Ubuntu20.04虚拟机使用Kubeadm从0到1搭建K8S集群(超详细)
前言
最近在读张磊老师的《深入剖析Kubernets》,在阅读4.2节的时候遇到了问题,由于书上使用的版本已经过时,很多命令的执行都失败了,在经历了长达两个星期的折磨以后,我终于把这一节需要完成的部署任务都搞定了,写成这篇文章,拿出来与大家交流学习一下。
1 虚拟机配置
master镜像:PD自带(Ubuntu 20.04.1 LTS desktop版)
worker镜像:ubuntu-20.04.3-live-server-amd64
1.1 硬件配置
master: 2核CPU+8G内存
worker: 2核CPU+4G内存
1.2 网络配置(worker节点的IP在安装的时候进行配置)
说明:1.2部分的操作只需要在master节点上进行,worker节点的IP配置在安装的过程中已经完成了,安装步骤参考:Ubuntu 20.04 live server版安装(详细版) - 运维密码 - 博客园 (cnblogs.com)
为4台虚拟机配置的IP地址(根据你自己的虚拟网络地址进行修改):
k8s-master: 10.211.55.122
k8s-node-1:10.211.55.123
k8s-node-2:10.211.55.124
k8s-node-3:10.211.55.125
统一修改root密码,后续操作如无特别说明,均在root用户中执行:
sudo passwd root
查看网卡名称:
ip a
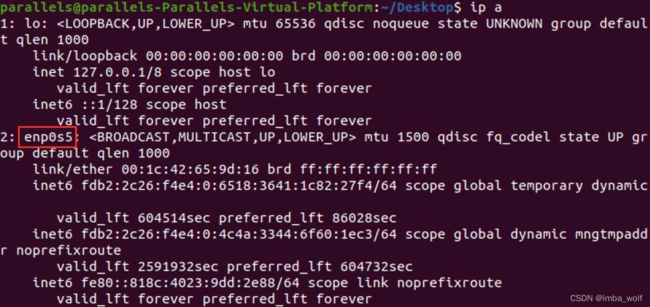
修改网络配置文件:
vi /etc/netplan/01-network-manager-all.yaml
改为如下所示:
network:
version: 2
renderer: NetworkManager
ethernets:
enp0s5:
dhcp4: false
addresses: [10.211.55.122/24]
gateway4: 10.211.55.1
nameservers:
addresses: [223.5.5.5,8.8.8.8]
使配置生效:
netplan --debug apply
现在,ping一下宿主机和百度,都能ping通了。
网络弄好了之后安装一下vim,后面会经常需要用到:
apt-get update
apt-get install -y vim
1.3 ssh配置(可以不配)
安装openssh的服务器和客户端:
apt install -y openssh-server openssh-client
修改sshd服务配置,允许xshell以root用户访问(使用root身份修改/etc/ssh/sshd_config文件,设置PermitRootLogin为yes):
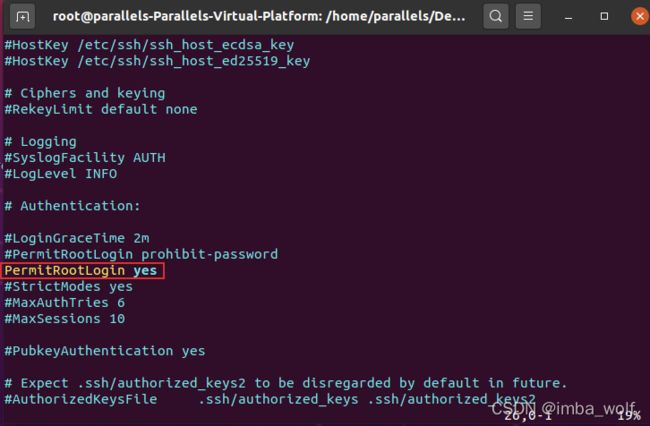
# 重启ssh服务
service ssh restart
主机使用ssh连接到虚拟机的root用户:

1.4 其他配置
关闭防火墙、虚拟交换分区
# 关闭防火墙
ufw disable
# 关闭虚拟交换(注释fstab中swap配置)
vim /etc/fstab

