PP-MobileSeg: 探索移动设备上又快又准的语义分割模型
论文:https://arxiv.org/abs/2304.05152
代码:https://github.com/open-mmlab/mmsegmentation/tree/main/projects/pp_mobileseg
0、摘要
transformer在CV领域的成功之后,出现了很多在移动设备上使用它们的尝试性工作,但是这些工作在某些实际应用中的表现仍然不能令人满意。为了解决这个问题,本文提出PP-MobileSeg——一个在移动设备上达到SOTA的语义分割模型。PP-MobileSeg包含三个新颖的设计:StrideFormer backbone、聚合注意力模块(AAM)、有效差值模块(VIM):
- 包含了4个stage的StrideFormer backbone 由MV3块和SEA注意力模块构建,能够以最小的参数量提取丰富的语义信息与细节特征;
- AAM则首先通过语义特征集成投票过滤细节特征,然后将它们与语义特征相结合以增强语义信息;
- VIM将下采样的特征上采样到输入图像的大小,它通过仅插值最终预测中存在的类来显着降低模型延迟,这是降低整体模型延迟的最主要因素。
大量实验表明,与其他方法相比,PP-MobileSeg 在准确性、模型大小和延迟之间实现了更好的权衡。在ADE20K数据集上,PP-MobileSeg在mIoU上比SeaFormer-Base高1.57%,在高通骁龙855上减少了32.9%的参数和42.3%的加速。
1、引言
相比图像分类、目标检测之类的图像任务,语义分割计算比较昂贵的,因为它需要预测每个像素的类别。由于GPU的存在,现在很少有针对移动设备的语义分割研究。而研究的缺乏,又阻碍了语义分割在移动APP上的应用。
最近,视觉transformer的爆发式增长,证明了基于transformer的神经网络在语义分割方面的潜力。有部分工作提出利用transformer-CNN结合的混合架构来设计轻量网络,比如Mobile ViT、MobileFormer、EdgeNext。这种混合架构的网络以最低的计算成本结合了全局与局部信息,然而多头自注意力(MHSA)却使得这几个网络很难用于移动设备。尽管已经通过诸如滑窗注意力、高效注意力、外部注意力、轴向注意力、SEA注意力等技术来降低计算复杂度,但是这些技术中的许多需要复杂的索引操作,ARM CPU仍不能支持。除了延时与准确率,内存也是一个制约移动设备应用的关键因素,因为移动设备的内存通常比较有限。因此出现了一个基本问题:我们能否为移动设备设计一个混合网络,在参数、延迟和精度之间具有优越的权衡?
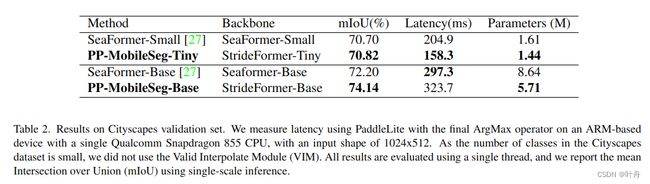
在这项工作中,我们通过在模型大小和速度约束下探索移动分割架构来解决上述问题,以实现性能飞跃。在广泛搜索下,我们设法提出了三个新颖的设计模块:四级主干StrideFormer、特征融合块AAM和上采样模块VIM,如图2所示。通过结合这些模块,我们提出了一系列名为 PP-MobileSeg 的 SOTA 移动语义分割网络,该网络非常适合具有大量参数、延迟和精度平衡的移动设备。我们改进的网络设计允许 PPMobileSeg-Base 在保持具有竞争力的 1.37 更高的 mIoU(表1)的同时,将推理速度提高 40% 和并将模型大小降低34.9%。与 MobileSeg-MV3 相比,PP-MobileSeg-Tiny 实现了 3.13 更高的 mIoU,同时速度提高了 45% 和 49.5%(表 1)。我们还评估了 PP-MobileSeg 在 Cityscapes 数据集 (表 2)上的性能,这表明它在高分辨率输入上的模型性能方面具有优势。尽管 PP-MobileSeg-Base 的延迟稍长,但它在 mIoU 上比 SeaFormer在Cityscapes数据集 上的模型大小优势高 1.96。
