微服务、事件驱动架构和 Kafka
想象一下,有一个巨大的整体应用程序,其中许多复杂的功能紧密地联系在一起。可扩展性是一个很大的挑战,部署过程可能会变得非常繁琐,而且由于内部组件高度耦合,改变功能流程也不是那么容易。
也许很多人都熟悉这个概念,因为直到几年前这是构建应用程序的标准方法,而且现在生产中仍然有很多单体应用。
但与此同时,尤其是在云服务“爆炸”之后,构建产品的过程转向了微服务方法。具有明确范围的小型微服务,可以与其他服务进行通信以完成业务范围。
尽管它们有其缺点,如复杂的集成测试、更多的远程调用、更大的安全挑战等,但它们在这个行业中已经证明了自己的实力。由于微服务是解耦的,它们可以更容易地扩展,如果你想做出改变,你只需要改变一个组件,只要它们之间的契约得到尊重,其他的微服务不应受到那个改变的影响。
但是,当然,并不是所有事情都是甜蜜的。这种情况很快演变为有很多微服务,每一个都与其他人通信,像在单体中的意大利面代码那样“绑定”在一起。
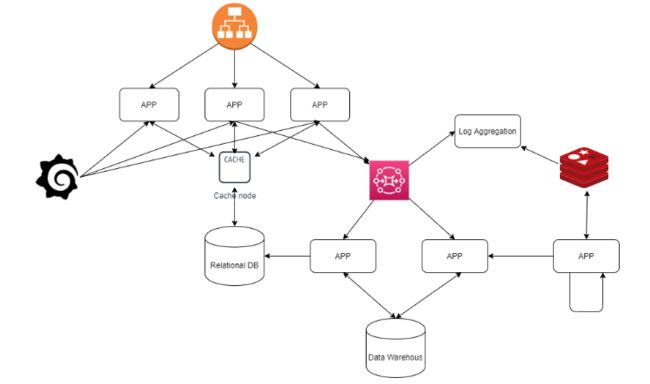
所以,你现在有很多微服务,它们通过REST、Soap、消息队列或其他通信渠道相互通信。这确实更具扩展性。但这样开发更简单吗?更容易理解工作流程吗?
答案是不!事实上更难。为了理解一个单体的工作流程,你必须从一个方法跳到另一个方法,从一个类跳到另一个类。现在你必须从一个微服务跳到另一个微服务。要做一些更改,你必须确保微服务之间的向后兼容性。
对于测试,你现在必须进行一个异步的集成测试,由不同的微服务组成,它们彼此通信,并且最终部署在不同的实例上。这似乎并不更简单。那么转向微服务方法是一个错误吗?答案是不。我们只需要一个范式变化。
事件驱动架构
为了克服这种问题,一些微服务应用采用了事件驱动架构。这是因为事件驱动架构具有一些适合微服务方法的特点。让我们来看看它们。
事件与业务流程相符
从商业角度看,把工作流程描述为一系列事件更容易理解。商人不关心你的内部逻辑。他看到的是事件。
例如,假设我们有一个在线商店。你有一些实体,如:客户、订单、支付和产品。流程是这样的:一个客户订购一些产品,如果支付成功,产品应该交付给客户。如果你以非事件的方式实施这一点,你的工作流程可能是这样的:
-
客户使用网页界面认证在线商店。
-
客户通过Web界面与服务器建立HTTP会话。
-
客户进行REST调用来订购一些产品。
-
在服务器端,创建了一个订单对象,并将产品添加到其中。
-
服务器向客户发送支付请求。
-
如果支付成功,服务器确认订单,更新仓库,产品交付将开始。
这很好,但商人不关心REST协议、会话、认证等细节。他像事件流那样看待一切,这可能会触发其他事件:
-
客户创建一个订单
-
客户收到支付请求
-
如果支付成功,库存将更新并交付订单
这更易于人类阅读,如果出现新的业务需求,更改流程也更容易。
事件与操作相匹配,微服务只关心事件,而不关心其他微服务。我们将有一个微服务,它将获取一个事件,进行一些操作,并可能发送另一个事件。
在我们的情况下,一个客户端应用程序将从客户那里获得一些输入,并触发一个创建订单事件。一些订单服务将接收此事件,它将创建一个订单,并将一个订单创建事件发送到支付服务。这个服务将向客户发送一个支付请求,并尝试验证支付。如果支付成功,它将发送一个支付成功事件到一个仓库服务,这个服务将更新库存并交付产品。
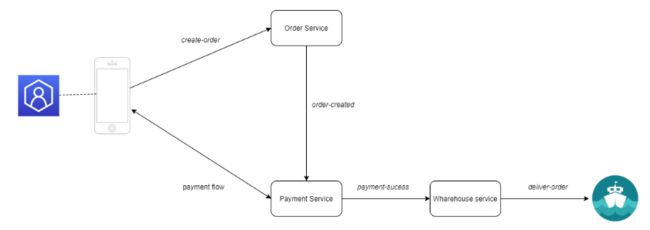
流程更简单,微服务是解耦的。如果你想添加另一个应该记录已创建订单的服务,更改非常小。你需要创建该服务并订阅它的创建订单事件。由于这将与其他服务解耦,原始工作流程不会受到任何修改,风险将是最小的。
