YugabyteDB对比CockroachDB-第一部分
注:本文翻译自YugabyteDB官网文章 https://blog.yugabyte.com/yugabytedb-vs-cockroachdb-bringing-truth-to-performance-benchmark-claims-part-1/
介绍
在Yugabyte,我们欢迎竞争和批评。我们相信这些方面对于广泛采用像YugabyteDB这样的业务关键、完全开源的项目是至关重要的。具体来说,建设性的批评有助于我们改进项目,使我们的大型用户社区受益。蟑螂实验室的工程师几个月前发布了他们对蟑螂数据库与YugabyteDB的对比分析。我们感谢他们花时间这样做。不幸的是,他们对YugabyteDB设计的理解存在一些事实性错误,这导致了他们对它的误解。我们想借此机会澄清这些误解。
我们相信,任何想要了解开源数据库内部工作原理的人都应该能够这样做,不管他们是用户、数据库爱好者,甚至是竞争对手。因此,我们花时间写了以下关于YugabyteDB的架构和设计的附加内容。
为什么我们要通过重用PostgreSQL查询层来构建YugabyteDB
YugabyteDB在PostgreSQL上做了5个查询下推
我们在构建YugabyteDB之前分析了4种分片策略
YugabyteDB v2.1中的性能增强
YugabyteDB自动分片系统的设计
概要
- YugabyteDB并不是一个“移植到分布式KV数据库上的单一SQL数据库”。它是一个功能全面、符合ACID的分布式SQL数据库,不仅水平扩展写操作和自修复失败,而且还通过“代码传递”(又称下推)执行分布式查询。这篇文章引用了重用PostgreSQL的查询层作为这个不准确声明的基础。事实上,这种重用是一种架构上的优势,它允许YugabyteDB支持高级RDBMS特性,而这些特性在CockroachDB中是没有的。
- Yugabyte SQL (YSQL)支持范围分片以及将一个范围预分割为多个分片(又称tablets)的能力。但是,默认选项是哈希分片(而不是范围分片),这样SQL工作负载就可以立即受益于水平扩展。此外,tablets的数量和单个tablet的尺寸都没有限制。当大型tablet需要额外的处理能力时,可以使用手动拆分tablet。动态劈片是一项正在进行的工作。
- 与声称的相反,YSQL以显式行级锁的形式支持悲观锁。这些锁的语义与PostgreSQL非常匹配。
- YugabyteDB在Yugabyte Cloud QL (YCQL) API的背景下提供了在线索引重建和模式更改。YSQL API的这些特性还在开发中。
- 使用YugabyteDB v2.1, YSQL在YCSB基准测试中优于CockroachDB v19.2,特别是当每个节点存储的数据量增长到tb时。此外,2.1版本还对行业标准基准(如pgbench、sysbench和TPC-C)进行了显著的性能改进。
澄清事实
分布式SQL vs 单片SQL
蟑螂实验室发布了一个错误的声明,称YugabyteDB使用了一个单一的SQL架构(这意味着“代码传递”无法完成)。蟑螂实验室帖子摘录:
我们发现了CockroachDB的分布式SQL执行和Yugabyte的SQL执行的不同之处,前者分解SQL查询以便在接近数据的地方运行,后者将数据移动到网关节点进行集中处理。
...
与其说Yugabyte是分布式SQL数据库,不如说Yugabyte是分布式KV数据库之上的单片SQL数据库。
...