设置hosts(记得改成自己的):
cat >> /etc/hosts << EOF
10.211.55.122 k8s-master
10.211.55.123 k8s-node-1
10.211.55.124 k8s-node-2
10.211.55.125 k8s-node-3
EOF
将桥接的IPV4流量传递到iptables链中
# 配置
cat >> /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
设置apt-get 国内源
# 备份/etc/apt/sources.list
cp /etc/apt/sources.list /etc/apt/sources.list.bak
# 使用vim 替换/etc/apt/sources.list中的资源地址
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
# 更新
apt-get update
2 集群部署
2.1 安装Docker
安装:
# 安装
apt-get install -y docker.io
# 查看docker状态
systemctl status docker
# 如果没有启动,就手动启动
# systemctl start docker
# 设置开机自启
systemctl enable docker
为Docker配置镜像加速:
阿里云加速器(点击管理控制台 -> 登录账号(淘宝账号) -> 右侧镜像工具 -> 镜像加速器 -> 复制加速器地址)
修改/etc/docker/daemon.json文件,xxxxxxxx改成你自己的加速器地址:
{
"registry-mirrors": [
"https://xxxxxxxx.mirror.aliyuncs.com"
]
}
之后重新启动服务:
# 重启
systemctl daemon-reload
systemctl restart docker
# 检查加速器是否生效
docker info
如果从结果中看到了如下内容,说明配置成功。
Registry Mirrors:
https://xxxxxxxxx.mirror.aliyuncs.com/
将当前用户加入docker用户组中:
# 添加docker用户组(应该已经存在了)
sudo groupadd docker
# 将当前用户加入到docker用户组中
sudo gpasswd -a $USER docker
# 测试docker命令是否可以正常使用
docker ps
以上配置在重启以后生效(newgrp docker 命令只能让你登入docker用户组,但是新建的terminal仍然是没有docker用户组权限的)。
2.2 安装Kubeadm
apt-get update && apt-get install -y apt-transport-https curl
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat >> /etc/apt/sources.list.d/kubernetes.list << EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl
添加k8s自动补全请参考:Install and Set Up kubectl on Linux | Kubernetes
2.3 部署Master节点
在正式开始之前,我们要先做一件事——修改主机名,不然后面显示信息可能会有点困扰,具体做法如下:
先修改/etc/hostname文件,改成k8s-master:

然后修改一下/etc/hosts文件:
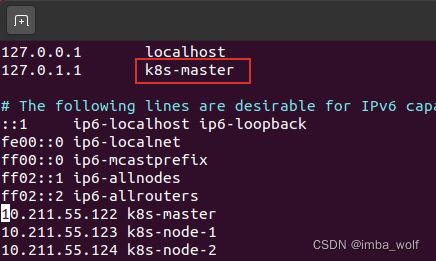
重启机器即可生效。worker节点的名字在安装的时候就改好了,如果你没有修改的话,可以按照上述步骤进行修改。
言归正传,新建一个kubeadm.yaml文件(因为书上是使用yaml文件初始化的,当然你也可以用命令行参数进行初始化,这里的yaml文件我已经修改过了),内容如下:
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.211.55.122
bindPort: 6443
nodeRegistration:
kubeletExtraArgs:
cgroup-driver: "systemd"
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
imageRepository: registry.aliyuncs.com/google_containers
kubernetesVersion: 1.23.0
clusterName: "example-cluster"
controllerManager:
extraArgs:
horizontal-pod-autoscaler-sync-period: "10s"
node-monitor-grace-period: "10s"
apiServer:
extraArgs:
runtime-config: "api/all=true"
执行初始化命令:
kubeadm init --config kubeadm.yaml
报错:
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
解决方案:
修改我们的docker配置文件/etc/docker/daemon.json,添加一行:
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://xxxxxxxx.mirror.aliyuncs.com"
]
}
之后执行如下命令:
# 重启docker
systemctl daemon-reload
systemctl restart docker
# kubeadm重置
kubeadm reset
rm -rf $HOME/.kube/config
# 重新初始化
kubeadm init --config kubeadm.yaml
这样就初始化成功啦:

按照提示,执行后续操作:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
查看部署状态:
kubectl get nodes
# 显示结果
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane,master 6m54s v1.23.3
可以看到STATUS显示的是NotReady,我们可以使用kubectl describe查看一下节点信息:
kubectl describe node k8s-master

这里我们可以看到,出现NotReady的原因是我们尚未部署任何网络插件。
另外,我们可以通过kubectl查询Pod状态:
kubectl get pods -n kube-system

可以看到,CoreDNS的Pod处于Pending状态,因为它是依赖于网络的,这个状态是符合预期的。
2.4 部署网络插件
可选的网络插件包括Flannel、Calico、Weave等,这里我们以Weave为例。
部署Weave插件非常简单,只需要一行指令:
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
稍等片刻,再查询pod状态,可以发现全都Running了,而且还新增了一个名叫weave-net-rtdhz的Pod。
kubectl get pods -n kube-system

至此,Master节点的部署就全部完成了。
2.5 部署woker节点
worker节点的部署很简单,只需要执行之前kubeadm init成功后生成的kubeadm join指令即可:
# 查询join语句
kubeadm token create --print-join-command
# 加入集群
kubeadm join 10.211.55.122:6443 --token f5g7lb.iwqo5lyqy35qs9q8 --discovery-token-ca-cert-hash sha256:b0f0d2e7fd2383a0e77a937b4e7ebafec4e847977a5a633ad621ec4992a90c54
这里报了跟之前一样的错,像之前那样解决就行(同样需要重置kubeadm)。
两个节点都部署完了以后,我们在master上再次执行kubectl get nodes,可以看到worker节点已经部署成功,并且所有节点全部Ready了:

至此,一个基本完整的Kubernetes集群就部署完毕了。
接下来,我们将在这个Kubernetes集群上安装一些辅助插件,如Dashboard插件和存储插件。
2.6 部署Dashboard可视化插件
首先是部署:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml
验证一下部署是否成功:
kubectl get svc,pods -n kubernetes-dashboard

查看代理是否正确安装部署:
kubectl cluster-info

开启代理:
kubectl proxy
访问下面这个地址:
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
这时你的界面可能是这样的:

这是为什么呢?让我们查看一下Pod所在节点:
kubectl get pods --all-namespaces -o wide
可以看到kubernetes-dashboard是运行在k8s-node-1上的!

为此,我们只能修改一下dashboard的部署文件了。
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml
将 “beta.kubernetes.io/os”: linux 修改为 type: master:

注意,这样的修改有两处。
然后再执行:
# 给主节点加标签
kubectl label node k8s-master type=master
# 删除之前创建的资源
kubectl delete all --all -n kubernetes-dashboard
kubectl apply -f recommended.yaml

现在,这俩Pod都运行在master节点上啦。
重新执行kubectl proxy,访问之前的地址,可以看到如下界面:
下面我们要做的就是获取token了。
新建一个dashboard-adminuser.yaml文件,内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
执行:
kubectl apply -f dashboard-adminuser.yaml
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
输出的一长串字符串就是我们的token。将其拷贝,粘贴到浏览器中,就可以进入Dashboard了。
当然,里面可能啥也没有,因为我们在default命名空间里没有部署任何Pod:

没关系,我们可以切换一下命名空间,比如kube-system:

这样就能以可视化的方式查看集群的状态了。
2.7 部署容器存储插件Rook

由于墙的存在,在部署rook的时候有些镜像拉取不下来(如上图所示),因此我们得在worker节点上提前下载好镜像,重命名为Rook需要的镜像(版本号是笔者写文时的版本号,以后镜像可能会更新,如果pod卡住了,记得describe一下,确认版本号是否一致):
# csi-node-driver-registrar:v2.3.0
docker pull longhornio/csi-node-driver-registrar:v2.3.0
docker tag longhornio/csi-node-driver-registrar:v2.3.0 k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.3.0
docker image rm longhornio/csi-node-driver-registrar:v2.3.0
# csi-provisioner:v3.0.0
docker pull bingo4933/csi-provisioner:v3.0.0
docker tag bingo4933/csi-provisioner:v3.0.0 k8s.gcr.io/sig-storage/csi-provisioner:v3.0.0
docker image rm bingo4933/csi-provisioner:v3.0.0
# csi-resizer:v1.3.0
docker pull bingo4933/csi-resizer:v1.3.0
docker tag bingo4933/csi-resizer:v1.3.0 k8s.gcr.io/sig-storage/csi-resizer:v1.3.0
docker image rm bingo4933/csi-resizer:v1.3.0
# csi-attacher:v3.3.0
docker pull bingo4933/csi-attacher:v3.3.0
docker tag bingo4933/csi-attacher:v3.3.0 k8s.gcr.io/sig-storage/csi-attacher:v3.3.0
docker image rm bingo4933/csi-attacher:v3.3.0
# csi-snapshotter:v4.2.0
docker pull bingo4933/csi-snapshotter:v4.2.0
docker tag bingo4933/csi-snapshotter:v4.2.0 k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0
docker image rm bingo4933/csi-snapshotter:v4.2.0
# 删除所有镜像
# docker image rm k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.3.0
# docker image rm k8s.gcr.io/sig-storage/csi-provisioner:v3.0.0
# docker image rm k8s.gcr.io/sig-storage/csi-resizer:v1.3.0
# docker image rm k8s.gcr.io/sig-storage/csi-attacher:v3.3.0
# docker image rm k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0
这里我们选择部署的是Rook,按照官方文档来就行:
git clone --single-branch --branch master https://github.com/rook/rook.git
# 部署Rook Operator
cd rook/deploy/examples
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
# 验证rook-ceph-operator处于`Running`状态
kubectl -n rook-ceph get pod
![]()
# 创建Ceph集群
kubectl create -f cluster.yaml
# 验证Ceph集群部署成功
kubectl -n rook-ceph get pod -o wide
这个时候我们看到了下面的状态,似乎全都运行成功了:

我们用Ceph工具来查看一下集群状态,确认已经部署成功:
# 部署Ceph toolbox
kubectl apply -f toolbox.yaml
# 验证是否部署成功
kubectl -n rook-ceph get pods -o wide | grep ceph-tools
# 进入pod
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
# 查看Ceph集群状态
ceph status

