Unity 性能优化归纳
1、SimpleLOD :
除了同样拥有Mesh Baker所具有的Mesh合并、Atlas烘焙等功能,它还能提供Mesh的简化,并对动态蒙皮网格进行了很好的支持。
该插件可在Run-time和Editor中都可以使用,同时开放了源码,大家可以根据项目的实际情况而作修改。
http://download.csdn.net/download/jasonczy/10178526
一、
转载自 http://blog.csdn.net/game_jqd/article/details/51899000
使用Profiler工具分析内存占用情况
- System.ExecutableAndDlls:系统可执行程序和DLL,是只读的内存,用来执行所有的脚本和DLL引用。不同平台和不同硬件得到的值会不一样,可以通过修改Player Setting的Stripping Level来调节大小。
Ricky:我试着修改了一下Stripping Level似乎没什么改变,感觉虽占用内存大但不会影响游戏运行。我们暂时忽略它吧(- -)!
- GfxClientDevice:GFX(图形加速\图形加速器\显卡 (GraphicsForce Express))客户端设备。
Ricky:虽占用较大内存,但这也是必备项,没办法优化。继续忽略吧(- -)!!
- ManagedHeap.UsedSize:托管堆使用大小。
Ricky:重点监控对象,不要让它超过20MB,否则可能会有性能问题!
- ShaderLab:Unity自带的着色器语言工具相关资源。
Ricky:这个东西大家都比较熟悉了,忽略它吧。
- SerializedFile:序列化文件,把显示中的Prefab、Atlas和metadata等资源加载进内存。
Ricky:重点监控对象,这里就是你要监控的哪些预设在序列化中在内存中占用大小,根据需求进行优化。
- PersistentManager.Remapper:持久化数据重映射管理相关
Ricky:与持久化数据相关,比如AssetBundle之类的。注意监控相关的文件。
- ManagedHeap.ReservedUnusedSize:托管堆预留不使用内存大小,只由Mono使用。
Ricky:无法优化。
- 许多贴图采用的Format格式是ARGB 32 bit所以保真度很高但占用的内存也很大。在不失真的前提下,适当压缩贴图,使用ARGB 16 bit就会减少一倍,如果继续Android采用RGBA Compressed ETC2 8 bits(iOS采用RGBA Compressed PVRTC 4 bits),又可以再减少一倍。把不需要透贴但有alpha通道的贴图,全都转换格式Android:RGB Compressed ETC 4 bits,iOS:RGB Compressed PVRTC 4 bits。
- 当加载一个新的Prefab或贴图,不及时回收,它就会永驻在内存中,就算切换场景也不会销毁。应该确定物体不再使用或长时间不使用就先把物体制空(null),然后调用Resources.UnloadUnusedAssets(),才能真正释放内存。
- 有大量空白的图集贴图,可以用TexturePacker等工具进行优化或考虑合并到其他图集中。
- AudioManager:音频管理器
Ricky:随着音频文件的增多而增大。
- AudioClip:音效及声音文件
Ricky:重点优化对象,播放时长较长的音乐文件需要进行压缩成.mp3或.ogg格式,时长较短的音效文件可以使用.wav 或.aiff格式。
- Cubemap:立方图纹理
Ricky:这个一般在天空盒中比较常见,我也不知道如何优化这个。。。
- Mesh:模型网格
Ricky:主要检查是否有重复的资源,还有尽量减少点面数。
- Mesh:场景中使用的网格模型
Ricky:注意网格模型的点面数,能合并的mesh尽量合并。
1)ManagedHeap.UsedSize: 移动游戏建议不要超过20MB.
2)SerializedFile: 通过异步加载(LoadFromCache、WWW等)的时候留下的序列化文件,可监视是否被卸载.
3)WebStream: 通过异步WWW下载的资源文件在内存中的解压版本,比SerializedFile大几倍或几十倍,不过我们现在项目中展示没有。
4)Texture2D: 重点检查是否有重复资源和超大Memory是否需要压缩等.
5)AnimationClip: 重点检查是否有重复资源.
6)Mesh: 重点检查是否有重复资源.
1.Device.Present:
1)GPU的presentdevice确实非常耗时,一般出现在使用了非常复杂的shader.
2)GPU运行的非常快,而由于Vsync的原因,使得它需要等待较长的时间.
3)同样是Vsync的原因,但其他线程非常耗时,所以导致该等待时间很长,比如:过量AssetBundle加载时容易出现该问题.
4)Shader.CreateGPUProgram:Shader在runtime阶段(非预加载)会出现卡顿(华为K3V2芯片).
5)StackTraceUtility.PostprocessStacktrace()和StackTraceUtility.ExtractStackTrace(): 一般是由Debug.Log或类似API造成,游戏发布后需将Debug API进行屏蔽。
2.Overhead:
1)一般情况为Vsync所致.
2)通常出现在Android设备上.
3.GC.Collect:
原因:
1)代码分配内存过量(恶性的)
2)一定时间间隔由系统调用(良性的).
占用时间:
1)与现有Garbage size相关
2)与剩余内存使用颗粒相关(比如场景物件过多,利用率低的情况下,GC释放后需要做内存重排)
4.GarbageCollectAssetsProfile:
1)引擎在执行UnloadUnusedAssets操作(该操作是比较耗时的,建议在切场景的时候进行)。
2)尽可能地避免使用Unity内建GUI,避免GUI.Repaint过渡GCAllow.
3)if(other.tag == a.tag)改为other.CompareTag(a.tag).因为other.tag为产生180B的GC Allow.
4)少用foreach,因为每次foreach为产生一个enumerator(约16B的内存分配),尽量改为for.
5)Lambda表达式,使用不当会产生内存泄漏.
5.尽量少用LINQ:
1)部分功能无法在某些平台使用.
2)会分配大量GC Allow.
6.控制StartCoroutine的次数:
1)开启一个Coroutine(协程),至少分配37B的内存.
2)Coroutine类的实例 -> 21B.
3)Enumerator -> 16B.
7.使用StringBuilder替代字符串直接连接.
8.缓存组件:
1)每次GetComponent均会分配一定的GC Allow.
2)每次Object.name都会分配39B的堆内存.
.框架设计层面。
一个相对中大型的游戏,系统非常的多。这时候合理的适时的释放内存有助于游戏的正常体验,甚至可以防止内存快速到达峰值,导致设备Crash。
目前主流平台机型可用内存:
Android平台:在客户端最低配置以上,均需满足以下内存消耗指标(PSS):
1)内存1G以下机型:最高PSS<=150MB
2)内存2G的机型:最高PSS<=200MB
iOS平台:在iPhone4S下运行,消耗内存(real mem)不大于150MB
1.场景切换时避开峰值。
当前一个场景还未释放的时候,切换到新的场景。这时候由于两个内存叠加很容易达到内存峰值。解决方案是,在屏幕中间遮盖一个Loading场景。在旧的释放完,并且新的初始化结束后,隐藏Loading场景,使之有效的避开内存大量叠加超过峰值。
2.GUI模块加入生命周期管理。
主角、强化、技能、商城、进化、背包、任务等等。通常一个游戏都少不了这些系统。但要是全部都打开,或者这个时候再点世界地图,外加一些逻辑数据内存的占用等等。你会发现,内存也很快就达到峰值。
这时候有效的管理系统模块生命周期就非常有必要。首先将模块进行划分:
1)经常打开 Cache_10;
2)偶尔打开 Cache_5;
3)只打开一次 Cache_0。
创建一个ModuleMananger 类,内部Render方法每分钟轮询一次。如果是“Cache_0”这个类型,一关闭就直接Destroy释放内存;“Cache_10”这个类型为10分钟后自动释放内存;" Cache_5"这种类型为5分钟后自动释放内存。每次打开模块,该模块就会重新计时。这样就可以有效合理的分配内存。
1、 由于实时对战游戏的数据包数量巨大,早期版本的帧同步策略会导致比较明显的卡顿,通过进行数据包的合并与优化逐渐解决了卡顿问题;
2、 频繁创建和销毁的小兵对象让CPU爆表了,大量的小兵如果采用实时内存的分配和回收,会产生大量的内存碎片和系统开销,解决方法之一就是采用高效的对象池进行优化,对每个内存对象的状态进行操作即可;
3、 性能分析过程中,发现单人同屏和多人同屏时的开销都很大,通过视野裁剪技术,使得玩家视野外的不必要的特效和渲染可以全部关闭,极大降低了CPU、GPU和内存的开销;
4、 在高中低三档机型上玩游戏时,分别加载不同层次的特效包,这也有助于降低CPU和内存的开销;性能分析过程中发现副本内wwise音频组件占了30%的CPU时间,果断抛弃之,采用Unity自带音频功能,优化很明显;
5、 游戏内界面采用了UGUI的方式实现,但大量的实时UI变化使得副本内每帧会有230以上的drawcall,导致中低端机型感受到明显卡顿,最终采用UGUI+自研究UI的组合拳,重写了一套紧密结合游戏自身特性的UI来实现战斗血条和浮动文字的效果。
6、 资源使用总量是否在合理范围之内。
7、 一个场景内的资源重复率。
8、 资源对象拷贝的数量是否合理。
9、 场景切换时保留的资源详情。
10、 网格、纹理、音频、动画、GameObject等资源是否超标。
11、 贴图:
12、 l 控制贴图大小,尽量不要超过 1024x1024;
13、 l 尽量使用2的n次幂大小的贴图,否则GfxDriver里会有2份贴图;
14、 l 尽量使用压缩格式减小贴图大小;
15、 l 若干种贴图合并技术;
16、 l 去除多余的alpha通道;
17、 l 不同设备使用不同的纹理贴图,分层显示;
18、
19、 模型:
20、 l 尽量控制模型的面数,小于1500会比较合适;
21、 l 不同设备使用不同的模型面数;
22、 l 尽量保持在30根骨骼内;
23、 l 一个网格不要超过3个material;
24、 动画:
25、 l N种动画压缩方法;
26、 l 尽量减少骨骼数量;
27、 声音:
28、 l 采用压缩MP3 和 wav;
29、 资源方面的优化:
30、 l 使用 Resource.Load 方法在需要的时候再读取资源;
31、 l 各种资源在使用完成后,尽快用Resource.UnloadAsset和UnloadUnusedAsset卸载掉;
32、 l 灵活运用AssetBundle的Load和Unload方法动态加载资源,避免主要场景内的初始化内存占用过高;(实现起来真的很难…)
33、 l 采用www加载了AssetBundle后,要用www.Dispose 及时释放;
34、 l 在关卡内谨慎使用DontDestroyOnLoad,被标注的资源会常驻内存;
35、 代码的优化:
36、 l 尽量避免代码中的任何字符串连接,因为这会给GC带来太多垃圾;
37、 l 用简单的“for”循环代替“foreach”循环;
38、 l 为所有游戏内的动态物体使用内存对象池,可以减少系统开销和内存碎片,复用对象实例,构建自己的内存管理模式,减少Instantiate和Destory;
39、 l 尽量不使用LINQ命令,因为它们一般会分配中间缓器,而这很容易生成垃圾内存;
40、 l 将引用本地缓存到元件中会减少每次在一个游戏对象中使用 “GetComponent” 获取一个元件引用的需求;
41、 l 减少角色控制器移动命令的调用。移动角色控制器会同步发生,每次调用都会耗损较大的性能;
