YugabyteDB对比CockroachDB-第二部分
注:本文翻译自YugabyteDB官网文章 yugabytedb-vs-cockroachdb-bringing-truth-to-performance-benchmark-claims-part-2
概要
Yugabyte SQL是基于对PostgreSQL原生查询层的重用。这种重用保留了PostgreSQL中许多最先进的RDBMS特性,因此应用程序的开发速度不会受到影响。另一方面,CockroachDB还远没有成为今天PostgreSQL那样完整的RDBMS。尝试与PostgreSQL v9.6兼容是一个很好的起点,但还不足以满足目前由PostgreSQL或其他成熟的关系数据库提供的关系工作负载的广度和深度。
此外,YugabyteDB的DocDB(基于rocksdb的存储层)从头开始设计,以高性能作为明确的设计目标,特别是针对大规模工作负载。多盘智能负载均衡,压缩队列分离,减少读放大,系统过载时反压写,保持良好的读性能。以及允许多个RocksDB实例在单个节点上高效地协同工作,这些设计决策可以带来更高的性能特征。另一方面,由于在存储层的设计选择过于简单,CockroachDB在大规模工作负载下的性能很差。这种选择包括将多个不相关范围的物理存储多路复用到一个RocksDB实例中,以及频繁的资源密集型范围分割操作(假设最大范围大小只有64MB)。
我们已经证明了Yugabyte SQL的性能优于CockroachDB,在一个拥有450万行的1.35TB数据集上使用YCSB测试,平均吞吐量提高了3倍,延迟降低了4.5倍。此外,CockroachDB无法在合理的时间内加载包含1B行的3TB数据集,而Yugabyte SQL没有遇到这样的问题。包括复制文件在内的详细信息在下面的性能深入研究部分提供。
查询层 –重用PostgreSQL
Cockroach Labs的分析一再指出,重用PostgreSQL是YugabyteDB架构问题背后的主要原因,这是一个完全错误的声明。重用PostgreSQL有许多优点。我们将在本节中重点介绍其中的一些。关于为什么我们在YugabyteDB中重用PostgreSQL查询层的细节,在另一篇单独的博客文章中有详细描述。
YugabyteDB重用了PostgreSQL的上半部分,同时用一个叫做DocDB的分布式存储层替换了PostgreSQL的存储层。如下图所示,整体PostgreSQL在左边,分布式YugabyteDB在右边。

这种方法最大的一个优点是YugabyteDB可以利用高级的RDBMS特性,这些特性是经过精心设计的、经过实战测试的,并且已经被PostgreSQL记录下来了。虽然在YugabyteDB节点集群上优化这些特性的工作非常重要,但使用这种方法确实从根本上简化了查询层。
更具体地说,让我们比较一下CockroachDB选择在Go中重写一个与PostgreSQL兼容的查询层和YugabyteDB重用PostgreSQL原生c++查询层的方法。尽管YugabyteDB的开发时间较短,但它已经比CockroachDB支持更多的RDBMS特性。下面是YugabyteDB支持而CockroachDB不支持的特性列表,其中一些在CockroachDB文档中列出了:

存储层 – 大规模下高性能
DocDB是YugabyteDB的底层分布式文档存储,其设计目标是在大规模下提供高性能。如下图所示,为了支持这一设计目标,DocDB内建了许多特性。请注意,DocDB使用了一个高度定制的RocksDB版本来实现节点本地持久性。

