【机翻】MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition
MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition

Abstract
现实世界的训练数据通常表现为长尾分布,其中几个大多数类的样本数量显著多于其余少数类。这种不平衡降低了为平衡训练集设计的典型监督学习算法的性能。在本文中,我们利用最近提出的隐式语义数据增强(ISDA)算法来增强少数类来解决这个问题,该算法通过沿着多个语义有意义的方向翻译深层特征来产生多样化的增强样本。重要的是,考虑到ISDA估计类条件统计数据来获得语义方向,我们发现由于训练数据不足,在少数类上这样做是无效的。为此,我们提出了一种基于元学习的语义方向转换自动学习方法。具体来说,在训练过程中,增强策略是动态优化的,目的是最小化小型平衡验证集的损失,这是通过一个元更新步骤来近似的。CIFAR-LT-10/100、ImageNet-LT和iNaturalist 2017/2018的大量实证结果验证了我们方法的有效性。
1. Introduction
近年来,深度卷积神经网络(Deep convolutional neural networks, CNNs)取得了显著的成就[22,15,17]。它们最先进的性能通常在ImageNet[31]和MS COCO[24]等基准上进行演示。虽然这些数据集是通过为每个类理想地收集相似且足够数量的样本建立起来的,但现实世界的训练数据通常是不平衡的,如图1(a)所示。例如,在自动医学诊断中,少数常见疾病可能主导训练集,而其余类的病例很少。不幸的是,如果使用标准的训练策略(例如,交叉熵损失的监督学习),这种长尾分布会严重降低网络的性能。
为了解决数据不平衡的问题,一种自然的解决方案可能是增加少数类以获得更多的训练样本,如图1(b)所示,例如,利用数据增强技术[15,17,42,27]。然而,传统的数据增强技术,如裁剪、镜像和混合通常在输入上执行。因此,增强样本的多样性在本质上受到少数类训练数据量小的限制。
幸运的是,这个问题可以通过最近提出的隐式语义数据增强(ISDA)技术[37]来解决。ISDA通过将深层特征向特定有意义的语义方向转换,实现类身份保持语义转换(如改变物体的颜色和改变视角),如图1©所示。cnn提取的深度特征空间趋于线性化,其复杂度明显小于像素空间。因此,只要找到合适的语义方向,就可以有效地增强少数类的多样性。ISDA根据深度特征和高斯分布的样本语义方向估计类级协方差矩阵。然而,我们发现这将导致较差的性能在长尾情况下,因为少数类的稀缺数据不足以获得合理的协方差矩阵。
在本文中,我们提出了一种元语义扩展(MetaSAug)方法,旨在通过学习更有意义的类协方差,对长尾问题进行有效的语义数据扩展。我们的主要观点是,如果使用适当的协方差矩阵进行语义扩展,那么平衡验证集上的损失应该最小化。在每次训练迭代时,我们在一个小型的平衡验证集上执行验证,并通过最小化验证损失来更新类的协方差。具体地说,我们首先利用当前类的协方差来实现增广过程。然后,我们根据类协方差计算验证集上的损失。通过优化验证损失,我们可以得到更新的类级协方差,包含丰富的语义方向。利用它,我们用足够的语义增广样本在增广集上训练模型。此外,我们的方法可以被视为一个插件模块,并与以前的方法统一。我们将焦点损失[23]和LDAM损失[7]与MetaSAug结合,进一步提高了它们的分类能力。
我们在几个长尾数据集上进行了广泛的实验,包括人工长尾CIFAR- 10/100[21,9]、ImageNet[31,26]和自然长尾数据集inaturalist 2017和2018[36,1]。实验结果表明了该方法的有效性。