42、 l 最小化碰撞检测请求(例如raycasts和sphere checks),尽量从每次检查中获得更多信息;
43、 l AI逻辑通常会生成大量物理查询,建议让AI更新循环设置低于图像更新循环,以减少CPU负荷;
44、 l 要尽量减少Unity回调函数,哪怕是空函数也不要留着;(例如空的Update、FixedUpdate函数)
45、 l 尽量少使用FindObjectsOfType函数,这个函数非常慢,尽量少用且一定不要在Update里调用;
46、 l 千万一定要控制mono堆内存的大小;
47、
48、 unity3D 对于移动平台的支持无可厚非,但是也有时候用Unity3D 开发出来的应用、游戏在移动终端上的运行有着明显的效率问题,比如卡、画质等各种问题。自己在做游戏开发的时候偶有所得。对于主要影响性能的因素做个总结。
49、
50、 主要因素有:
51、 1. Savedby batching 值过大 ---- > 这个值主要是针对Mesh的批处理,这个值越高,应用就越卡
52、 2. Drawcall值过大 ---- > Drawcall 值过大,所需要的 GPU 的处理性能较高,从而导致CPU的计算时间过长,于是就卡了
53、 3. 点、面过多 ----> 点、面过多,GPU 根据不同面的效果展开计算,并且CPU计算的数据也多,所以效果出来了,但是卡巴斯基
54、 由于 Saved by batching 和 Drawcall 值过大所引起的卡的问题我所做的优化方式有:
55、 1. 对于模型 :Mesh 合并,有个不错的插件(DrawCallMinimizer ---> 直接上AssetStore 下载即可,免费的,而且有文档,很容易上手)
56、 2. 对于UI : 尽量避免使用Unity3D自带的 GUI 换用 NGUI或者EZGUI;因为这两个UI插件对于UI中的图片处理是将UI图片放置在一个 Atlas中,一个 Atlas 对应一个Drawcall
57、 3. 对于灯光: 可以使用 Unity3D 自带的 Lightmapping插件来烘焙场景中的灯光效果到物体材质上
58、 4. 对于场景: 可以使用 Unity3D 自带的 OcclusionCulling 插件把静止不动的场景元素烘焙出来
59、 4. 对于特效:尽量把材质纹理合并
60、 对于Unity3D 在移动终端上支持的Drawcall 数到底多少,主要是跟机子性能有关的,当然也不是说值小性能就一定没问题(本人亲测,也有17就卡的,主要是模型材质纹理过大所引起的),目前我做的是70左右的,还OK,挺正常的
61、
62、 由于点、面过多所导致的性能问题,最好用简模,用四面体来做复杂的模型,但是面、点也别太多,至于Unity3D 到底支持多少点、面的说法各异,我也搞不懂,总之少些肯定OK
63、
64、
65、
66、 检测方式:
67、 一,Unity3D 渲染统计窗口
68、 Game视窗的Stats去查看渲染统计的信息:
69、 1、FPS
70、 fps其实就是 framesper second,也就是每一秒游戏执行的帧数,这个数值越小,说明游戏越卡。
71、
72、 2、Draw calls
73、 batching之后渲染mesh的数量,和当前渲染到的网格的材质球数量有关。
74、
75、 3、Saved by batching
76、 渲染的批处理数量,这是引擎将多个对象的绘制进行合并从而减少GPU的开销;
77、 很多GUI插件的一个好处就是合并多个对象的渲染,从而降低DrawCalls ,保证游戏帧数。
78、
79、 4、Tris 当前绘制的三角面数
80、
81、 5、Verts 当前绘制的顶点数
82、
83、 6、Used Textures 当前帧用于渲染的图片占用内存大小
84、
85、 7、Render Textures 渲染的图片占用内存大小,也就是当然渲染的物体的材质上的纹理总内存占用
86、
87、 8、VRAM usage 显存的使用情况,VRAM总大小取决于你的显卡的显存
88、
89、 9、VBO Total 渲染过程中上载到图形卡的网格的数量,这里注意一点就是缩放的物体可能需要额外的开销。
90、
91、 10、VisibleSkinned Meshes 蒙皮网格的渲染数量
92、
93、 11、Animations 播放动画的数量
94、 注意事项:
95、 1,运行时尽量减少 Tris 和 Draw Calls
96、 预览的时候,可点开 Stats,查看图形渲染的开销情况。特别注意 Tris 和 Draw Calls 这两个参数。
97、 一般来说,要做到:
98、 Tris 保持在 7.5k 以下,有待考证。
99、 Draw Calls 保持在 20 以下,有待考证。
100、 2,FPS,每一秒游戏执行的帧数,这个数值越小,说明游戏越卡。
101、 3,Render Textures 渲染的图片占用内存大小。
102、 4,VRAM usage 显存的使用情况,VRAM总大小取决于你的显卡的显存。
103、
104、 二,代码优化
105、 1. 尽量避免每帧处理
106、 比如:
107、 function Update() {DoSomeThing(); }
108、 可改为每5帧处理一次:
109、 function Update() { if(Time.frameCount% 5 == 0) { DoSomeThing(); } }
110、 2. 定时重复处理用InvokeRepeating 函数实现
111、 比如,启动0.5秒后每隔1秒执行一次 DoSomeThing 函数:
112、
113、 function Start() {InvokeRepeating("DoSomeThing", 0.5, 1.0); }
114、
115、 3. 优化 Update,FixedUpdate, LateUpdate 等每帧处理的函数
116、 函数里面的变量尽量在头部声明。
117、 比如:
118、 function Update() { var pos:Vector3 = transform.position; }
119、 可改为
120、 private var pos: Vector3;function Update(){ pos = transform.position; }
121、
122、 4. 主动回收垃圾
123、 给某个 GameObject 绑上以下的代码:
124、 function Update() {if(Time.frameCount % 50 == 0) { System.GC.Collect(); } }
125、
126、 5. 优化数学计算
127、 比如,如果可以避免使用浮点型(float),尽量使用整形(int),尽量少用复杂的数学函数比如 Sin 和 Cos 等等
128、
129、 6,减少固定增量时间
130、 将固定增量时间值设定在0.04-0.067区间(即,每秒15-25帧)。您可以通过Edit->Project Settings->Time来改变这个值。这样做降低了FixedUpdate函数被调用的频率以及物理引擎执行碰撞检测与刚体更新的频率。如果您使用了较低的固定增量时间,并且在主角身上使用了刚体部件,那么您可以启用插值办法来平滑刚体组件。
131、 7,减少GetComponent的调用
132、 使用 GetComponent或内置组件访问器会产生明显的开销。您可以通过一次获取组件的引用来避免开销,并将该引用分配给一个变量(有时称为"缓存"的引用)。例如,如果您使用如下的代码:
133、 function Update () {
134、 transform.Translate(0, 1, 0);
135、
136、 }
137、 通过下面的更改您将获得更好的性能:
138、
139、 var myTransform : Transform;
140、 function Awake () {
141、 myTransform = transform;
142、 }
143、 function Update () {
144、 myTransform.Translate(0, 1, 0);
145、 }
146、
147、 8,避免分配内存
148、 您应该避免分配新对象,除非你真的需要,因为他们不再在使用时,会增加垃圾回收系统的开销。您可以经常重复使用数组和其他对象,而不是分配新的数组或对象。这样做好处则是尽量减少垃圾的回收工作。同时,在某些可能的情况下,您也可以使用结构(struct)来代替类(class)。这是因为,结构变量主要存放在栈区而非堆区。因为栈的分配较快,并且不调用垃圾回收操作,所以当结构变量比较小时可以提升程序的运行性能。但是当结构体较大时,虽然它仍可避免分配/回收的开销,而它由于"传值"操作也会导致单独的开销,实际上它可能比等效对象类的效率还要低。
149、
150、 9,使用iOS脚本调用优化功能
151、 UnityEngine 命名空间中的函数的大多数是在 C/c + +中实现的。从Mono的脚本调用 C/C++函数也存在着一定的性能开销。您可以使用iOS脚本调用优化功能(菜单:Edit->Project Settings->Player)让每帧节省1-4毫秒。此设置的选项有:
152、 Slow and Safe – Mono内部默认的处理异常的调用
153、
154、 Fast and Exceptions Unsupported–一个快速执行的Mono内部调用。不过,它并不支持异常,因此应谨慎使用。它对于不需要显式地处理异常(也不需要对异常进行处理)的应用程序来说,是一个理想的候选项。
155、
156、 10,
157、 优化垃圾回收
158、
159、 如上文所述,您应该尽量避免分配操作。但是,考虑到它们是不能完全杜绝的,所以我们提供两种方法来让您尽量减少它们在游戏运行时的使用:
160、 如果堆比较小,则进行快速而频繁的垃圾回收
161、 这一策略比较适合运行时间较长的游戏,其中帧率是否平滑过渡是主要的考虑因素。像这样的游戏通常会频繁地分配小块内存,但这些小块内存只是暂时地被使用。如果在iOS系统上使用该策略,那么一个典型的堆大小是大约 200 KB,这样在iPhone 3G设备上,垃圾回收操作将耗时大约 5毫秒。如果堆大小增加到1 MB时,该回收操作将耗时大约 7ms。因此,在普通帧的间隔期进行垃圾回收有时候是一个不错的选择。通常,这种做法会让回收操作执行的更加频繁(有些回收操作并不是严格必须进行的),但它们可以快速处理并且对游戏的影响很小:
162、 if (Time.frameCount % 30 == 0)
163、 {
164、 System.GC.Collect();
165、 }
166、
167、 但是,您应该小心地使用这种技术,并且通过检查Profiler来确保这种操作确实可以降低您游戏的垃圾回收时间
168、 如果堆比较大,则进行缓慢且不频繁的垃圾回收
169、 这一策略适合于那些内存分配 (和回收)相对不频繁,并且可以在游戏停顿期间进行处理的游戏。如果堆足够大,但还没有大到被系统关掉的话,这种方法是比较适用的。但是,Mono运行时会尽可能地避免堆的自动扩大。因此,您需要通过在启动过程中预分配一些空间来手动扩展堆(ie,你实例化一个纯粹影响内存管理器分配的"无用"对象):
170、
171、 function Start() {
172、
173、 var tmp = newSystem.Object[1024];
174、
175、 // make allocations in smallerblocks to avoid them to be treated in a special way, which is designed forlarge blocks
176、
177、 for (var i : int = 0; i <1024; i++)
178、
179、 tmp[i] = new byte[1024];
180、
181、 // release reference
182、
183、 tmp = null;
184、
185、 }
186、