在下面我们将详细介绍的性能测试中,我们只关注了DocDB的一些增强和体系结构决策。更具体地说,我们将专注于多个磁盘的智能负载平衡,分离压缩队列以减少读放大,并使多个RocksDB实例能够在单个节点上高效地工作。DocDB为RocksDB增加了许多其他的增强功能,以使YugabyteDB能够实现大规模的高性能。在查询层和全局事务管理器中还有其他类似的改进,但这些主题本身就是一系列帖子。
大数据量下性能的深度挖掘
在第一个示例中,我们想做一个“苹果对苹果”的比较,查看在磁盘上有大量数据集的场景中CockroachDB和YugabyteDB的性能。在这个实验中,我们使用带有标准JDBC绑定的YCSB基准测试将10亿行加载到3个节点的集群中。我们希望数据加载结束时,每个节点上的数据集跨1TB(或每个集群中总数据集大小为3tb)。
以下是关于我们测试的配置的相关细节:
两个集群都部署在AWS us-west-2区域
CockroachDB v19.2.6
带有YSQL API的YugabyteDB v2.1.5
每个集群有3个节点
每个节点是一个c5.4 ×大
每个节点有2个5TB ssd (gp2 EBS)
基准测试是在CockroachDB的一个范围分片表上运行的,而在YugabyteDB上,我们同时使用了范围和散列。没有使用散列分片的CockroachDB表进行基准测试,因为GA版本中没有这一功能。
这两个数据库都以默认隔离级别运行(CockroachDB使用serializable, YugabyteDB使用快照隔离)。注意,CockroachDB只支持可序列化的隔离级别,而YugabyteDB同时支持可序列化和快照隔离。
初见结果
请注意,使用YCSB基准测试的这些说明可以复制下面的所有结果。
YugabyteDB的数据加载顺利完成,而CockroachDB未能在合理的时间内加载1B行(即3TB数据)。因此,我们将目标重置为450M行,这大约是1.3TB的数据。
当使用YCSB加载450M行时,YugabyteDB可以维持比CockroachDB高3倍的吞吐量。
在450M行数据集中,我们注意到不同YCSB工作负载的平均性能特征如下。
YugabyteDB的吞吐量比CockroachDB高3倍
YugabyteDB的更新延迟比CockroachDB低7倍
YugabyteDB的读延迟比CockroachDB低2倍
随着数据集大小的增加,cockachdb的吞吐量和更新延迟会急剧恶化。
在450M行表上,CockroachDB的吞吐量比在1M行表上低51%,而在YugabyteDB上的降解率仅为9%。
当从1M行到450M行时,CockroachDB的更新延迟增加了180%,而YugabyteDB的更新延迟只增加了11%。
对于这个特定的基准测试设置,无论我们使用范围分片还是哈希分片,对加载时间、吞吐量和延迟的影响都是最小的。这导致YugabyteDB在这三个维度上击败了CockroachDB,无论采用何种分片方案。
64线程加载1 B行
我们开始在两个数据库上运行记录数为10亿行的YCSB。这是使用标准JDBC绑定完成的,使用64个线程,如下所示。
$ ./bin/ycsb load jdbc -P db.properties -P workloada -threads 64 -s
上面命令中的-s选项定期打印状态,包括加载数据的估计时间。YCSB估计,使用范围分片加载CockroachDB和YugabyteDB的数据大约需要20个小时。注意,对于YSQL散列分片表,使用多个线程将把插入并行化到多个分片中,从而最小化任何“热点”。最终,我们希望每个数据库的吞吐量都达到某种稳定状态。
CockroachDB:数据量越大数据加载性能越低
我们注意到,随着向CockroachDB加载更多的数据,写吞吐量下降,从大约12K操作/秒下降到3.5K操作/秒。由于吞吐量的下降,装载10亿行所需的初始估计时间从20小时增加到45小时以上。

