python中成绩分析函数_自学Python笔记:用Python做成绩分析(1)
有朋友会问,刚学了一周,什么是面向对象都还不清楚就可以写程序?还有Python不是写“爬虫”吗?
Python是面向对象的语言,函数、模块、数字、字符串都是对象,并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。如果想快速的搞清楚面向对象的三大特性“封装、继承和多态”估计不下点功夫还真搞不明白,还有Python的类可以继承多个类,虽然是一种多态语言但多态的使用也有争议,纯粹学面向感觉对于数据结构不扎实的初学者来说搞不好容易搞迷糊。

抽象派
函数式编程对于初学者来说可能更容易理解,再就是编个小程序直接函数式编程就可以解决了。好处是Python同时支持两种编程方式,且函数式编程能完成的操作,面向对象都可以实现,虽然从编写成绩分析这样的小程序来说可能面向对象更合适,为什么这么说呢?在编写时需要创建多个事物,每个事物属性个数相同,但是值的需求都是不相同(如:张三、李四、杨五,他们都有姓名、班级、成绩,但值不同)这种非常适合面向对象的。
不管是哪种方式,只要能够解决当前的问题就是正确的方式,毕竟对于软件工程来说解决问题是最主要的,用的工具反而没有那么重要,就像对程序员来说语言不重要,重要的是解决问题的思想。
另外Python翻译过来“蟒蛇”,蟒蛇是什么?爬的大虫啊O(∩_∩)O~。“爬虫”主要目的是将网页下载到本地,然后通过一系列的数据分析算法等提取有效信息,进而对后续的机器学习,自然语言分析,数据可视化。因为python的库实在是太丰富了,又容易入手,很容易把这些工作无缝衔接起来,自然也就成了第一选择。
后面恰当的时候会写一个“爬虫”来获取学生成绩用于数据分析,什么成绩需要“爬”?比如高考成绩公布了,领导安排你做数据分析,原来都是学生把查到数据交给班主任,班主任汇总后交到学校,最后才做分析,费时不说还容易出差错,如果用“爬虫”可以省去很多的麻烦,这个属于数据信息的获取,后面将提到。

数据分析
废话好像太多了,开始今天的话题:用Python做一份成绩分析。
任务交代:
有三个学校(育英中学、育才中学、育德中学)的成绩,excel表部分数据如下:
准考证号
姓名
学校
班级
语文
数学
英语
综合
体育
实验
信息
总分
名次
20180101002
李子强
育才中学
1
79
105
88
137
41
18
18
20180101312
尹金杰
育德中学
3
72
99
26
122
46
20
12
20180101195
李帅
育德中学
1
89
98
115
140
37
20
11
20180101197
李帅
育德中学
1
93
98
98
136
44
20
13
20180101252
张梦冉
育德中学
2
81
96
64
133
39
20
7
20180101228
张如霞
育德中学
1
83
95
72
137
41
20
14
20180101200
段树伟
育德中学
1
94
95
96
131
46
18
12
20180101137
徐晓潭
育英中学
1
75
94
69
128
48
20
19
20180101004
吴子航
育才中学
1
90
94
89
125
44
20
13
20180101194
刘帅
育德中学
1
89
93
111
138
45
20
16
20180101221
韩睿
育德中学
1
83
93
84
125
46
20
19
20180101198
张帅
育德中学
1
97
92
103
138
44
20
9
需要计算各考生的总分、总名次并根据公布的分数线(一线:430二线:320)统计各学校的上线情况。
学校
考生数
平均分
一线人数
一线率
二线人数
二线率
育才中学
育英中学
育德中学
任务比较简单,主要目的还是熟悉Python的基本用法,获得存在感,其实这么简单的数据分析用excel很容易搞定,但现实中处理起来可能不限于以上要求,到时根据需要再增加功能即可。
工具选择:python、 pandas 、openpyxl、matplotlib(考虑后面可能做图表,也符合教材要求)
Python处理excel有好多的库可以选择,比如:xlwings、openpyxl、pandas、Xlsxwriter、xlutils(结合xlrd/xlwt)等,各有各的特点,特别前三种推荐使用,尤其数据处理是pandas的强项,这里它吧Excel 作为输入/输出数据的容器。
第一篇笔记中已经完成了pandas 、matplotlib的安装,为了后面的应用建议安装一下openpyxl和numexpr,命令如下:

openpyxl的安装
numexpr的安装
今天重点学习一下pandas 可能需要的excel操作。
1.导入pandas模块
import pandas as pd
import pandas as pd
2.导入原始成绩Excel文件“grade.xlsx”,如果不加"Sheet1,默认是第一个sheet页。
df = pd.read_excel("grade.xlsx","Sheet1")
df = pd.read_excel("grade.xlsx","Sheet1")
或者(sheetname=0表示第一个sheet页,sheetname=1表示第二个sheet页,以此类推)
df = pd.read_excel(r"grade.xlsx",sheetname=0)
df = pd.read_excel(r"grade.xlsx",sheetname=0)
如果在命令行下可以利用 “df.dtypes”浏览一下该数据表的数据类型。
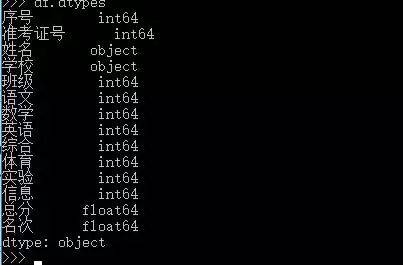
原始表数据类型
3.数据的筛选,如筛选所有“育才中学”的学生。如果想要更多复杂的筛选,可以使用map来以多重标准进行筛选,这里暂且不表。
df[df["学校"] =='育才中学'].head()
df[df["学校"] =='育才中学'].head()

筛选后显示
如果安装了numexpr后还可以用query来完成,结果一样。
df.query('学校 == ["育才中学"]').head()
df.query('学校 == ["育才中学"]').head()
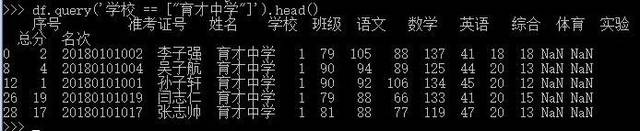
query筛选
注意:df.head()一般列举的是前5条
4.数据简单的计算,如计算每个学生的总分。
df["总分"] = df["语文"] + df["数学"] + df["英语"]+ df["综合"]+ df["体育"]+ df["实验"]+ df["信息"]
df["总分"] = df["语文"] + df["数学"] + df["英语"]+ df["综合"]+ df["体育"]+ df["实验"]+ df["信息"]

计算总分
5.排序,by为字段,ascending为排序方式,如下面为按总分倒序排序。
df.sort_values(by='总分',ascending=False)
df.sort_values(by='总分',ascending=False)

排序
下面这一条是按学校正序、总分倒序排序。
df.sort_values(by=['学校','总分'],ascending=[1,0])
df.sort_values(by=['学校','总分'],ascending=[1,0])
6.数据的统计,利用pandas库进行数据分组分析十分便捷,其中应用最多的方法包括:groupby、pivot_table及crosstab。举个小栗子,如统计各个学校的学生人数。
df.groupby('学校')['总分'].count()
df.groupby('学校')['总分'].count()

分类统计
7.文件的保存。只有一个工作簿的话可以用to_excel()方法创建Excel文件是将DataFrame里的内容写入,这里只有DataFrame对象才可以用to_excel()。多个DataFrame导入同一个Excel表格,但是要区分工作簿时需要用“ExcelWriter”。
df.to_excel('grade.xlsx',sheet_name='grade')
df.to_excel('grade.xlsx',sheet_name='grade')
基本的知识先学到这,下一步尝试按要求形成demo。
关注我,带给您更多有趣有意义的信息~