图1所示。(a):在iNaturalist 2018真实数据集的数据分布中,少数多数类别占了大多数样本,而少数类别的代表不足。(b):这项工作的动机。促进长尾问题的数据增强,以改善分类器的性能。©:传统数据增强和语义数据增强的说明。
2. Related Work
在本节中,我们将简要回顾与我们的工作相关的工作。
重采样。研究人员建议通过对少数群体的过度抽样[32,5,6]或对多数群体的不充分抽样[14,19,5]来实现更均衡的数据分布。过采样虽然有效,但可能会导致少数类的过拟合,而过采样由于缺乏有价值的实例,可能会削弱大多数类的特征学习[40,7,8,9]。Chawla等人[8]揭示,对少数类进行更强的增强有助于减少过拟合,这符合我们方法的目标。
权重。重新加权也被称为代价敏感学习,目的是在类或实例级别上为训练样本分配权重。一个经典的方案是用与它们的频率成反比的权重来重新加权类[16,38]。Cui等人利用提出的有效数对该方案进行了进一步的改进。最近,元类权重[18]利用元学习来估计精确的类权重,而Cao等人[7]将大量的边际分配给尾部类。除上述工作外,Focal Loss[23]、L2RW[30]和meta-weight-net[33]明智地为实例分配权重。其中,focal loss根据实例预测分配权重,L2RWand meta-weight-net根据梯度方向分配权重。我们的方法主要是增加训练集来克服不平衡问题,而不是为类设计不同的权值。
此外,为了学习更好的表示,一些方法提出将训练分为两个阶段:表示学习和分类器再平衡学习[7,18,10,20]。BBN[43]进一步将这两个阶段结合起来,形成一个累积学习策略。
元学习与头到尾的知识转移。元学习的最新发展[11,35,3]激励研究者利用元学习来处理课堂失衡。一种典型的方法是通过元学习来学习样本的权值[30,18,33]。另一个方法管道试图将知识从头类转移到尾类。Wang等人[38]采用元学习器回归网络参数。Liu等人的[26]利用一个内存库来传输这些特征。Yin等人[41]和Liu等人[25]提出将类内方差从头部转移到尾部。与这些工作不同的是,我们的方法试图自动学习语义方向,以增加少数类,改善分类器的性能。
数据增强是一种典型的技术,在cnn中被广泛用于缓解过拟合。例如,通过旋转和水平翻转来保持cnn的预测不变性[15,17,34]。作为对传统数据增强的补充,执行语义改变的语义数据增强对提高分类器性能也很有效[4,37]。ISDA[37]对类条件统计信息进行语义扩展,但不能对少数类中的稀缺数据进行合理的协方差估计。我们和ISDA之间的主要区别是MetaSAug利用元学习来学习适当的类级协方差,以获得更有意义的增强结果。
3. Method
考虑有N个训练样本的训练集 D = { ( x i , y i ) } i = 1 N D=\left\{\left(\boldsymbol{x}_{i}, y_{i}\right)\right\}_{i=1}^{N} D={(xi,yi)}i=1N ,其中 x i {x}_{i} xi表示第i个训练样本, y i y_{i} yi表示C类上对应的标签。设f为参数为 Θ \Theta Θ的分类器, a i a_{i} ai为分类器f提取的第i个样本的特征。在实际应用中,训练集D往往不平衡,导致对少数类的性能较差。因此,我们的目标是对少数类进行语义扩充,以改善分类器的学习。
3.1. Implicit Semantic Data Augmentation