事实上,当吞吐量不断下降时,加载数据的总时间就变成了一个移动目标。因此,我们在此时停止了负载,并开始研究为什么CockroachDB无法维持12k ops/秒的吞吐量。
单个大表使用多块盘
我们的调查发现,虽然提供了两个磁盘,但CockroachDB只能有效地利用一个磁盘。根据文件,这两个磁盘作为参数被传递给CockroachDB。
cockroach start
--store=/mnt/d0/cockroach --store=/mnt/d1/cockroach
但我们发现负载在磁盘之间严重不平衡。以下是在集群中各个节点的每个数据磁盘上运行df -h命令的输出结果。请注意,一个磁盘的使用率很高,而另一个磁盘几乎不被使用。
Node1:
/dev/nvme1n1 5.0T 454M 5.0T 1% /mnt/d0 <-- barely used disk
/dev/nvme2n1 5.0T 455G 4.6T 9% /mnt/d1
Node 2:
/dev/nvme1n1 5.0T 455G 4.6T 9% /mnt/d0
/dev/nvme2n1 5.0T 234M 5.0T 1% /mnt/d1 <-- barely used disk
Node 3
/dev/nvme1n1 5.0T 455G 4.6T 9% /mnt/d0
/dev/nvme2n1 5.0T 174M 5.0T 1% /mnt/d1 <-- barely used disk
每个节点上的一个磁盘的SSTable文件比另一个磁盘少一个数量级。例如,在node1上,我们注意到/mnt/d0/cockroach有15个数据(SSTable)文件,而/mnt/d1/cockroach有超过23K的SSTable文件!
相比之下,YugabyteDB在两个磁盘上的数据分割如下。
Node1:
/dev/nvme1n1 4.9T 273G 4.7T 6% /mnt/d0
/dev/nvme2n1 4.9T 223G 4.7T 5% /mnt/d1
Node 2:
/dev/nvme1n1 4.9T 228G 4.7T 5% /mnt/d0
/dev/nvme2n1 4.9T 268G 4.7T 6% /mnt/d1
Node 3
/dev/nvme1n1 4.9T 239G 4.7T 5% /mnt/d0
/dev/nvme2n1 4.9T 258G 4.7T 6% /mnt/d1
为了理解为什么CockroachDB不能很好地利用多个磁盘,我们转向了YugabyteDB中的tablets和CockroachDB中的range之间的基本区别。
Ranges vs tablets – 架构不同
在CockroachDB和YugabyteDB中,一个表被分割成一个或多个碎片。分布式表中的每一行都只属于这些分片中的一个。一个碎片在CockroachDB中被称为一个范围,而在YugabyteDB中被称为一个tablet。然而,range和tablet之间有一些重要的架构差异,这导致了我们看到的性能差异。
在CockroachDB中,一个范围通常是64MB左右的大小。这意味着对于大型数据集,数据库将不得不管理许多范围。在我们将一个1.3TB的数据集加载到集群的示例中,表中最终有9,223个范围。一个表的多个范围对应的数据存储在一个RocksDB实例中。这意味着范围是数据的纯逻辑拆分,属于不同范围的数据被复用到一个RocksDB实例的物理存储中。在YugabyteDB中,tablet的大小没有限制。我们有用户在生产环境中使用超过100GB的tablet。
与这个CockroachDB Forum用户类似,我们发现CockroachDB中一个表的所有范围都被复用到任何给定节点上的一个RocksDB实例中。然而,一个RocksDB实例只能使用一个磁盘,根据RocksDB FAQ:
您可以在多个磁盘上创建单个文件系统(ext3、xfs等)。然后,您可以在单个文件系统上运行rocksdb。使用磁盘的一些提示:
•如果使用RAID,那么不要使用太小的RAID条带大小(64kb太小,1MB就很好)。
•考虑启用压缩读ahead,指定ColumnFamilyOptions::compaction_readahead_size至少2MB。
•如果工作负载是写大量的,那么有足够的压缩线程保持磁盘繁忙
•考虑启用异步写后压缩
要求更改(如使用RAID在磁盘上创建单个文件系统)会带来很大的操作复杂性。
YugabyteDB中每个tablet的数据都存储在一个单独的RocksDB实例中。表中的tablet均匀地分布在可用磁盘上。这允许YugabyteDB跨磁盘平衡负载并有效地利用它们。为了使每个节点运行多个RocksDB实例非常高效,YugabyteDB的DocDB存储层需要进行一些增强。
compaction对查询性能的影响
在将大约450M行加载到CockroachDB后,我们立即运行YCSB Workload C,它只执行读查询。
$ ./bin/ycsb run jdbc -P db.properties -P workloadc -threads 128 -s
我们注意到,CockroachDB的吞吐量只有每秒8.5K的查询,并且延迟比预期的要高得多(p99延迟为每幅图800毫秒)。
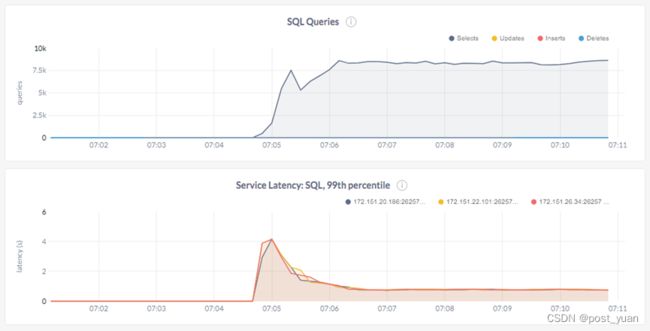
在分析了关于系统的一些事情之后,突出的事实是SSTable文件的数量在加载结束时激增到大约200K个文件。SSTable文件是由RocksDB创建的数据文件。由于CockroachDB重用RocksDB实现持久性,所以这些文件保存了各个表范围内的实际数据。