事件驱动架构模式
事件驱动架构有不同的风格。让我们看一下最常见的模式。
事件通知
在这种设计模式中,事件旨在仅通知状态更改。它们不带任何状态,只是告诉某事已经发生。通常,发送者不期望任何响应。它不是用于来回通信的。事件通知意味着发送者和可能的接收者之间有明确的分隔。因此,它们之间的耦合度很低。任何人都可以接收通知,发送者只是不关心。
让我们看一下在线商店的例子,看看这种模式如何应用。如果客户完成支付,那么支付服务可以发送一个通知,告诉支付已经成功。它不期望任何反馈。其他服务如何处理这个通知,完全取决于它们。
当然,这可能带来一些劣势。如果许多服务正在监听这种通知,如果此通知是复杂逻辑的一部分,跟踪流程并看到发生了什么非常困难。可能需要在生产环境中检查流程才能实际复现问题。
但是,尽管有其劣势,考虑到组件之间的低耦合度和你可以轻松扩展的方式,事件通知模式非常有用。
事件承载状态转移
顾名思义,在这个模式中,事件将包含整个状态而不仅仅是一个通知。客户端需要的所有信息都包含在那个事件中。客户端不需要为额外信息调用发送者。
如果我们看前面的例子,如果客户想买一些产品,他会选择它们并创建一个订单。然后,订单将发布到订单服务。订单事件包含完成订单所需的所有必要信息。客户详细信息,账单地址,产品,付款方式等。它不需要从客户那里获得任何其他细节。
显然,缺点是你从一个服务传递很多信息到另一个服务。
事件源
另一种事件驱动模式是事件源。在这里,所有事件都被记录,系统的状态可以通过重播所有事件来重新创建。整个记录库成为真理的唯一来源。
一个非常熟悉的例子是像GIT这样的版本控制服务,其中当前状态是通过重播所有提交来创建的。当然,你可以进行一些优化。例如,GIT会保留一个快照并与提交一起,所以当你克隆一个项目时,你实际上不是从开始重播所有提交,你是从一个快照开始的。但是,记录列表是真理的唯一来源。
这可以带来多种好处,如:
-
强大的审计功能。你可以看到每一个时间点发生了什么。
-
你可以重新创建历史状态。
-
通过返回到旧状态并应用不同的事件,你可以探索替代历史。
Kafka和事件驱动架构
如今有许多技术可以用来从一个组件传递事件到另一个组件,如Aws Kinesis, Apache Flink, Rabbit Mq等等。
在这篇文章中,我想谈谈Apache Kafka,它可能是目前最受欢迎的流媒体服务,以及为什么它非常适合事件驱动架构。
传统上有两种消息传传递模型:
消息队列:其中消费者从队列中读取。
-
优点:这种消息类型的优势是可扩展性。如果你需要更多的工人来处理事件,只需添加更多的消费者。
-
缺点:一个事件只被一个消费者消费。如果你希望两个不同的消费者获得相同的事件,那是做不到的。
发布-订阅者:其中一个消费者订阅一个发布者以获取某种类型的事件。使用这种模型,更多的消费者可以获得相同的数据。但是,由于所有的消息都发给所有的消费者,你不能并行化工作。
-
优点:事件分发给更多的消费者。
-
缺点:它不是可扩展的。
Apache Kafka是一个分布式流平台,每天能够处理万亿次的事件。考虑到它的设计,它为你提供了队列消息和发布-订阅服务的双重优势。
它是如何工作的
Kafka将事件存储在主题中。主题是数据的逻辑分割,如一个分类。例如:所有与客户请求相对应的事件可以保存在一个名为customer-requests的专用主题中,而所有与接收的付款相对应的事件可以保存在另一个名为payment-received的主题中。因此,如果你只想消费客户请求,那么你可以订阅customer-requests主题。这就像拥有多个消息队列,每个分类一个队列。
在内部,一个主题可以被分割成多个分区。分区是一个有序的、不可变的记录序列。