在这里,我们重新讨论隐式语义数据增强(ISDA)[37]方法。对于语义增强,ISDA统计估计类协方差矩阵 Σ = Σ 1 , Σ 2 , , , Σ C {\varSigma}={{\varSigma}_{1},{\varSigma}_{2},,,{\varSigma}_{C}} Σ=Σ1,Σ2,,,ΣC从深度特征在每次迭代。然后,ISDA样本变换方向由高斯分布 N ( 0 , λ Σ y i ) \mathcal{N}(0,\lambda{\varSigma}_{{y}_{i}}) N(0,λΣyi)来增强深度特征 a i {a}_{i} ai,其中 λ \lambda λ是调优增强强度的超参数。当然,探索所有可能的有意义的方向 N ( 0 , λ Σ y i ) \mathcal{N}(0,\lambda{\varSigma}_{{y}_{i}}) N(0,λΣyi),一个人应该尝试大量的方向。更进一步,如果对无限方向采样,ISDA得出所有增广特征的交叉熵损失的上界:
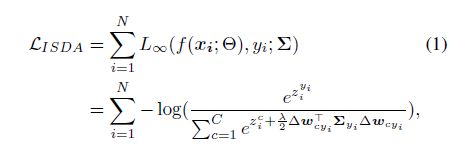
其中 z i c {z}_{i}^{c} zic是 x i {x}_{i} xi的logits输出的第c个元素, Δ ω c y i = ( ω c − ω y i ) \Delta{\omega}_{c{y}_{i}}=({\omega}_{c}-{\omega}_{{y}_{i}}) Δωcyi=(ωc−ωyi), w c {w}_{c} wc是最后一个全连通层权值矩阵的第c列。通过优化这个上界 L I S D A {\mathcal{L}}_{ISDA} LISDA, ISDA可以有效地实现等价语义扩展过程。
然而,ISDA的性能依赖于协方差矩阵的估计。在长尾情况下,我们发现ISDA的表现不令人满意,因为少数类的稀缺数据不足以实现合理的协方差矩阵。
3.2. Meta Semantic Augmentation
为了解决类别不平衡的问题,我们建议增加少数类别以获得更多的训练样本。如前所述,数据的稀缺性限制了语义增强的有效性。因此,我们尝试学习适当的类级协方差矩阵来增广,从而在少数类上获得更好的性能。其关键思想是,如果使用适当的协方差矩阵进行语义扩展,则应尽量减少平衡验证集上的损失。在这项工作中,我们利用金属学习来实现这一目标。
元学习目标 一般来说,我们可以利用eq.(1)中的 L ∞ {L}_{∞} L∞来训练分类器,同时完成语义增强过程。然而,在班级不平衡学习的情况下,大部分的班级支配着训练集。从eq.(1)中我们可以看到,增强结果依赖于训练数据。如果我们直接应用eq.(1),实际上我们主要是增加了大多数类,这违背了我们的目标。
因此,为了解决这一问题,我们提出将[9]中的分类条件权重与eq.(1)相统一,以降低多数样本的损失。类条件权重定义为 ϵ c ≈ ( 1 − β ) / ( 1 − β n c ) {\epsilon}_{c} \approx (1-\beta )/(1-{\beta }^{{n}_{c}}) ϵc≈(1−β)/(1−βnc),其中 n c {n}_{c} nc是第c类中的数据数量,是超参数,推荐值为 ( N − 1 ) / N (N-1)/N (N−1)/N。综上所述,利用训练集上的加权损失可以计算出最优参数 Θ ∗ {\Theta}^{*} Θ∗:
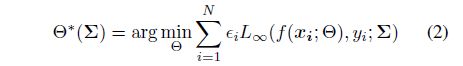
