Kafka3.x笔记






1.本地环境搭建
--条件有限,暂时单服务器模拟集群情况
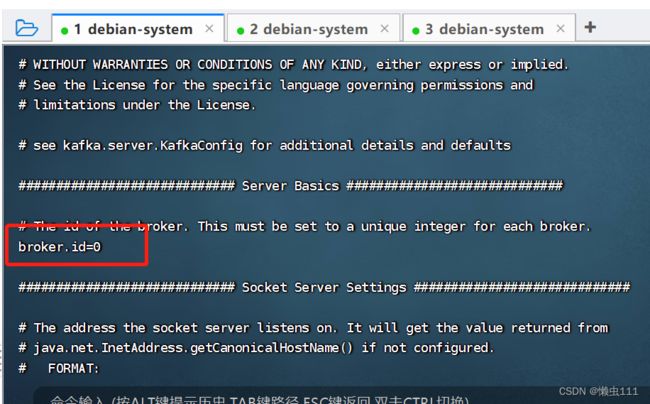
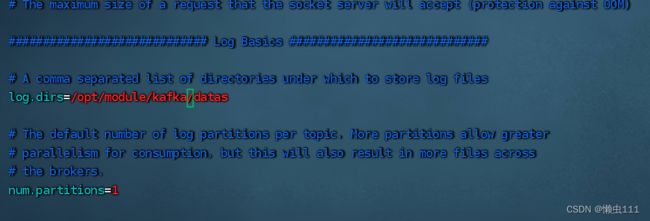