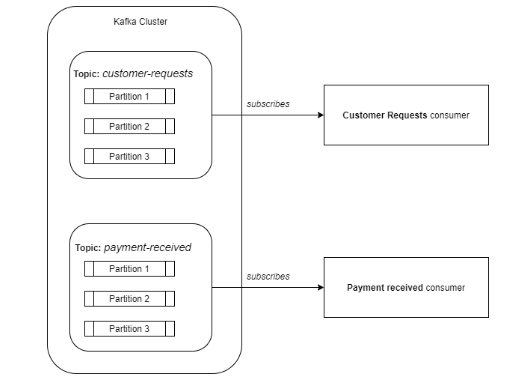
生产者
生产者将数据发布到主题中。此外,生产者还负责选择将数据放入哪个主题分区。默认情况下,Kafka会计算密钥的哈希码并使用它来选择分区。
消费者
消费者订阅一个主题,然后它将开始从该主题接收数据。消费者可以在消费者组中定义(只是一个标签)。但是,使用这个消费者组对于扩展负载来说是一个关键点。消费者组与kafka主题之间的关系就像一个发布-订阅服务,其中订阅者是整个消费者组。
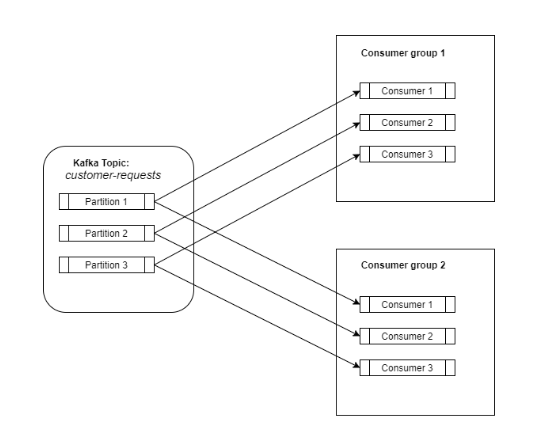
因此,一个主题的所有数据都会分发给订阅了该特定主题的所有消费者组。现在,我们拥有了一个发布-订阅服务的所有优点,所有数据都分发给所有订阅者。
可扩展性
在这种情况下,我们如何扩展?就像我之前说的,主题中的数据被分割成多个分区,而消费者组由不同的消费者组成(它们可以是不同机器上的不同进程)。
Kafka确保每个消费者组只有一个消费者会消费一个分区。一个消费者可以从零、一个或多个分区中消费数据。
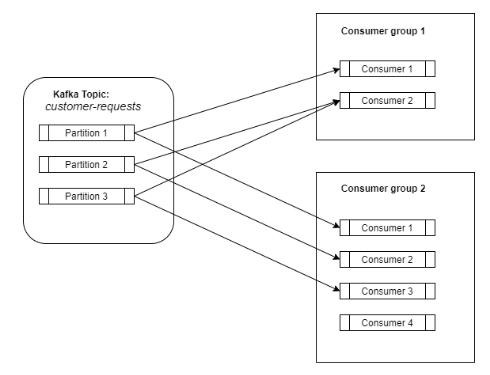
现在,在一个消费者组内部,我们有一个消息队列,消费者进入一个队列并获取一个元素。这就是我们获得可扩展性的方式。需要更多的工作人员吗?增加消费者和分区的数量。理想情况下,它将是一对一的映射。
这就是Kafka如何结合消息队列和发布订阅者的双重优势,消除了它们的劣势。数据可以分发给更多的消费者,而不牺牲可扩展性。所有这一切都是通过分区和消费者组的概念获得的。
其他优点
消息排序
Kafka不保证主题中数据的顺序,但它确保每个分区的数据顺序,而且,由于每个消费者组只有一个消费者消费一个分区,你有保证这些事件以正确的顺序被消费。这与消息队列形成对比,在消息队列中,即使事件按顺序保存,由于许多消费者同时获取数据,你不能保证处理顺序。
数据分发
Kafka集群可以由多个服务器组成,每个服务器处理一部分分区。但是,此外,分区可以复制到多个服务器。
每个分区都有一个负责填充和处理该分区的读取请求的领导者。但是,由于分区是复制的,如果领导者死亡,其他的跟随者将成为新的领导者,因此不会丢失数据。
因此,这种分布保证了对于一个复制因子为N的主题,一个Kafka集群将容忍N-1次故障而不会丢失任何数据。
存储
在Kafka中,消费者与生产者是解耦的。生产者发布数据,消费者来控制他们想要消费什么数据,通过指定消息偏移量,以及多久消费一次。因此,Kafka成为一个存储服务。数据在集群中保留一段配置的保留时间,不管数据是否被某些消费者读取。
此外,由于分区是为了故障转移而复制的,数据是隐式复制的。所以,就像我之前说的,对于一个复制因子为N的主题,Kafka保证在最多N-1次故障中不会丢失数据。
结论
如今,特别是在“云服务的爆炸”之后,我们越来越感到迁移到微服务的需要,而不是构建单体应用。可以单独开发、使用不同的编程语言、由不同的团队开发,并根据其特定需求单独扩展的小型解耦微服务。当然,为了实现业务范围,你需要将多个微服务绑定在一起。
有很多方法可以做到这一点,但是,正如我们所看到的,事件驱动架构具有一些特点,使其非常适合将服务绑定在一起。
一个事件驱动的设计伴随着一个共同的事件通道的需求。在那里有很多不同的解决方案,Kafka也许是最受欢迎的一个。Kafka结合了发布-订阅服务和消息队列的双重优势,成为一个非常高效且可扩展的平台,每天可以传送数百万(甚至数万亿)的事件。
作者:Ioan Tinca
更多内容请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。