 8042:8042 -p 19888:19888 -p 22:22 -p 3306:3306 hadoop_centos /usr/sbin/init
2. 参考Docker 伪分布式安装 Spark
需要改动的地方(主要针对Spark安装)
- $SPARK_HOME/conf/workers
vim $SPARK_HOME/conf/workers
在文件内容替换为:
node02
node03
- 安装依赖处(安装python3不变,其他变为如下)
yum install -y libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel zlib gcc make libpcap-devel xz-devel gdbm-devel
3. 提交镜像
本命令最后一个字段本人在docker的 用户名/仓库名:标签
docker commit -a "CMCST" -m "Deploy PySpark And Hadoop based on centos" centos7 cmcst/centos7:SparkAndHadoop
3.1 上传镜像至服务器[此步可不执行]
docker push cmcst/centos7:SparkAndHadoop
3.2 下拉镜像至本地[3.1没有执行,此步也无需执行]
docker pull cmcst/centos7:SparkAndHadoop
4. 启动集群
4.0 创建网络
docker network create -d bridge 网络名称
网络名称定义为什么,后面执行含有 - -network 字样的都要将本人的hadoop替换为自定义的网络名称(4.1、4.2、4.3就需要替换下)
本人的网络名称为hadoop,故命令为
docker network create -d bridge hadoop
4.1. 主节点node01
docker run -v E:\COURSE\spark:/home -itd --privileged --network hadoop -h "node01" --name "node01" -p 9870:9870 -p 8088:8088 -p 4040:4040 -p 8080:8080 -p 50070:50070 -p 9001:9001 -p 8030:8030 -p 8031:8031 -p 8032:8032 -p 8042:8042 -p 19888:19888 -p 22:22 -p 3306:3306 cmcst/centos7 /usr/sbin/init
4.2. 从节点node02
docker run -itd --privileged --network hadoop -h "node02" --name "node02" cmcst/centos7 /usr/sbin/init
4.3. 从节点node03
docker run -itd --privileged --network hadoop -h "node03" --name "node03" cmcst/centos7 /usr/sbin/init
4.4 修改文件/etc/hosts
vim /etc/hosts
文件首部填入如下值[具体填入哪些值,可使用命令docker network inspect hadoop查看]
172.18.0.2 node01
172.18.0.3 node02
172.18.0.4 node03
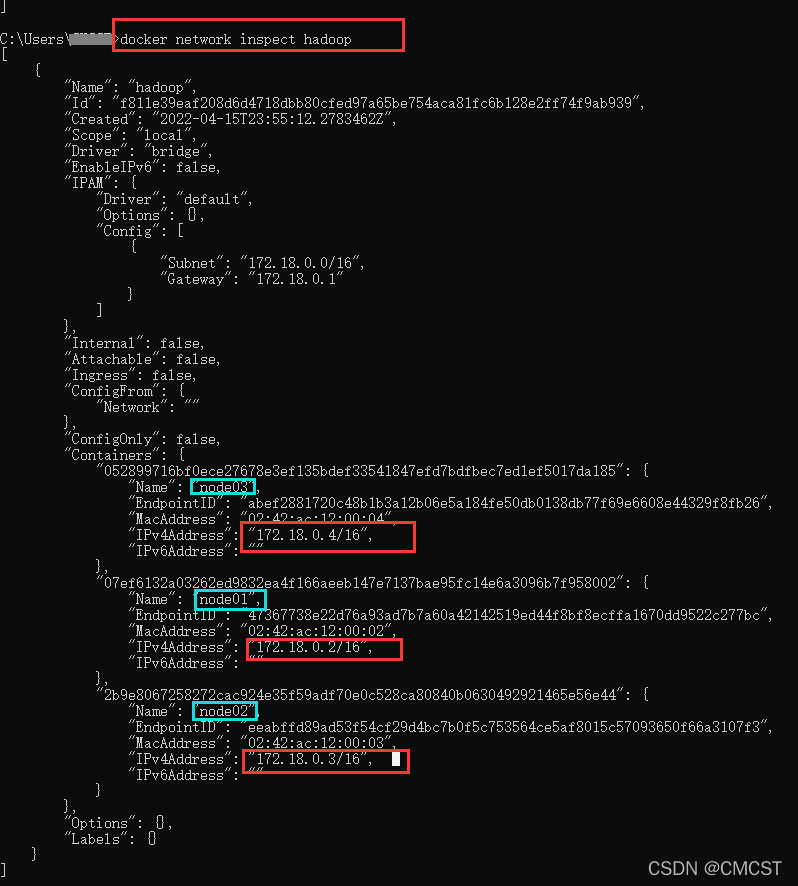
- 若输入命令docker network inspect hadoop查得结果为
此命令中的hadoop是自定义的网络名称
[]
Error: No such network: hadoop
解决方案为:
docker network create -d=bridge 网络名称
4.5 为python3添加包pyspark
/usr/local/python3/bin/pip3 install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
4.6 格式化主节点node01[在node01下]
/usr/local/hadoop/bin/hadoop namenode -format
4.7 启动Hadoop集群
/usr/local/hadoop/sbin/start-all.sh
4.8 启动Spark集群
/usr/local/spark/sbin/start-all.sh
5. 使用windows端PyCharm开发pyspark程序
5.1
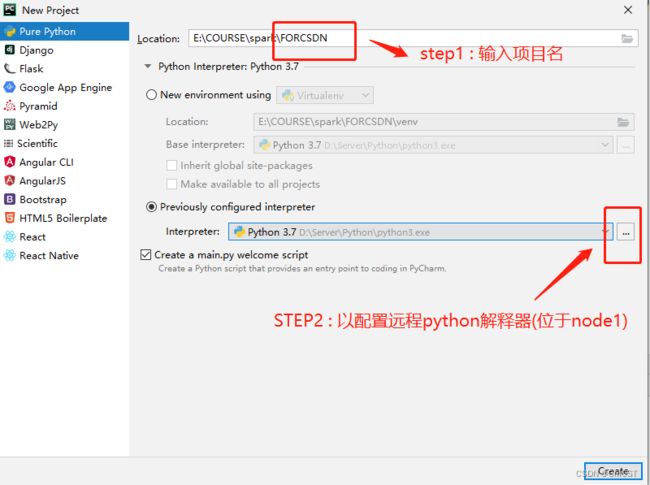
5.2 完成下图设置后点击next