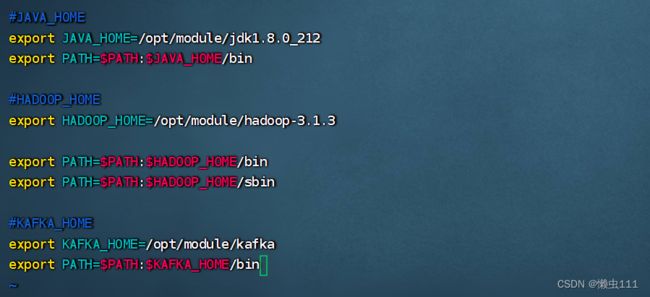
cd/etc/profile.d/my_env.sh
zookeeper集群启动
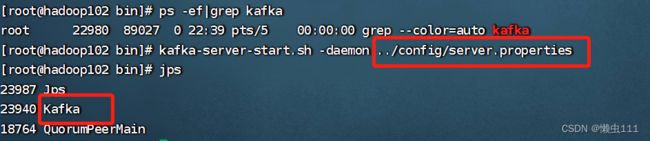
kafka集群启动
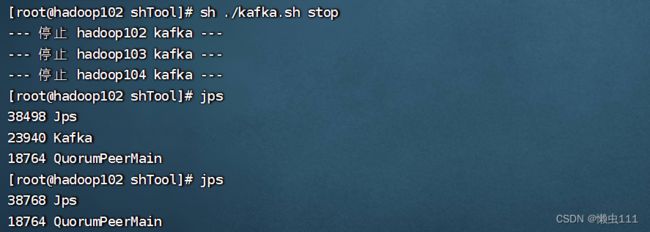
编写kafka.sh 集群操作脚本(先关闭kafka,再关闭zookeeper)
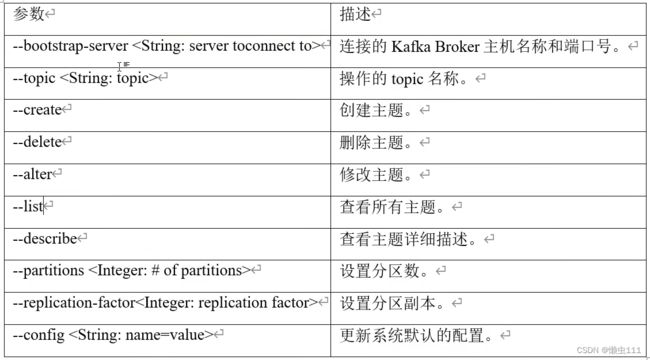
2.kafka 命令行操作
2.1主题命令行操作
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --topic first --create --partitions 1 --replication-factor 3
Created topic first.
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
first
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --topic first --describe
Topic: first TopicId: v3lrR_ESRIuzo-QY5Ke7Dg PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --topic first --alter --partitions 3
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --topic first --describe
Topic: first TopicId: v3lrR_ESRIuzo-QY5Ke7Dg PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: first Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: first Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
生产者连接上集群,发送消息
[root@hadoop102 kafka]# bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
>hello
>atguigu
>hello
>
消费者连接集群,消费即时消息(从头获取添加--from-beginning)
[root@hadoop103 kafka]# bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
atguigu
hello
^CProcessed a total of 2 messages
[root@hadoop103 kafka]# bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --from-beginning
hello
hello
atguigu
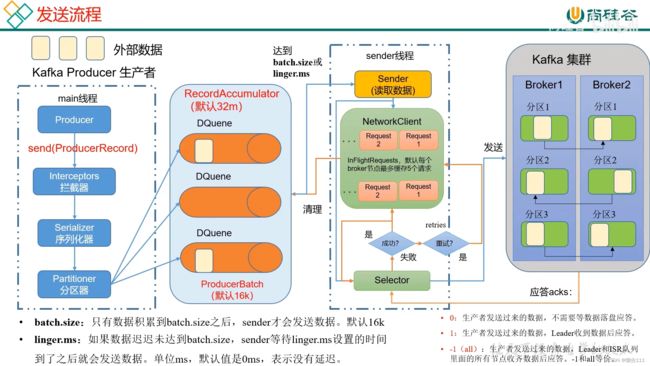
3. KafKa生产者
3.1发送流程
3.2 异步发送API
3.2.1 普通异步发送
public static void main(String[] args){
//0 配置
Properties properties = new Properties();
//配置连接集群信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
//指定对应的key和value的序列化类型 key.serializer:org.apache.kafka.common.serialization.StringSerializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 1.创建kafka生产者对象
// "" hello
KafkaProducer producer = new KafkaProducer(properties);
// 2.发送数据
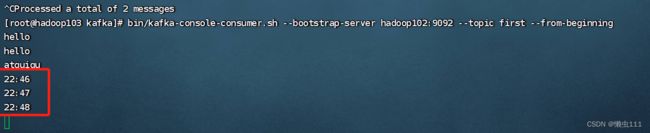
producer.send(new ProducerRecord("first","22:46"));
producer.send(new ProducerRecord("first","22:47"));
producer.send(new ProducerRecord("first","22:48"));
// 3.关闭资源
producer.close();
} 
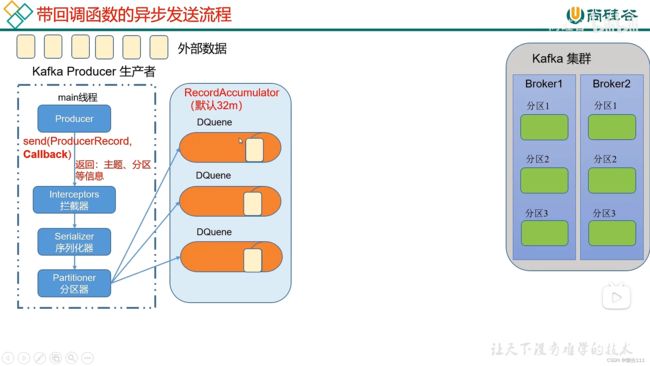
3.2.2 带回调函数的异步发送流程
public static void main(String[] args){
//0 配置
Properties properties = new Properties();
//配置连接集群信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
//指定对应的key和value的序列化类型 key.serializer:org.apache.kafka.common.serialization.StringSerializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 1.创建kafka生产者对象
// "" hello
KafkaProducer producer = new KafkaProducer(properties);
// 2.发送数据
producer.send(new ProducerRecord("first", "22:46"), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("主题: "+metadata.topic()+" 分区: "+metadata.partition());
}
}
});
// 3.关闭资源
producer.close();
} 
3.3 同步发送API
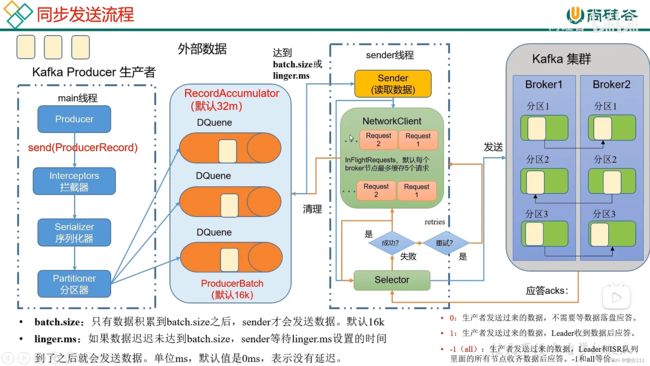
public static void main(String[] args) throws ExecutionException, InterruptedException {
//0 配置
Properties properties = new Properties();
//配置连接集群信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
//指定对应的key和value的序列化类型 key.serializer:org.apache.kafka.common.serialization.StringSerializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 1.创建kafka生产者对象
// "" hello
KafkaProducer producer = new KafkaProducer(properties);
// 2.发送数据(同步)
producer.send(new ProducerRecord("first", "22:46")).get();
// 3.关闭资源
producer.close();
} 3.4 生产者分区
3.4.1 分区好处

