vue为什么要用虚拟dom机制_Vue源码解析:虚拟dom比较原理
通过对 Vue2.0 源码阅读,想写一写自己的理解,能力有限故从尤大佬2016.4.11第一次提交开始读,准备陆续写:
其中包含自己的理解和源码的分析,尽量通俗易懂!由于是2.0的最早提交,所以和最新版本有很多差异、bug,后续将陆续补充,敬请谅解!包含中文注释的Vue源码已上传...
开始
先说一下为什么会有虚拟dom比较这一阶段,我们知道了Vue是数据驱动视图(数据的变化将引起视图的变化),但你发现某个数据改变时,视图是局部刷新而不是整个重新渲染,如何精准的找到数据对应的视图并进行更新呢?那就需要拿到数据改变前后的dom结构,找到差异点并进行更新!
虚拟dom实质上是针对真实dom提炼出的简单对象。就像一个简单的div包含200多个属性,但真正需要的可能只有tagName,所以对真实dom直接操作将大大影响性能!
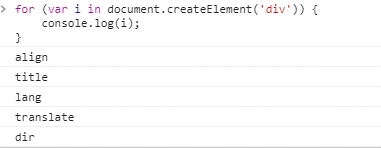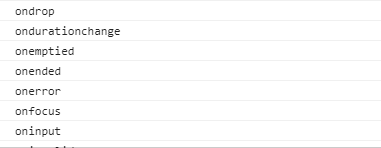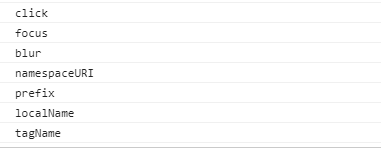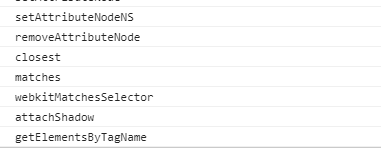
简化后的虚拟节点(vnode)大致包含以下属性:
{
tag: 'div', // 标签名
data: {}, // 属性数据,包括class、style、event、props、attrs等
children: [], // 子节点数组,也是vnode结构
text: undefined, // 文本
elm: undefined, // 真实dom
key: undefined // 节点标识
}
虚拟dom的比较,就是找出新节点(vnode)和旧节点(oldVnode)之间的差异,然后对差异进行打补丁(patch)。大致流程如下
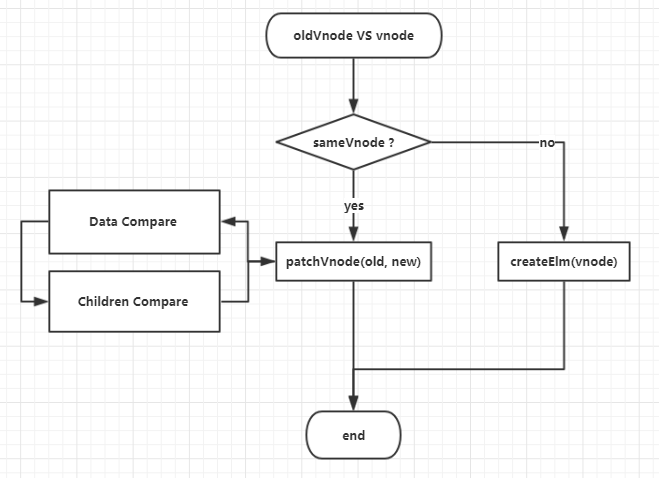
整个过程还是比较简单的,新旧节点如果不相似,直接根据新节点创建dom;如果相似,先是对data比较,包括class、style、event、props、attrs等,有不同就调用对应的update函数,然后是对子节点的比较,子节点的比较用到了diff算法,这应该是这篇文章的重点和难点吧。
值得注意的是,在Children Compare 过程中,如果找到了相似的childVnode,那它们将递归进入新的打补丁过程。
源码解析
这次的源码解析写简洁一点,写太多发现自己都不愿意看 (┬_┬)
开始
先来看patch()函数:
function patch (oldVnode, vnode) {
var elm, parent;
if (sameVnode(oldVnode, vnode)) {
// 相似就去打补丁(增删改)
patchVnode(oldVnode, vnode);
} else {
// 不相似就整个覆盖
elm = oldVnode.elm;
parent = api.parentNode(elm);
createElm(vnode);
if (parent !== null) {
api.insertBefore(parent, vnode.elm, api.nextSibling(elm));
removeVnodes(parent, [oldVnode], 0, 0);
}
}
return vnode.elm;
}
patch()函数接收新旧vnode两个参数,传入的这两个参数有个很大的区别:oldVnode的elm指向真实dom,而vnode的elm为undefined...但经过patch()方法后,vnode的elm也将指向这个(更新过的)真实dom。
判断新旧vnode是否相似的sameVnode()方法很简单,就是比较tag和key是否一致。
function sameVnode (a, b) {
return a.key === b.key && a.tag === b.tag;
}
打补丁
对于新旧vnode不一致的处理方法很简单,就是根据vnode创建真实dom,代替oldVnode中的elm插入DOM文档。
对于新旧vnode一致的处理,就是我们前面经常说到的打补丁了。具体什么是打补丁?看看patchVnode()方法就知道了:
function patchVnode (oldVnode, vnode) {
// 新节点引用旧节点的dom
let elm = vnode.elm = oldVnode.elm;
const oldCh = oldVnode.children;
const ch = vnode.children;
// 调用update钩子
if (vnode.data) {
updateAttrs(oldVnode, vnode);
updateClass(oldVnode, vnode);
updateEventListeners(oldVnode, vnode);
updateProps(oldVnode, vnode);
updateStyle(oldVnode, vnode);
}
// 判断是否为文本节点