CockroachDB提供了“代码传递”而不是“数据传递”架构。这在分布式体系结构中是至关重要的。
我们Yugabyte的许多人都曾从事过Oracle、Apache Cassandra和Apache HBase等多种流行数据库的内部工作,我们为自己对架构选择的认真考虑感到自豪。我们很清楚,将查询处理移动到更接近数据的位置,可以限制分布式系统中跨节点传输的数据量。
“代码传递”到存储层实际上是YugabyteDB的一个基本特性。我们最近的一篇文章讨论了YugabyteDB通过修改PostgreSQL的执行计划来实现的一些问题。这篇文章涵盖了以下几种类型的下推:
单行操作,如INSERT, UPDATE, DELETE
批处理操作,如COPY FROM, INSERT数组的值和嵌套查询
使用索引谓词时有效地过滤
表达式以及他们是如何被推下去的
对索引组织表的各种优化,如谓词下推、排序消除、处理LIMIT和OFFSET子句
因此,YugabyteDB不仅继承了PostgreSQL的查询处理和所有层的优化,它还拥有一个健壮的框架来实现额外的分布式SQL优化。请注意,执行这些额外的下推来支持更广泛的查询数组表示一个连续的工作。任何数据库都是这样——CockroachDB和YugabyteDB也不例外。
哈希分区vs范围分区
现在,让我们转向散列与范围分片的辩论。再次引用CockroachDB的博客:
默认的散列分区是一个可疑的选择,因为它不同于PostgreSQL默认的SQL表和正常的期望。许多NoSQL系统使用散列分区,这是在此类系统上实现完整SQL困难的主要因素。
选择分布式SQL数据库的主要原因之一是水平写可伸缩性,其中跨节点的数据分布是一个基本问题。跨节点分布数据的方案称为分片(也称为水平分区)。
在单节点PostgreSQL数据库中,由于水平可伸缩性不受关注,因此跨节点分布的分片数据的概念是不相关的。因此,除了范围排序(本质上是只有一个分片的范围分片)之外,以任何形式存储数据都是不必要的。我们关于分片策略的博文解释了我们的决策过程,并强调了为什么YugabyteDB默认支持哈希分片和范围分片。考虑到在分布式SQL数据库中交付水平可伸缩性的基本需求,我们坚信我们做出了正确的选择。此外,我们相信,在现实世界中,有许多应用程序不需要范围分片表,使用散列分片表可以更好地伸缩。行业标准TPC-C基准测试就是一个很好的例子。
下一个值得关注的问题是,在负载平衡和热点缓解的背景下,每个分片策略的有效性。他们的博客文章如下所示。
负载平衡和负载热点是分布式系统中相当常见的问题。即使分布式系统在理论上可以水平扩展,开发人员仍然需要小心地以可分布的方式访问它们。在范围分区系统中,如果只关注特定范围的数据,负载可能会变得不平衡。在一个散列分区系统中,如果由于散列冲突而集中在一个特定的散列桶上,负载可能会变得不平衡。
...
这(向顺序键写入工作负载)在CockroachDB中被认为是一种反模式,这也是我们建议在文档中避免这种访问模式的原因。
鉴于YugabyteDB对哈希分片的本地支持,流行的顺序键插入工作负载当然不是反模式。在我们看来,声称只使用范围分片来构建一个大规模可伸缩的数据库,而让用户来实现哈希分片,并将其合理化为PostgreSQL的默认行为(不能水平扩展),这是一个更可疑的选择。[更新:虽然我们还没有查看细节,但看起来CockroachDB将在其下一个主要版本中添加对哈希分片索引的支持。]这肯定了他们对我们关于散列分片对于分布式SQL数据库至关重要的观点的认可。
带有悲观锁的分布式事务
CockroachDB的博客文章陈述如下:
DocDB事务的功能和限制直接向SQL公开。例如,DocDB事务没有为读或写操作提供悲观锁。如果两个事务冲突,其中一个将被终止。这种行为类似于原始的CockroachDB事务支持。
...
