《数据结构与算法》基本概念
一、什么是数据结构
1.1 关于数据组织——例:图书摆放
1.1.1 定义
-
“数据结构是数据对象,以及存在于该对象的实例和组成实例的数据元素之间的各种联系。这些联系可以通过定义相关的函数来给出。”——Sartaj
Sahni《数据结构,算法与应用》 -
“数据结构是ADT(Abstract Date Type)的物理实现”——Clifford
Shaffer《数据结构与算法分析》 -
“数据结构是计算机存储、组织数据的方式。通常情况下,精心选择的数据结构可以带来最优效率的算法。”——中文维基百科
1.1.2 如何在书架上摆放图书?
【涉及到的两个操作:新书怎么插入?怎么找到某一个
- 指定书?】 随便放?(累死……)
- 字母序,二分查找(边儿上的查找不方便《阿Q正传》)
- 先分类,在每类中拼音排序,二分查找。衍生问题:空间分配问题—类别分多细?
综上所述: 解决问题方法的效率。跟数据的组织方式有关。
1.2 关于空间使用——例:PrintN函数实现
例2:写程序实现一个函数PrintN,使得传入一个正整数为N的参数后,使顺序打印从1到N的全部正整数。
①for循环实现:
void PrintN( int N )
{ int i;
for(i=1;i<=N;i++){
printf("%d\n",i);
}
return;
}
②递归实现:
void PrintN( int N )
{ if(N){
PrintN(N-1);
Printf("%d\n",N);
}
return
}
计算机不愿意跑递归程序,对空间占用很恐怖。
综上所述:解决问题方法的效率,跟空间的利用效率有关。
1.3 关于算法效率——例:计算多项式值
例3:写程序计算给定多项式在给定点 x x x处的值:
f ( x ) = a 0 + a 1 x + … … + a n − 1 x n − 1 + a n x n f(x)=a_0+a_1x+……+a_{n-1}x^{n-1}+a_nx^n f(x)=a0+a1x+……+an−1xn−1+anxn
算法一:从左到右
double f(int n,double a[],double x)
{ int i;
double p=a[0];
for(i=1;i<=n;i++)
p+=(a[i]*pow(x,i);
return p;
}
算法二:从里到外(秦九韶)——标准程序,更快
f ( x ) = a 0 + x ( a 1 + x ( … ( a n − 1 + x ( a n ) ) ) ) f(x)=a_0+x(a_1+x(…(a_{n-1}+x(a_n)))) f(x)=a0+x(a1+x(…(an−1+x(an))))
double f(int n,double a[],double x)
{ int i;
double p=a[n];
for(i=n;i>0;i--)
p=a[i-1]+x*p;
return p;
}
验证:两个程序用时比较,调用clock( )函数,此函数时间单位为clock tick(时钟打点)。常数CLK_TCK:机器时钟每秒所走的时钟打点数。
#include实例:写程序计算多项式 f ( x ) = f(x)= f(x)= ∑ i = 0 9 i ∗ x i \displaystyle\sum_{i=0}^{9} i*x^i i=0∑9i∗xi 在给定点 x = 1.1 x=1.1 x=1.1处的值 f ( 1.1 ) f(1.1) f(1.1)
综上所述:解决问题方法的效率,跟算法的巧妙程度有关
1.4 抽象数据类型
所以到底什么是数据结构?