3.4.2 生产者发送消息的分区策略

3.4.3 自定义分区

public class MyPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取数据 atguigu hello
String msgValues = value.toString();
int partition;
if(msgValues.contains("atguigu")){
partition=0;
}else{
partition=1;
}
return partition;
}
public void close() {
}
public void configure(Map configs) {
}
} 
3.5 生产经验--生产者如何提高吞吐量
public class CustomerProducerParameters {
public static void main(String[] args){
//0 配置信息
Properties properties = new Properties();
//连接kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
//序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
//批次大小 16k
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
//linger;ms 等待时间,默认 0
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);
//缓冲区大小 32m
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//compression.type: 压缩,默认: none ,可配置值 gzip/snappy/lz4/zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
//1 创建生产者
KafkaProducer kafkaProducer = new KafkaProducer(properties);
//2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord("first","atguigu"+i));
}
//关闭资源
kafkaProducer.close();
}
} 
3.6 生产经验-数据可靠性
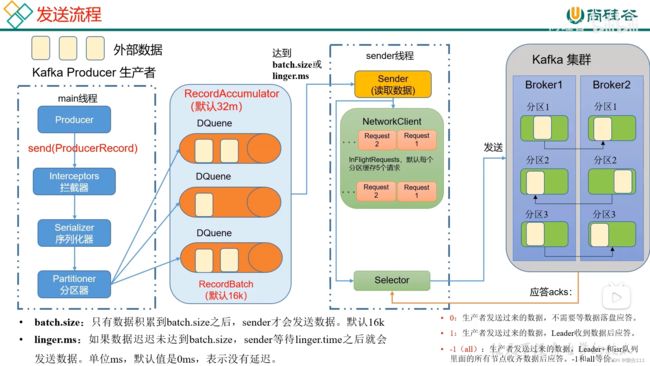
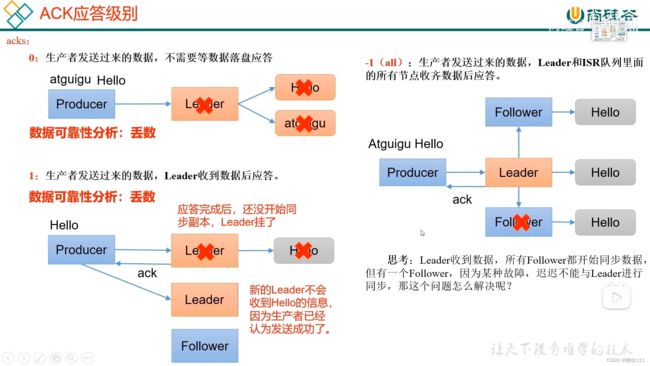
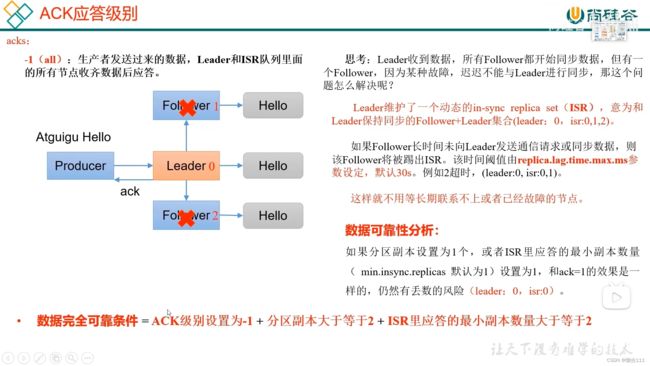