187、 游戏中的暂停是用来对堆内存进行回收,而一个足够大的堆应该不会在游戏的暂停与暂停之间被完全占满。所以,当这种游戏暂停发生时,您可以显式请求一次垃圾回收:
188、
189、 System.GC.Collect();
190、
191、 另外,您应该谨慎地使用这一策略并时刻关注Profiler的统计结果,而不是假定它已经达到了您想要的效果。
192、
193、 三,模型
194、 1,压缩 Mesh
195、 导入 3D 模型之后,在不影响显示效果的前提下,最好打开 Mesh Compression。
196、 Off, Low, Medium, High 这几个选项,可酌情选取。
197、 2,避免大量使用 Unity 自带的 Sphere 等内建 Mesh
198、 Unity 内建的 Mesh,多边形的数量比较大,如果物体不要求特别圆滑,可导入其他的简单3D模型代替。
199、
200、 1不是每个主流手机都支持的技术(就是如果可以不用就不用或有备选方案)
201、 屏幕特效
202、 动态的pixel光照计算(如法线)
203、 实时的阴影
204、
205、 2优化建议
206、 2.1渲染
207、 1.不使用或少使用动态光照,使用light mapping和light probes(光照探头)
208、 2.不使用法线贴图(或者只在主角身上使用),静态物体尽量将法线渲染到贴图
209、 3.不适用稠密的粒子,尽量使用UV动画
210、 4.不使用fog,使用渐变的面片(参考shadowgun)
211、 5.不要使用alpha–test(如那些cutout shader),使用alpha-blend代替
212、 6.使用尽量少的material,使用尽量少的pass和render次数,如反射、阴影这些操作
213、 7.如有必要,使用Per-LayerCull Distances,Camera.layerCullDistances
214、 8.只使用mobile组里面的那些预置shader
215、 9.使用occlusionculling
216、 11.远处的物体绘制在skybox上
217、 12.使用drawcallbatching:
218、 对于相邻动态物体:如果使用相同的shader,将texture合并
219、 对于静态物体,batching要求很高,详见Unity Manual>Advanced>Optimizing Graphics Performance>Draw Call Batching
220、
221、 规格上限
222、 1. 每个模型只使用一个skinnedmesh renderer
223、 2. 每个mesh不要超过3个material
224、 3. 骨骼数量不要超过30
225、 4. 面数在1500以内将得到好的效率
226、 2.2物理
227、 1.真实的物理(刚体)很消耗,不要轻易使用,尽量使用自己的代码模仿假的物理
228、 2.对于投射物不要使用真实物理的碰撞和刚体,用自己的代码处理
229、 3.不要使用meshcollider
230、 4.在edit->projectsetting->time中调大FixedTimestep(真实物理的帧率)来减少cpu损耗
231、 2.3脚本编写
232、 1.尽量不要动态的instantiate和destroyobject,使用object pool
233、 2.尽量不要再update函数中做复杂计算,如有需要,可以隔N帧计算一次
234、 3.不要动态的产生字符串,如Debug.Log("boo"+ "hoo"),尽量预先创建好这些字符串资源
235、 4.cache一些东西,在update里面尽量避免search,如GameObject.FindWithTag("")、GetComponent这样的调用,可以在start中预先存起来
236、 5.尽量减少函数调用栈,用x= (x > 0 ? x : -x);代替x = Mathf.Abs(x)
237、 6.下面的代码是几个gc“噩梦”
238、 String的相加操作,会频繁申请内存并释放,导致gc频繁,使用System.Text.StringBuilder代替
239、 functionConcatExample(intArray: int[]) {
240、 varline = intArray[0].ToString();
241、
242、 for(i = 1; i < intArray.Length; i++) {
243、 line+= ", " + intArray[i].ToString();
244、 }
245、
246、 returnline;
247、 }
248、 在函数中动态new array,最好将一个array、传进函数里修改
249、 functionRandomList(numElements: int) {
250、 varresult = new float[numElements];
251、
252、 for(i = 0; i < numElements; i++) {
253、 result[i]= Random.value;
254、 }
255、
256、 returnresult;
257、 }
258、
259、 2.4 shader编写
260、 1.数据类型
261、 fixed / lowp -for colors, lighting information and normals,
262、 half / mediump -for texture UV coordinates,
263、 float / highp -avoid in pixel shaders, fine to use in vertex shader for position calculations.
264、 2.少使用的函数:pow,sin,cos等
265、 2.4 GUI
266、 1.不要使用内置的onGUii函数处理gui,使用其他方案,如NGUI
267、
268、 3.格式
269、 1.贴图压缩格式:ios上尽量使用PVRTC,android上使用ETC
270、 最简单的优化建议:
1.PC平台的话保持场景中显示的顶点数少于200K~3M,移动设备的话少于10W,一切取决于你的目标GPU与CPU。
2.如果你用U3D自带的SHADER,在表现不差的情况下选择Mobile或Unlit目录下的。它们更高效。
3.尽可能共用材质。
4.将不需要移动的物体设为Static,让引擎可以进行其批处理。
5.尽可能不用灯光。
6.动态灯光更加不要了。
7.尝试用压缩贴图格式,或用16位代替32位。
8.如果不需要别用雾效(fog)
9.尝试用OcclusionCulling,在房间过道多遮挡物体多的场景非常有用。若不当反而会增加负担。
10.用天空盒去“褪去”远处的物体。
11.shader中用贴图混合的方式去代替多重通道计算。
12.shader中注意float/half/fixed的使用。
13.shader中不要用复杂的计算pow,sin,cos,tan,log等。
14.shader中越少Fragment越好。
15.注意是否有多余的动画脚本,模型自动导入到U3D会有动画脚本,大量的话会严重影响消耗CPU计算。
16.注意碰撞体的碰撞层,不必要的碰撞检测请舍去。
1.为什么需要针对CPU(中央处理器)与GPU(图形处理器)优化?
CPU和GPU都有各自的计算和传输瓶颈,不同的CPU或GPU他们的性能都不一样,所以你的游戏需要为你目标用户的CPU与GPU能力进行针对开发。
2.CPU与GPU的限制
GPU一般具有填充率(Fillrate)和内存带宽(Memory Bandwidth)的限制,如果你的游戏在低质量表现的情况下会快很多,那么,你很可能需要限制你在GPU的填充率。
CPU一般被所需要渲染物体的个数限制,CPU给GPU发送渲染物体命令叫做DrawCalls。一般来说DrawCalls数量是需要控制的,在能表现效果的前提下越少越好。通常来说,电脑平台上DrawCalls几千个之内,移动平台上DrawCalls几百个之内。这样就差不多了。当然以上并不是绝对的,仅作一个参考。
往往渲染(Rendering)并不是一个问题,无论是在GPU和CPU上。很可能是你的脚本代码效率的问题,用Profiler查看下。
关于Profiler介绍:http://docs.unity3d.com/Documentation/Manual/Profiler.html
需要注意的是:
在GPU中显示的RenderTexture.SetActive()占用率很高,是因为你同时打开了编辑窗口的原因,而不是U3D的BUG。
3.关于顶点数量和顶点计算
CPU和GPU对顶点的计算处理都很多。GPU中渲染的顶点数取决于GPU性能和SHADER的复杂程度,一般来说,每帧之内,在PC上几百万顶点内,在移动平台上不超过10万顶点。
CPU中的计算主要是在蒙皮骨骼计算,布料模拟,顶点动画,粒子模拟等。GPU则在各种顶点变换、光照、贴图混合等。
【个人认为,具体还是看各位的项目需求,假设你项目的是3d游戏。你游戏需要兼容低配置的硬件、流畅运行、控制硬件发热的话,还要达到一定效果(LIGHTMAP+雾效),那么顶点数必定不能高。此时同屏2W顶点我认为是个比较合适的数目,DRAWCALL最好低于70。另,控制发热请控制最高上限的帧率,流畅的话,帧率其实不需要太高的。】
4.针对CPU的优化——减少DRAW CALL 的数量
为了渲染物体到显示器上,CPU需要做一些工作,如区分哪个东西需要渲染、区分开物体是否受光照影响、使用哪个SHADER并且为SHADER传参、发送绘图命令告诉显示驱动,然后发送命令告诉显卡删除等这些。
假设你有一个上千三角面的模型却用上千个三角型模型来代替,在GPU上花费是差不多的,但是在CPU上则是极其不一样,消耗会大很多很多。为了让CPU更少的工作,需要减少可见物的数目:
a.合并相近的模型,手动在模型编辑器中合并或者使用UNITY的Draw call批处理达到相同效果(Draw call batching)。具体方法和注意事项查看以下链接:
Draw call batching :http://docs.unity3d.com/Documentation/Manual/DrawCallBatching.html
b.在项目中使用更少的材质(material),将几个分开的贴图合成一个较大的图集等方式处理。
如果你需要通过脚本来控制单个材质属性,需要注意改变Renderer.material将会造成一份材质的拷贝。因此,你应该使用Renderer.sharedMaterial来保证材质的共享状态。
有一个合并模型材质不错的插件叫Mesh Baker,大家可以考虑试下。
c.尽量少用一些渲染步骤,例如reflections,shadows,per-pixel light 等。
d.Draw call batching的合并物体,会使每个物体(合并后的物体)至少有几百个三角面。
假设合并的两个物体(手动合并)但不共享材质,不会有性能表现上的提升。多材质的物体相当于两个物体不用一个贴图。所以,为了提升CPU的性能,你应该确保这些物体使用同样的贴图。
另外,用灯光将会取消(break)引擎的DRAW CALL BATCH,至于为什么,查看以下:
Forward Rendering Path Details:
http://docs.unity3d.com/Documentation/Components/RenderTech-ForwardRendering.html
e.使用相关剔除数量直接减少Draw Call数量,下文有相关提及。
5.优化几何模型
最基本的两个优化准则:
a.不要有不必要的三角面。
b.UV贴图中的接缝和硬边越少越好。
需要注意的是,图形硬件需要处理顶点数并跟硬件报告说的并不一样。不是硬件说能渲染几个点就是几个点。模型处理应用通展示的是几何顶点数量。例如,一个由一些不同顶点构成的模型。在显卡中,一些集合顶点将会被分离(split)成两个或者更多逻辑顶点用作渲染。如果有法线、UV坐标、顶点色的话,这个顶点必须会被分离。所以在游戏中处理的实际数量显然要多很多。
6.关于光照