5.3

5.4

5.5 进入项目后

5.6
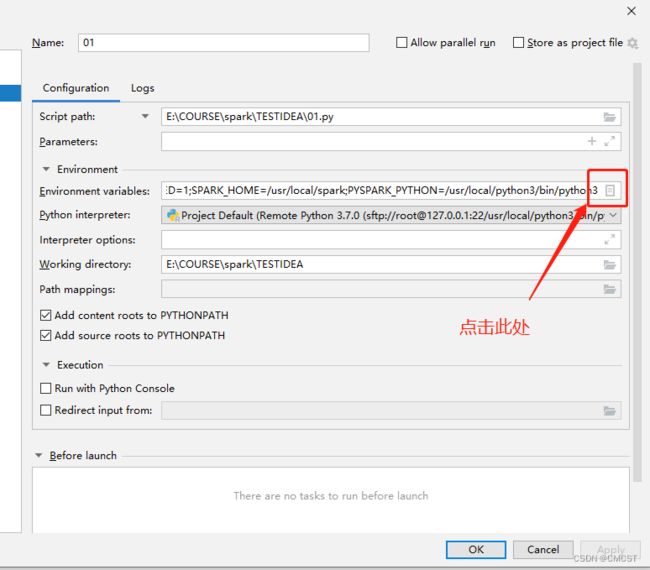
5.7 添加如下环境变量
变量的值在文件$SPARK_HOME/conf/spark-env.sh中可查得

6. 使用spark-submi提交
6.1 使用spark提交
/usr/local/spark/bin/spark-submi --master spark://node01:7077 源文件路径
6.2 使用yarn提交
/usr/local/spark/bin/spark-submit --master yarn 源文件路径
官方示例:
/usr/local/spark/bin/spark-submit --master spark://node01:7077 --class org.apache.spark.examples.JavaSparkPi /usr/local/spark/examples/jars/spark-examples_2.12-3.2.1.jar
6.3 本地运行
- 本人在目录/tmp/pycharm_project_489/00/下有00_03.py
- 00_03.py文件内容为:
import os
os.environ["PYSPARK_PYTHON"]="/usr/local/python3/bin/python3"
os.environ["SPARK_HOME"]="/usr/local/spark"
# import sys
# sys.path.append('/usr/local/spark/python/lib/py4j-0.10.9.3-src.zip')
from pyspark import SparkContext,SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("00_03")
sc = SparkContext(conf=conf)
lineRdd = sc.textFile("file:///tmp/pycharm_project_489/00/DataFor00_03/*").filter(lambda line : len(line.strip()) > 0)
rdd = lineRdd.map(lambda line : line.strip().split(" ")).map(tuple).mapValues(int)
rdd2 = rdd.combineByKey(
lambda grade : (grade , 1),
lambda acc , grade : (acc[0] + grade , acc[1] + 1),
lambda acc1 , acc2 : (acc1[0] + acc2[0] , acc1[1] + acc2[1])
).map(lambda x : (x[0] , x[1][0] / x[1][1]))
# print(rdd2.collect())
print("\033[37;46m " , rdd2.collect(),"\033[0m")
- /tmp/pycharm_project_489/00/DataFor00_03/文件夹下有如下文件
3.1 /tmp/pycharm_project_489/00/DataFor00_03/Algorithm.txt
小明 92
小红 87
小新 82
小丽 90
3.2 /tmp/pycharm_project_489/00/DataFor00_03/DataBase.txt
小明 95
小红 81
小新 89
小丽 85
3.3 /tmp/pycharm_project_489/00/DataFor00_03/Python.txt
小明 82
小红 83
小新 94
小丽 91
- 执行00_03.py
/usr/local/python3/bin/python3 /tmp/pycharm_project_489/00/00_03.py
第一个字段意为 : python解释器
第二个字段 :要执行的文件
注意
- 若使用6.3方式运行,必须在文件前加入环境变量
import os
os.environ["PYSPARK_PYTHON"]="/usr/local/python3/bin/python3"
os.environ["SPARK_HOME"]="/usr/local/spark"
第二行 指出python解释器路径为/usr/local/python3/bin/python3
第三行 指出spark路径为/usr/local/spark
若不添加,会报错如下:
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure:
Task 1 in stage 0.0 failed 1 times, most recent failure:
Lost task 1.0 in stage 0.0 (TID 1) (node01 executor driver):
java.io.IOException:
Cannot run program "python3": error=2, No such file or directory
- 若使用6.3方式运行,并且使用本地文件系统路径,需要在路径前加file:///,,告知解释器使用本地文件系统,否则会报错
java.net.ConnectException: Call From node01/172.18.0.2 to node01:9000
failed on connection exception:
java.net.ConnectException: Connection refused;
For more details see: http://wiki.apache.org/hadoop/ConnectionRefused