3.7 生产经验-数据重复

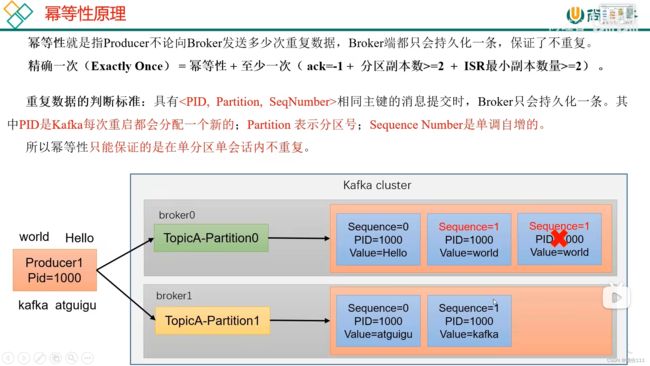

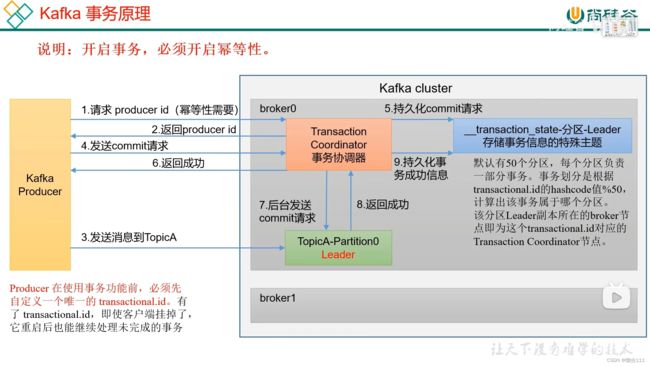
3.7.3 生产者事务
3.8 生产经验-数据有序

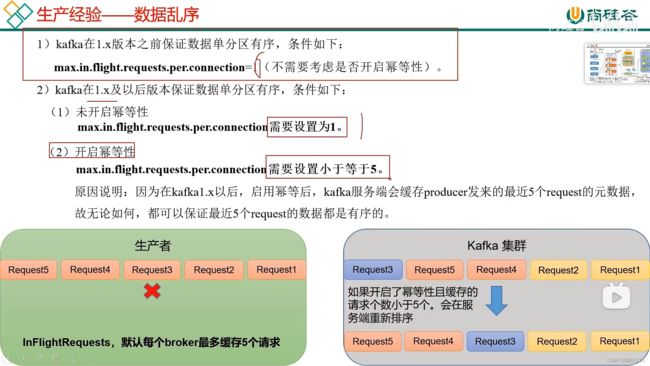
3.9 生产经验-数据乱序
第四章 Kafka Broker
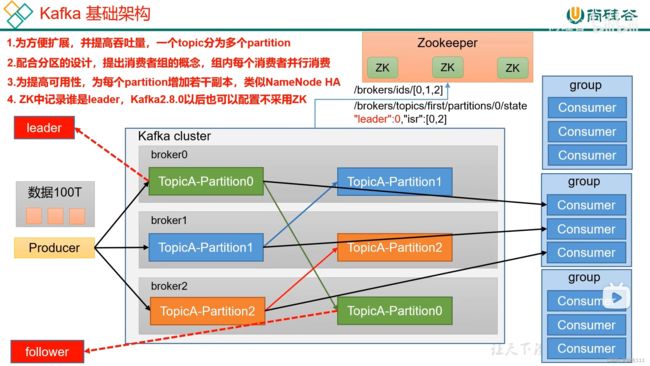
4.1 kafka broker工作流程
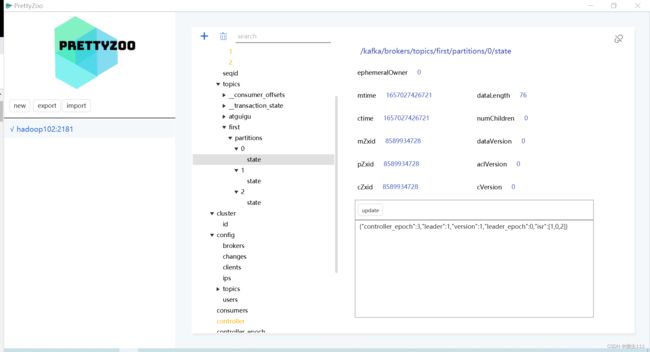
4.1.1 zookeeper存储的kafka信息

PrettyZoo-高颜值的zookeeper可视化工具_张俊杰1994的博客-CSDN博客_prettyzoo使用
4.1.2 kafka Broker总体工作流程

4.2 生产经验--节点服役和退役
退役: 生成负载均衡计划,并执行,更新当前指定topic的数据到其他节点,执行完成状态后,即可删除节点(退役),服役反之一样

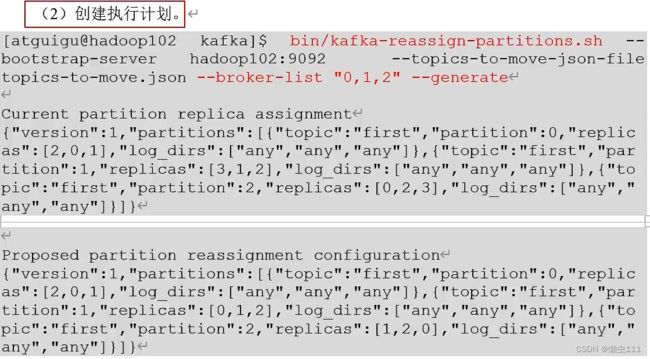
4.3 Kafka副本
4.3.1 副本基本信息

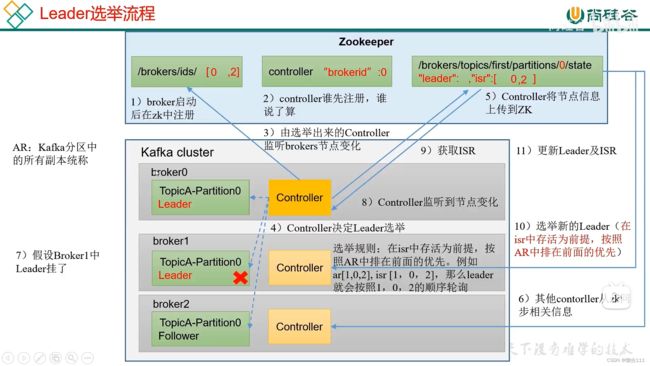
新建一个topic,测试将leader关闭后,follower上位的情形:
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic atguigu2 --partitions 3 --replication-factor 3
Created topic atguigu2.
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu2
Topic: atguigu2 TopicId: vErSSslGStqOC79XJ_BrqQ PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: atguigu2 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: atguigu2 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: atguigu2 Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0


重启后:

默认:ar(Replicas)第一个+isr存活
4.3.3 Leader和Follower故障处理细节


4.3.4 分区副本分配

错位分布,尽可能保证负载均衡
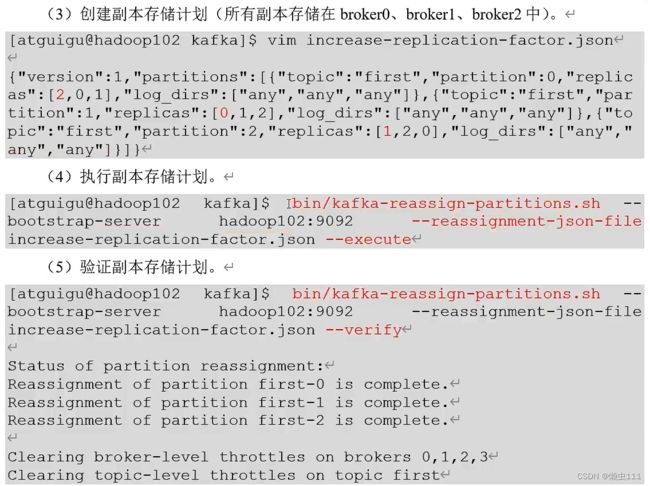
4.3.5 生产经验--手动调整分区副本存储

kafka目录下创建json文件:
vim increase-replication-factor.json
{
"version":1,
"partitions":[
{
"topic":"atguigu3",
"partition":0,
"replicas":[0,1]
},
{
"topic":"atguigu3",
"partition":1,
"replicas":[1,0]
},
{
"topic":"atguigu3",
"partition":2,
"replicas":[0,1]
},
]
}
[root@hadoop102 kafka]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"atguigu3","partition":0,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"atguigu3","partition":1,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"atguigu3","partition":2,"replicas":[1,2],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for atguigu3-0,atguigu3-1,atguigu3-2
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu3
Topic: atguigu3 TopicId: gu4hOjsnRoyzwX1sxJPnTg PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: atguigu3 Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: atguigu3 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 0,1
Topic: atguigu3 Partition: 2 Leader: 1 Replicas: 0,1 Isr: 1,0
[root@hadoop102 kafka]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition atguigu3-0 is complete.
Reassignment of partition atguigu3-1 is complete.
Reassignment of partition atguigu3-2 is complete.
Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic atguigu3
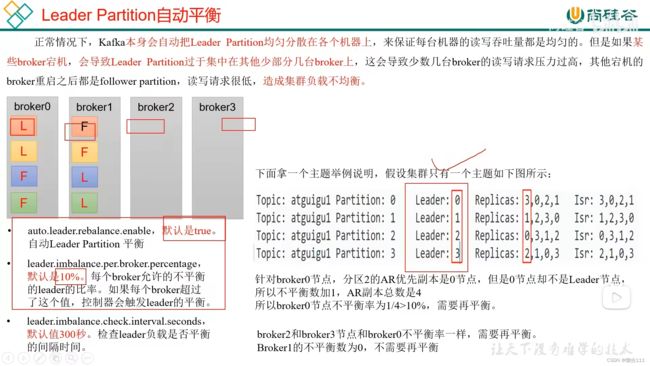
4.3.6 生产经验--Leader Partition 负载均衡
4.3.7 生产经验--增加副本因子
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic atguigu3 --partitions 3 --replication-factor 1
Created topic atguigu3.
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu3Topic: atguigu3 TopicId: i-ghyHlvRV-Q0u9vTlh_9w PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: atguigu3 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: atguigu3 Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: atguigu3 Partition: 2 Leader: 1 Replicas: 1 Isr: 1
[root@hadoop102 kafka]# vim increase-replication-factor.json
[root@hadoop102 kafka]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"atguigu3","partition":0,"replicas":[0],"log_dirs":["any"]},{"topic":"atguigu3","partition":1,"replicas":[2],"log_dirs":["any"]},{"topic":"atguigu3","partition":2,"replicas":[1],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for atguigu3-0,atguigu3-1,atguigu3-2
[root@hadoop102 kafka]# bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition atguigu3-0 is complete.
Reassignment of partition atguigu3-1 is complete.
Reassignment of partition atguigu3-2 is complete.
Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic atguigu3
[root@hadoop102 kafka]# bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu3
Topic: atguigu3 TopicId: i-ghyHlvRV-Q0u9vTlh_9w PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: atguigu3 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: atguigu3 Partition: 1 Leader: 2 Replicas: 1,0,2 Isr: 2,1,0
Topic: atguigu3 Partition: 2 Leader: 1 Replicas: 2,0,1 Isr: 1,2,0
[root@hadoop102 kafka]# cat increase-replication-factor.json
{
"version":1,
"partitions":[
{
"topic":"atguigu3",
"partition":0,
"replicas":[0,1,2]
},
{
"topic":"atguigu3",
"partition":1,
"replicas":[1,0,2]
},
{
"topic":"atguigu3",
"partition":2,
"replicas":[2,0,1]
}
]
}
4.4 文件存储
4.4.1 文件存储机制

kafka存储索引数据(稀疏索引4kb),按照相对offset,去log文件中定位数据
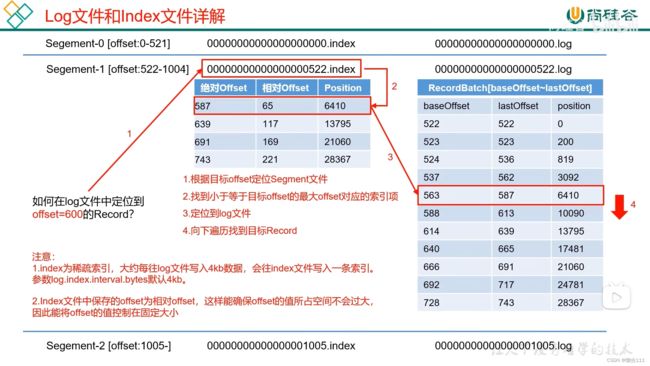
4.4.2文件清理策略