若不用光肯定是最快的。移动端优化可以采用用光照贴图(Lightmapping)去烘培一个静态的贴图,以代替每次的光照计算,在U3D中只需要非常短的时间则能生成。这个方法能大大提高效率,而且有着更好的表现效果(平滑过渡处理,还有附加阴影等)。
在移动设备上和低端电脑上尽量不要在场景中用真光,用光照贴图。这个方法大大节省了CPU和GPU的计算,CPU得到了更少的DRAWCALL,GPU则需要更少顶点处理和像素栅格化。
Lightmapping : http://docs.unity3d.com/Documentation/Manual/Lightmapping.html
7.对GPU的优化——图片压缩和多重纹理格式
Compressed Textures(图片压缩):
http://docs.unity3d.com/Documentation/Components/class-Texture2D.html
图片压缩将降低你的图片大小(更快地加载更小的内存跨度(footprint)),而且大大提高渲染表现。压缩贴图比起未压缩的32位RGBA贴图占用内存带宽少得多。
之前U3D会议还听说过一个优化,贴图尽量都用一个大小的格式(512 * 512 , 1024 * 1024),这样在内存之中能得到更好的排序,而不会有内存之间空隙。这个是否真假没得到过测试。
MIPMAps(多重纹理格式):
http://docs.unity3d.com/Documentation/Components/class-Texture2D.html
跟网页上的略缩图原理一样,在3D游戏中我们为游戏的贴图生成多重纹理贴图,远处显示较小的物体用小的贴图,显示比较大的物体用精细的贴图。这样能更加有效的减少传输给GPU中的数据。
8.LOD 、 Per-Layer Cull Distances 、 Occlusion Culling
LOD (Level Of Detail) 是很常用的3D游戏技术了,其功能理解起来则是相当于多重纹理贴图。在以在屏幕中显示模型大小的比例来判断使用高或低层次的模型来减少对GPU的传输数据,和减少GPU所需要的顶点计算。
摄像机分层距离剔除(Per-Layer Cull Distances):为小物体标识层次,然后根据其距离主摄像机的距离判断是否需要显示。
遮挡剔除(Occlusion Culling)其实就是当某个物体在摄像机前被另外一个物体完全挡住的情况,挡住就不发送给GPU渲染,从而直接降低DRAW CALL。不过有些时候在CPU中计算其是否被挡住则会很耗计算,反而得不偿失。
以下是这几个优化技术的相关使用和介绍:
Level Of Detail :
http://docs.unity3d.com/Documentation/Manual/LevelOfDetail.html
Per-Layer Cull Distances :
http://docs.unity3d.com/Documentation/ScriptReference/Camera-layerCullDistances.html
Occlusion Culling :
http://docs.unity3d.com/Documentation/Manual/OcclusionCulling.html
9.关于Realtime Shadows(实时阴影)
实时阴影技术非常棒,但消耗大量计算。为GPU和CPU都带来了昂贵的负担,细节的话参考下面:
http://docs.unity3d.com/Documentation/Manual/Shadows.html
10.对GPU优化:采用高效的shader
a.需要注意的是有些(built-in)Shader是有mobile版本的,这些大大提高了顶点处理的性能。当然也会有一些限制。
b.自己写的shader请注意复杂操作符计算,类似pow,exp,log,cos,sin,tan等都是很耗时的计算,最多只用一次在每个像素点的计算。不推荐你自己写normalize,dot,inversesqart操作符,内置的肯定比你写的好。
c.需要警醒的是alpha test,这个非常耗时。
d.浮点类型运算:精度越低的浮点计算越快。
在CG/HLSL中--
float :32位浮点格式,适合顶点变换运算,但比较慢。
half:16位浮点格式,适合贴图和UV坐标计算,是highp类型计算的两倍。
fixed: 10位浮点格式,适合颜色,光照,和其他。是highp格式计算的四倍。
写Shader优化的小提示:
http://docs.unity3d.com/Documentation/Components/SL-ShaderPerformance.html
11.另外的相关优化:
a.对Draw Call Batching的优化
http://docs.unity3d.com/Documentation/Manual/DrawCallBatching.html
b.对Rendering Statistics Window的说明和提示:
http://docs.unity3d.com/Documentation/Manual/RenderingStatistics.html
c.角色模型的优化建议
用单个蒙皮渲染、尽量少用材质、少用骨骼节点、移动设备上角色多边形保持在300~1500内(当然还要看具体的需求)、PC平台上1500~4000内(当然还要看具体的需求)。
http://docs.unity3d.com/Documentation/Manual/ModelingOptimizedCharacters.html
渲染顺序
U3D的渲染是有顺序的,U3D的渲染顺序是由我们控制的,控制好U3D的渲染顺序,你才能控制好DrawCall
一个DrawCall,表示U3D使用这个材质/纹理,来进行一次渲染,那么这次渲染假设有3个对象,那么当3个对象都使用这一个材质/纹理的 时候,就会产生一次DrawCall,可以理解为一次将纹理输送到屏幕上的过程,(实际上引擎大多会使用如双缓冲,缓存这类的手段来优化这个过程,但在这 里我们只需要这样子认识就可以了),假设3个对象使用不同的材质/纹理,那么无疑会产生3个DrawCall
接下来我们的3个对象使用2个材质,A和B使用材质1,C使用材质2,这时候来看,应该是有2个DrawCall,或者3个DrawCall。 应该是2个DrawCall啊,为什么会有3个DrawCall???而且是有时候2个,有时候3个。我们按照上面的DrawCall分析流程来分析一 下:
1.渲染A,使用材质1
2.渲染B,使用材质1
3.渲染C,使用材质2
在这种情况下是2个DrawCall,在下面这种情况下,则是3个DrawCall
1.渲染A,使用材质1
2.渲染C,使用材质2
3.渲染B,使用材质1
因为我们没有控制好渲染顺序(或者说没有去特意控制),所以导致了额外的DrawCall,因为A和B不是一次性渲染完的,而是被C打断了,所以导致材质1被分为两次渲染
那么是什么在控制这个渲染顺序呢?首先在多个相机的情况下,U3D会根据相机的深度顺序进行渲染,在每个相机中,它会根据你距离相机的距离,由远到近进行渲染,在UI相机中,还会根据你UI对象的深度进行渲染
那么我们要做的就是,对要渲染的对象进行一次规划,正确地排列好它们,规则是,按照Z轴或者深度,对空间进行划分,然后确定好每个对象的Z轴和深度,让使用同一个材质的东西,尽量保持在这个空间内,不要让其他材质的对象进入这个空间,否则就会打断这个空间的渲染顺序
在这个基础上,更细的规则有:
场景中的东西,我们使用Z轴来进行空间的划分,例如背景层,特效层1,人物层,特效层2
NGUI中的东西,我们统一使用Depth来进行空间的划分
人物模型,当人物模型只是用一个材质,DrawCall只有1,但是用了2个以上的材质,DrawCall就会暴增(或许对材质的RenderQueue 进行规划也可以使DrawCall只有2个,但这个要拆分好才行),3D人物处于复杂3D场景中的时候,我们的空间规则难免被破坏,这只能在设计的时候尽 量去避免这种情况了
使用了多个材质的特效,在动画的过程中,往往会引起DrawCall的波动,在视觉效果可以接受的范围内,可以将特效也进行空间划分,假设这个特效是2D显示,那么可以使用Z轴来划分空间
二、
优化:
1. 更新不透明贴图的压缩格式为ETC 4bit,因为android市场的手机中的GPU有多种,
每家的GPU支持不同的压缩格式,但他们都兼容ETC格式,
2. 对于透明贴图,我们只能选择RGBA 16bit 或者RGBA 32bit。
3. 减少FPS,在ProjectSetting-> Quality中的
VSync Count 参数会影响你的FPS,EveryVBlank相当于FPS=60,EverySecondVBlank = 30;
这两种情况都不符合游戏的FPS的话,我们需要手动调整FPS,首先关闭垂直同步这个功能,然后在代码的Awake方法里手动设置FPS(Application.targetFrameRate = 45;)
降低FPS的好处:
1)省电,减少手机发热的情况;
2)能都稳定游戏FPS,减少出现卡顿的情况。
4. 当我们设置了FPS后,再调整下Fixed timestep这个参数,
这个参数在ProjectSetting->Time中,目的是减少物理计算的次数,来提高游戏性能。
5. 尽量少使用Update LateUpdate FixedUpdate,这样也可以提升性能和节省电量。
多使用事件(不是SendMessage,使用自己写的,或者C#中的事件委托)。
6. 待机时,调整游戏的FPS为1,节省电量。
7. 图集大小最好不要高于1024,否则游戏安装之后、低端机直接崩溃、原因是手机系统版本低于2.2、超过1000的图集无法读取、导致。
2.2 以上没有遇见这个情况。
注意手机的RAM 与 ROM、小于 512M的手机、直接放弃机型适配。
VSCount 垂直同步
中新建一个场景空的时候,帧速率(FPS总是很低),大概在60~70之间。
一直不太明白是怎么回事,现在基本上明白了。我在这里解释一下原因,如有错误,欢迎指正。
在Unity3D中当运行场景打开Profiler的时候,我们会看到VSync 这一项占了很大的比重。
这个是什么呢,这个就是垂直同步,稍后再做解释。
我们可以关闭VSync来提高帧速率,选择edit->project settings->Quality。

在右侧面板中可以找到VSync Count,把它选成Don't Sync。
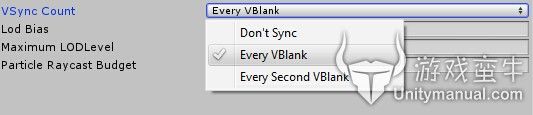
这就关闭了VSync(垂直同步),现在在运行场景看看,帧速率是不是提高很多。
现在来说说什么是垂直同步,要知道什么是垂直同步,必须要先明白显示器的工作原理,
显示器上的所有图像都是一线一线的扫描上去的,无论是隔行扫描还是逐行扫描,
显示器都有两种同步参数——水平同步和垂直同步。
什么叫水平同步?什么叫垂直同步?
垂直和水平是CRT中两个基本的同步信号,水平同步信号决定了CRT画出一条横越屏幕线的时间,
垂直同步信号决定了CRT从屏幕顶部画到底部,再返回原始位置的时间,
而恰恰是垂直同步代表着CRT显示器的刷新率水平。
为什么关闭垂直同步信号会影响游戏中的FPS数值?
如果我们选择等待垂直同步信号(也就是我们平时所说的垂直同步打开),
那么在游戏中或许强劲的显卡迅速的绘制完一屏的图像,但是没有垂直同步信号的到达,
显卡无法绘制下一屏,只有等85单位的信号到达,才可以绘制。
这样FPS自然要受到操作系统刷新率运行值的制约。
而如果我们选择不等待垂直同步信号(也就是我们平时所说的关闭垂直同步),那么游戏中作完一屏画面,
显卡和显示器无需等待垂直同步信号就可以开始下一屏图像的绘制,自然可以完全发挥显卡的实力。
但是不要忘记,正是因为垂直同步的存在,才能使得游戏进程和显示器刷新率同步,使得画面更加平滑和稳定。
取消了垂直同步信号,固然可以换来更快的速度,但是在图像的连续性上势必打折扣。
这也正是很多朋友抱怨关闭垂直后发现画面不连续的理论原因。
合并材质球unity 3d中每倒入一次模型就多一个材质球,可我的这些模型都是共用一张贴图的就想共用一个材质球,所以每次都要删除再附上,很麻烦。怎么才能合并这些材质球?
