爱某霸js逆向爬虫-制作自己的翻译软件
爱某霸js逆向爬虫-制作自己的翻译脚本
爱某霸爬虫
文章目录
- 爱某霸js逆向爬虫-制作自己的翻译脚本
- 爬虫第一步-打开浏览器
- 爬虫第二部-分析js
- 爬虫第三步-代码优化
爬虫第一步-打开浏览器
网友提供的网址:http://www.iciba.com/fy
打开就能看到两个文本框,左边是待翻译文本框,右边是翻译后的文本框(这是废话)
来吧,让我们看一下这个网站是如何工作的,首先F12 打开控制台(chrome的控制台,不是你的cmd,也不是你敲代码用的那个控制台)
下面看图 图比文本更清楚
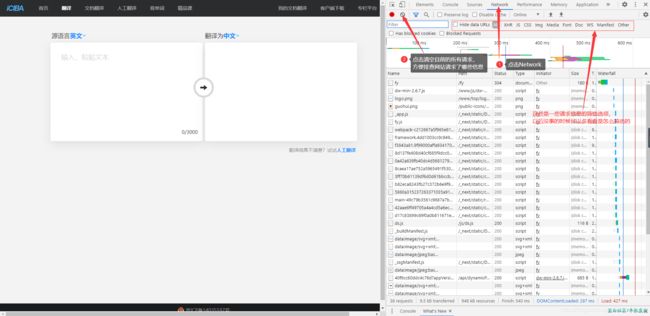
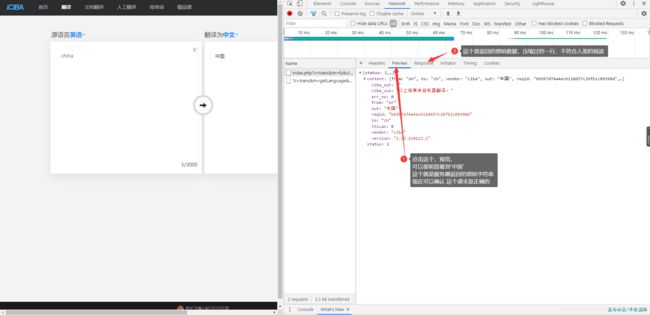
清空所有请求,然后尝试输入一个英文,让它翻译一下,看下翻译效果-注意看图

你现在认为我们该干什么?害 还能干什么?点进去看返回的内容啊,然后用python去模拟访问啊,然后解析数据啊,最后,没有了
看图,注意看图
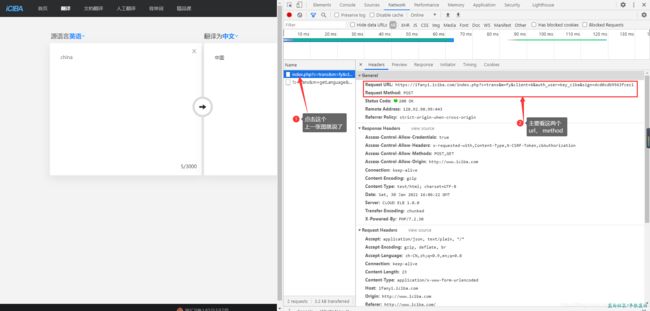
点进去响应内容之后,我们可以看到url和method,url 就是网址,method 就是你访问数据的方式,这个方式有很4种,最常用的有 get和post
get : 其实你每天都在用,你打开浏览器,输入baidu.com 这个过程就属于get操作,顾名思义,就是服务器给你数据。
post: 这个你每天也在用,你注册YY网站的时候,输入个人信息,点击确认提交,这个就属于post;通俗一点就是,你向服务器问问题,服务器给给你答案,这么说不准确,暂时可以这么理解。
(又说了很多废话)
来吧继续吧,继续看图
ok 来吧,敲代码
class Iciba():
def fanyi(self, q: str):
"""
翻译主方法
:param q: 待翻译的文本
:return: 返回翻译后的文本
"""
data = {
'from':'en',
'to':'auto',
'q':q
}
url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=dcd0cdb9563fcec1'