每个SSTable文件都是由RocksDB作为memstore flush进程的一部分创建的。一旦创建,这些SSTable文件是不可变的。这是像RocksDB这样的日志结构合并树(LSM)存储的基础。为了满足查询,RocksDB对一个或多个SSTable文件执行多次内部读取。为了满足表上的任何逻辑查询,这些内部读取的数量越多,性能就越差。满足逻辑查找的内部查询的数量称为读放大。
LSM数据库运行一个称为压缩的过程,在后台不断地将多个SSTable文件合并并替换为一个新的文件,从而减少读放大。除了紧凑性不断保持,读放大是通过使用一些额外的技术来减少。例如,bloom过滤器用于概率性地减少需要咨询的文件数量。
在CockroachDB中,由于SSTable文件的数量急剧增加,即使在数据加载完成后,也会导致性能下降,因为内部读放大会随着SSTable文件数量的增加而增加。下面的图表支持了这一结论。

解决这种情况的惟一方法是等待compaction赶上来,而系统没有任何负载。我们决定通过在系统上不运行任何工作负载来解决compaction问题。这花费了大约5-6个小时使集群保持空闲,而没有执行任何写入或更新。一旦进行了压缩,SSTable文件的数量就会减少,读取放大量也会像预期的那样下降。这种行为可以在下面的图表中看到。

然后,我们运行读工作负载,在吞吐量和延迟方面看到了更好的查询性能。集群能够完成将近40K的读取/秒。这个实验表明,CockroachDB的架构选择和缺乏及时的压缩对读取性能有巨大的负面影响。

YugabyteDB: 成功加载1B数据
相比之下,YSQL的1B行数据加载(使用范围分片表)在大约26小时内就成功完成。下图显示了加载阶段期间YCSB基准测试的范围分片加载阶段的吞吐量和平均延迟。

跨两个节点的总数据集为3.2TB。每个节点有超过1TB的数据。
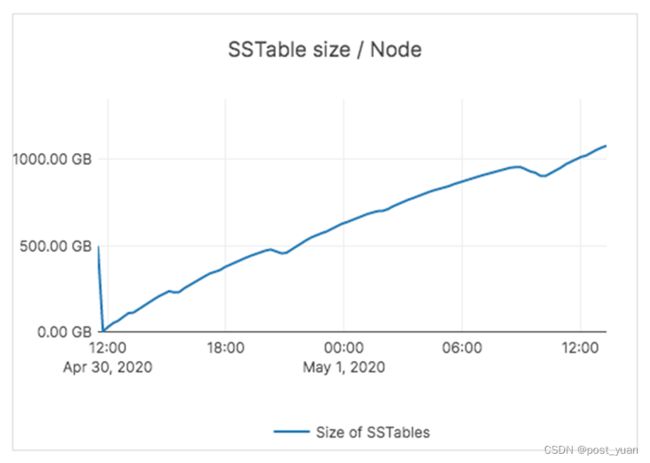
而YugabyteDB中的压缩能够与数据加载保持同步,从而保持较低的SSTable文件计数和读取放大。通过加载过程,YugabyteDB中sstable的数量如下所示。
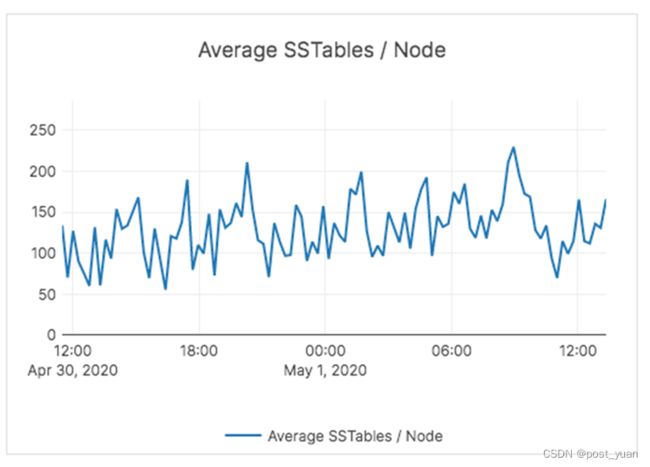
YugabyteDB使用多个基于大小的压缩队列进行了调优,以确保压缩与传入的写负载保持一致,并可以(在需要时)反压力摄取,以确保读操作的系统性能不会下降。