采用TexturePacking吧
1、遍历gameobject,取出material,并根据shader来将material分类
2、调用Unity自带的PackTextures函数来合并每个shader分类中的material所对应的textures(PackTextures函数有缺陷,不过可以将就用)
3、根据合并的大的texture来更新原有模型的texture、material已经uv坐标值。
需要注意的是:需要合并的纹理应该是物体在场景中距离相近的,如果物体在场景中的距离较远,
则不建议合并纹理,因为这样做很有可能非但起不到优化的作用,反而降低了运行效率。
mesh合并
分为2种方式合并
1.自带的合并必须勾选静态。
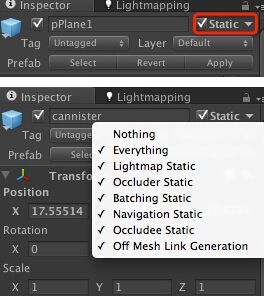
所有被勾选了“Static”的GameObject,其中的Mesh Filter中的mesh都会被合并到 "Combined Mesha (root: scene)" 中
2.也可以用脚本来合并mesh 。
[C#] 纯文本查看 复制代码
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 |
|
1. 先在 Unity 中建立 空物件 ( Empty )
2. 再创建2个 Cube 方块,并放入 空物件底下 (可以改成你自己的模型)
3. 把 MyClass 代码丟进 空物件上 。
4. (可选) 建立一个 Material 材质,并且丢进 空物件上
5. 执行
前
后
========================================分割线====================================
- 角色Material数量
2-3个
- 骨骼数量
小于30个
- 面片数量
300-1500
- 一般角色应该没有IK结点
这是因为角色的动作大多数都是事先设定好的,并不需要经过IK操作来进行实时计算(Rogdoll除外),所以在模型导入时,不要将IK结点一起导入。
2、静态实体
- 不要附加 Component
在静态实体上附加Animation部件虽然对结果没有影响,但却会增加一定的CPU开销来调用这一组件,所以尽量去掉该组件。
- 网格顶点数
小于500
- UV值范围尽量不要超过(0, 1)区间
尽量保证UV值不越界,这对于将来的纹理拼合优化很有帮助。
3、地形
- 地形的分辨率大小
长宽均尽量小于257。这是因为地形太大,会造成大量顶点数据,给你的内存带宽造成一定的影响,在目前的ios设备中,内存带宽是非常有限的,需要尽量节省。同时,如果用Unity自带的地形,一定也要使用Occlusion Culling,因为Unity的刷地形工具虽然方便,但却是framekiller,刷过之后,你会发现drawcall增加的非常多。
- 混合纹理数量
不要超过4。地形的混合操作是很耗时的,应该尽量避免。能合并的纹理尽量合并。
4、纹理
- 纹理格式
建议png或tga。不用转成ios硬件支持的PVRTC格式,因为Unity在发布时会帮你自动转的。
- 纹理尺寸
长宽小于1024。同时应该尽可能地小,够用就好,以保证纹理对内存带宽的影响达到最小。
- 支持Mipmap
建议生成Mipmap。虽然这种做法会增加一些应用程序的大小,但在游戏运行时,系统会根据需求应用Mipmap来渲染,从而减少内存带宽。
- 检查Alpha值
如果纹理的alpha通道均为1,则用RGB的24位纹理来代替RGBA的32位纹理。(据说Unity内部会进行自动检测)
5、光源
- 光源“Important”个数
建议1个,一般为方向光。“Important”个数应该越小越少。个数越多,drawcall越多。
- Pixel Light数目
1-2个。
6、粒子特效
- 屏幕上的最大粒子数
建议小于200个粒子。
- 每个粒子发射器发射的最大粒子数
建议不超过50个。
- 粒子大小
如果可以的话,粒子的size应该尽可能地小。因为Unity的粒子系统的shader无论是alpha test还是alpha blending都是一笔不小的开销。同时,对于非常小的粒子,建议粒子纹理去掉alpha通道。
- 尽量不要开启粒子的碰撞功能。
非常耗时。
7、音频
- 游戏中播放时间较长的音乐(如背景音乐)
使用.ogg或.mp3的压缩格式。
- 较短音乐(如枪声)
使用.wav和.aif的未压缩音频格式。
8、相机
- 裁剪平面
将远平面设置成合适的距离。远平面过大会将一些不必要的物体加入渲染,降低效率。
- 根据不同的物体设置不同的远裁剪平面
Unity提供了可以根据不同的layer来设置不同的view distance,所以我们可以实现将物体进行分层,大物体层设置的可视距离大些,而小物体层可以设置地小些,另外,一些开销比较大的实体(如粒子系统)可以设置得更小些等等。
9、碰撞
- 尽量不用MeshCollider
如果可以的话,尽量不用MeshCollider,以节省不必要的开销。如果不能避免的话,尽量用减少Mesh的面片数,或用较少面片的代理体来代替。
10、其他
- Drawcall
尽可能地减少Drawcall的数量。IOS设备上建议不超过100。减少的方法主要有如下几种:Frustum Culling,Occlusion Culling,Texture Packing。Frustum Culling是Unity内建的,我们需要做的就是寻求一个合适的远裁剪平面;Occlusion Culling,遮挡剔除,Unity内嵌了Umbra,一个非常好OC库。但Occlusion Culling也并不是放之四海而皆准的,有时候进行OC反而比不进行还要慢,建议在OC之前先确定自己的场景是否适合利用OC来优化;Texture Packing,或者叫Texture Atlasing,是将同种shader的纹理进行拼合,根据Unity的static batching的特性来减少draw call。建议使用,但也有弊端,那就是一定要将场景中距离相近的实体纹理进行拼合,否则,拼合后很可能会增加每帧渲染所需的纹理大小,加大内存带宽的负担。这也就是为什么会出现“DrawCall降了,渲染速度也变慢了”的原因。
- 非运动物体尽量打上Static标签
Unity在运行时会对static物体进行自动优化处理,所以应该尽可能将非运行实体勾上static标签。
- 场景中尽可能地使用prefab
尽可能地使用prefab的实例化物体,以降低内存带宽的负担。检查实体的PrefabType,尽量将其变成PrefabInstance,而不是ModelPrefabInstance。
========================================分割线====================================
移动平台相对于PC机,具有体积小,计算弱,带宽少的特点。
因此做手机游戏的开发,优化的方向,与力度对比PC游戏都有所区别。
必须要做到优化流程,合理利用资源。
目前在手机上面,还不能够像PC游戏那样追求高质量渲染效果,为了让手机不那么容易发烫,还要控制cpu,gpu,不能让他们全速运算。
材质方面:
纹理方面,建议使用压缩纹理,
上面使用ETC1,苹果上面使用PVRTC。
UV坐标控制在0到1之间,人物模型面数控制在1500内,骨骼控制在30个以内。
场景中使用一个主光(不能再多了)。
尽量减少alphaTest和alphaBlend材质的使用。在手机上,这是很杀效率的。
骨骼动画方面:
在动画方面可以考虑不使用插值,固定的帧率的动画。
如果要做插值,考虑使用四元数(表示旋转)和向量(表示位移)来做插值。
四元数做插值速度比矩阵来的快,Slerp提供了平滑插值。
========================================分割线====================================
优化的常规技巧
剖析你的游戏。
不要花费时间来优化那些晦涩的代码或者缩减图形文件的大小,除非这是你游戏的瓶颈。
第一次剖析你的游戏将会使你发现你游戏的瓶颈。Apple's Shark是一个很好的用来剖析基于OpenGL的程序的工具。
再次剖析你的游戏。
优化之后不要忘记再剖析一次你的游戏,这样可以检查你所做的优化是否达到了预期的效果。
当然,这样做也可能会使你发现更多的瓶颈。
流程第一、性能第二。花费时间来使你游戏的创建尽可能地流畅。
尽可能快地修正游戏中的错误将会使你后期更容易优化你的游戏。
在Scene View中测试场景。
这样做将会使你清楚了解这个场景中的物体或者附加在物体上的脚本是否降低了游戏性能。
如果Scene View反应迟钝,那么有可能是图形方面的原因,如果Scene View反应不迟钝,那么瓶颈可能出在脚本或者物理系统上。
禁用指定游戏物体。
在play模式下,尝试禁用并启用游戏物体来排查出游戏慢的原因。
网格
如果可能的话,把相邻的物体(网格)合并为一个只有一个材质的物体(网格)。比如,你的游戏中包含一个桌子,上面有一堆东西,你完全可以在3D程序中将它们合并在一起(这可能也需要你将这些物体的纹理合并为一个大的纹理集)。减少需要渲染的物体的数量可以极大地提高游戏性能。
不要有不必要的网格。
如果你的游戏场景中有一个人物,那么他应该是一个网格。如果你有一个船,那么它也应该只是一个网格。
每一个网格只用一种材质。
使用极少的面数的网格(比如500个多边形以下)。
最好把你人物的三角面数量控制在1500-2000个之间。
这个数量可以说是游戏质量和性能之间一个均衡值。如果你的模型有四边形,那么在导入模型的时候,引擎将会把每个四边形变为两个三角形。
光照
像素光。
像素光可以让你的游戏看起来效果很牛逼,但是不要使用过多的像素光。
在你的游戏中可以使用质量管理器来调节像素光的数量来取得一个性能和质量的均衡点.
性能占用顺序:聚光灯>点光源>平行光。
一个好的点亮场景的方法就是先得到你想要的效果,然后看看哪些光更重要;
在保持光效的前提下看看哪些光可以去掉。
点光源和聚光灯只影响它们范围内的网格。
如果一个网格处于点光源或者聚光灯的照射范围之外,并且光源的attenuate开关是打开的,那么这个网格将不会被光源所影响,这样就可以节省性能开销。
这样做理论上来讲可以使用很多小的点光源而且依然能有一个好的性能,因为这些光源只影响一小部分物体。
一个网格在有8个以上光源影响的时候,只响应前8个最亮的光源。
贴图
在外观不变的前提下,贴图大小越小越好。
如果你的显卡的显存不够大的话,你游戏中的贴图将会被转存到系统内存中,在显卡调用它们的时候再传到显卡中。
对于比较新的电脑来说,内存和显卡之间有足够的带宽来达到一个很好的性能;
如果你很无耻地用了巨多的大图片的话,在低显存的电脑上运行你的游戏的时候,你的游戏必然会挂掉。
倒是没有必要在图形编辑软件中调整贴图的大小。你可以在unity导入贴图的时候进行调整。
不要使用低质量的图片。
在小播放界面的游戏中使用低质量的jpeg图片或者低色彩的png图片亦或是gif图片没什么问题。
在发布游戏的时候,引擎会自动压缩这些图片,多重压缩和解压将会降低图片的质量,所以最好保持贴图文件的分辨率为原始分辨率。
这样就会减少多重压缩和解压所导致的图片失真现象。
Shaders
多重效果的shader就比看起来样式很单一的shader要更耗费资源。
同样在一个拥有贴图和光反射的物体上,使用VertexLit Diffuse shader无疑是最省资源的。
========================================分割线====================================
在美术制作场景的过程中,会使用到大量的粒子系统。
比如场景中的火把。在我们的一个地下城场景中,美术们放置了大量的火把。整个场景中的各个地方,有100来个火把。
unity中,在摄像机范围外的粒子系统虽然不会被绘制。
但是update是一直持续的。这也就意味着,这100多个火把,不论是否可见都在更新。
这个设计应该是很不合理的,在我看过的其他引擎中,都会有一个开关,来控制不可见的粒子系统是否需要update。
有的粒子系统在不可见的时候需要更新,比如爆炸。有的不需要更新,比如火堆火把。
为了避免不必要的update开销,尤其是最后游戏是要发布到页游平台(web player只能使用一个cpu的核)。
于是写了一个脚本,控制不可见的粒子系统就不更新。
该脚本主要是用到了2个MonoBehaviour的函数。
OnBecameInvisible() 当变为不可见 和 OnBecameVisible() 当变成可见。
要这2个函数起作用的前提是,该GameObject绑定了MeshRender组件。
所以,我们要在粒子系统的GameObject放置在一个GameObject 下,且给该GameObject绑定一个MeshRender 与 MeshFilter。
MeshFilter中的mesh可以随便找个cube。
在Start() 的时候,把最GameObject的scale设置为很小,以保证该cube不被看见。
其实遍历所有的child,把active设置为false。
在OnBecameVisible 中 遍历所有child,把active设置为true。
在OnBecameInvisible中 遍历所有child,把active设置为false。
========================================分割线====================================
Unity 性能优化 Draw Call
Unity(或者说基本所有图形引擎)生成一帧画面的处理过程大致可以这样简化描述:引擎首先经过简单的可见性测试,确定摄像机可以看到的物体,然后把这些物体的顶点(包括本地位置、法线、UV等),索引(顶点如何组成三角形),变换(就是物体的位置、旋转、缩放、以及摄像机位置等),相关光源,纹理,渲染方式(由材质/Shader决定)等数据准备好,然后通知图形API——或者就简单地看作是通知GPU——开始绘制,GPU基于这些数据,经过一系列运算,在屏幕上画出成千上万的三角形,最终构成一幅图像。
在Unity中,每次引擎准备数据并通知GPU的过程称为一次Draw Call。这一过程是逐个物体进行的,对于每个物体,不只GPU的渲染,引擎重新设置材质/Shader也是一项非常耗时的操作。因此每帧的Draw Call次数是一项非常重要的性能指标,对于iOS来说应尽量控制在20次以内,这个值可以在编辑器的Statistic窗口看到。
Unity内置了Draw Call Batching技术,从名字就可以看出,它的主要目标就是在一次Draw Call中批量处理多个物体。只要物体的变换和材质相同,GPU就可以按完全相同的方式进行处理,即可以把它们放在一个Draw Call中。Draw Call Batching技术的核心就是在可见性测试之后,检查所有要绘制的物体的材质,把相同材质的分为一组(一个Batch),然后把它们组合成一个物体(统一变换),这样就可以在一个Draw Call中处理多个物体了(实际上是组合后的一个物体)。
但Draw Call Batching存在一个缺陷,就是它需要把一个Batch中的所有物体组合到一起,相当于创建了一个与这些物体加起来一样大的物体,与此同时就需要分配相应大小的内存。这不仅会消耗更多内存,还需要消耗CPU时间。特别是对于移动的物体,每一帧都得重新进行组合,这就需要进行一些权衡,否则得不偿失。但对于静止不动的物体来说,只需要进行一次组合,之后就可以一直使用,效率要高得多。
Unity提供了Dynamic Batching和Static Batching两种方式。Dynamic Batching是完全自动进行的,不需要也无法进行任何干预,对于顶点数在300以内的可移动物体,只要使用相同的材质,就会组成Batch。Static Batching则需要把静止的物体标记为Static,然后无论大小,都会组成Batch。如前文所说,Static Batching显然比Dynamic Batching要高效得多,于是,Static Batching功能是收费的……
要有效利用Draw Call Batching,首先是尽量减少场景中使用的材质数量,即尽量共享材质,对于仅纹理不同的材质可以把纹理组合到一张更大的纹理中(称为Texture Atlasing)。然后是把不会移动的物体标记为Static。此外还可以通过CombineChildren脚本(Standard Assets/Scripts/Unity Scripts/CombineChildren)手动把物体组合在一起,但这个脚本会影响可见性测试,因为组合在一起的物体始终会被看作一个物体,从而会增加GPU要处理的几何体数量,因此要小心使用。
对于复杂的静态场景,还可以考虑自行设计遮挡剔除算法,减少可见的物体数量同时也可以减少Draw Call。
总之,理解Draw Call和Draw Call Batching原理,根据场景特点设计相应的方案来尽量减少Draw Call次数才是王道,其它方面亦然。
Draw Call Batching (绘制调用批处理)
To draw an object on the screen, the engine has to issue a draw call to the graphics API (OpenGL ES in the case of iOS). Every single draw call requires a significant amount of work on the part of the graphics API, causing significant performance overhead on the CPU side.