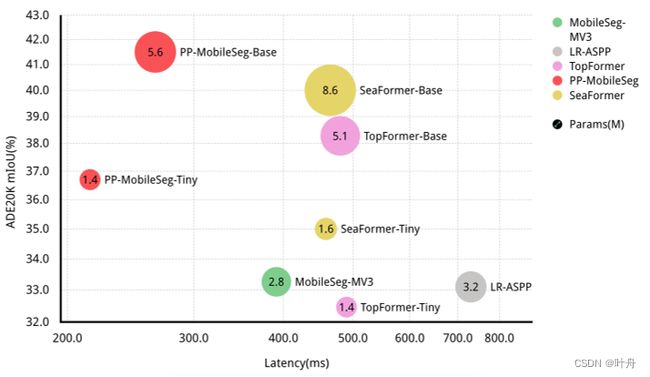 图 1. 我们在 ADE20K 验证集上展示了我们提出的 PP-MobileSeg 模型的准确度延迟参数分析。trade-off分析表示为气泡图,其中 x 轴表示延迟,y 轴表示 mIoU。具有相同颜色的模型来自同一个模型系列。我们的模型实现了更好的准确性-延迟-参数权衡。请注意,延迟使用 Qualcomm Snapdragon 855 CPU 上的 PaddleLite 测试,单线程为 512x512 作为输入形状。
图 1. 我们在 ADE20K 验证集上展示了我们提出的 PP-MobileSeg 模型的准确度延迟参数分析。trade-off分析表示为气泡图,其中 x 轴表示延迟,y 轴表示 mIoU。具有相同颜色的模型来自同一个模型系列。我们的模型实现了更好的准确性-延迟-参数权衡。请注意,延迟使用 Qualcomm Snapdragon 855 CPU 上的 PaddleLite 测试,单线程为 512x512 作为输入形状。
 表 1. ADE20K 验证集的结果。使用PaddleLite测量延迟,在高通骁龙855 CPU上使用最终的ArgMax算子,以512x512为输入形状。所有结果都使用单个线程进行评估。mIoU 是通过单尺度推理报告的。
表 1. ADE20K 验证集的结果。使用PaddleLite测量延迟,在高通骁龙855 CPU上使用最终的ArgMax算子,以512x512为输入形状。所有结果都使用单个线程进行评估。mIoU 是通过单尺度推理报告的。
本文贡献总结如下:
- 提出了StrideFormer,一个具有MobileNetV3块的4-stage的backbone,可以有效地提取不同接收域的特征,同时最小化参数开销;
- 提出了聚合注意模块(AAM),它通过增强语义特征的集成投票来融合来自主干的特征,并进一步增强融合特征具有最大感受野的语义特征;
- 为了减少最终插值和 ArgMax 操作引起的显着延迟,我们设计了 Valid Interplate Module (VIM),该模块在推理时只对最终预测中存在的类进行上采样;用 VIM 替换最终的插值和 ArgMax 操作显着减少了模型延迟;
- 我们将上述模块结合起来,创建了一系列名为 PPMobileSeg 的 SOTA 移动分割模型。我们的大量实验表明,PPMobileSeg 在 ADE20K 和 Cityscapes 数据集的延迟、模型大小和准确性之间取得了很好的平衡。
2、相关工作
在速度和模型大小约束下,移动语义分割是一项旨在采用高效网络设计的语义分割网络的任务。
2.1. 语义分割
为了在语义分割中实现高性能,几个关键元素是必不可少的,包括一个大的感受野来捕获上下文、高分辨率的特征进行精确分割、细节和语义特征的融合用于精确预测以及改进特征表示的注意机制。SOTA模型通常结合几个甚至所有这些元素来实现卓越的性能。语义分割任务的主要要求是,网络必须能够捕获场景的整体视图,同时保留图像的细节和语义。因此,必须设计能够高效有效地整合这些元素的网络架构。
2.2. 高效网络设计
由于语义分割的计算复杂度大,移动设备上的分割研究有限,只有少数研究关注这一领域。其中,TopFormer 使用自注意力块增强令牌金字塔,并使用他们提出的注入模块将其与局部特征融合。此外,SeaFormer通过高效的SEA注意模块提高了模型的性能。它们都显着优于 MobileSeg 和 LRASPP,后者目前代表了移动语义分割的最新技术。
3、方法