因此,即使在加载之后,YugabyteDB的读取性能也始终保持高水平,而无需等待数小时来完成压缩。
过载时反向压力用户请求
上面的场景还展示了通过对应用程序施加反压力来减慢写请求的重要性,从而使数据库始终能够以良好的性能为读请求提供服务。例如,在上面的场景中,随着数据逐渐加载,磁盘成为CockroachDB和YugabyteDB的瓶颈。CockroachDB无法限制写请求,这会影响读性能,集群必须闲置数小时才能恢复。相比之下,YugabyteDB的负载吞吐量图显示,数据库反复对加载器施加反压力,以确保读查询总是能够执行良好。下面的图表是在加载阶段捕获的,展示了实际情况。

32线程加载4.5亿行
由于我们无法在可接受的时间内将1B行加载到CockroachDB,所以我们决定减少需要加载的行数和线程数。由于在前一次运行中,CockroachDB可以在24小时内加载约4.5亿行,所以我们将其作为要加载的目标行数。这意味着加载后的总数据集大小约为1.35TB,而不是最初的3TB目标。
CockroachDB的数据加载在~25小时内完成。我们发现,随着数据负载的增加,它的总写吞吐量从12K insert /sec下降到3.5K write /sec(延迟也在稳步增加,但在这个数据负载场景中影响较小)。
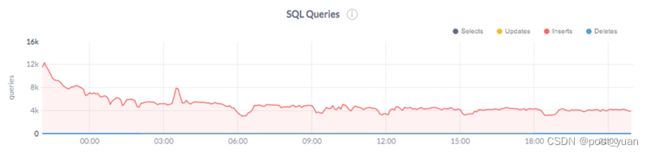
相比之下,将数据加载到哈希分片YugabyteDB表需要7个小时,每秒写18K次,平均延迟约为2ms。

此外,将数据加载到范围分片的YugabyteDB表需要大约9个小时,每秒14K操作,平均延迟2ms。
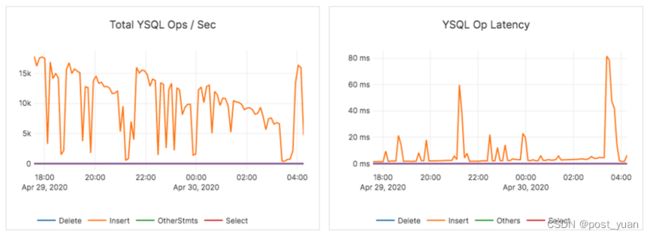
因此,即使在处理更大规模的数据集大小时,YugabyteDB也能够稳定地加载整个数据集。
详细YCSB结果
加载了450M行之后,我们就可以使用JDBC驱动程序运行标准的YCSB基准测试了。本节概述了在CockroachDB范围分片表(CockroachDB中的哈希分片表还没有稳定发布)和YugabyteDB范围和哈希分片表上运行基准测试的结果。
数据加载
当数据的规模增加到450M行时,YugabyteDB能够以大约3倍的速度加载数据。加载数据的时间如下表所示。