if (vnode.text == undefined) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue)
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) api.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
api.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
api.setTextContent(elm, vnode.text)
}
}
打补丁其实就是调用各种updateXXX()函数,更新真实dom的各个属性。每个的update函数都类似,就拿updateAttrs()举例看看:
function updateAttrs (oldVnode, vnode) {
let key, cur, old
const elm = vnode.elm
const oldAttrs = oldVnode.data.attrs || {}
const attrs = vnode.data.attrs || {}
// 更新/添加属性
for (key in attrs) {
cur = attrs[key]
old = oldAttrs[key]
if (old !== cur) {
if (booleanAttrsDict[key] && cur == null) {
elm.removeAttribute(key)
} else {
elm.setAttribute(key, cur)
}
}
}
// 删除新节点不存在的属性
for (key in oldAttrs) {
if (!(key in attrs)) {
elm.removeAttribute(key)
}
}
}
属性(Attribute)的更新函数的大致思路就是:
遍历vnode属性,如果和oldVnode不一样就调用setAttribute()修改;
遍历oldVnode属性,如果不在vnode属性中就调用removeAttribute()删除。
你会发现里面有个booleanAttrsDict[key]的判断,是用于判断在不在布尔类型属性字典中。
['allowfullscreen', 'async', 'autofocus', 'autoplay', 'checked', 'compact', 'controls', 'declare', ......]
eg: ,想关闭自动播放,需要移除该属性。
所有数据比较完后,就到子节点的比较了。先判断当前vnode是否为文本节点,如果是文本节点就不用考虑子节点的比较;若是元素节点,就需要分三种情况考虑:
新旧节点都有children,那就进入子节点的比较(diff算法);
新节点有children,旧节点没有,那就循环创建dom节点;
新节点没有children,旧节点有,那就循环删除dom节点。
后面两种情况都比较简单,我们直接对第一种情况,子节点的比较进行分析。
diff算法
子节点比较这部分代码比较多,先说说原理后面再贴代码。先看一张子节点比较的图:
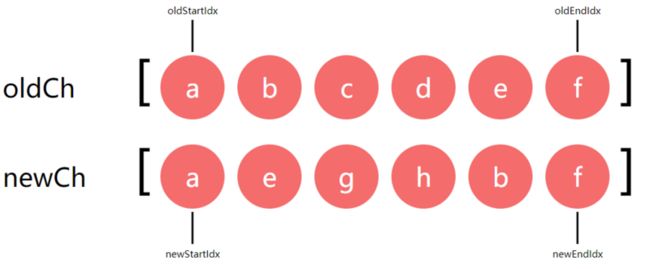
图中的oldCh和newCh分别表示新旧子节点数组,它们都有自己的头尾指针oldStartIdx,oldEndIdx,newStartIdx,newEndIdx,数组里面存储的是vnode,为了容易理解就用a,b,c,d等代替,它们表示不同类型标签(div,span,p)的vnode对象。
子节点的比较实质上就是循环进行头尾节点比较。循环结束的标志就是:旧子节点数组或新子节点数组遍历完,(即 oldStartIdx > oldEndIdx || newStartIdx > newEndIdx)。大概看一下循环流程:
第一步 头头比较。若相似,旧头新头指针后移(即 oldStartIdx++ && newStartIdx++),真实dom不变,进入下一次循环;不相似,进入第二步。
第二步 尾尾比较。若相似,旧尾新尾指针前移(即 oldEndIdx-- && newEndIdx--),真实dom不变,进入下一次循环;不相似,进入第三步。
第三步 头尾比较。若相似,旧头指针后移,新尾指针前移(即 oldStartIdx++ && newEndIdx--),未确认dom序列中的头移到尾,进入下一次循环;不相似,进入第四步。
第四步 尾头比较。若相似,旧尾指针前移,新头指针后移(即 oldEndIdx-- && newStartIdx++),未确认dom序列中的尾移到头,进入下一次循环;不相似,进入第五步。
第五步 若节点有key且在旧子节点数组中找到sameVnode(tag和key都一致),则将其dom移动到当前真实dom序列的头部,新头指针后移(即 newStartIdx++);否则,vnode对应的dom(vnode[newStartIdx].elm)插入当前真实dom序列的头部,新头指针后移(即 newStartIdx++)。
先看看没有key的情况,放个动图看得更清楚些!