在屏幕上渲染物体,引擎需要发出一个绘制调用来访问图形API(iOS系统中为OpenGL ES)。
每个绘制调用需要进行大量的工作来访问图形API,从而导致了CPU方面显著的性能开销。
Unity combines a number of objects at runtime and draws them together with a single draw call. This operation is called "batching". The more objects Unity can batch together, the better rendering performance you will get.
Unity在运行时可以将一些物体进行合并,从而用一个绘制调用来渲染他们。这一操作,我们称之为“批处理”。
一般来说,Unity批处理的物体越多,你就会得到越好的渲染性能。
Built-in batching support in Unity has significant benefit over simply combining geometry in the modeling tool (or using theCombineChildren script from the Standard Assets package). Batching in Unity happensafter visibility determination step. The engine does culling on each object individually, and the amount of rendered geometry is going to be the same as without batching. Combining geometry in the modeling tool, on the other hand, prevents effecient culling and results in much higher amount of geometry being rendered.
Unity中内建的批处理机制所达到的效果要明显强于使用几何建模工具(或使用Standard Assets包中的CombineChildren脚本)的批处理效果。
这是因为,Unity引擎的批处理操作是在物体的可视裁剪操作之后进行的。
Unity先对每个物体进行裁剪,然后再进行批处理,这样可以使渲染的几何总量在批处理前后保持不变。
但是,使用几何建模工具来拼合物体,会妨碍引擎对其进行有效的裁剪操作,从而导致引擎需要渲染更多的几何面片。
Materials
材质
Only objects sharing the same material can be batched together. Therefore, if you want to achieve good batching, you need to share as many materials among different objects as possible.
只有拥有相同材质的物体才可以进行批处理。
因此,如果你想要得到良好的批处理效果,你需要在程序中尽可能地复用材质和物体。
If you have two identical materials which differ only in textures, you can combine those textures into a single big texture - a process often calledtexture atlasing. Once textures are in the same atlas, you can use single material instead.
如果你的两个材质仅仅是纹理不同,那么你可以通过 纹理拼合 操作来将这两张纹理拼合成一张大的纹理。
一旦纹理拼合在一起,你就可以使用这个单一材质来替代之前的两个材质了。
If you need to access shared material properties from the scripts, then it is important to note that modifyingRenderer.material will create a copy of the material. Instead, you should useRenderer.sharedMaterial to keep material shared.
如果你需要通过脚本来访问复用材质属性,那么值得注意的是改变Renderer.material将会造成一份材质的拷贝。
因此,你应该使用Renderer.sharedMaterial来保证材质的共享状态。
Dynamic Batching
动态批处理
Unity can automatically batch moving objects into the same draw call if they share the same material.
如果动态物体共用着相同的材质,那么Unity会自动对这些物体进行批处理。
Dynamic batching is done automatically and does not require any additional effort on your side.
动态批处理操作是自动完成的,并不需要你进行额外的操作。
Tips:
提醒:
1、 Batching dynamic objects has certain overheadper vertex, so batching is applied only to meshes containing less than900 vertex attributes in total.
批处理动态物体需要在每个顶点上进行一定的开销,所以动态批处理仅支持小于900顶点的网格物体。
2、 If your shader is using Vertex Position, Normal and single UV, then you can batch up to 300 verts and if your shader is using Vertex Position, Normal, UV0, UV1 and
Tangent, then only 180 verts.
Please note: attribute count limit might be changed in future
如果你的着色器使用顶点位置,法线和UV值三种属性,那么你只能批处理300顶点以下的物体;
如果你的着色器需要使用顶点位置,法线,UV0,UV1和切向量,那你只
能批处理180顶点以下的物体。
请注意:属性数量的限制可能会在将来进行改变。
4、 Don't use scale. Objects with scale (1,1,1) and (2,2,2) won't batch.
不要使用缩放尺度(scale)。分别拥有缩放尺度(1,1,1)和(2,2,2)的两个物体将不会进行批处理。
5、 Uniformly scaled objects won't be batched with non-uniformly scaled ones.
统一缩放尺度的物体不会与非统一缩放尺度的物体进行批处理。
Objects with scale (1,1,1) and (1,2,1) won't be batched. On the other hand (1,2,1) and (1,3,1) will be.
使用缩放尺度(1,1,1)和 (1,2,1)的两个物体将不会进行批处理,但是使用缩放尺度(1,2,1)和(1,3,1)的两个物体将可以进行批处理。
6、 Using different material instances will cause batching to fail.
使用不同材质的实例化物体(instance)将会导致批处理失败。
7、 Objects with lightmaps have additional (hidden) material parameter: offset/scale in lightmap, so lightmapped objects won't be batched (unless they point to same
portions of lightmap)
拥有lightmap的物体含有额外(隐藏)的材质属性,比如:lightmap的偏移和缩放系数等。所以,拥有lightmap的物体将不会进行批处理(除非他们指向lightmap的同一
部分)。
8、 Multi-pass shaders will break batching. E.g. Almost all unity shaders supports several lights in forward rendering, effectively doing additional pass for them
多通道的shader会妨碍批处理操作。比如,几乎unity中所有的着色器在前向渲染中都支持多个光源,并为它们有效地开辟多个通道。
9、 Using instances of a prefab automatically are using the same mesh and material.
预设体的实例会自动地使用相同的网格模型和材质。
Static Batching
静态批处理
Static batching, on the other hand, allows the engine to reduce draw calls for geometry of any size (provided it does not move and shares the same material). Static batching is significantly more efficient than dynamic batching. You should choose static batching as it will require less CPU power.
相对而言,静态批处理操作允许引擎对任意大小的几何物体进行批处理操作来降低绘制调用(只要这些物体不移动,并且拥有相同的材质)。因此,静态批处理比动态批处理更加有效,你应该尽量低使用它,因为它需要更少的CPU开销。
In order to take advantage of static batching, you need explicitly specify that certain objects are static and willnot move, rotate or scale in the game. To do so, you can mark objects as static using the Static checkbox in the Inspector:
为了更好地使用静态批处理,你需要明确指出哪些物体是静止的,并且在游戏中永远不会移动、旋转和缩放。想完成这一步,你只需要在检测器(Inspector)中将Static复选框打勾即可,如下图所示:
Using static batching will require additional memory for storing the combined geometry. If several objects shared the same geometry before static batching, then a copy of geometry will be created for each object, either in the Editor or at runtime. This might not always be a good idea - sometimes you will have to sacrifice rendering performance by avoiding static batching for some objects to keep a smaller memory footprint. For example, marking trees as static in a dense forest level can have serious memory impact.
使用静态批处理操作需要额外的内存开销来储存合并后的几何数据。在静态批处理之前,如果一些物体共用了同样的几何数据,那么引擎会在编辑以及运行状态对每个物体创建一个几何数据的备份。这并不总是一个好的想法,因为有时候,你将不得不牺牲一点渲染性能来防止一些物体的静态批处理,从而保持较少的内存开销。比如,将浓密森里中树设为Static,会导致严重的内存开销。
Static batching is only available in Unity iOS Advanced.
