机器学习-基本知识
任务类型
◼ 有监督学习(Supervised Learning) 每个训练样本x有人为标注的目标t,学习的目标是发现x到t的映射,如分类、回归。
◼ 无监督学习(Unsupervised Learning) 学习样本没有人为标注,学习的目的是发现数据x本身的分布规律,如聚类
◼ 半监督学习(Semi-Supervised Learning) 少量数据有标注,大部分数据没有标注,需设计合理的算法对未标注数据进行有效利用。
◼ 增强学习(Reinforcement Learning) 数据本身没有确切标注,学习基于系统和环境进行交互时得到的反馈信息。这一反馈可能是部分 的,可能是随机的,可能是即时的,可能是延时的。
常用数据类型:
1. 数值数据 2. 类别数据 3. 文本数据 4. 时序数据 5. 图像数据
特征工程:不同的数据类型有不同的特征提取技术,涉及使用领域知识、业务约束、 人工转换和数学转换的组合,将原始数据转换为所需的特征
一、数值数据
➢ 整数和浮点数是最常见和最广泛使用的数值型数据
➢ 尽管数值数据可以直接输入机器学习模型,但在构建模型之前,仍需要设计与场景、问题和 领域相关的特征。因此,特征工程的需求仍然存在。
特征工程方法
◼ 特定转换技术,如二值化、凑整、构造交互项、分箱、缩放等
◼ 统计转换技术,更改数值的总体分布,将偏态分布转换为正态分布,如对数转换、BOX-Cox转换
(1)二值化 (Binarization) 原始数据包含的指示特定属性的计数数据(如总计数、频率等数据),在一些 特定的应用中(构造推荐系统引擎),可进行二值化处理。即是否,是非,0-1判断
(2)凑整(Rounding) 通常,在处理百分比等数字属性时,可能不需要高精度的值。因此,将这些高精 度百分比四舍五入为整数数字更有意义。然后,这些整数可以直接用作原始数值, 甚至可以用作离散类特征。
(3)构造交互项(Interactions) 模型在建立时,试图将输出响应(离散类或连续值)建模为输入特征变量的函数,通常基于多个单 独的输入特征。在一些真实世界的数据集场景中,也可以尝试捕获这些特征变量之间的交互,作 为输入特征集的一部分。即两个变量或许可以相乘变成一个变量
(4)数据分箱(Binning) 通常,原始数据中某些特征值或频率的分布往往是倾斜的,如果直接使用具有多个数量级范围的 原始数字特征,在相似性度量、聚类距离、回归系数等指标可能会受到不利影响。有多种方法可以解 决这些影响,包括数据分箱、缩放或统计转换。
数据分箱:用于将连续数值转换为离散数值,离散数值被分组到箱,每个箱代表一个特定的等级,并 且有一个特定的取值范围,连续型数值依次归入到各个分箱。目前有多种数据分箱方法,包括:
➢ 固定宽度分箱
固定宽度分箱中,每个bin都有一个预先固定的值范围,这些值根据一些业务或自定义逻辑、规 则或必要的转换确定。
常见的固定分箱技术包括:
- 基于舍入(rounding)操作分箱#取整数位20-29定位2
- 基于自定义范围分箱#自定义宽度#可以定15
➢ 自适应分箱
固定分箱技术可能会导致不规则的箱子,有些箱子数据密集,有些箱子数据稀少,甚至是空箱。 自适应分箱是一种更可取的方法,它根据数据的分布本身来决定应该如何分箱。
常见的自适应分箱技术: - 基于分位数的分箱 (Quantile based binning)
(4)数值数据的统计转换技术
• 对数转换(Log Transform)#即![]() ,底数可以任意取,当应用于倾斜分布时,对数变换很有用,因为它们倾向于扩展较低级数范围内的值,并倾向于压缩或减少较 高级数范围内的值,使偏态分布尽可能转换为正态分布。
,底数可以任意取,当应用于倾斜分布时,对数变换很有用,因为它们倾向于扩展较低级数范围内的值,并倾向于压缩或减少较 高级数范围内的值,使偏态分布尽可能转换为正态分布。
• BOX-Cox转换#即
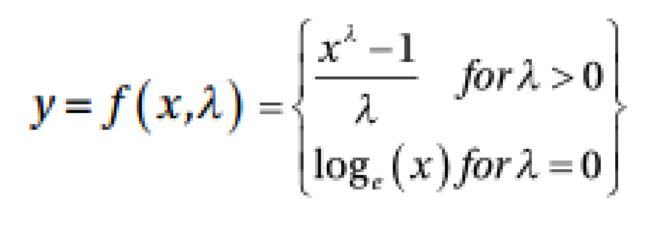