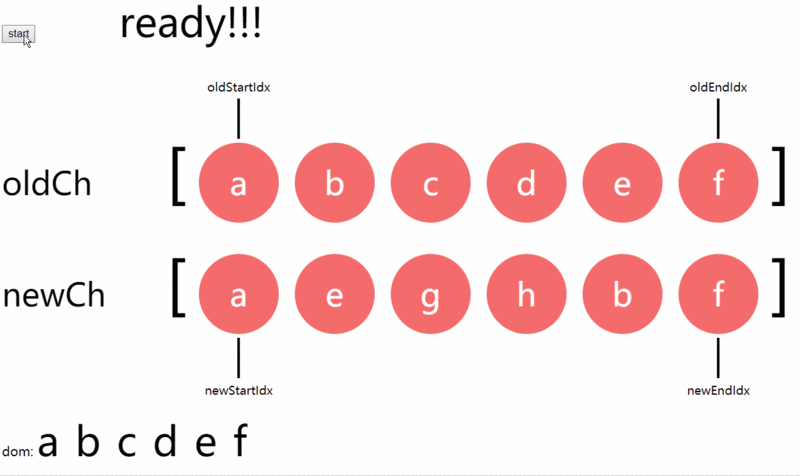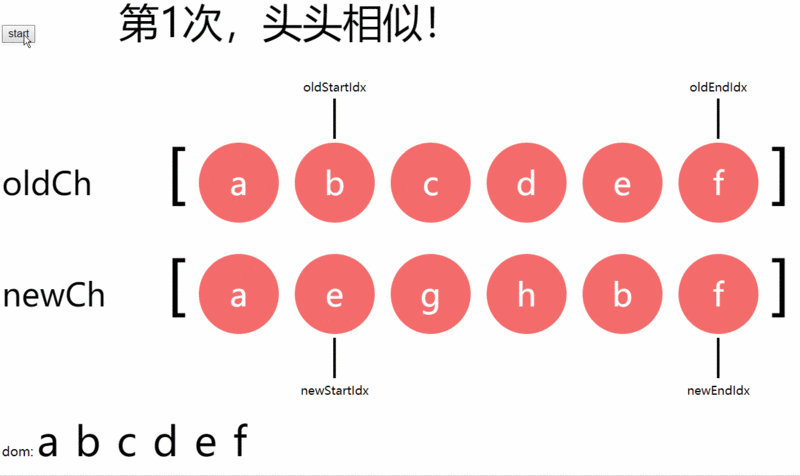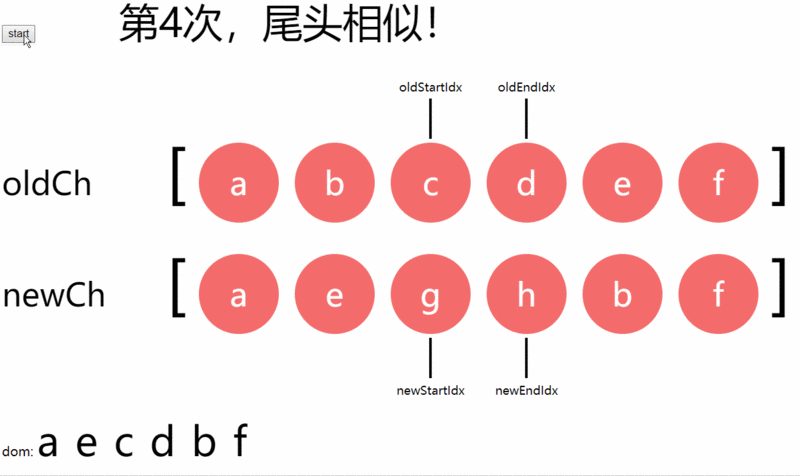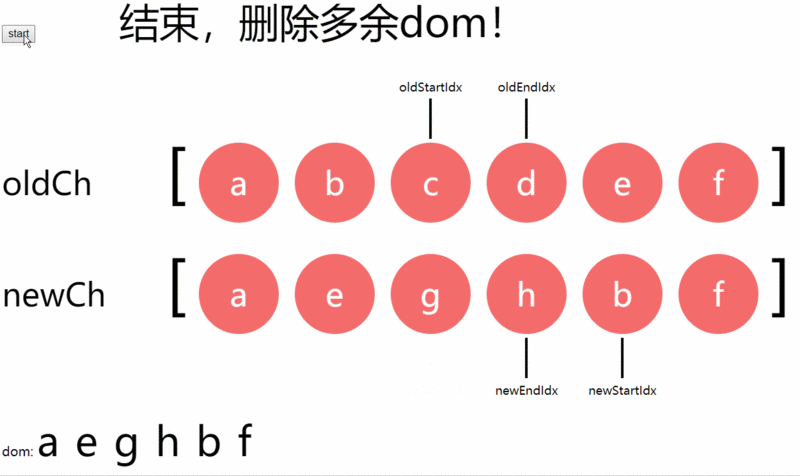
相信看完图片有更好的理解到diff算法的精髓,整个过程还是比较简单的。上图中一共进入了6次循环,涉及了每一种情况,逐个叙述一下:
第一次是头头相似(都是a),dom不改变,新旧头指针均后移。a节点确认后,真实dom序列为:a,b,c,d,e,f,未确认dom序列为:b,c,d,e,f;
第二次是尾尾相似(都是f),dom不改变,新旧尾指针均前移。f节点确认后,真实dom序列为:a,b,c,d,e,f,未确认dom序列为:b,c,d,e;
第三次是头尾相似(都是b),当前剩余真实dom序列中的头移到尾,旧头指针后移,新尾指针前移。b节点确认后,真实dom序列为:a,c,d,e,b,f,未确认dom序列为:c,d,e;
第四次是尾头相似(都是e),当前剩余真实dom序列中的尾移到头,旧尾指针前移,新头指针后移。e节点确认后,真实dom序列为:a,e,c,d,b,f,未确认dom序列为:c,d;
第五次是均不相似,直接插入到未确认dom序列头部。g节点插入后,真实dom序列为:a,e,g,c,d,b,f,未确认dom序列为:c,d;
第六次是均不相似,直接插入到未确认dom序列头部。h节点插入后,真实dom序列为:a,e,g,h,c,d,b,f,未确认dom序列为:c,d;
但结束循环后,有两种情况需要考虑:
新的字节点数组(newCh)被遍历完(newStartIdx > newEndIdx)。那就需要把多余的旧dom(oldStartIdx -> oldEndIdx)都删除,上述例子中就是c,d;
新的字节点数组(oldCh)被遍历完(oldStartIdx > oldEndIdx)。那就需要把多余的新dom(newStartIdx -> newEndIdx)都添加。
上面说了这么多都是没有key的情况,说添加了:key可以优化v-for的性能,到底是怎么回事呢?因为v-for大部分情况下生成的都是相同tag的标签,如果没有key标识,那么相当于每次头头比较都能成功。你想想如果你往v-for绑定的数组头部push数据,那么整个dom将全部刷新一遍(如果数组每项内容都不一样),那加了key会有什么帮助呢?这边引用一张图:
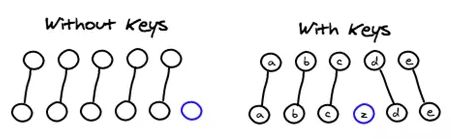
有key的情况,其实就是多了一步匹配查找的过程。也就是上面循环流程中的第五步,会尝试去旧子节点数组中找到与当前新子节点相似的节点,减少dom的操作!
有兴趣的可以看看代码:
function updateChildren (parentElm, oldCh, newCh) {
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, elmToMove, before