res = requests.post(url,data=data).json()
return res['content']['out']
if __name__ == '__main__':
iciba = Iciba()
word = 'china'
iciba.get_language('china')
写完了,运行下试试
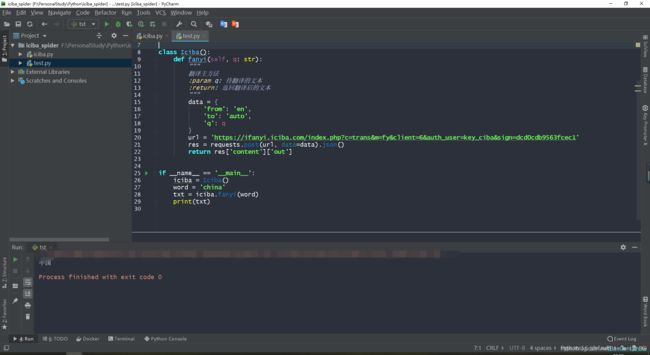
ok 完成了!太简单了。嘿嘿,换个词试试
换个词之后,你会发现 报错了 ……
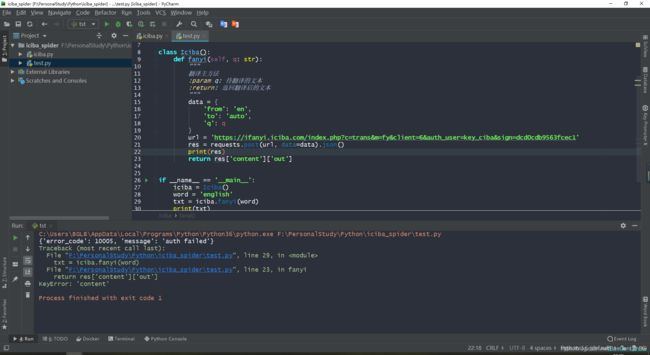
服务器给我们返回一个auth failed 认证失败! 难到 这就被反扒了? 我们才访问了一次啊。怎么会这样?????
换回china试试? 换回china 之后我们发现 程序又开始正常运行了!what 这是对english 有歧视???不行 先会网站正常翻译下试试
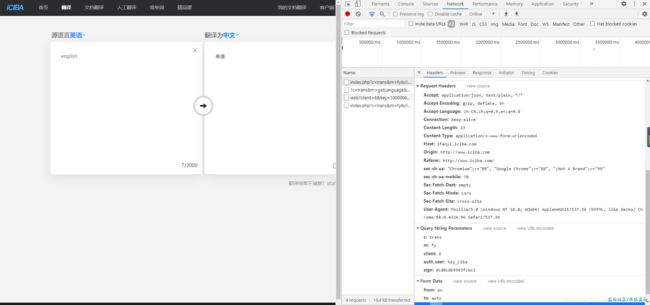
明明没有歧视啊!怎么程序就不行呢????多试试几次之后,你会发现只要你换除china之外的词都会报错,这是为什么呢?
看图看图看图
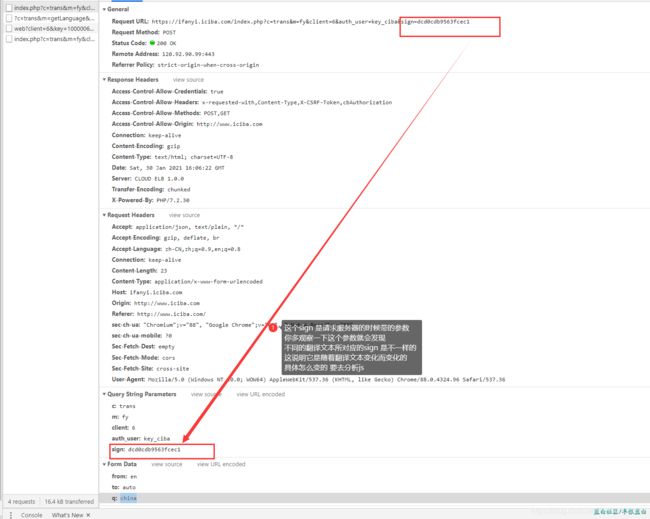
url ?之后的代表参数 关于url 详细的只是可以自行百度(篇幅太大了)
好了 问题找到了,接下来就去分析js吧
爬虫第二部-分析js
首先来张图
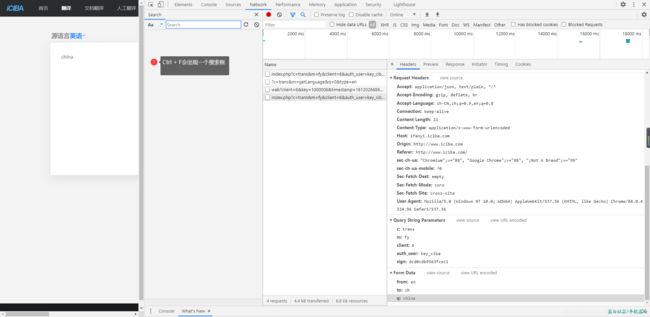
可以通过上一张图的搜索框搜索出sign出现在那个js文件里面,在搜索之前,我们需要刷新下页面,把所有的js加载出来然后搜索

我们通过搜索找到了sign的出生地,但是有两个,好像是个双胞胎,不过他们的出生方式都是一样的,代码一模一样,所以我们只需要用python 模拟sign 出生就可以了
其实全局搜索太慢了,我们可以用简便的方法找到sign的出生地 下面看图

设置好了拦截请求之后,重新触发一次请求,看图看图
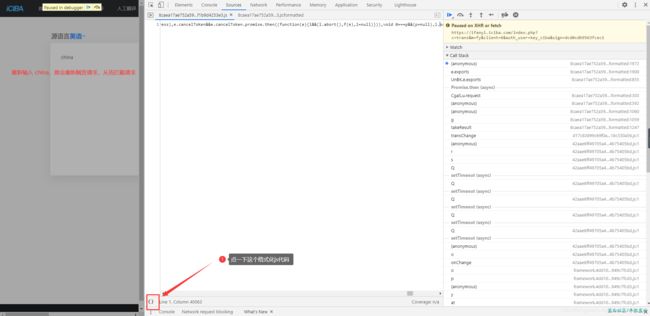