本节全面探索在速度和大小约束下设计的移动分割网络,旨在获得更好的分割精度。通过我们的研究,我们确定了三个关键模块,这些模块导致更快的推理速度或更小的模型大小,并略微提高了性能。PP-MobileSeg 的完整架构如图 2 所示,它包括四个主要部分:StrideFormer、Aggregate Attention Module (AAM)、segmentation head 和 Valid Interpolate Module (VIM)。StrideFormer利用输入图像生成一个特征金字塔,将跨步注意应用于最后两个阶段,以合并全局语义。AAM负责融合局部特征和语义特征,然后通过分割头生成分割掩码。最后,上采样模块 VIM 用于进一步增强分割掩码,仅通过对最终预测中存在的类对应的少数通道进行上采样来减少延迟。以下部分详细描述了这些模块中的每一个。
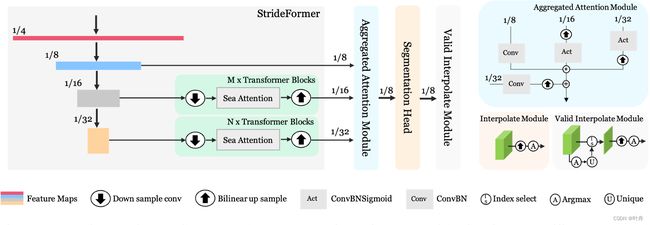 图 2. PP-MobileSeg 网络架构。AAM 的结构在图的顶部。法线插值模块和 VIM 之间的差异显示在图右下角。通过选择最终预测中存在的类,VIM 通过上采样几个通道显着降低了延迟。
图 2. PP-MobileSeg 网络架构。AAM 的结构在图的顶部。法线插值模块和 VIM 之间的差异显示在图右下角。通过选择最终预测中存在的类,VIM 通过上采样几个通道显着降低了延迟。
3.1. StrideFormer
在StrideFormer模块中,我们利用MobileNetV3[12]块的堆栈来提取不同接收域的特征。关于该架构变体的更详细信息可以在 3.4 小节中找到。给定一个![]() 的图像,其中 3, H, W 表示图像的通道、高度和宽度。StrideFormer 产生特征 {F×8, F×16, F×32},表示原分辨率下采样 8, 16 和 32 倍的特征。一个关键的设计选择是主干中的阶段数,其中每个阶段都是一个MobileNetv3块的堆叠,它产生一个特征集
的图像,其中 3, H, W 表示图像的通道、高度和宽度。StrideFormer 产生特征 {F×8, F×16, F×32},表示原分辨率下采样 8, 16 和 32 倍的特征。一个关键的设计选择是主干中的阶段数,其中每个阶段都是一个MobileNetv3块的堆叠,它产生一个特征集![]() 。受 EfficientFormer 的启发,我们发现与 五阶段模型相比,四阶段模型具有最小的参数开销,同时仍然保持出色的性能。因此,我们设计了具有四个阶段范式的StrideFormer。使用从四个阶段主干生成的 {F×8, F×16, F×32},我们在最后两个阶段的特征上添加 M/N SEA 注意块。考虑到具有高分辨率输入的自注意力模块的时间复杂度,我们在 SEA 注意力模块之前添加了步幅卷积,然后对特征进行上采样。通过这种方式,当我们用全局信息赋予特征时,我们将计算复杂度降低了原始实现的 1/4。
。受 EfficientFormer 的启发,我们发现与 五阶段模型相比,四阶段模型具有最小的参数开销,同时仍然保持出色的性能。因此,我们设计了具有四个阶段范式的StrideFormer。使用从四个阶段主干生成的 {F×8, F×16, F×32},我们在最后两个阶段的特征上添加 M/N SEA 注意块。考虑到具有高分辨率输入的自注意力模块的时间复杂度,我们在 SEA 注意力模块之前添加了步幅卷积,然后对特征进行上采样。通过这种方式,当我们用全局信息赋予特征时,我们将计算复杂度降低了原始实现的 1/4。
3.2. Aggregated Attention Module,AAM
使用主干生成的 {F×8, F×16, F×32},我们设计了一个聚合注意模块 (AAM) 来融合特征。AAM的结构在图2的右上角。在生成的特征中,{F×16, F×32}具有更大的接受域,包含丰富的语义信息。因此,我们通过集成投票将它们用作信息过滤器,来从详细的特征 F×8 中找到重要信息。在过滤过程中,F×16 和 F×32 上采样到与 F×8 相同的分辨率。并将它们应用 sigmoid 算子来获得权重系数。之后,将F×16和F×32相乘,利用乘法结果过滤F×8。我们可以将上述过程表述为公式1:
此外,我们观察到具有丰富语义的特征补充了先前过滤的细节特征,并且对于提高模型性能至关重要。因此,应该最大程度地保留它。因此,我们将具有最大感受野且使用全局视图增强的 F×32 也添加到过滤后的细节特征中。

特征融合后,就能够捕获丰富的空间和语义信息,这是分割性能的基础。 在此基础上,我们按照TopFormer的方式添加了一个简单的分割头。分割头由一个 1×1 层组成,这有助于沿通道维度交换信息。然后应用 dropout 层和卷积层来生成下采样分割图。
3.3. Valid Interpolate Module,VIM
在延迟约束下,我们进行了延迟配置文件,发现最终的插值和 ArgMax 操作占总延迟的 50% 以上。因此,我们设计了有效的插值模块(VIM)来代替插值和 ArgMax 操作,并大大减少模型延迟。SeaFormer-Base和PP-MobileSeg-Base的延迟曲线如图3所示。
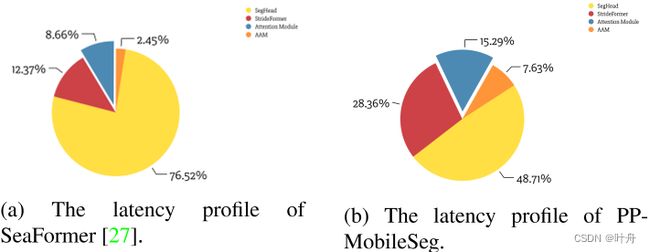 图3. SeaFormer和PPMobileSeg的延迟剖面比较。
图3. SeaFormer和PPMobileSeg的延迟剖面比较。
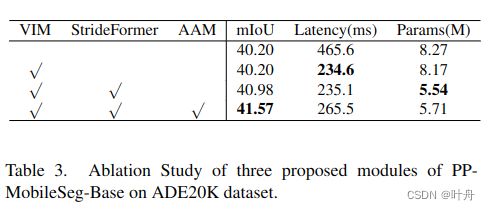
添加 VIM 后的详细统计数据见表3。
VIM 的提出是基于观察到出现在训练好的模型预测时出现的类别数通常远小于数据集中类别的总数,尤其是对于具有大量类别的数据集,这在具有大量类的数据集中比较常见。因此,在插值和 ArgMax 过程中没有必要考虑所有类。VIM的结构在图2的右下角。如图所示,VIM 由三个主要步骤组成。首先,在下采样后的分割map上应用ArgMax 和 Unique 操作来找到必要的通道;然后,使用索引选择操作来仅选中那些有效通道,并在缩小后的特征上应用插值操作;最后,将所选通道上采样到原始分辨率,生成最终的分割图。使用 VIM 代替插值和 ArgMax 操作,我们以更少的延迟成本检索最终的分割图。
VIM 的使用大大减少了插值和 ArgMax 操作中涉及的通道,导致模型延迟显着下降。但是,VIM 仅适用于类数足够大以在模型中具有通道冗余的情况。因此,设置了 30 的类阈值,当类的数量低于此阈值时,VIM 不会生效。
3.4. 架构变体
我们提供了 PP-MobileSeg 的两种变体,以使我们的模型适应不同的复杂性要求,即 PPMobileSeg-Base 和 PP-MobileSeg-Tiny。这两个输入形状为 512x512 的变体的大小和延迟如表中所示1。base模型和tiny模型拥有相同数量的 MobileNetV3 层,但base模型比tiny模型宽。base模型生成具有更多通道的特征来丰富特征表示。此外,注意块也存在一些差异。PP-MobileSeg-Base 模型在 SEA 注意力模块中有 8 个头,M/N = 3/3 个注意块。PP-MobileSeg-Tiny 模型在 SEA 注意力模块中有 4 个头,块数为 M/N = 2×2。在最后两个阶段的特征通道个数上,PP-MobileSeg-Base是128、192,而PP-MobileSeg-Tiny是64、128。特征融合模块的设置对于base模型和tiny模型是相同的,AAM的嵌入通道dim设置为256。
4、实验结果

5、总结
在本文中,我们研究了混合视觉主干的设计,并解决了移动设备语义分割网络的延迟瓶颈。经过彻底的探索,我们确定了对移动设备友好的设计选项,并提出了一种新的结合了transformer块和CNN的移动语义分割网络,称为PP-MobileSeg。通过精心设计的主干、融合模块和插值模块,PP-MobileSeg 在基于 ARM 的设备上实现了模型大小、速度和准确性之间的 SOTA 平衡。