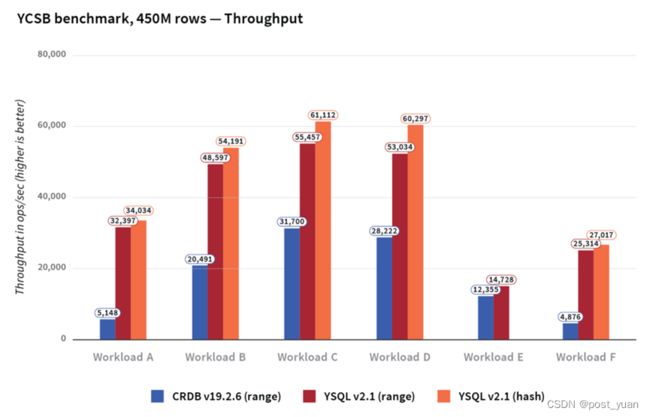
吞吐量
跨各种工作负载的吞吐量如下所示。YugabyteDB的吞吐量平均比CockroachDB高3倍,在所有YCSB工作负载中,无论是使用散列还是范围分片,它的吞吐量都优于CockroachDB。
延迟
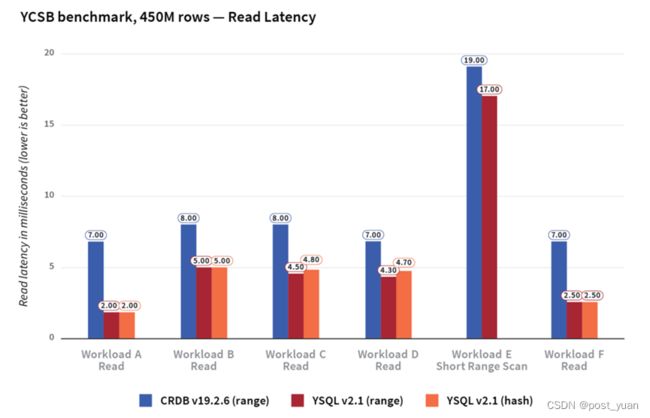
平均而言,与CockroachDB相比,YugabyteDB的写/更新延迟是前者的7倍,读延迟是后者的2倍。

各种更新操作的延迟如下图所示。
理解分布式SQL的性能
大数据集vs 小数据集
数据库的性能特征可能因数据集的大小而显著不同。这是因为当数据集增长时,许多体系结构因素都会发挥作用。在本节中,我们将使用YCSB基准测试来研究伸缩数据集对YugabyteDB和CockroachDB性能的影响。为了获得更小数据集大小的基线,我们在两个数据库中只有1M行的数据集上运行标准YCSB基准测试。下面的图比较了数据行为1M和450M时数据库的性能。
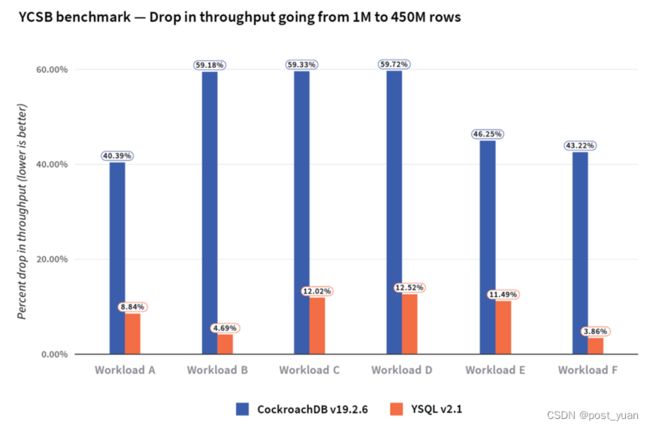
我们注意到,在所有的YCSB工作负载中,当行数从1M增加到450M时,CockroachDB吞吐量下降了51%,而在范围分片的YSQL表中,相应的下降仅为9%。下图总结了在两个db中,当行数从1M增加到450M时,不同YCSB工作负载的吞吐量下降情况。
我们还注意到,当CockroachDB从1M行增加到450M行时,它的更新延迟增加了180%,而YugabyteDB的更新延迟只增加了11%。
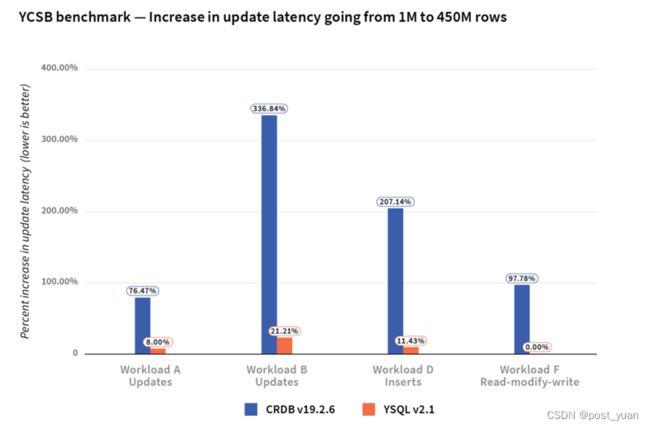
对于1M行和450M行,两个数据库之间的读延迟没有显著差异。
范围分区vs 哈希分区
正如前面提到的,YugabyteDB同时支持表的范围分片和哈希分片。Cockroach 实验室的分析声称,范围分片对于所有SQL工作负载都是非常优越的。那么,这两种类型的分片对性能的影响究竟是什么呢?我们使用这两种形式的分片,对450M行的YugabyteDB表运行YCSB基准测试。
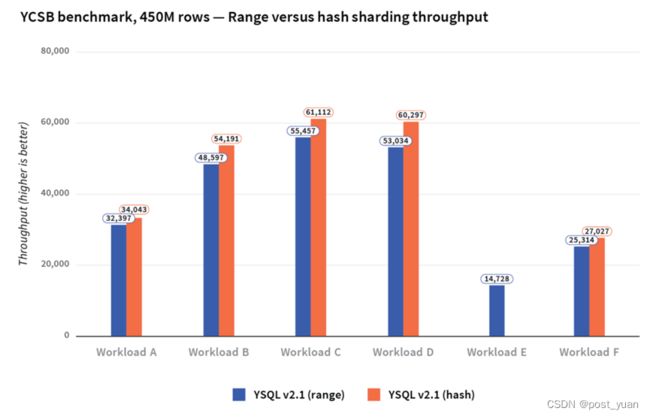
与范围分片相比,散列分片的数据加载时间要快得多。范围查询在哈希分片表中显然效率不高。对于所有其他YCSB工作负载,无论我们使用范围分片还是散列分片,对吞吐量和延迟的影响都是最小的。
YCSB基准测试的加载时间如下所示。请注意,在其他设置中,散列分片的写吞吐量比范围分片的性能要好得多。

