MySQL常用增删改查语法命令
一. 添加数据:INSERT
Insert 语句用于向数据库中插入数据
1. 插入单条数据(常用)
语法:INSERT INTO 表名(列名1,列名2,...) values(值1,值2,...)
案例:
insert into Student(s_id,s_name,s_birth,s_sex) values('01' , '赵信' , '1990-01-01' , '男');
2. 插入单条数据
语法:INSERT INTO 表名 SET 列名 = 值,列名 = 值
这种方式每次只能插入一行数据,每列的值通过赋值列表制定
案例:
INSERT INTO student SET s_id='02',s_name='德莱厄斯',s_birth='1990-01-01',s_sex='男'
3. 插入多条数据
语法:insert into 表名 values(值1,值2,值3),(值4,值5,值6),(值7,值8,值9)
案例:
INSERT INTO student VALUES('03','艾希','1990-01-01','女'),('04','德莱文','1990-08-06','男'),('05','俄洛依','1991-12-01','女');
二. 更新数据:UPDATE
Update 语句一共有两种语法,分别用于更新单表数据和多表数据。
1. 修改一条数据的某个字段
语法:UPDATE 表名 SET 字段名 =值 where 字段名=值
案例:
UPDATE student SET s_name ='张三' WHERE s_id ='01'
2. 修改多个字段为同一的值
语法:UPDATE 表名 SET 字段名= 值 WHERE 字段名 in ('值1','值2','值3');
案例:
UPDATE student SET s_name = '李四' WHERE s_id in ('01','02','03');
三. 删除数据:DELETE
数据库一旦删除数据,它就会永远消失。 因此,在执行DELETE语句之前,应该先备份数据库,以防万一要找回删除过的数据。
1. 删除指定数据
语法:DELETE FROM 表名 WHERE 列名=值
注意:删除的时候如果不指定where条件,则保留数据表结构,删除全部数据行,有主外键关系的都删不了
案例:
DELETE FROM student WHERE s_id='09'
2. 删除表中全部数据
语法:TRUNCATE 表名;
注意:全部删除,内存无痕迹,如果有自增会重新开始编号。
与 DELETE 不同的是,TRUNCATE 只能删除表中的全部数据,而不能通过 WHERE 子句指定条件来删除部分数据。也正是因为它不能具体地控制删除对象, 所以其处理速度比 DELETE 要快得多。实际上,DELETE 语句在 DML 语句中也 属于处理时间比较长的,因此需要删除全部数据行时,使用 TRUNCATE 可以缩短 执行时间。
案例:
TRUNCATE student1;
四. wherer 条件语句
语法:select 列名 from 表名 where 列名 =值
案例 1(AND):
SELECT * FROM student1 WHERE name ='张三' AND sex='男'
案例 2(OR):
SELECT * FROM student WHERE s_name ='奥特曼' OR s_sex='男'
案例 3(NOT):
SELECT * FROM student WHERE NOT s_name ='奥特曼'
案例 4(IS NULL):
SELECT * FROM student1 WHERE name IS NULL;
案例 5(IS NOT NULL):
SELECT * FROM student1 WHERE name IS NOT NULL;
案例 6(BETWEEN):
SELECT * FROM student1 WHERE s_birth BETWEEN '2022-01-20' AND '2022-01-22'
案例 7(LINK):
SELECT * FROM student1 WHERE name LIKE '大%'
案例 8(IN):
SELECT * FROM student1 WHERE name IN ('小四','小李')
五. as 取别名
- 表里的名字没有变,只影响了查询出来的结果
案例:
SELECT A_name as `name` FROM student
六. distinct 去除重复记录
- 注意:当查询结果中所有字段全都相同时 才算重复的记录
案例:
SELECT DISTINCT * FROM student1查询指定字段
- 星号表示所有字段
- 手动指定需要查询的字段
- 案例:
SELECT DISTINCT s_name,s_birth FROM student
七. group by 分组
- group by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组。
语法:select 字段名 from 表名 group by 字段名称;
1. 单个字段分组
SELECT COUNT(*)FROM student GROUP BY sex;
2. 多个字段分组
SELECT s_name,s_sex,COUNT(*) FROM student GROUP BY s_name,s_sex;
八. having 过滤
HAVING 子句对 GROUP BY 子句设置条件的方式与 WHERE 和 SELECT 的交互方式类似。WHERE 搜索条件在进行分组操作之前应用;而 HAVING 搜索条件在进行分组操作之后应用。HAVING 语法与 WHERE 语法类似,但 HAVING 可以包含聚合函数。HAVING 子句可以引用选择列表中显示的任意项。
我们如果要查询男生或者女生,人数大于5的性别
SELECT s_sex as 性别,count(s_id) AS 人数 FROM student GROUP BY s_sex HAVING COUNT(s_id)>5
九. order by 排序
根据某个字段排序,默认升序(从小到大)
语法:
select * from 表名 order by 字段名;
1. 一个字段,降序(从大到小)
SELECT * FROM student ORDER BY id DESC;
2. 多个字段
SELECT * FROM student ORDER BY id DESC, birth ASC;
多个字段 第一个相同在按照第二个 asc 表示升序
十.limit 分页
用于限制要显示的记录数量
语法1:
select * from name limit 个数;语法2:
select * from name limit 起始位置,个数;案例:
查询前三条数据
SELECT * FROM student1 LIMIT 3;从第三条开始 查询3条
SELECT * FROM student1 LIMIT 2,3;子查询
- 将一个查询语句的结果作为另一个查询语句的条件或是数据来源, 当我们一次性查不到想要数据时就需要使用子查询。
SELECT * FROM score WHERE id =( SELECT id FROM student1 WHERE name = '李四')1. in 关键字子查询
- 当内层查询 (括号内的) 结果会有多个结果时, 不能使用 = 必须是in ,另外子查询必须只能包含一列数据
- 要分析 查到最终的数据 到底有哪些步骤
- 根据步骤写出对应的sql语句
- 把上一个步骤的sql语句丢到下一个sql语句中作为条件
-
子查询的思路:
SELECT
*
FROM
score
WHERE
id IN (
SELECT
id
FROM
student1
WHERE
sex = '女')
多表查询
1. 内连接查询
- 本质上就是笛卡尔积查询
语法:select * from 表1 inner join 表2;
2.左外连接查询
- 左边的表无论是否能够匹配都要完整显示,右边的仅展示匹配上的记录
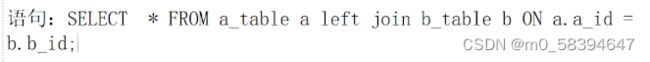
3.右外连接查询
- 右边的表无论是否能够匹配都要完整显示,左边的仅展示匹配上的记录