除了性能之外,在冲突期间中止一个事务还需要应用程序在其应用程序代码中添加重试循环。CockroachDB现在具有悲观锁定机制,以提高争用下的性能,并减少用户可见的事务重启。
YugabyteDB中的分布式事务在设计时考虑到了可扩展性。DocDB事务层同时支持乐观锁和悲观锁。当YugabyteDB中的两个事务发生冲突时,优先级低的事务被终止。悲观锁是通过查询层为在悲观并发控制下运行的事务的优先级分配一个非常高的值来实现的。这使得当前事务优先于其他冲突事务。
YugabyteDB选择了乐观并发控制,以支持并发事务的高吞吐量。在竞争激烈的情况下,YugabyteDB建议使用带有显式行锁的悲观并发控制。这些事务处理功能允许YugabyteDB支持大多数PostgreSQL支持的悲观行级锁定特性,包括:
FOR UPDATE
FOR NO KEY UPDATE
FOR SHARE
在线修改schema
Cockroach Labs的博客文章指出,模式更改在各个节点之间并不协调。所使用的示例是在具有现有数据并运行并发操作的表上重新构建索引。从YCQL API的YugabyteDB 2.1版本开始,以安全、分布式的方式重建索引的特性就已经可用了。这个特性正在为YSQL API进行积极的开发。我们承认在YugabyteDB v2.0中还没有这个功能,在他们撰写这篇文章的时候,这个版本已经发布了。他们写道:
我们创建了一个表,添加了一些数据,然后添加了一个索引。在添加索引时,我们并发地插入另一个节点上的表。最终的结果是索引与主表数据不同步。
虽然观察到的行为是正确的,但这个问题与YugabyteDB对PostgreSQL查询层的重用无关。相反,它源于这样一个事实:当时不支持在已经有数据的表上回填索引。
另一个被指出的问题是目录不匹配错误的存在。当节点确定它拥有过时的模式版本时,就会发生这种情况。作为一个记录系统,YugabyteDB将安全放在首位。目前,这些目录版本不匹配错误出现在比理想情况更多的场景中。也就是说,用于索引重建的相同框架也适合以安全的方式执行其他在线模式更改,而不会导致虚假错误。由于在线模式更改而遇到的目录版本不匹配错误,将由这个框架逐步解决。
总的来说,我们在YugabyteDB中在这方面做了很多改进,表明这个架构没有什么基础,这些问题很容易解决。
Tablets和分裂
关于碎片(也就是tablets)在YugabyteDB中的工作方式有一些错误的信息。在这一节中,我们将把事情弄清楚。他们写道:
我们发现Yugabyte SQL表最多有50个tablets。
YugabyteDB表对tablet的数量没有任何硬性限制。例如,在我们实现每秒100万次并发插入的基准中,一个表被分割成分布在100个节点集群上的2000个tablet。此外,多个用户在生产环境中运行YugabyteDB,每个集群有数千台tablet。所以,这种说法是完全不准确的。此外,tablet的尺寸也没有限制。
我们发现Yugabyte范围分区表仅限于一台tablet,这限制了此类表的性能和可伸缩性。
在YugabyteDB中,将一个范围分片表拆分到多个tablet的功能在撰写上述博客时正在进行。YugabyteDB现在支持将哈希分片表和范围分片表拆分到多个tablet上。他们写道:
我们发现Yugabyte tablet不会进行拆分或合并,这就要求运营商在他们的数据模式上提前做出重要的决定。
YugabyteDB表默认是哈希分区的。每个表被预先划分为集群中每个节点可配置的tablet数量,默认为每个节点8个tablet。例如,默认情况下,10个节点的集群将从80个tablet开始(每个节点8个tablet*集群中的10个节点)。这减少了执行昂贵的拆分操作的需要。我们同意在初始表创建后分割一个tablet是处理大型tablet的一个基本特性。目前,可以手动拆分大的tablet,而完全动态拆分目前正在进行中。
性能和基准