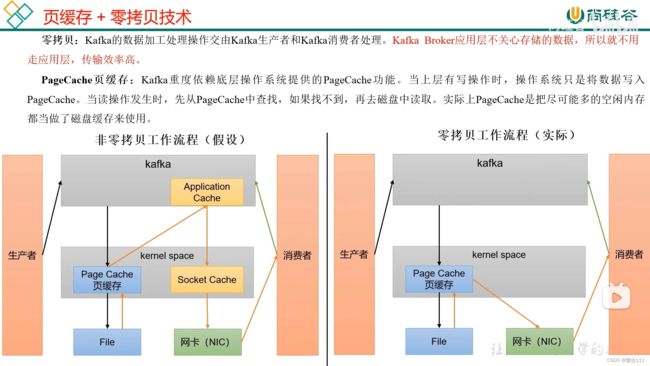
4.5 高效读写数据(重要)

4) 页缓存和零拷贝技术
第5章 Kafka消费者(重点)
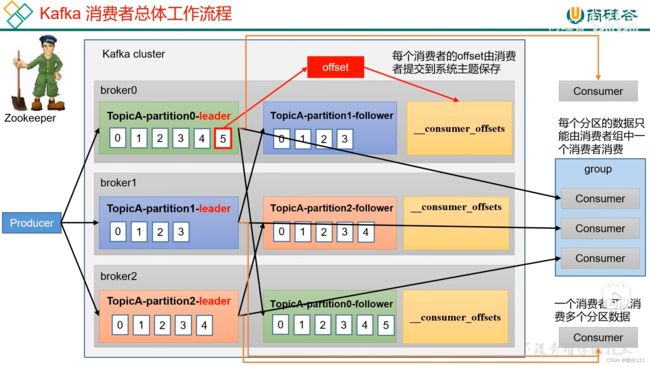
5.1 Kafka消费方式

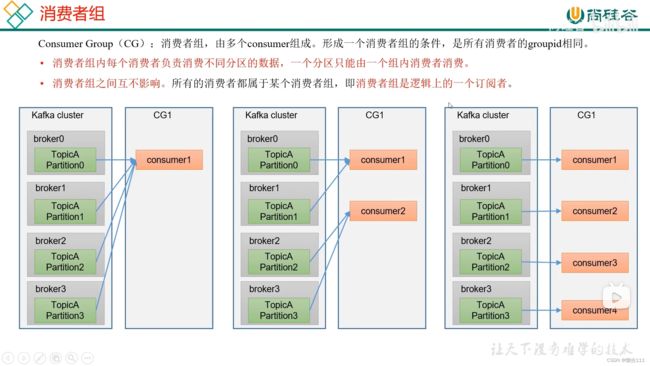
5.2 消费者组原理

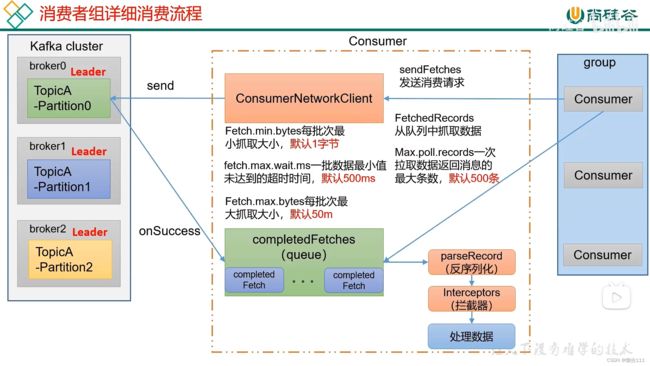
5.3 消费者API
5.3.1 独立消费者案例(订阅主题)

public class CustomConsumer {
public static void main(String[] args){
//配置
Properties properties = new Properties();
//连接的kafka集群信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
//反序列化方式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//配置groupid
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//创建一个消费者
KafkaConsumer consumer = new KafkaConsumer(properties);
//定义主题
consumer.subscribe(Arrays.asList("first"));
//消费数组
while(true){
ConsumerRecords records = consumer.poll(Duration.ofSeconds(1));
for(ConsumerRecord record:records){
System.out.println(record);
}
}
}
} 

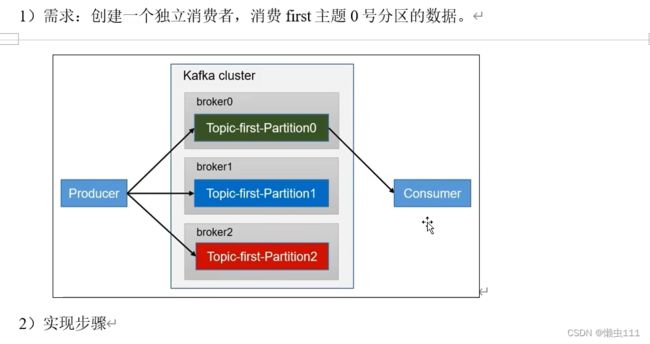
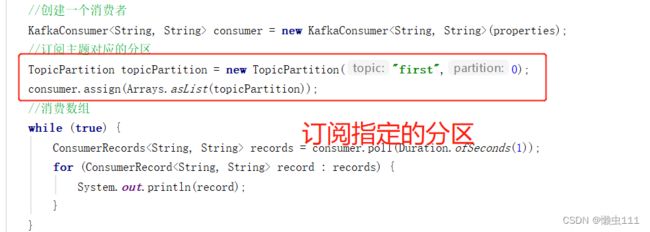
5.3.2 独立消费者案例(单一消费者消费指定分区)