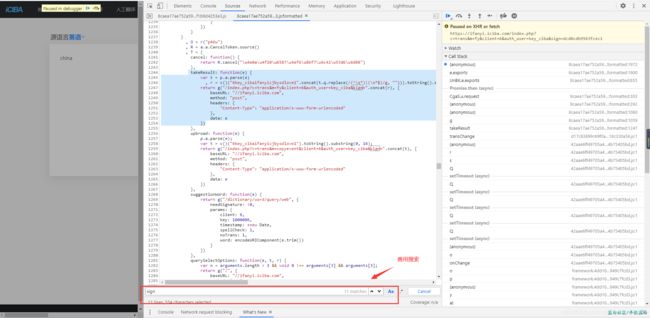
好了 返回正题, 我们拿到了sign 的出生代码块,不认识没关系,你只需要看与sign 有关的就行了。
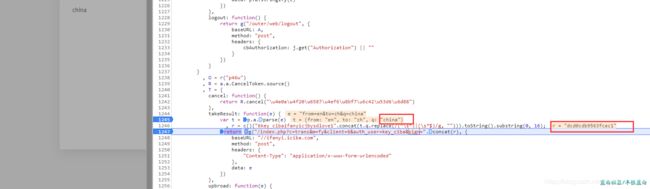
var t = p.a.parse(e)
r = c()("6key_cibaifanyicjbysdlove1".concat(t.q.replace(/(^\s*)|(\s*$)/g, ""))).toString().substring(0, 16);
return g("/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=".concat(r), {
baseURL: "//ifanyi.iciba.com",
method: "post",
headers: {
"Content-Type": "application/x-www-form-urlencoded"
},
data: e
}
一步一步来,可以初步看出,sign 和 r 有关 , r 和 c 与 t 有关,t 与 e 有关
所以 我们先搞清楚e
把鼠标放到e 上面 发现有很多东西,不方便我们查看,所以,我们给它打一个断点,debug一下 一步一步的看它的过程。
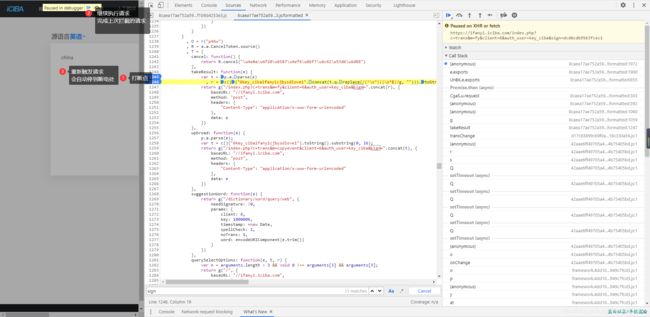
操作吧 ,继续看图
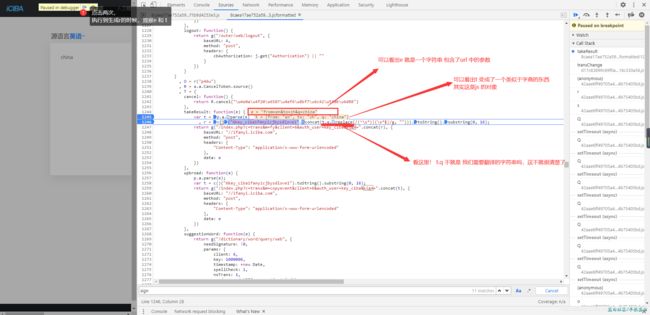
现在清晰多了 ......sign=".concat(r)
r = c()("6key_cibaifanyicjbysdlove1".concat("需要翻译的字符串".replace(/(^\s*)|(\s*$)/g, ""))).toString().substring(0, 16);
我们只需要解决.concat() 这个 和 c() 以及 .toString().substring(0, 16); 即可
但是我们不知道 .concat() 和 .toString().substring(0, 16);这些方法是干嘛的 怎么办呢 ???
