CPU缓存命中率和缓存行详解
冯诺依曼计算机
早期的冯诺依曼计算机,大抵功能和工作流程如下:
- 输入设备接收用户输入的指令信息
- 数据到达到达运算器,运算器将需要的指令存入存储器中
- 控制器从存储器中捞数据和指令进行计算再给运算器进行计算,然后再响应到输出设备
从这几个步骤中,我们可以感觉到一个很明显的坑,控制流程调度的事情落到了运算器身上,导致了很多没必要的开销。

现代计算机
现在计算机对此进行了改造,可以看出他们将需要处理的数据的运算器和存储器放到两边,然后存储器负责运输数据给这两者,数据经过运算器计算之后再将数据经过存储器再转交给控制器转发到输出设备

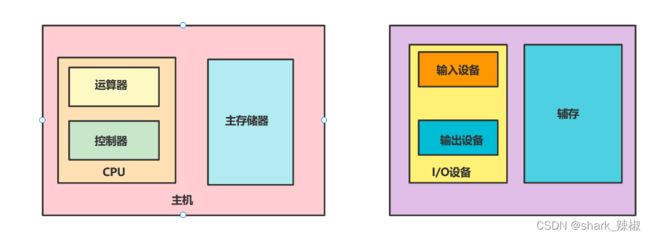
了解这样的体系结构后,我们将这些组成部分转换为下图,就得到了现代计算机重要的一个部分-cpu
cpu就包含了运算器和控制器以及主存储器,也就是我们常说的内存。
而辅存就是我们常说的硬盘
了解完现代计算机体系结构后,我们将职责进行划分就构成了下图所示的样子,可以看出由运算器和控制器构成了CPU,主存也就是我们常说的内存,外设部分由一些I/O设备、辅存(就是硬盘)组成。
来聊聊CPU调优
为什么写代码时,要考虑到通过CPU来提升程序性能呢?
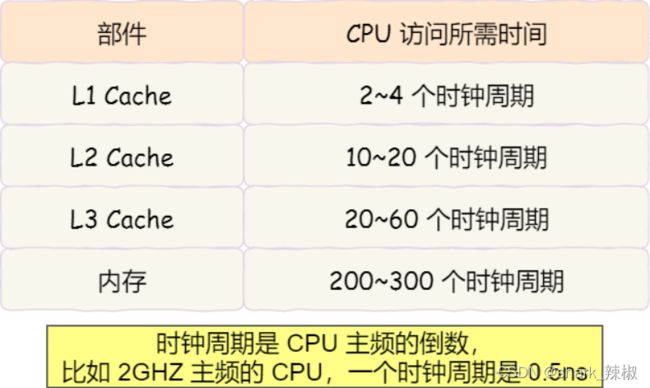
如下图所示,可以看出cpu cache的访问速度远远大于内存以及辅存速度。所以我们如果能够尽可能的利用cpu cache来存储我们常访问到的速度。
简述CPU Cache的工作过程
在CPU访问数据的时候,都会优先去缓存中获取数据,如果没数据再去内存取,若内存找不到,则直接取磁盘中找到数据并加载到CPU CACHE中。

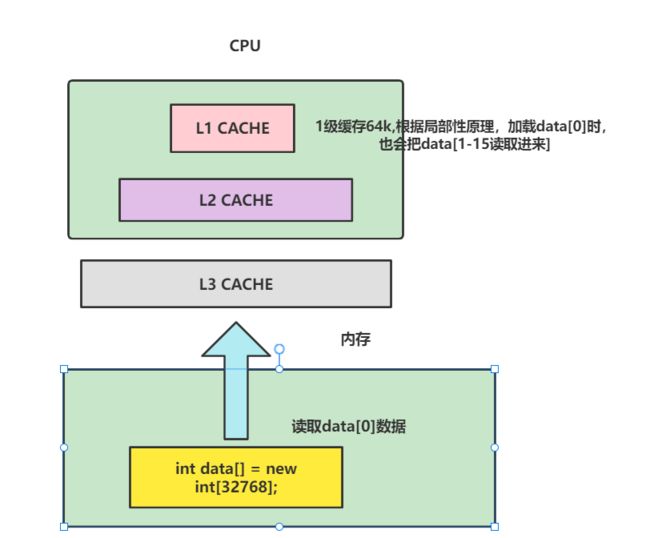
当CPU CACHE开始加载数据的时候,他也不是一个数组都读起来,而是一小块一小块的进行数据读取。而这一小块数据就是我们日常所说的CPU Line(缓存行)。
我们不妨在Linux中键入如下的命令,我们就能够看到自己CPU L1 Cache对应的CPU Line的大小。以笔者为例,查到的大小为64字节。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
# 输出结果
64
这64字节是什么概念呢?
我们都知道一个整型变量是4个字节。假如我们声明一个数组int data[] = new int[32768];,当CPU cache载入data[0]时,由于cache line的大小为64字节,也就是说还会有一些空闲的空间没用到,根据局部性原理,CPU就会将剩余部分用于存储data[0]附近的数据,也就是说载入data[0]时,cache line顺手将索引1-15的元素也加载到CPU cache line中。
那么问题又来了?当cache中有内存加载的数据时,我们怎么知道这个数据对应的内存那块数据呢?
其实CPU早就考虑到这点了,实现方式也很简单,通过直接映射Cache(Direct Mapped Cache),说白了就是将内存地址和CPU cache line做一个映射,我们都知道内存的一块块数据称为内存块,实现地址映射的方式也很简单,就是将内存块地址进行取模运算后再将存到对应的cache line中。
例如我们有8个cache line,32个内存块,当cache需要载入15号块时,cache就会将其存到15%8=7,即7号cache line中。
假如映射地址冲突了怎么办?
这个问题也很简单,增加一个标记就好了,CPU cache给这个标记一个名字Tag。
有了tag区分冲突,cpu cache line还需要data存储数据,由于操作系统是多线程运行的,很可能某些数据会在运行期间过期,所以我们也要加一个Valid bit判断这个cache line的数据是否有效,若无效则让CPU别管这个cache line的数据,直接去找内存要数据**(这个工作机制即MESI协议,感兴趣的读者可以自行了解一下)**。
而CPU真正要访问数据的时候,也并不是读取整个cache line的数据,而是读取其中需要的一小部分,这一小部分我们称之为字(Word)。那么我们又该如何找到这个字呢?就是偏移量。
如下图所示,通过取模运算找到对应的cache line,再通过valid bit看看这个cache line是否有效,若有效则继续通过tag找到需要的组,配合偏移量获取的自己所需要的字,CPU就可以开始真正干活了。