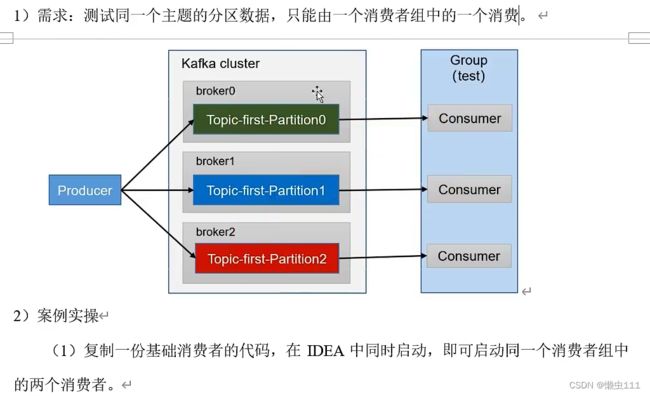
5.3.3 消费者组案例
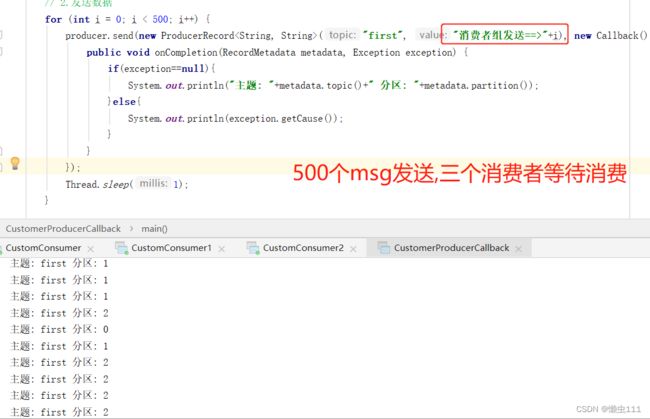
![]()

![]()
5.4 生产经验-分区的分配以及再平衡(分区数>=消费者数,否则消费者溢出不处理)
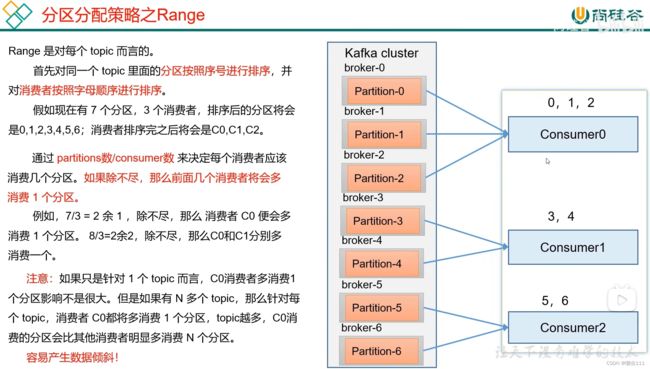
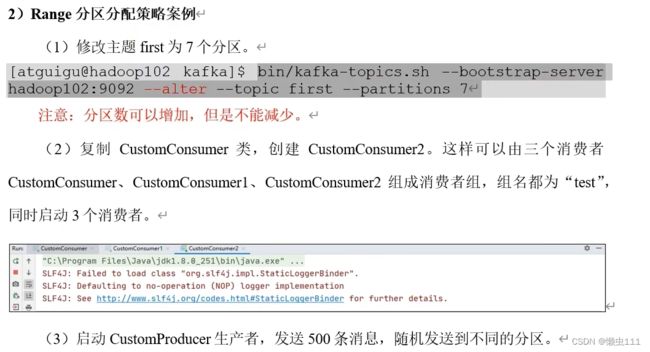
5.4.1 分区策略-Range概述



5.4.2 RoundRobin 以及再平衡
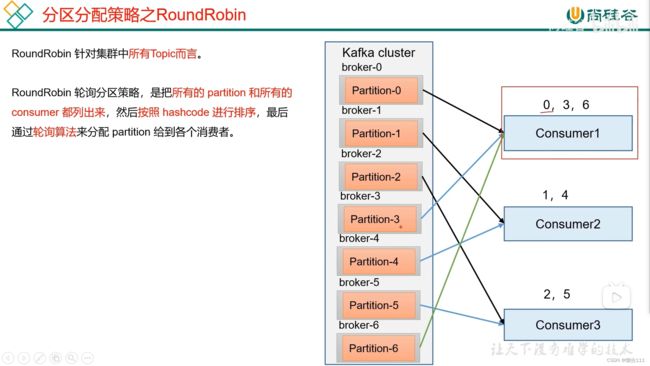


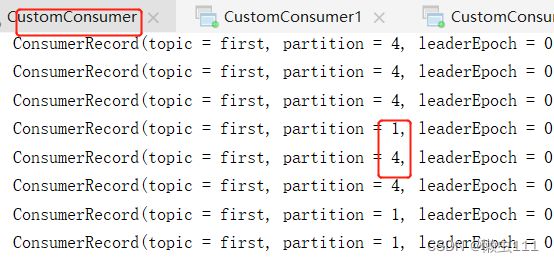

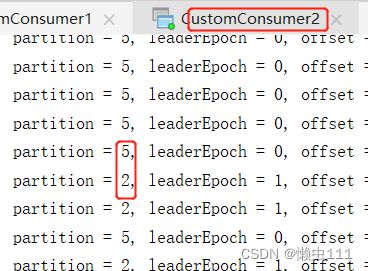
手动关闭,45s内将无法发送到指定分区的打包发送另外一个分区,45s超时,则重新分配消费策略
5.4.3 Sticky以及再平衡