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // 未定义表示被移动过
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) { // 头头相似
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) { // 尾尾相似
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // 头尾相似
patchVnode(oldStartVnode, newEndVnode)
api.insertBefore(parentElm, oldStartVnode.elm, api.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // 尾头相似
patchVnode(oldEndVnode, newStartVnode)
api.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 根据旧子节点的key,生成map映射
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
// 在旧子节点数组中,找到和newStartVnode相似节点的下标
idxInOld = oldKeyToIdx[newStartVnode.key]
if (isUndef(idxInOld)) {
// 没有key,创建并插入dom
api.insertBefore(parentElm, createElm(newStartVnode), oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
// 有key,找到对应dom ,移动该dom并在oldCh中置为undefined
elmToMove = oldCh[idxInOld]
patchVnode(elmToMove, newStartVnode)
oldCh[idxInOld] = undefined
api.insertBefore(parentElm, elmToMove.elm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}
}
}
// 循环结束时,删除/添加多余dom
if (oldStartIdx > oldEndIdx) {
before = isUndef(newCh[newEndIdx+1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
最后
希望看完这篇对虚拟dom的比较会有一定的了解!如果有什么错误记得悄悄告诉我啊哈哈。
文笔还是不好,希望大家能理解o(︶︿︶)o
4篇文章写了两个月......真是佩服自己的执行力!但发现写博客好像确实挺费时的(┬_┬),不过以后一定会经常写,先两周一篇?