静态批处理目前只支持Unity iOS Advanced。
备注:最近一直在研究Unity3D的性能优化问题,这段时间可能会多翻译这方面的文章。
前两天,MadFinger,就是当今iOS与Android上画质最牛逼闪闪的游戏之一——ShadowGun的开发商,令人惊异地放出了一个ShadowGun的样例关卡以及若干可免费使用的Shader,国外同行们的分享精神真的是令人赞叹不已。原文在这里,以下是我的一些摘录和笔记。
首先是一些优化常识。针对图形方面的优化主要包括三角形数量,纹理所占内存,以及Shader,前两项基本没什么好讲的,针对设备机能的限制制定相应的指标即可,所以Shader就成为了图形性能优化的关键。
Alpha blending
在Unity官方文档中讲,由于硬件原因,在iOS设备上使用alpha-test会造成很大的性能开销,应尽量使用alpha-blend代替。这里提到,在同屏使用alpha-blend的面数,尤其是这些面所占屏幕面积的大小,对性能也会造成很大影响。原因是使用alpha-blend的面会造成overdraw的增加,这尤其对低性能设备的影响很大。不过没有购买Pro版,没有Occlusion Culling功能的话,就不必顾虑这一问题了,反正overdraw是必然的。
复杂的Per-pixel shader
Per-pixel shader即Fragment shader,顾名思义是要对每个渲染到屏幕上的像素做处理的shader,如果per-pixel shader比较复杂且需要处理的像素很多时,也就是使用该shader的面占屏幕面积很大时,对性能的影响甚至要超过alpha blending。因此复杂的per-pixel shader只适用于小物体。
下面是对几个Shader的逐一讲解:
Environment specular maps(Shader Virtual Gloss Per Vertex Additive)
Specular map通常都是利用贴图的alpha通道来定义物体表面的光滑程度(反光度),这个shader的特点是per-vertex计算反光度的,有着相当不错的效果的同时比per-pixel的shader性能要高得多。这个shader很适用于关卡环境等占很大区域的模型。
经过优化的动态角色光照和阴影(Light probes和BRDF Shader)
传统的Lightmaps无法支持动态物体,对此Unity提供了Light probes技术,预先把动态物体的光照信息保存在代理对象(即Light probes)中,运行时动态物体从距离最近的Probe中获取光照信息。
Unity本身还提供了一个效果非常棒的专为移动设备优化过的角色Shader,支持Diffuse、Specular和Normal maps,并通过一个特殊的脚本生成贴图用于模仿BRDF光照效果。最终产生的效果堪比次时代大作中的角色光影效果。
雾和体积光(Shader Blinking Godrays)
目前在移动设备上要开启真正的雾效基本不可行,ShadowGun的方案是通过简单的网格+透明贴图(称为雾面)来模拟雾效。在玩家靠近时,雾面逐渐变淡,同时fog plane的顶点也会移开(即使完全透明的alpha面也会消耗很多渲染时间)。
使用这个Shader的网格需要经过处理:
顶点的alpha值用于决定顶点是否可以移动(在例子中0为不可动,1为可动)。
顶点法线决定移动的方向
然后Shader通过计算与观察者的距离来控制雾面的淡入/淡出。
这个Shader还可以用来做体积光和其它一些alpha效果。
飞机坠毁的浓烟效果(Shader Scroll 2 Layers Sine Alpha-blended)
通过粒子产生浓烟的代价太高,所以ShadowGun中使用了网格+贴图动画来制作这个效果。通过混合两层贴图并让它们交错移动来产生动画效果。其中顶点alpha值用于让网格的边缘看起来比较柔和,同时使用顶点颜色来模拟从火焰到烟雾的过渡效果。
带动态效果的天空盒(Shader Scroll 2 Layers Multiplicative)
通过两张贴图的混合和移动产生云的动态效果。
旗帜和衣服的飘动效果(Shader Lightmap + Wind)
同样利用顶点alpha值决定哪些顶点可以移动,然后shader的参数用于调整摆动的方向和速度。
=======================分割线========================
一、程序方面
01、务必删除脚本中为空或不需要的默认方法;
02、只在一个脚本中使用OnGUI方法;
03、避免在OnGUI中对变量、方法进行更新、赋值,输出变量建议在Update内;
04、同一脚本中频繁使用的变量建议声明其为全局变量,脚本之间频繁调用的变量或方法建议声明为全局静态变量或方法;
05、不要去频繁获取组件,将其声明为全局变量;
06、数组、集合类元素优先使用Array,其次是List;
07、脚本在不使用时脚本禁用之,需要时再启用;
08、可以使用Ray来代替OnMouseXXX类方法;
09、需要隐藏/显示或实例化来回切换的对象,尽量不要使用SetActiveRecursively或active,而使用将对象远远移出相机范围和移回原位的做法;
10、尽量少用模运算和除法运算,比如a/5f,一定要写成a*0.2f。
11、对于不经常调用或更改的变量或方法建议使用Coroutines & Yield;
12、尽量直接声明脚本变量,而不使用GetComponent来获取脚本;
iPhone
13、尽量使用整数数字,因为iPhone的浮点数计算能力很差;
14、不要使用原生的GUI方法;
15、不要实例化(Instantiate)对象,事先建好对象池,并使用Translate“生成”对象;
二、模型方面
01、合并使用同贴图的材质球,合并使用相同材质球的Mesh;
02、角色的贴图和材质球只要一个,若必须多个则将模型离分离为多个部分;
02、骨骼系统不要使用太多;
03、当使用多角色时,将动画单独分离出来;
04、使用层距离来控制模型的显示距离;
05、阴影其实包含两方面阴暗和影子,建议使用实时影子时把阴暗效果烘焙出来,不要使用灯光来调节光线阴暗。
06、少用像素灯和使用像素灯的Shader;
08、如果硬阴影可以解决问题就不要用软阴影,并且使用不影响效果的低分辨率阴影;
08、实时阴影很耗性能,尽量减小产生阴影的距离;
09、允许的话在大场景中使用线性雾,这样可以使远距离对象或阴影不易察觉,因此可以通过减小相机和阴影距离来提高性能;
10、使用圆滑组来尽量减少模型的面数;
11、项目中如果没有灯光或对象在移动那么就不要使用实时灯光;
12、水面、镜子等实时反射/折射的效果单独放在Water图层中,并且根据其实时反射/折射的范围来调整;
13、碰撞对效率的影响很小,但碰撞还是建议使用Box、Sphere碰撞体;
14、建材质球时尽量考虑使用Substance;
15、尽量将所有的实时反射/折射(如水面、镜子、地板等等)都集合成一个面;
16、假反射/折射没有必要使用过大分辨率,一般64*64就可以,不建议超过256*256;
17、需要更改的材质球,建议实例化一个,而不是使用公共的材质球;
18、将不须射线或碰撞事件的对象置于IgnoreRaycast图层;
19、将水面或类似效果置于Water图层
20、将透明通道的对象置于TransparentFX图层;
21、养成良好的标签(Tags)、层次(Hieratchy)和图层(Layer)的条理化习惯,将不同的对象置于不同的标签或图层,三者有效的结合将很方便的按名称、类别和属性来查找;
22、通过Stats和Profile查看对效率影响最大的方面或对象,或者使用禁用部分模型的方式查看问题到底在哪儿;
23、使用遮挡剔除(Occlusion Culling)处理大场景,一种较原生的类LOD技术,并且能够“分割”作为整体的一个模型。
三、其它
场景中如果没有使用灯光和像素灯,就不要使用法线贴图,因为法线效果只有在有光源(Direct Light/Point Light/Angle Light/Pixel Light)的情况下才有效果。
C#语言 优化
一、用属性代替可访问的字段
1、.NET数据绑定只支持数据绑定,使用属性可以获得数据绑定的好处;
2、在属性的get和set访问器重可使用lock添加多线程的支持。
二、readonly(运行时常量)和const(编译时常量)
1、const只可用于基元类型、枚举、字符串,而readonly则可以是任何的类型;
2、const在编译时将替换成具体的常量,这样如果在引用中同时使用了const和readonly两种值,则对readonly的再次改变将会改变设计的初衷,这是需要重新编译所更改的程序集,以重新引用新的常量值。
3、const比readonly效率高,但失去了应用的灵活性。
三、is与as
1、两者都是在运行时进行类型的转换,as操作符只能使用在引用类型,而is可以使用值和引用类型;
2、通常的做法是用is判断类型,然后选择使用as或强类型转换操作符(用operater定义的转换)有选择地进行。
四、ConditionalAttribute代替#if #endif条件编译
1、ConditionalAttribute只用于方法级,对其他的如类型、属性等的添加都是无效的;而#if #endif则不受此限制;
2、ConditionalAttribute可以添加多个编译条件的或(OR)操作,而#if #endif则可以添加与(AND)[这里可以完全定义为另一个单独的符号];
3、ConditioanlAttribute定义可以放在一个单独的方法中,使得程序更为灵活。
五、提供ToString()方法
1、可以更友好的方式提供用户详细的信息;
2、使用IFormatter.ToString()方法提供更灵活的定制,如果添加IFormatProvider 和ICustomFormatter接口则更有意义的定制消息输出。
六、值和引用类型的区别
1、值类型不支持多态,适合存储应用程序操作的数据,而引用则支持多态,适用于定义应用程序的行为;
2、对于数组定义为值类型可以显著提高程序的性能;
3、值类型具有较少的堆内存碎片、内存垃圾和间接访问时间,其在方法中的返回是以复制的方式进行,避免暴露内部结构到外界;
4、值类型应用在如下的场景中:类型的职责主要是用于数据存储;公共接口完全由一些数据成员存取属性定义;永远没有子类;永远没有多态行为。
七、值类型尽可能实现为常量性和原子性的类型
1、使我们的代码更易于编写和维护;
2、初始化常量的三种策略:在构造中;工厂方法;构造一个可变的辅助类(如StringBuilder)。
八、确保0为值得有效状态
1、值类型的默认状态应为0;
2、枚举类型的0不应为无效的状态;在FlagsAttribute是应确保0值为有效地状态;
3、在字符串为为空时可以返回一个string.Empty的空字符串;
九、相等判断的多种表示关系
1、ReferenceEquals()判断引用相等,需要两个是引用同一个对象时方可返回true;
2、静态的Equals()方法先进性引用判断再进行值类型判断的;
3、对于引用类型的判断可以在使用值语义时使用重写Equals()方法;
4、重写Equals()方法时也应当重写GetHashCode()方法,同时提供operater==()操作。
十、理解GetHashCode()方法的缺陷
1、GetHashCode()仅应用在基于散列的集合定义键的散列值,如HashTable或Dictionary;
2、GetHashCode()应当遵循相应的三条规则:两个相等对象应当返回相同的散列码;应当是一个实例不变式;散列函数应该在所有的整数中产生一个随机的分布;
十一、优先使用foreach循环语句
1、foreach可以消除编译器对for循环对数组边界的检查;
2、foreach的循环变量是只读的,且存在一个显式的转换,在集合对象的对象类型不正确时抛出异常;
3、foreach使用的集合需要有:具备公有的GetEnumberator()方法;显式实现了IEnumberable接口;实现了IEnumerator接口;
4、foreach可以带来资源管理的好处,因为如果编译器可以确定IDisposable接口时可以使用优化的try…finally块;
十二、默认字段的初始化优于赋值语句
1、字段生命默认会将值类型初始化为0,引用类型初始化为null;
2、对同一个对象进行多次初始化会降低代码的执行效率;
3、将字段的初始化放到构造器中有利于进行异常处理。
十三、使用静态构造器初始化静态成员