- 数据对象在计算机中的组织方式。
- 数据对象必定与一系列加在其上的操作相关联。
- 实现这些操作所用的方法就是算法。
1.4.1 定义
1. 数据类型:
- 数据对象集
- 数据集合相关联的操作集
2. 抽象:描述数据类型的方法不依赖于具体实现。
- 与存放数据的机器无关
- 与数据存储的物理结构无关
- 与实现操作的算法和编程语言均无关
总体来说:只描述数据对象集和相关操作“是什么”,并不涉及“如何做到”的问题。
3. 例子:矩阵的抽象数据类型定义
- 类型名称:矩阵(Matrix)
- 数据对象集:一个MN的矩阵 A M ∗ N = ( a i j ) A_{M*N}=(a_ij) AM∗N=(aij) ( i = 1 , … , M ; j = 1 , … , N ) (i=1,…,M;j=1,…,N) (i=1,…,M;j=1,…,N)由MN个三元组 < a , i , j >
- 操作集:

二、什么是算法
2.1 算法的定义
1. 算法(Algorithm)
- 一个有限指令集
- 接受一些输入(有些情况下不需要输入)
- 产生输出
- 一定在有限步骤之后终止
- 每一条指令必须:有充分明确的目标,不可以有歧义、在计算机能处理的范围之内、描述应不依赖于任何一个计算机语言以及具体的实现手段。
2.例子: 选择排序算法的伪码描述
void SelectionSort ( int List[], int N )
{
for (i=0;i<N;i++){
MinPositon = ScanForMin(List,i,N-1);
/* 从List[i]到List[N-1]中找最小元,并将其位置赋给MinPostion*/
swap(List[i],List[MinPostion]);
/*将未排序部分的最小元换到有序部分的最后未知*/
}
}
抽象一:List到底是数据还是链表?
抽象二:swap用函数还是宏去实现?
2.2 什么是好的算法?
- 空间复杂度:程序执行占用存储单元的长度 S ( n ) S(n) S(n)
- 时间复杂度:程序执行耗费时间的长度 T ( n ) T(n) T(n)
- 例一:PrintN的递归算法
void PrintN( int N )
{ if(N){
PrintN(N-1);
Printf("%d\n",N);
}
return
}
调用一次划分一次空间,占用空间数量和原始n的大小成正比: S ( N ) = C ∗ N S(N)=C*N S(N)=C∗N
例二:PrintN的for循环实现
void PrintN( int N )
{ int i;
for(i=1;i<=N;i++){
printf("%d\n",i);
}
return;
}
它没有涉及到任何程序调用的问题,不管N多大,他占用空间是固定的,所以空间复杂度是一个常数,即 S ( N ) = C S(N)=C S(N)=C。
- 事实上:第二个函数要比第一个函数运行快很多。
- 探究运行效率——数乘除法的次数
计算多项式值从左到右算法:一个for循环里面 pow() 函数做 i i i 次乘法,即:
乘法次数=(1+2+3+…+n)=n(n+1)/2
T ( n ) = C 1 n 2 + C 2 n T(n)=C_1n^2+C_2n T(n)=C1n2+C2n
计算多项式值从内到外实现:n 次乘法
T ( n ) = C n T(n)=Cn T(n)=Cn - 分析一般算法的效率时,经常关注以下两种复杂度:
- 最坏情况复杂度 T w o r s t ( n ) T_{worst}(n) Tworst(n)
- 平均复杂度 T a v g ( n ) T_{avg}(n) Tavg(n)
- T a v g ( n ) < = T w o r s t ( n ) T_{avg}(n)<=T_{worst}(n) Tavg(n)<=Tworst(n)
- 一般是分析最坏情况复杂度
2.3 复杂度的渐进表示法
关心的点: 随着数据规模的增大,他这个算法复杂度增长的性质会怎么样?