(实践)通过CPU的核心原理编写高效的代码
遍历顺序适配CPU缓存加载顺序
先看看下面一段代码,可以看出下面这段代码每一轮都只遍历二维数组的每一行的第一列,在笔者电脑上运行需要5321微秒
public static void main(String[] args) {
int[][] arr = new int[10000][10000];
long start = System.currentTimeMillis();
// 纵向遍历,即外层循环代表二维数组的列,内层循环遍历数组的行,例如下面代码执行到 i=0 j=1,就代表获取以第1行第0个元素
for (int i = 0; i < 10000; i++) {
for (int j = 0; j < 10000; j++) {
arr[j][i] = 0;
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
}
再看看这段代码,在笔者电脑上运行只需要119微妙,这是为什么呢?
public static void main(String[] args) {
int[][] arr=new int[10000][10000];
long start=System.currentTimeMillis();
for (int i = 0; i <10000 ; i++) {
for (int j = 0; j < 10000; j++) {
arr[i][j]=0;
}
}
long end=System.currentTimeMillis();
System.out.println(end-start);
}
我们不妨想想上文中,cpu cache的原理,由于局部性原理,加载某个数据时会加载其附近的数据,第一段代码遍历数据是纵向遍历的。这就意味着CPU CACHE中的数据不一定有我们for循环所需要的数据。
。就像下图一样,cpu cache只会顺序加载其附近的数据,假如我们取得arr[0] [0],那么他就会顺序加载arr[0] [1]、arr[0] [2]、arr[0] [3]。这就导致遍历过程中只有第一次遍历的列在缓存中,其他列的数据都要去内存中取。

而第二段代码遍历顺序和局部性原理加载顺序是一致的,所需效率自然高了。

提升指令缓存命中率提高效率
我们需要编写这样一段代码,这段代码实现的事情很简单。随机生成一个一维数组,然后遍历判断其ASCII码值是否大于128,若大于128则进行相加。然后排序输出。
先看看第一段代码,实现过程时,先计算,在排序。这段代码在笔者电脑执行时间为10.4748198s
public static void main(String[] args) {
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i) {
// Primary loop
for (int c = 0; c < arraySize; ++c) {
if (data[c] >= 128)
sum += data[c];
}
}
// !!! With this, the next loop runs faster
Arrays.sort(data);
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
再看看第二段代码,先排序再计算。神奇的是这段代码只需要4.5811642s。
public static void main(String[] args) {
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// Test
long start = System.nanoTime();
long sum = 0;
// !!! With this, the next loop runs faster
Arrays.sort(data);
for (int i = 0; i < 100000; ++i) {
// Primary loop
for (int c = 0; c < arraySize; ++c) {
if (data[c] >= 128)
sum += data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
这是为什么呢?
原因其实也很简单,CPU中有一个分支预测器,他会动态根据代码执行if else逻辑的命中数,决定是否将某个分支代码加载到cache中。就以上面两段代码为例,第一段代码数组毫无规律,导致分支预测器无法准确预测,所以cache中的指令不一定是将要执行的分支代码,代码段二反之。
基于现场绑定CPU实现多核 CPU 的缓存命中率
在单核 CPU,虽然只能执行一个进程,但是操作系统给每个进程分配了一个时间片,时间片用完了,就调度下一个进程,于是各个进程就按时间片交替地占用 CPU,从宏观上看起来各个进程同时在执行。
而现代 CPU 都是多核心的,进程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个进程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果进程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
参考文献
2.3 如何写出让 CPU 跑得更快的代码?
深入理解CPU的分支预测(Branch Prediction)模型