如果我们将协方差矩阵 Σ \varSigma Σ作为训练超参数,我们实际上可以在验证集上搜索它们的最优值[30,33,3,28,29]。具体来说,考虑一个小的验证集 D v = { x i v , y i v } i = 1 N D^{v}=\left\{\boldsymbol{x}_{i}^{v}, y_{i}^{v}\right\}_{i=1}^{N} Dv={xiv,yiv}i=1N,其中 N v N^{v} Nv为总样本量, N v ≪ N N^{v}\ll N Nv≪N。通过最小化以下验证损失,可以获得最优分类协方差:
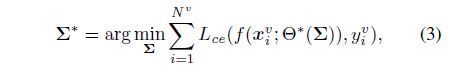
L c e ( ⋅ , ⋅ ) L_{ce}(·,·) Lce(⋅,⋅)为交叉熵(CE)损失函数。由于验证集是平衡的,我们采用香草CE损耗来计算验证集上的损耗。
在线近似为了获得 Θ \Theta Θ和 Σ \varSigma Σ的最优值,我们需要经过两个嵌套循环,这可能会带来昂贵的代价。因此,我们利用一种在线策略,通过一步循环更新 Θ \Theta Θ和 Σ \varSigma Σ。给定当前步骤t,根据[37]可以得到当前协方差矩阵 Σ t {\varSigma}^{t} Σt。接下来,我们更新分类器 Θ \Theta Θ的参数,目的如下:
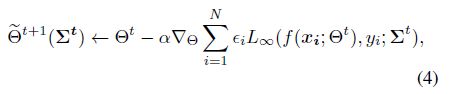
其中 α \alpha α是 Θ \Theta Θ的步长。执行反向传播这一步后,我们得到优化后的参数 Θ ~ t + 1 ( Σ t ) \widetilde{\Theta}^{t+1}\left(\boldsymbol{\Sigma}^{\boldsymbol{t}}\right) Θ t+1(Σt)。然后我们可以使用eq.(3)产生的梯度来更新类-wise协方差 Σ \varSigma Σ:
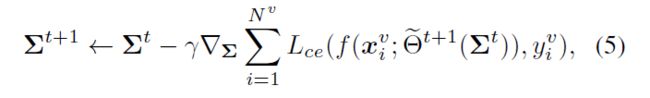
其中 γ \gamma γ 为 Σ \varSigma Σ的步长。利用学到的类智慧 Σ \varSigma Σ,我们可以对分类器的参数 Θ \Theta Θ进行改进,如下:

由于更新的类级协方差矩阵 Σ t + 1 {\varSigma}^{t+1} Σt+1是从平衡验证数据中学习的,我们可以期望 Σ t + 1 {\varSigma}^{t+1} Σt+1有助于学习更好的分类器参数 Θ t + 1 {\Theta}^{t+1} Θt+1。在实际应用中,我们采用了常用的SGD技术来实现我们的算法。此外,一些先前的研究已经证明,在早期阶段训练网络而不使用再平衡策略可以更好地学习可泛化表示[20,7,18]。因此,我们首先用vanilla CE loss训练分类器,然后用MetaSAug训练分类器。训练算法如算法1所示。

3.3. Discussion
在这项工作中,我们利用元学习学习适当的协方差矩阵来增加少数类。因此,有必要了解 Σ {\varSigma} Σ从验证数据中学到了什么。为了研究这个问题,我们进行奇异值分解,提取最罕见类 r r r的协方差矩阵 Σ r {\varSigma}_{r} Σr的奇异值:

M对角线上的每个元素都是 Σ r {\varSigma}_{r} Σr的奇异值。然后,我们对ISDA和我们的MetaSAug学习到的 Σ r {\varSigma}_{r} Σr的前5个奇异值(max-normalized)进行了说明。主成分分析表明,奇异值越大的特征向量包含的信息变化就越多[39,2]。从图2(a)中,我们可以看到ISDA在不平衡数据集上学习到的 Σ r {\varSigma}_{r} Σr的最大奇异值明显大于其他奇异值,而其他奇异值较小的特征向量的信息信号被抑制。这种奇异值的尖锐分布意味着 Σ r {\varSigma}_{r} Σr的重要主成分较少,用 Σ r {\varSigma}_{r} Σr可能无法对多样化的变换向量进行采样。究其原因,ISDA无法利用少数族裔群体的数据来估算出合适的 Σ r {\varSigma}_{r} Σr。