下图比较了不同YCSB工作负载下散列和范围分片的吞吐量。
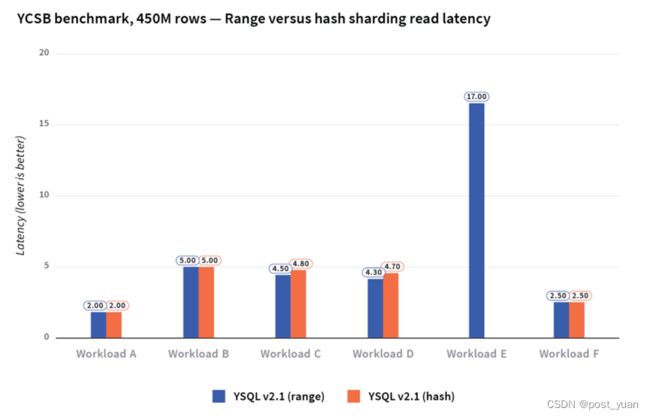
这些工作负载之间的读延迟如下所示。
结论
Cockroach Labs在许多方面对YugabyteDB的看法都是错误的,从而导致(用他们的话来说)“Yugabyte是一个移植到分布式KV数据库的单片SQL数据库”的错误结论。上面的分析说明了为什么YugabyteDB实际上是一个更强大的分布式SQL产品,尽管它比CockroachDB更新。
我们想借此机会强调一下,CockroachDB缺少了许多像Oracle/MySQL/PostgreSQL这样的系统的用户所熟悉的RDBMS的强大特性。虽然与PostgreSQL的连线兼容性是分布式SQL数据库的一个很好的起点,但要想赢得传统RDBMS用户的青睐,就需要显著的特性深度,而这正是YugabyteDB所提供的。此外,YugabyteDB以高性能作为其核心设计原则之一。YCQL API是底层DocDB存储层功能的一个示例。我们在每个版本中都对YSQL的性能进行了持续的改进,使其与YCQL的性能持平。