1、静态构造器会在一个类的任何方法、变量或者属性访问之前执行;
2、静态字段同样会在静态构造器之前运行,同时静态构造器有利于异常处理。
十四、利用构造器链(在.NET 4.0已经用可选参数解决了这个问题)
1、用this将初始化工作交给另一个构造器,用base调用基类的构造器;
2、类型实例的操作顺序是:将所有的静态字段都设置为0;执行静态字段初始化器;执行基类的静态构造器;执行当前类型的静态构造器;
将所有的实例字段设置为0;执行实例字段初始化器;执行合适的基类实例构造器;执行当前类型的实例构造器。
十五、利用using和try/finally语句来清理资源
在IDisposable接口的Dispose()方法中用GC.SuppressFinalize()可通知垃圾收集器不再执行终结操作。
十六、尽量减少内存垃圾
1、分配和销毁一个对上的对象都要花费额外的处理器时间;
2、减少分配对象数量的技巧:经常使用的局部变量提升为字段;提供一个类,用于存储Singleton对象来表达特定类型的常用实例。
3、用StringBuilder进行复杂的字符串操作。
十七、尽量减少装箱和拆箱
1、关注一个类型到System.Object的隐式转换,同时值类型不应该被替换为System.Object类型;
2、使用接口而不是使用类型可以避免装箱,即将值类型从接口实现,然后通过接口调用成员。
十八、实现标准Dispose模式
1、使用非内存资源,它必须有一个终结器,垃圾收集器在完成没有终结其的内存对象后会将实现了终结器对象的添加到终结队列中,然后垃圾收集器会启动一个新的线程来运行这些对象上的终结器,这种防御性的变成方式是因为如果用户忘记了调用Dispose()方法,垃圾回收器总是会调用终结器方法的,这样可以避免出现非托管的内存资源不被释放引起内存泄漏的问题;
2、使用IDisposable.Dispose()方法需要做四个方面的工作:释放所有的非托管资源;释放所有的托管资源;设置一个状态标记来表示是否已经执行了Dispose();调用GC.SuppressFinalize(this)取消对象的终结操作;
3、为需要多态的类型添加一个受保护的虚方法Dispose(),派生类通过重写这个方法来释放自己的任务;
4、在需要IDisoposable接口的类型中,即使我们不需要一个终结器也应该实现一个终结器。
十九、定义并实现接口优于继承类型
1、不相关的类型可以共同实现一个共同的接口,而且实现接口比继承更容易;
2、接口比较稳定,他将一组功能封装在一个接口中,作为其他类型的实现合同,而基类则可以随着时间的推移进行扩展。
二十、明辨接口实现和虚方法重写
1、在基类中实现一个接口时,派生类需要使用new来隐藏对基类方法的使用;
2、可以将基类接口的方法申明为虚方法,然后再派生类中实现。
二十一、使用委托表达回调
1、委托对象本身不提供任何异常捕获,所以任何的多播委托调用都会结束整个调用链;
2、通过显示调用委托链上的每个委托目标可以避免多播委托仅返回最后一个委托的输出。
二十二、使用事件定义外部接口
1、应当声明为共有的事件,让编译器为我们创建add和renmove方法;
2、使用System.ComponentModel.EventHandlerList容器来存储各个事件处理器,在类型中包含大量事件时可以使用他来隐藏所有事件的复杂性。
二十三、避免返回内部类对象的引用
1、由于值类型对象的访问会创建一个该对象的副本,所以定义一个值类型的的属性完全不会改变类型对象内部的状态;
2、常量类型可以避免改变对象的状态;
3、定义接口将访问限制在一个子集中从而最小化对对象内部状态的破坏;
4、定义一个包装器对象来限制另一个对象的访问;
5、希望客户代码更改内部数据元素时可以实现Observer模式,以使对象可以对更改进行校验或相应。
二十四、声明式编程优于命令式编程
可以避免在多个类似的手工编写的算法中犯错误的可能性,并提供清晰和可读的代码。
二十五、尽可能将类型实现为可序列化的类型
1、类型表示的不是UI控件、窗口或者表单,都应使类型支持序列化;
2、在添加了NonSerializedAttribute的反序列化的属性时可以通过实现IDeserializationCallback的OnDeserialization()方法装入默认值;
3、在版本控制中可以使用ISerializable接口来进行灵活的控制,同时提供一个序列化的构造器来根据流中的数据初始化对象,在实现时还要求SerializationFormatter异常的许可。
4、如果需要创建派生类则需要提供一个挂钩方法供派生类使用。
二十六、使用IComparable和IComparer接口实现排序关系
1、IComparable接口用于为类型实现最自然的排序关系,重载四个比较操作符,可以提供一个重载版的CompareTo()方法,让其接受具体类型作为参数;
2、IComparer用于提供有别于IComparable的排序关系,或者为我们提供类型本身说没有实现的排序关系。
二十七、避免ICloneable接口
1、对于值类型永远不需要支持ICloneable接口使用默认的赋值操作即可;
2、对于可能需要支持ICloneable接口的基类,应该为其创造一个受保护的复制构造器,并应当避免支持IConeable接口。
二十八、避免强制转换操作符
通过使用构造器来代替转换操作符可以使转换工作变得更清晰,由于在转换后使用的临时对象,容易导致一些诡异的BUG。
二十九、只有当新版积累导致问题是才考虑使用new修饰符
三十、尽可能实现CLS兼容的程序集
1、创建一个兼容的程序集需要遵循两条规则:程序集中所有公有和受保护成员所使用的参数和返回值类型都必须与CLS兼容;任何与CLS不兼容的公有和受保护成员都必须有一个与CLS兼容的替代品;
2、可以通过显式实现接口来避开CLS兼容类型检查,及CLSCompliantAttribute不会检查私有的成员的CLS兼容性。
三十一、尽可能实现短小简洁的方法
1、JIT编译器以方法为单位进行编译,没有被调用的方法不会被JIT编译;
2、如果将较长的Switch中的Case语句的代码替换成一个一个的方法,则JIT编译器所节省的时间将成倍增加;
3、短小精悍的方法并选择较少的局部变量可以获得优化的寄存器使用;
4、方法内的控制分支越少,JIT编译器越容易将变量放入寄存器。
三十二、尽可能实现小尺寸、高内聚的程序集
1、将所有的公有类以及共用的基类放到一些程序集中,把为公有类提供功能的工具类也放入同样的程序集中,把相关的公有接口打包到他们自己的程序集中,最后处理遍布应用程序中水平位置的类;
2、原则上创建两种组件:一种为小而聚合、具有某项特定功能的程序集,另一种为大而宽、包含共用功能的程序集。
三十三、限制类型的可见性
1、使用接口来暴露类型的功能,可以使我们更方便地创建内部类,同时又不会限制他们在程序集外的可用性;
2、向外暴露的公有类型越少,未来扩展和更改实现所拥有的选择就越多。
三十四、创建大粒度的Web API
这是在机器之间的交易的频率和载荷都降到最低,将大的操作和细粒度的执行放到服务器执行。
三十五、重写优于事件处理器
1、一个事件处理器抛出异常,则事件链上的其他处理器将不会被调用,而重写的虚方法则不会出现这种情况;
2、重写要比关联事件处理器高效得多,事件处理器需要迭代整个请求列表,这样占用了更多的CPU时间;
3、事件能在运行时响应,具有更多的灵活性,可以对同一个事件关联多个响应;
4、通行的规则是处理一个派生类的事件是,重写方式较好。
三十六、合理使用.NET运行时诊断
1、System.Diagnostics.Debug\Trace\EventLog为运行时提供了程序添加诊断信息所需要的所有工具,EventLog提供入口时的应用程序能写到系统事件日志中;
2、最后不要写自己的诊断库,.NET FCL 已经拥有了我们需要的核心库。
三十七、使用标准配置机制
1、.NET框架的System.Windows.Application类为我们定义了建立通用配置路径的属性;
2、Application.LocalAppDataPath和Application.userDataPath 会生成本地数据目录和用户数据的路径名;
3、不要在ProgramFiles和Windows系统目录中写入数据,这些位置需要更高的安全权限,不要指望用户拥有写入的权限。
三十八、定制和支持数据绑定
1、BindingMananger和CurrencyManager这两个对象实现了控件和数据源之间的数据传输;
2、数据绑定的优势:使用数据绑定要比编写自己的代码简单得多;应该将它用于文本数据项之外的范围-其他显示属性也可以被绑定;对于Windowos Forms 数据绑定能够处理多个控件同步的检查相关数据源;
3、在对象不支持所需的属性时可以通过屏蔽当前的对象然后添加一个想要的对象来支持数据绑定。
三十九、使用.NET验证
1、ASP.NET中有五种控件来验证有效性,可以用CustomValidator派生一个新类来增加自己的认证器;
2、Windows验证需要子System.Windows.Forms.Control.Validating些一个事件处理器。
四十、根据需要选用恰当的集合
1、数组有两个比较明显的缺陷:不能动态的调整大小;调整大小非常耗时;
2、ArrayList混合了一维数组和链表的特征,Queue和Stack是建立在Array基础上的特殊数组;
3、当程序更加灵活的添加和删除项时,可以使更加健壮的集合类型,当创建一个模拟集合的类时,应当为其实现索引器和IEnumberable接口。
四十一、DataSet优于自定义结构
1、DataSet有两个缺点个:使用XML序列化机制的DataSet与非.NET 代码之间的交互不是很好;DataSet是一个非常通用的容器;
2、强类型的DataSet打破了更多的设计规则,其获得的开发效率要远远高于自己编写的看上去更为优雅的设计。
四十二、利用特性简化反射
通过设计和实现特性类,强制开发人员用他们来声明可被动态使用的类型、方法和属性,可以减少应用程序的运行时错误,提高软件的用户满意度。
四十三、避免过度使用反射
1、Invoke成员使用的参数和返回值都是System.Object,在运行时进行类型的转换,但出现问题的可能性也变得更多了;
2、接口使我们可以得到一个更为清晰、也更具可维护性的系统,反射式一个很强大的晚期绑定机制.NET框架使用它来实现Windows控件和Web控件的数据绑定。
四十四、为应用程序创建特定的异常类
1、需要不同的异常类的唯一原因是让用户在编写catch处理器时能够方便地对不同的错误采取不同的做法;
2、可能有不同的修复行为时我们才应该创建多种不同的异常类,通过提供异常基类所支持的所有构造器,可以为应用程序创建功能完整的异常类,使用InnerException属性可以保存更低级别错误条件所产生的所有错误信息。
四十五、优先选择异常安全保证
1、强异常保证在从异常中恢复和简化异常处理之间提供了最好的平衡,在操作因为异常而中断,程序的状态保留不变;
2、对将要修改的数据做防御性的复制,对这些数据的防御性复制进行修改,这中间的操作可能会引发异常,将临时的副本和原对象进行交换;
3、终结器、Dispose()方法和委托对象所绑定的目标方法在任何情况下都应当确保他们不会抛出异常。
四十六、最小化互操作
1、互操作有三个方面的代价:数据在托管堆和非托管堆之间的列举成本,托管代码和非托管代码之间切换的成本,对开发人员来说与混合环境打交道的开发工作;
2、在interop中使用blittable类型可以有效地在托管和非托管环境中来回复制,而不受对象内部结构的影响;
3、使用In/Out特性来确保最贴切的不必要的多次复制,通过声明数据如何被列举来提高性能;
4、使用COM Interop用最简单的方式实现和COM组件的互操作,使用P/Invoke调用Win32 API,或者使用C++编译器的/CLR开关来混合托管和非托管的代码;
四十七、优先选择安全代码
1、尽可能的避免访问非托管内存,隔离存储不能防止来自托管代码和受信用户的访问;
2、程序集在Web上运行时可以考虑使用隔离存储,当某些算法确实需要更高的安全许可时,应该将那些代码隔离在一个单独的程序集中。
四十八、掌握相关工具与资源
1、使用NUnit建立自动单元测试(集成在VS2010 中了);
2、FXCop工具会获取程序集中的IL代码,并将其与异族编码规则和最佳实践对照分析,最后报告违例情况;
3、ILDasm是一个IL反汇编工具,可以帮助我们洞察细节;
4、Shared Source CLI是一个包含.NET框架内核和C#编译器的实现源码。