SpringCloud(五):ElasticSearch搜索引擎
编写:HorinJsor
文章目录
- 一、ElasticSearch是什么?
-
- 1.ES与Mysql概念对比
- 二、ElasticSearch环境和基础(索引库)
-
- 1.安装ES
- 2.部署kibana和安装IK分词器
- 3.创建、操作索引库语法(在kibana ➡ dev tolls中运行)
-
- ①约束:
- ②针对某个字段进行约束,创建索引库例子:
- ③修改索引库语法
- ④文档操作(在索引库操作数据)
- 4、RestClient操作索引库、文档
-
- 4.1 感觉要被刀的第一种方法(RestClient操作索引库)
- 4.2 感觉要被刀的第一种方法(RestClient操作文档)
- 三、未完待续~
- 总结
一、ElasticSearch是什么?
ElasticSearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
1.ES与Mysql概念对比


二、ElasticSearch环境和基础(索引库)
1.安装ES
Blibili黑马程序员 P81
2.部署kibana和安装IK分词器
kibana作用:帮我们发送请求语句到ES中,并可视化有哪些索引库
Blibili黑马程序员 P82
IK作用:处理中文分词
Blibili黑马程序员 P83
3.创建、操作索引库语法(在kibana ➡ dev tolls中运行)
①约束:

②针对某个字段进行约束,创建索引库例子:

PUT /heima //指定索引库名称
{
"mappings": {
"properties": {
"info":{
"type": "text", //文本,可分词类型
"analyzer": "ik_smart" //指定分词器类型,ik为中文分词器
},
"email":{
"type": "keyword", //精确值,不可分词类型
"index": "false" //不参与索引
},
"name":{
"type":"object", //对象类型
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// ... 略
}
}
}
两个字段合成一个索引字段:
字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段。
"all": {
"type": "text",
"analyzer": "ik_max_word" //拷贝字段属性
},
"brand": {
"type": "keyword",
"copy_to": "all" //指定拷贝到的目标地点(字段)
}
③修改索引库语法
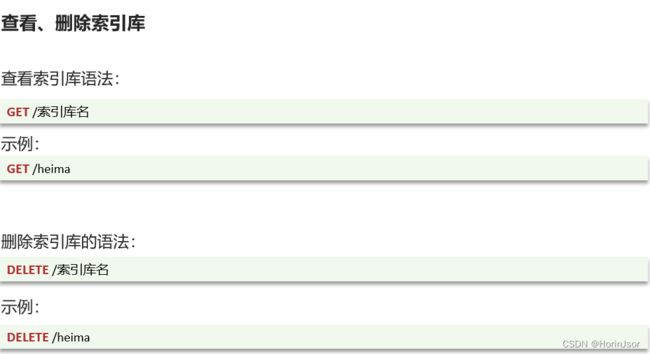
修改索引库:不能修改已经创建的索引字段,只能新增索引库不存在的字段

④文档操作(在索引库操作数据)
索引库是为了限制数据规则,文档是放数据。

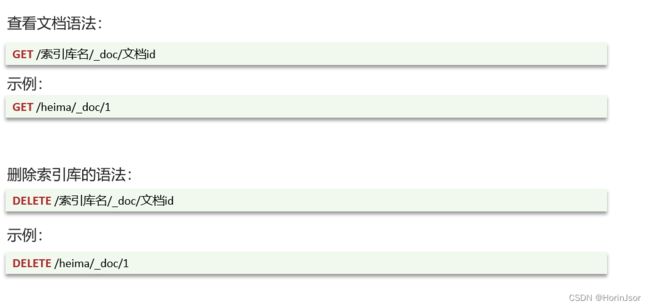

全量修改:可当新增使用,存在则会覆盖原有文档(数据)。
4、RestClient操作索引库、文档
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。(简化 3 的操作)
官方文档地址
4.1 感觉要被刀的第一种方法(RestClient操作索引库)
①引入依赖:pom配置文件
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
②因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.12.1elasticsearch.version>
properties>
③初始化客户端:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200") //指定ES的端口
));
初始化客户端参考完成代码:
public class ElasticsearchDocumentTest {
// 客户端
private RestHighLevelClient client;
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
client.close();
}
}
④创建索引库:
@Test
void testCreateHotelIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.请求参数,MAPPING_TEMPLATE是静态常量字符串,内容是创建索引库的DSL语句
request.source(MAPPING_TEMPLATE, XContentType.JSON); //MAPPING_TEMPLATE是常量,放入SSL创库语句
// 3.发起请求
client.indices().create(request, RequestOptions.DEFAULT);
}

4.2 感觉要被刀的第一种方法(RestClient操作文档)
①添加文档:
@Test
void testIndexDocument() throws IOException {
// 1.创建request对象
IndexRequest request = new IndexRequest("indexName").id("1");//id可以使用mapper查出来的对象id替换
// 2.准备JSON文档
request.source("{\"name\": \"Jack\", \"age\": 21}", XContentType.JSON);//数据可用mybatis查出来的数据,再用FastJson转对象为json
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
②根据id查询文档:
@Test
void testGetDocumentById() throws IOException {
// 1.创建request对象
GetRequest request = new GetRequest("indexName", "1");
// 2.发送请求,得到结果
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析结果
String json = response.getSourceAsString();
System.out.println(json);
}
③改、删(注意符号):
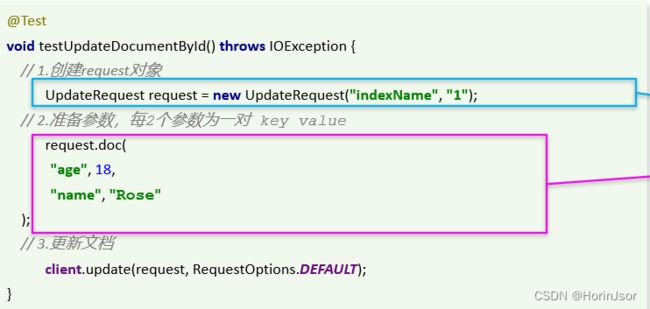

④批量新增文档(使用 MybatisPlus 查询数据后导入到 ES ):

三、未完待续~
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。