是时候拿出杀手锏了,百度啊 不会就百度
.concat() 就相当于 + 连接两个字符串,
.toString().substring(0,16) 这个就是字符串分割取前16个
ok了弄清楚了这两个 再来看看
var t = p.a.parse(e)
r = c()("6key_cibaifanyicjbysdlove1".concat('需要翻译的字符串'.replace(/(^\s*)|(\s*$)/g, ""))).toString().substring(0, 16);
sign = r
replace(/(^\s*)|(\s*$)/g, "") 这个就是一个正则替换,把字符串的前后空格去除(目前先忽略)
所以我们就只剩了下面这些
r = c()("6key_cibaifanyicjbysdlove1"+('需要翻译的字符串')).toString().substring(0, 16);
sign = r
关键在于 c()(字符串).toString().substring(0,16)
看起来像是一个函数,可又不像函数 ,分解一下看看 c() 和 (一个字符串),然后取前16位
这个其实也不难理解 就是一个函数,用python 模拟一下
def q(s):
print("执行p函数,传入的s={}".format(s))
return s
def c():
return q
r = c()("china")
print("r={}".format(r))

那这样来看的话,我们就只需要解决q函数就可以了,继续分析js
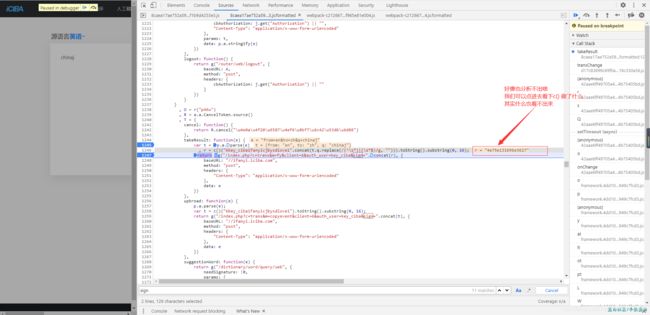
到这里,我们基本已经结束了,但是这个c()函数我们没办法,这个时候我们就得看经验了,用常见的加密方法去尝试,最常用的就是md5了,先试试 md5加密测试网站
我们把6key_cibaifanyicjbysdlove1加上一个china 拿去测试
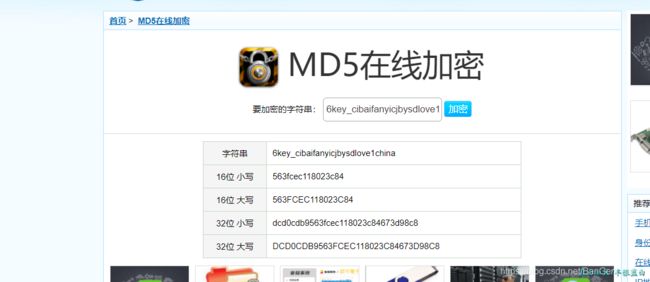
而js中的r等于什么呢?