输出y是输入x和变换参数λ的函数,当λ=0时,得到的变换是自然对数变换。 λ的最佳值通常使用最大似然或对数似然估计来确定。
两种变换函数都属于幂变换函数族,通常用于创建单调数据转换,主要意义在于 稳定方差,严格遵守正态分布,并使数据独立于基于其分布的均值。也常用作特 征缩放操作。
二、类别数据
➢ 类别或类别标签本质上可以是文本,通常有两种类型的类别特征:名义特征和序数特征。
- 名义特征是指在特征的值之间排序没有意义,通常有一组有限的不同离散值组成
- 序数特征可以根据它们的值进行排序,它们的顺序是有特定意义的
类别数据的特征工程技术
➢ 数字表示:名义特征通常是字符串或文本格式,机器学习算法无法直接理解它们, 首先要将这些功能转换为更具代表性的数字格式表示
➢ 数据编码:独热编码、虚拟编码、特征哈希方案
#都相当于建立一个文本到数字的映射
类别特征的编码
虽然已经将类别变量转换并映射为数字表示,但如果将这些类别特征的转换数字表示直接输入到算法中, 该模型基本上会试图将其解释为原始数字特征,因此数量的概念将错误地引入模型中。同样,虽然顺序在 序数型变量中很重要,但这里没有大小的概念。因而,需要引入编码方案。
独热编码( One Hot Encoding )
假设有m个标签的类别特征的数字表示,独热编码方案将特征编码为m个二进制特征,其中只能包含1或0的 值。因此,分类特征中的每个观察值都被转换为大小为m的向量,其中只有一个值为1(表示处于活跃状态)。
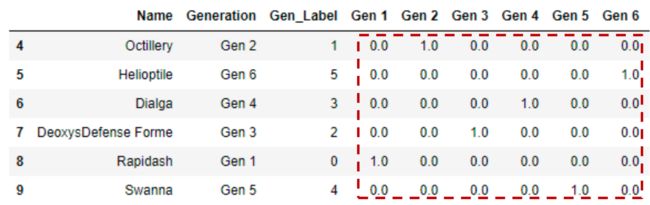
编码较原来的数字表示加长了m-1倍,简化为多个0加一个1的形式的向量
哑变量编码( Dummy Encoding )
哑变量编码方案类似于独热编码方案,区别在于,当应用于具有m个不同标签的类别特征时,我 们得到m-1个二进制特征,忽略的特征通常由全零(0)的向量表示。因此,分类变量的每个值 都被转换成大小为m-1的向量。
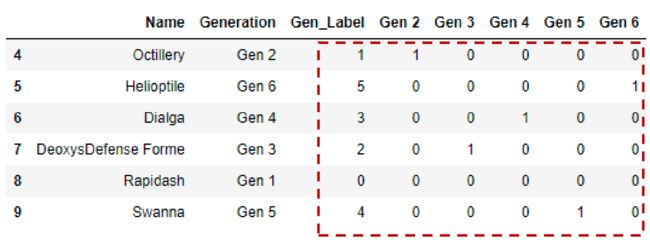
进一步压缩,向量相比独热减少了一个项
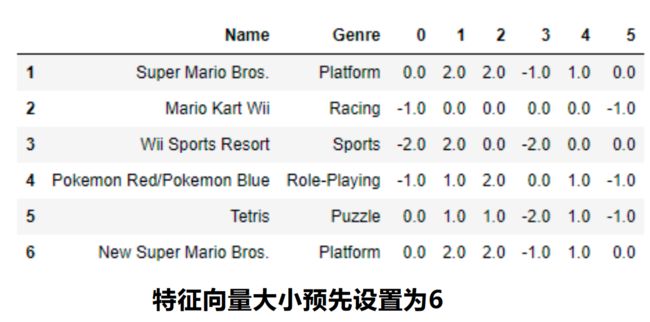
3)特征哈希编码( Feature Hashing Scheme)
特征哈希方案是处理大规模类别特征的另一种有用的特征工程方案。特征哈希编码可以将输出视为一 组有限的h-bin,h的值可以指定,它成为每个类别特征的编码特征向量的最终大小。因此,即使我们在一 个特征中有1000多个不同的类别,并且我们设置h=6,输出特征集仍然只有6个特征
三、时序数据的特征工程
时序数据
时序数据涉及在一段时间内发生变化的数据集,基于时间的属性在这些数据集中至关重要, 如股票、天气预报、商品零售等多个领域。通常,时序属性包括某种形式的时间数据和时间戳值, 并且通常可选地包括其他元数据,如时区、夏令时信息等。
特征工程技术
➢ 字符串时间数据转换为时间戳对象
➢ 从时间戳对象中提取时序属性
(1)字符串时间数据转换为时间戳对象
调用pandas.Timestamp()转换为Timestamp对象
每个Timestamp对象都有多个组件,包括日期、时间、甚至基于时间的偏移量、时区信息等
提取时序属性 1)基于日期的特征 2)基于时间的特征 3)衍生特征
特征中的每一个都可以用作类别特征,并且可以进行进一步的特征工程,比如独热编码、聚合、分箱等
四、分类模型的预备知识
1. 分类定义
分类是机器学习问题的子集,是整个监督学习领域的一个主要部分。
给定一个记录的集合(训练集)
- 每条记录用一个元组表示(x,y),其中x是属性的集合, y 是类标签
- 通过学习得到一个模型(函数),把每个属性集x映射到预先定义的类标签 y
2. 分类问题的不同类型
二分类模型 输出变量中总共有两个类别需要区分
多分类模型 有两个以上的类别需要分类。如预测手写数字,其中输出变量可 能是0到9之间的任意值。
多标签分类 又称多目标分类,一次性地根据给定输入预测多个二分类目标, 例如预测给定的图片是一条狗还是一只猫,同时预测其毛皮是长还是短。