当MetaSAug应用本文提出的元学习方法学习 Σ r {\varSigma}_{r} Σr时, Σ r {\varSigma}_{r} Σr的奇异值分布变得相对均衡,如图2(b)所示。除了奇异值最大的特征向量外,其他特征向量也具有较大的信息方差。对于具有均衡奇异值分布的 Σ r {\varSigma}_{r} Σr,可以对不同的变换向量进行采样,从而得到更好的增广效果。综上所述,使用我们提出的元学习方法,学习到的协方差矩阵 Σ r {\varSigma}_{r} Σr包含更多重要的主成分,这意味着它可能包含更多的语义方向。此外,我们在4.5节进一步实验验证了我们的元学习方法有助于提高分类器的性能。

图2 ISDA和MetaSAug学习的协方差矩阵 Σ r {\varSigma}_{r} Σr的前5个奇异值(最大归一化)。(a): Balanced是在平衡训练集(CIFAR-10)上估计的协方差矩阵,Imbalanced是在不平衡训练集(CIFAR-LT-10,不平衡因子为200)上估计的 Σ r {\varSigma}_{r} Σr。(b):这两个实验都是在不平衡的集合上进行的,红色线和蓝色线分别表示使用我们的元学习方法和不使用我们的元学习方法MetaSAug学习到的 Σ r {\varSigma}_{r} Σr。
4. Experiment
我们在以下长尾数据集上评估我们的方法:CIFAR-LT-10, CIFAR-LT-100, ImageNet-LT,iNaturalist 2017和iNaturalist 2018。此外,我们还报道了3次随机实验的平均结果。对于那些在相同环境下进行的实验,我们直接从原始论文中引用他们的结果。代码可在https://github.com/BIT-DA/MetaSAug上找到。
4.1. Datasets
不翻了,就常用的Long-Tailed CIFAR、ImageNet-LT、iNaturalist 2017 and iNaturalist 2018
4.2. Visual Recognition on CIFARLT
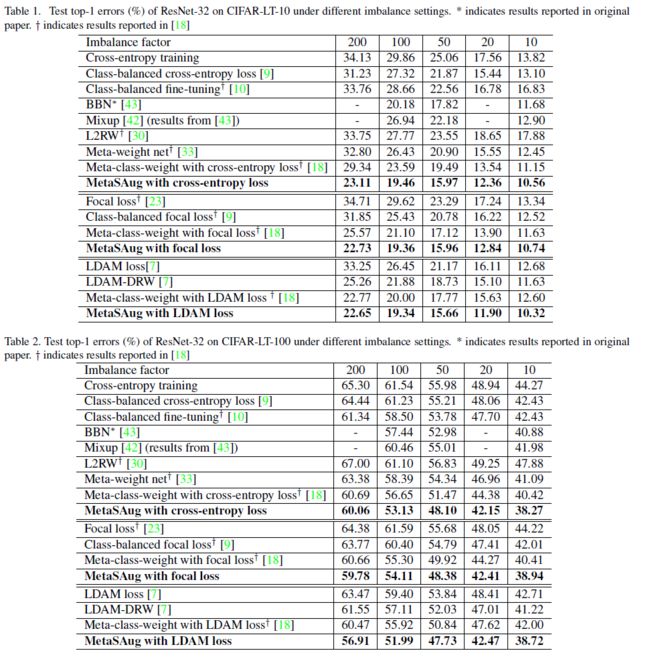
我们在长尾数据集CIFAR-LT-10和CIFAR-LT-100上进行了对比实验。继[18,9]之后,我们在实验中采用resnet - 32[15]作为骨干网。
实现细节 对于基线LDAM和LDAM- drw,我们用作者[7]发布的源代码复制了它们。在所有实验中,我们用标准随机梯度体面(SGD)训练ResNet-32[15],动量0.9,权重衰减 1 × 10 − 4 1×{10}^{-4} 1×10−4。我们在一个GPU上训练了200个时代的模型。此外,我们在第160和180个epochs的[18]的学习速率衰减0.01。对于我们的方法,我们采用初始学习率0.1。我们的实验设置为100epochs。超参数 λ \lambda λ是从{0.25,0.5,0.75,1.0}中选择的。
比较方法 我们将我们的方法与以下方法进行比较:
- 交叉熵训练是长尾视觉识别的基准方法,利用香草交叉熵损失函数训练ResNet-32。
- 类加权方法。这类方法在类级别为训练实例分配权重,包括类平衡损失[9]、元类权重[18]和LDAM-DRW[7]。类平衡损失提出了有效的数来衡量每个类的样本容量和类级权重。类平衡焦损失和类平衡交叉熵损失分别是指将类平衡损失应用于焦损失和交叉熵损失。LDAM-DRW根据标签分布为示例分配标签感知边距,并采用延迟重加权策略,以提高尾部类的性能。