这不就是 md5 的 32位小写 前 16 位吗
ok 到此结束
来吧 一把梭
# -*- coding:utf-8 -*-
# @Time : 2021-01-31 00:50
# @Author : BGLB
# @Software : PyCharm
from hashlib import md5
import requests
class Iciba():
def fanyi(self, q: str):
"""
翻译主方法
:param q: 待翻译的文本
:return: 返回翻译后的文本
"""
data = {
'from': 'en',
'to': 'auto',
'q': q
}
url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign={}'.format(sign)
res = requests.post(url, data=data).json()
print(res)
return res['content']['out']
def create_sign(self,q: str):
""""
模拟加密的sign
:param q: 待翻译的文本
:return: 返回加密好的sign
"""
KEY = "6key_cibaifanyicjbysdlove1"
base_sign = KEY + q.strip()
sign = str(md5((base_sign).encode('utf8')).hexdigest())
return sign[0:16]
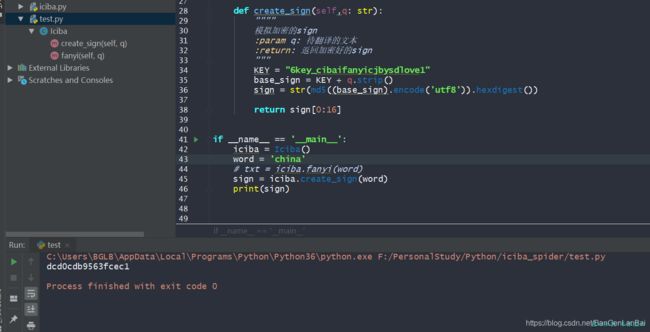
if __name__ == '__main__':
iciba = Iciba()
word = 'china'
# txt = iciba.fanyi(word)
sign = iciba.create_sign(word)
print(sign)
测试一下,嘿嘿 没问题一模一样
测试一下翻译 没问题了,哈哈哈哈
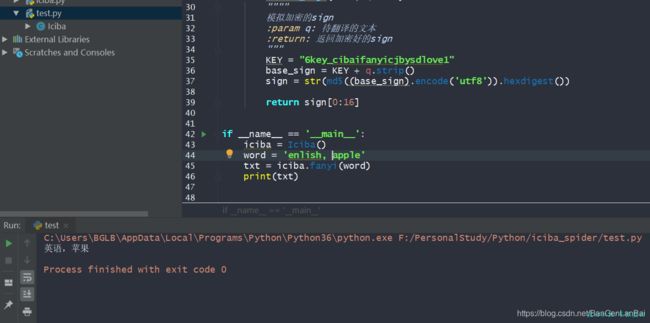
差不多就分享完了,但是 代码不是规范,重新优化下
爬虫第三步-代码优化
# -*- coding:utf-8 -*-
# @Time : 2021-01-30 21:20
# @Author : BGLB
# @Software : PyCharm
import requests
from hashlib import md5
class Iciba():
"""
爱某霸-爬虫
"""
def __init__(self):
self.__data = {
'from': None,
'to': None,
'q': ''
}
self.__INTERFACE_FANYI = "https://ifanyi.iciba.com/index.php"
self.__INTERFACE_LANGUAGE = "https://ifanyi.iciba.com/?c=trans&m=getLanguage&q=0&type=en"
def __create_sign(self, q: str):
"""
模拟加密的sign
:param q: 待翻译的文本
:return: 返回加密好的sign
"""
KEY = "6key_cibaifanyicjbysdlove1"
base_sign = KEY + q.strip()
sign = str(md5((base_sign).encode('utf8')).hexdigest())
return sign[0:16]
def __fanyi(self):
"""
获取翻译文本
:return:
"""
param = "c=trans&m=fy&client=6&auth_user=key_ciba&sign={}".format(self.__create_sign(self.__data['q']))
res = requests.post(self.__INTERFACE_FANYI, params=param, data=self.__data)
# print(res.url)
return res.json()
@property
def __language(self):
"""
获取站点所有语言json数据
:return: 返回拼装好的json 语言包 {"中文":"zh"}
"""
language = requests.get(self.__INTERFACE_LANGUAGE).json()
# print(language)
result = {}
for k, v in language.items():
result.update(v)
result.update({'auto': '自动识别'})
# print(result)
return result
def support_language(self):
"""
打印所有支持的语言
:return:
"""
for k, v in self.__language.items():
print(v)
def fanyi(self, q: str, _from: str = "自动识别", _to: str = "自动识别") -> str:
"""
翻译主方法
:param q: 待翻译的文本
:param _from: 翻译之前的语种
:param _to: 翻译之后的语种
:return: 返回翻译后的文本
"""
self.__data['q'] = q
for k, v in self.__language.items():
if v == _from:
self.__data['from'] = k
if v == _to:
self.__data['to'] = k
if not self.__data['from'] or not self.__data['to']:
raise KeyError('不支持的语种:{}'.format(_from, _to))
# print(_to)
result = self.__fanyi()
# print(result)
if str(result).find('content') > -1:
return result['content']['out']
raise Exception("error")
if __name__ == '__main__':
iciba = Iciba()
word = "Hello"
# iciba.support_language()
word_ja = iciba.fanyi(word, _to='日语')
word_cn = iciba.fanyi(word, _to='中文')
word_en = iciba.fanyi(word_ja, _to='英语')
print("{} - 翻译日文: {} - 翻译中文: {}".format(word, word_ja, word_cn))
print("{} - 翻译英语: {}".format(word_ja, word_en))
测试没有问题