举例说明:
计算多项式值从左到右算法,他的时间复杂度在当 n n n很大的时候,基本上就是 n 2 n^2 n2在起主要作用。
计算多项式值从内到外实现,他的时间复杂度是 n n n在起主要作用。
只需要粗略比较这两个算法 的增长趋势就可以了---->复杂度的渐进表示法
2.3.1概念
上界: T ( n ) = O ( f ( n ) ) T(n)=O(f(n)) T(n)=O(f(n))表示存在常数 C > 0 , n 0 > 0 C>0,n_0>0 C>0,n0>0使得当 n > n 0 n>n_0 n>n0时有 T ( n ) < = C ∗ f ( n ) T(n)<=C*f(n) T(n)<=C∗f(n)
下界: T ( n ) = Ω ( g ( n ) ) T(n)=Ω(g(n)) T(n)=Ω(g(n))表示存在常数 C > 0 , n 0 > 0 C>0,n_0>0 C>0,n0>0使得当 n > n 0 n>n_0 n>n0时有 T ( n ) > = C ∗ g ( n ) T(n)>=C*g(n) T(n)>=C∗g(n)
既是上界又是下界: T ( n ) = θ ( h ( n ) ) T(n)=θ(h(n)) T(n)=θ(h(n))表示同时有 T ( n ) = O ( h ( n ) T(n)=O(h(n) T(n)=O(h(n)和
T ( n ) = Ω ( h ( n ) T(n)=Ω(h(n) T(n)=Ω(h(n)
备注:上界和下界都不是唯一的,太大的上界和太小的下界在分析算法效率时都是没有意义的。**所以:**一般写的是 O ( 最 小 ) O(最小) O(最小)和 Ω ( 最 大 ) Ω(最大) Ω(最大)

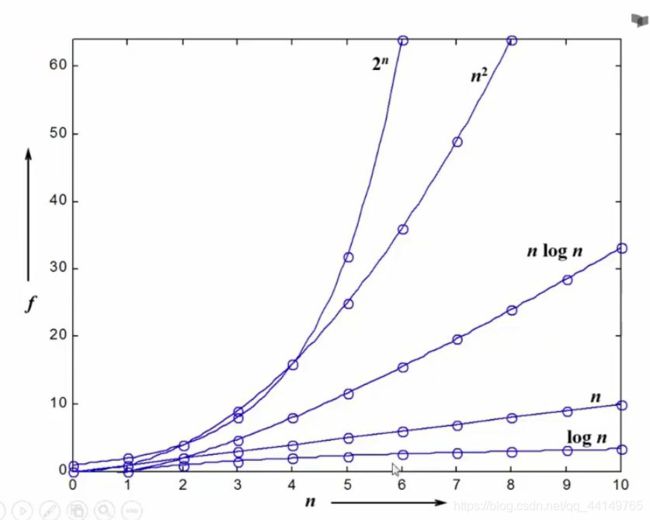
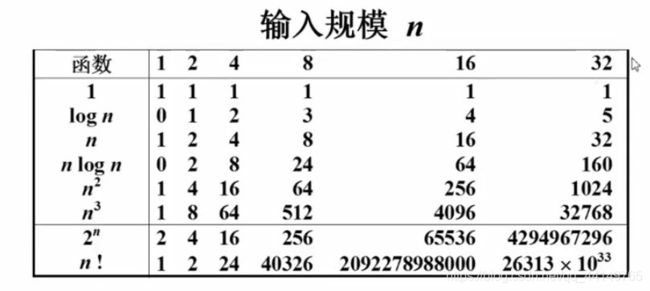
2.3.2 小窍门
若两段算法分别有复杂度 T 1 ( n ) = O ( f 1 ( n ) ) T_1(n)=O(f_1(n)) T1(n)=O(f1(n))和 T 2 ( n ) = O ( f 2 ( n ) ) T_2(n)=O(f_2(n)) T2(n)=O(f2(n)),则:
- T 1 ( n ) + T 2 ( n ) = m a x ( O ( f 1 ( n ) ) , O ( f 2 ( n ) ) ) T_1(n)+T_2(n)=max(O(f_1(n)),O(f_2(n))) T1(n)+T2(n)=max(O(f1(n)),O(f2(n)))
- T 1 ( n ) ∗ T 2 ( n ) = O ( f 1 ( n ) ∗ f 2 ( n ) ) T_1(n)*T_2(n)=O(f_1(n)*f_2(n)) T1(n)∗T2(n)=O(f1(n)∗f2(n))
若 T ( n ) T(n) T(n)是一个关于 n n n的 k k k阶多项式,则:
T ( n ) = θ ( n k ) T(n)=θ(n^k) T(n)=θ(nk)
一个for循环的时间复杂度=循环次数*循环体代码的复杂度
i f − e l s e if-else if−else结构的复杂度取决于 if 的条件判断复杂度和两个分支部分的复杂度,总体复杂度三者中取最大。