- 实例加权方法根据实例特征为样本分配权重[30,33,23]。例如,焦损[23]根据样本的难度来确定样本的权重。虽然焦丢失不是专门为长尾分类设计的,但如果分类器在训练过程中忽略了少数类的样本,就会对少数类的样本造成惩罚。
- 元学习方法。事实上,这些方法采用元学习来学习更好的类级或实例级权重[18,33,30]。为了节省空间,我们在这里只介绍它们。元类权重[18]利用元学习来模拟训练数据和测试数据之间的条件分布差异,从而得到更好的类级别权重。L2RW[30]和meta-weight-net[33]采用元学习方法对实例权重进行建模。L2RW直接优化权值变量,meta-weight-net额外构建多层感知器网络对权值函数进行建模。注意,L2RW和meta-weight-net都可以处理标签分布不平衡和有噪声标签的学习。
- 两阶段的方法。我们还比较了采用两阶段学习的方法[18,7,10]。BBN[43]将表示阶段和分类器学习阶段统一起来,形成累积学习策略。
结果 不同不平衡因素的CIFAR-10长尾实验结果如表1所示,根据采用的基本损失(交叉熵、焦点和LDAM)分为三组。从结果中,我们可以观察到重权策略对于长尾问题是有效的,因为一些重权方法(如元类权重)比交叉熵训练的效果要好得多。我们用三个基本损失来评估我们的方法。结果表明,我们的方法可以持续地显著提高基本损耗的性能。特别地,MetaSAug明显地超越了对输入进行增强的混合,表明促进语义增强在长尾场景中更有效。此外,我们的方法比重新加权的方法性能更好。这表明我们的扩展策略确实可以改善分类器的性能。当数据集不平衡程度较低,即不平衡因子=10)时,我们的方法仍然可以稳定地获得性能增益,这说明MetaSAug在相对平衡的设置下不会损害分类器的性能。
4.3. Visual Recognition on ImageNetLT
在ImageNet-LT上的实验中,我们使用resnet - 50[15]作为骨干网。我们培训的ResNet-50批量为64。我们在第60和第80时代的学习速度下降0.1。此外,为了提高训练效率,我们在元学习阶段固定表示时,只对最后一个全连接层进行微调。我们根据作者发布的代码重现了比较方法。
结果 实验结果见表3。类平衡交叉熵的性能优于交叉熵训练,LDAM-DRW远远超过LDAM。这些结果表明,调整权重策略对于类较多的数据集也是有效的。因此,MetaSAug也采用了这种策略来更好地实现语义增强过程。此外,与最佳竞争方法meta-classweight相比,MetaSAug仍然可以产生更好的结果,这表明MetaSAug能够执行对分类器分类学习有用的数据增强。

4.4. Visual Recognition on iNaturalist Datasets
为了公平比较,我们采用ResNet-50[15]作为《iNaturalist》2017年和2018年的骨干网络。在[18]之后,我们在ImageNet上为iNaturalist 2017预训练骨干网络。至于innaturalist 2018,该网络在ImageNet和innaturalist 2017上进行了预先训练。我们使用带动量的随机梯度下降(SGD)来训练模型。设批数为64,初始学习率为0.01。在我们方法的元学习阶段,我们将学习率衰减到0.0001,并仅微调最后一层全连接以提高训练效率。