结果发现显示的是WARN,似乎是osd出了问题。
我们输入kubectl describe -n rook-ceph pod rook-ceph-osd-prepare-k8s-node-1-srzgb
得到如下信息(只截取了部分):
lse Readonly:false Partitions:[] Filesystem:ext4 Vendor: Model: WWN: WWNVendorExtension: Empty:false CephVolumeData: RealPath:/dev/mapper/ubuntu--vg-ubuntu--lv KernelName:dm-0 Encrypted:false}
2022-02-15 09:26:54.468264 D | exec: Running command: udevadm info --query=property /dev/sda1
2022-02-15 09:26:54.480314 D | exec: Running command: lsblk /dev/sda1 --bytes --nodeps --pairs --paths --output SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME
2022-02-15 09:26:54.484662 D | exec: Running command: ceph-volume inventory --format json /dev/sda1
2022-02-15 09:26:55.425339 I | cephosd: skipping device "sda1": ["Insufficient space (<5GB)"].
2022-02-15 09:26:55.425496 I | cephosd: skipping device "sda2" because it contains a filesystem "ext4"
2022-02-15 09:26:55.425632 I | cephosd: skipping device "sda3" because it contains a filesystem "LVM2_member"
2022-02-15 09:26:55.425876 I | cephosd: skipping 'dm' device "dm-0"
2022-02-15 09:26:55.435003 I | cephosd: configuring osd devices: {"Entries":{}}
2022-02-15 09:26:55.435177 I | cephosd: no new devices to configure. returning devices already configured with ceph-volume.
2022-02-15 09:26:55.435758 D | exec: Running command: stdbuf -oL ceph-volume --log-path /tmp/ceph-log lvm list --format json
2022-02-15 09:26:56.057534 D | cephosd: {}
2022-02-15 09:26:56.057878 I | cephosd: 0 ceph-volume lvm osd devices configured on this node
2022-02-15 09:26:56.058081 D | exec: Running command: cryptsetup luksDump
2022-02-15 09:26:56.093716 E | cephosd: failed to determine if the encrypted block "" is from our cluster. failed to dump LUKS header for disk "". Device does not exist or access denied.: exit status 4
2022-02-15 09:26:56.094016 D | exec: Running command: stdbuf -oL ceph-volume --log-path /tmp/ceph-log raw list --format json
2022-02-15 09:26:57.201027 D | cephosd: {}
2022-02-15 09:26:57.201081 I | cephosd: 0 ceph-volume raw osd devices configured on this node
2022-02-15 09:26:57.201092 W | cephosd: skipping OSD configuration as no devices matched the storage settings for this node "k8s-node-2"
从上面可以看到,sda的三个分区全都不符合条件,因此我们要修改硬盘的大小,进行扩容,开辟出一块分区提供给OSD使用。退出虚拟机,修改设置,我这里将磁盘大小增加了10GB。
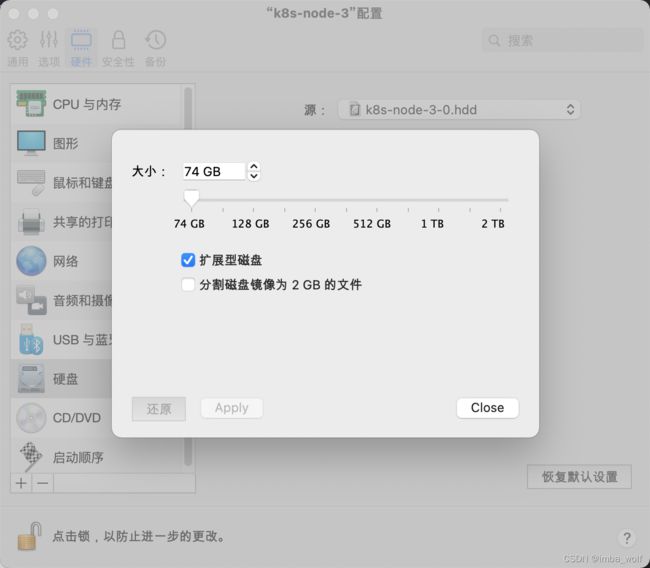
重新开启虚拟机,按照如下指令操作,不需要输入字符的时候就直接回车:

现在磁盘已经分好区了,我们可以重新部署一下节点,如果部署顺利的话,过程应该跟我下面的3张截图差不多:

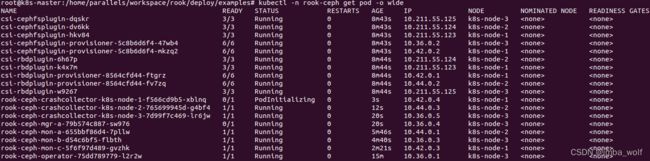

可以看到,比之前多了3个以rook-ceph-osd开头的pod,但是到底有没有部署成功,还是得用Ceph工具查看:

这样,一个基于Rook的持久化存储集群就以容器的方式运行起来了。
大功告成!
PS: 一些清理命令:
# 取消rook的部署
k delete -f toolbox.yaml
k delete -f cluster.yaml
k delete -f crds.yaml -f common.yaml -f operator.yaml
# 完全清理kubeadm环境
kubeadm reset
rm -rf /etc/cni/net.d
rm -rf $HOME/.kube/config
rm -rf /etc/kubernetes/
参考文章
Ubuntu 20.04 live server版安装(详细版)
ubuntu-20.04.3 使用kubeadm方式安装kubernetes(k8s)集群_我们的征途是星辰大海-CSDN博客
kubernetes:[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz’ failed_zJay-L’s Blog-CSDN博客
【Ubuntu】 Ubuntu16.04修改主机名和查看主机名的方法_嵌入式开发工程师—欢迎大家一起交流-CSDN博客_ubuntu修改主机名
Web 界面 (Dashboard)
Kubernetes Dashboard安装以及一些常见问题1_进击的小猴-CSDN博客
rook/quickstart.md at master · rook/rook
Ceph
k8s:unable to create new content in namespace kubernetes-dashboard because it is being terminated_笑笑布丁的博客-CSDN博客
给ubuntu18.04主机扩容,用于rook ceph的osd_晴朗711的博客-CSDN博客