5.5 offset位移
5.5.1 offset的默认维护位置



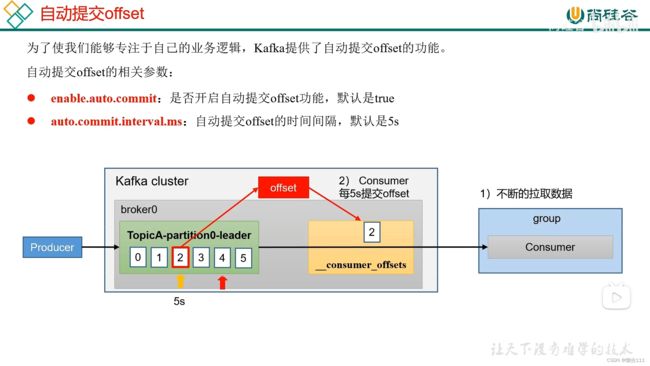
5.5.2 自动提交 offset

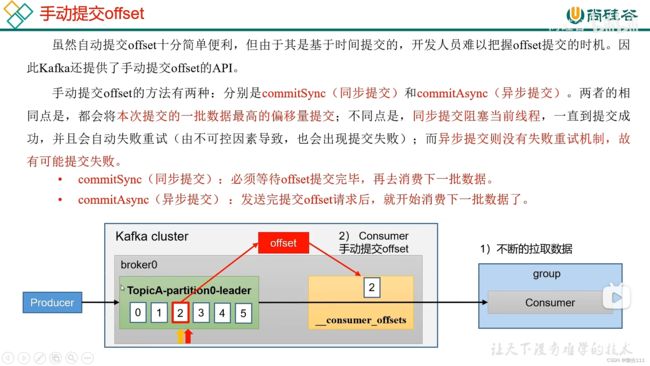
5.5.3 手动提交offset


5.5.4 指定 Offset消费


5.5.5 指定时间消费
需求: 在生产环境中,会遇到最近消费的几个小时的数据异常,想要重新按照时间消费.
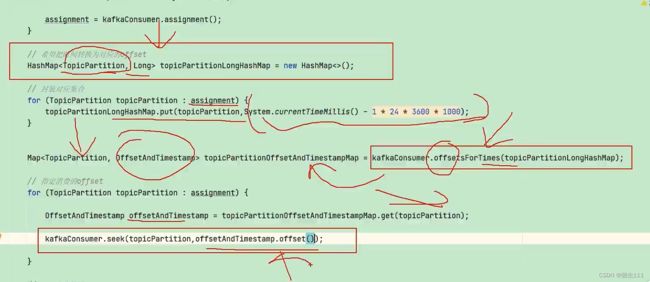
5.5.6 漏消费和重复消费

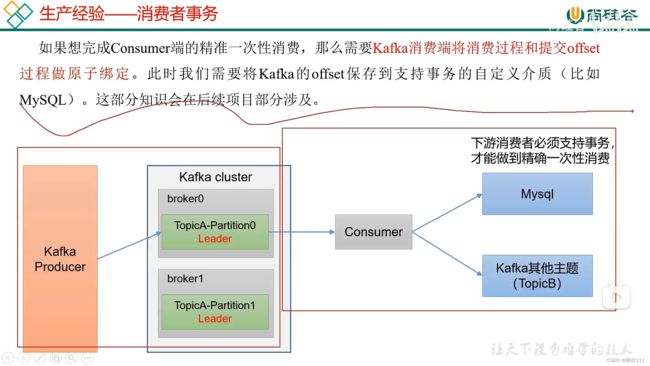
5.6 生产经验-消费者事务
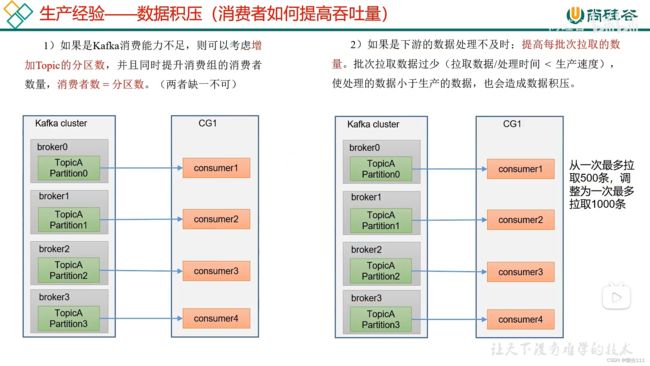
5.7 生产经验--数据积压(消费者如何提高吞吐量)