结果 表4给出了自然倾斜数据集iNaturalist 2017和iNaturalist 2018的实验结果。MetaSAug和meta-class-weight都利用CE损耗作为基本损耗。与类别平衡的CE[9]对CE丢失的改进相比,MetaSAug进一步提高了CE丢失的性能,这表明对长尾分类进行有效的数据增强也很重要。此外,MetaSAug在2018年的iNat上获得了这些竞争方法中最好的结果,并与2017年iNat上最先进的BBN[43]方法不相上下。这些结果表明,我们的方法确实可以促进数据增强,有助于分类在深度特征空间。

4.5. Analysis
消融实验 为了验证MetaSAug的每个成分,我们进行了消融研究(见表5)。去除重加权或元学习会导致绩效下降。这表明1)重新加权可以有效地构建一个合适的元学习目标,2)我们的元学习方法确实可以学习对分类有用的协方差。重要的是,后者并非微不足道,因为MetaSAug实现了如表5所示的显著精度增益。而采用固定ISDA的元加权方法(如L2RW;MWN Meta-weight净;Meta-class-weight华盛顿)。此外,我们观察到ISDA可以在一定程度上促进以前的长尾方法,但改进是有限的。这也验证了元学习算法的重要性。
对更深骨干网的适应性 为了与基线进行合理的比较,我们分别采用常用的ResNet-32和ResNet-50在CIFAR-LT和ImageNet-LT/iNaturalist数据集上评估我们的方法。然而,MetaSAug可以很容易地适应于其他网络,而且,正如[37]所指出的,更深层次的模型甚至可能对我们的方法更有利,因为它们具有更强的建模复杂语义关系的能力。表6展示了不同骨干网下MetaSAug、MCW[18]和LDAM-DRW[7]的结果。我们可以观察到MetaSAug的性能一直优于其他方法。
混淆矩阵 为了找出我们的方法是否改善少数类的性能,我们绘制交叉熵(CE)训练的混淆矩阵、元类权重[18]和我们的方法在不平衡因子为200的CIFAR-LT-10上。从图4中我们可以看到,CE训练在大多数类别中几乎可以很好地对样本进行分类,但在少数类别中表现严重退化。由于所提出的双分量权重,元类权重比CE在少数类上的训练效果要好得多。由于MetaSAug倾向于增强少数类,它可以进一步增强少数类的性能,并减少类似类之间的混淆(意味着automobile & truck,和airplane & ship)。
可视化结果 为了直观地揭示我们的方法确实可以改变训练样本的语义,并生成不同的有意义的增广样本,我们进行了可视化实验(详细的可视化算法在[37]中给出)。可视化结果如图3所示,从中我们可以看到MetaSAug能够在保留标签标识的同时,在语义上改变训练示例的语义。特别是,MetaSAug仍然可以为最罕见的类“truck”生成有意义的扩增样本。



图3 可视化四个最罕见的类的增强示例:青蛙、马、船和卡车(频繁!罕见)。我们采用WGAN-GP[13]生成器搜索增强特征对应的图像。“原始”为原始训练样本。“恢复”和“增强”分别是生成器生成的原始图像和增强图像。我们的方法能够在语义上改变训练图像的语义,例如改变对象的颜色、背景、形状等。

图4 香草交叉熵训练、元类权重[18]的混淆矩阵说明,以及我们在CIFARLT-10数据集上的方法。不平衡系数是200。班级的排名是根据频率,即频繁(左)→罕见的(右)。
5. Conclusion
在这篇论文中,我们深入研究了长尾视觉识别问题,并提出了从数据增强的角度来解决它,这还没有充分的探索。我们提出了一种元语义扩充(MetaSAug)方法,学习适当的类级协方差矩阵来扩充少数类,改善分类器的学习。此外,MetaSAug还适用于以前的几种长尾方法,如LDAM和focal loss。在几个基准上的大量实验验证了MetaSAug的有效性和通用性。