YugabyteDB提供了两个分布式SQL api——YSQL(与PostgreSQL线兼容的全关系型)和YCQL(与Apache Cassandra QL根兼容的半关系型云查询语言)。虽然YCQL已经是一个成熟的高性能API,但YSQL API的性能自去年普遍可用以来一直在稳步提高。YSQL最新运行的行业标准基准,如YCSB和sysbench显示了显著的改进。我们也在开发我们自己的严格遵守基准规范的TPC-C基准客户机。考虑到YSQL和YCQL引擎都运行在相同的DocDB存储层上,我们希望YSQL的性能能在较短的时间内与YCQL的性能接近。下面是我们所做的一些性能改进以及观察到的结果。
注意,下面的所有结果都可以通过YCSB基准测试、sysbench基准测试和TPCC基准测试的这些说明得到。
YCSB –Yugabyte SQL优于CockroachDB
如下图所示,YSQL v2.1在6个YCSB工作负载中有5个工作负载优于CockroachDB;YCQL v2.1在所有工作负载下都显著优于CockroachDB。YugabyteDB在一个包含三个AWS节点的集群上进行基准测试(每个节点都是一个c5.4 ×大的实例,带有16个vcpu)。下面的图表显示了CockroachDB在他们的博客文章中报告的数字(这是在一个等效的机器类型c5d上执行的。4 *大,也有16个vcpu)以及YugabyteDB数字。

注意,对于上面的结果,我们使用了新的yugabyteSQL、yugabyteSQL2Keys(仅用于工作负载E)和yugabyteCQL YCSB绑定,它们在YugabyteDB上高效地为工作负载建模。注意:使用2列键的yugabyteSQL2Keys绑定更好地模拟了Workload E,其中第一列标识线程,第二列标识线程内的post。要深入比较使用标准YCSB绑定的两个数据库,请参阅本系列的下一篇文章。
那么,为什么YSQL的数字在2.0和2.1之间急剧上升呢?性能改进可归因于以下两个更改。
单列更新下推
在v2.0中,YSQL没有将单行更新下推到DocDB存储层。因此,这些更新不必要地使用较慢的分布式事务执行路径,这需要来自查询协调器的多个RPC调用。这增加了事务冲突的可能性,从而导致更多的重试。YugabyteDB v2.1增加了单行更新的下推,这导致使用一个优化的快速路径的事务只发生一个RPC调用,从而更好的性能。
细粒度的列级锁定
YSQL v2.0将获得一个独占行锁,即使在更新涉及到一个列子集的情况下也是如此。这种方法会导致更多的事务冲突,因为锁的粒度比必要的粗。更理想的策略是获取行上的共享锁,只对需要更新的列进行独占锁。虽然这个特性已经被DocDB支持,因为它的使用模式与YCQL API类似,但它直到v2.1才被连接到YSQL API。
sysbench
在YCSB中看到了显著的改进之后,我们自然希望在sysbench结果中也看到类似的改进。但是,我们发现sysbench数据加载比预期的慢得多。我们决定进一步调查这个问题。
数据加载
我们首先检查sysbench创建的表的模式。
CREATE TABLE sbtest1 (
id SERIAL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY id);
注意,上面的表使用SERIAL数据类型作为主键。在YugabyteDB中的SERIAL数据类型严格遵循PostgreSQL的SERIAL语义,它需要在每次插入时为id列获取一个新的、单调递增的值。这导致每一个插入操作都会产生额外的RPC调用,导致加载阶段非常缓慢。
在CockroachDB中,SERIAL类型是一种伪数据类型,其语义与PostgreSQL完全不同,它不使用递增计数器,而是从当前时间戳和节点id生成一个唯一的数字(使用unique_rowid()调用)。下面突出显示了来自CockroachDB文档的相关代码片段。虽然使用随机数的技术不会引起额外的RPC调用,从而导致明显的加速,但它破坏了PostgreSQL的语义。依赖于此行为的应用程序可能会以微妙的方式失败。以下是上述CockroachDB文档页面的摘录:
正确的苹果到苹果的比较应该在PostgreSQL串行语义下运行。对于CockroachDB,可以通过设置以下会话变量来实现,这只是一个实验特性。
SET experimental_serial_normalization=sql_sequence
sysbench的加载时间如下所示。两个数据库的缓存值都设置为1,以便强制两个数据库为序列生成单个新值。
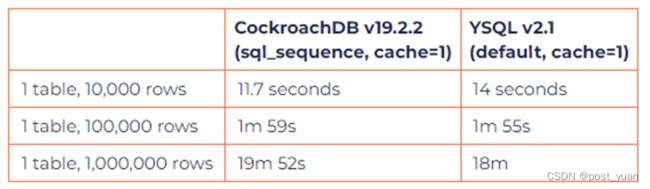
从上表可以明显看出,在这种配置下,两个数据库的表现都不太好。换句话说,当CockroachDB配置为使用每次插入都发出一个SERIAL值的相同方案时,观察到的性能几乎与YugabyteDB相同。
在不破坏PostgreSQL语义的情况下加速YSQL
CockroachDB通过使用伪数据类型加速sysbench加载阶段,就像我们之前看到的那样。加速YugabyteDB的加载阶段可以通过以下两种方式之一来实现,而不会牺牲PostgreSQL的语义。
运行auto_inc=false的sysbench。这个标志导致sysbench为id列生成随机值,完全消除了额外的RPC调用。
为SERIAL发出一批值。可以更改YugabyteDB来为id列请求一批值,而不是一次一个。这可以通过执行与PostgreSQL相同的操作来完成。例如,每个RPC调用发出1000个值可以通过在创建表之后运行以下命令来完成:
ALTER SEQUENCE sbtest1_id_seq CACHE 1000
上述两种技术所带来的性能增益是相同的。现在,让我们看看上述更改对性能的影响。下表还展示了YSQL 2.0的性能,以供参考。请注意,与前一个版本相比,YSQL v2.1中有许多性能改进,比如可以有效地加载一批插入。改进YSQL性能也是下一个主要版本的工作领域之一。
运行sysbench工作负载
与v2.0不同,YSQL v2.1成功地运行了所有sysbench工作负载。sysbench工作负载包含范围查询作为主要模式,因此需要在YugabyteDB中使用范围分片。首先,我们创建了一个预先分割的范围分片表,如下所示。
CREATE TABLE sbtest1 (
id SERIAL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id ASC))
SPLIT AT VALUES ((41666),(83333),(125000), ... ,(958333));
对于下面所示的基准测试结果,我们将100K行加载到上面sysbench创建的10个表中,并使用64个并发线程运行基准测试。下面是基于上面创建的表的吞吐量结果。虽然下面的结果反映了当前的状态,但仍有持续的工作来进一步改进性能。
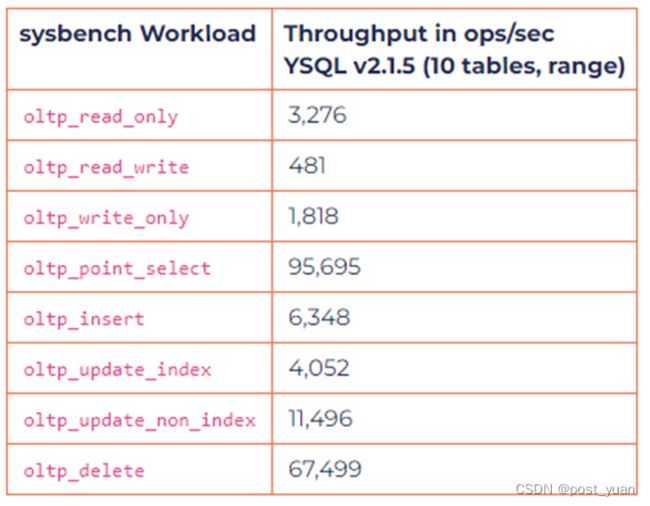
TPC-C
虽然YSQL v2.0几乎不能运行TPC-C工作负载,但我们很高兴地报告,2.1版本可以很好地运行TPC-C。我们还没有确定一个精确地遵循官方规范的官方TPC-C基准实现,因此还没有可以报告的官方tpc编号。为YugabyteDB开发TPC-C基准的工作正在顺利进行,初步结果看起来很有希望。期待很快看到关于我们TPC-C结果的后续博客文章。
结论
基于对竞争项目的不完全理解而做出错误的声明是很容易的。艰难的道路需要理性地分析体系结构决策,并强调对最终用户的影响。我们一直致力于沿着这条艰难的道路走下去,因为我们在过去几年里构建了YugabyteDB。对蟑螂实验室毫无根据的声明做出回应也不例外。在这篇文章中,我们不仅强调了他们分析中的事实错误,而且还用可验证的行业标准基准展示了YugabyteDB的真实表现。我们建议您阅读本博客系列的第2部分,其中我们提供了YugabyteDB架构背后的下一层细节,重点是将其与CockroachDB进行比较。