facenet 人脸模型训练
人脸检测与特征描述是人脸相关项目应用的基础(包括人脸识别,人脸认证以及人脸聚类等)
本文以mtcnn与facent算法为基础,讲述怎样训练自己的人脸模型。
主题框架采用的是 facenet 源码,依据具体需求,对facnet做了一定的修改,facenet源码见
https://github.com/davidsandberg/facenet
1、数据集收集
由于目前开源的数据集中,大多数都是欧美人士的,直接用这些数据来训练的模型对亚洲人脸的泛化能力有限制。所以需要自己采集人脸数据集,这里主要采用是通过爬虫,爬取尚街拍(https://www.jiepai.net/)上的人物照片。
具体爬虫操作见以下博客的说明
https://blog.csdn.net/reset2021/article/details/119103008
https://blog.csdn.net/reset2021/article/details/119107894
最终爬取的数据形式如下

2、数据集清洗
人脸训练数据,主要是针对人脸来进行的训练,所以对数据集进行简单的清洗,主要要清洗两部分数据:
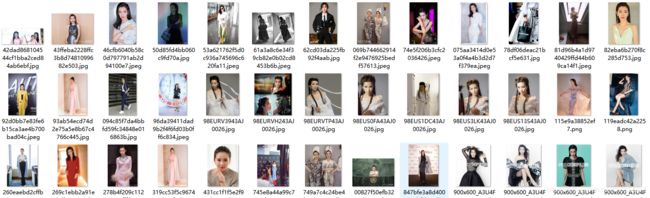
2.1、从网站上爬取的数据中还有一些脏数据(与目标人物相关的其他人物色数据)
如下图所示的图片
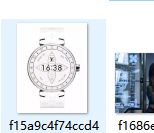
2.2、清洗多人数据
如下图所所示的多人合照

3、数据预处理
数据预处理主要包括两部分操作,一是对数据进行人脸检测(主要采用mtcnn算法);二是拆分训练数据集与测试数据集,并且对测试数据集进行处理,生成pairs.txt文件(用于验证)
3.1、对目标数据进行人脸检测
将经过清洗后的数据集放在facnet源码下的images目录下:
python src/align_dataset_mtcnn.py ./images/ ./images_align/ --image_size=160然后将在images_align下生成160*160的目标数据。

3.2、 对目标数据集进行拆分
将经过特征检测后的数据集进行拆分,本操作按8:2的拆分,拆分训练数据集与测试数据集
3.3、验证文件生成(pairs.txt)
facenet源码中没有提供相应的方法,依据lfw与pairs.txt文件推测编写了一个简单的pairs.txt文件的生成过程,主要是对经过特征检测后的人脸数据集进行同类与非同类的划分,详情见
https://download.csdn.net/download/reset2021/20068196
4、模型训练
模型训练的主要实现过程为facenet中train_tripletloss.py
具体调用方法为:
python src/train_tripletloss.py --logs_base_dir=log/ --models_base_dir=models/ --data_dir=images_align --image_size=160 --lfw_dir=/images_valid/ --lfw_pairs=images_valid_pairs.txt直接执行是存在一定的问题,本文对facnet做了如下修改:
① 修改加载模型的过程
if args.pretrained_model:
print('Restoring pretrained model: %s' % args.pretrained_model)
#saver.restore(sess, os.path.expanduser(args.pretrained_model))
#saver.restore(sess,os.path.abspath(args.pretrained_model))
facenet.load_model(args.pretrained_model)② 修改evaluate函数,在每次迭代后,进行验证,保存验证效果更佳的(以accuracy为判别依据)的模型
def evaluate(model_dir,models_base_dir,sess, image_paths, embeddings, labels_batch, image_paths_placeholder, labels_placeholder,
batch_size_placeholder, learning_rate_placeholder, phase_train_placeholder, enqueue_op, actual_issame, batch_size,
nrof_folds, log_dir, step, summary_writer, embedding_size):
start_time = time.time()
# Run forward pass to calculate embeddings
print('Running forward pass on LFW images: ', end='')
global g_accuracy
nrof_images = len(actual_issame)*2
assert(len(image_paths)==nrof_images)
labels_array = np.reshape(np.arange(nrof_images),(-1,3))
image_paths_array = np.reshape(np.expand_dims(np.array(image_paths),1), (-1,3))
sess.run(enqueue_op, {image_paths_placeholder: image_paths_array, labels_placeholder: labels_array})
emb_array = np.zeros((nrof_images, embedding_size))
nrof_batches = int(np.ceil(nrof_images / batch_size))
label_check_array = np.zeros((nrof_images,))
for i in xrange(nrof_batches):
batch_size = min(nrof_images-i*batch_size, batch_size)
emb, lab = sess.run([embeddings, labels_batch], feed_dict={batch_size_placeholder: batch_size,
learning_rate_placeholder: 0.0, phase_train_placeholder: False})
emb_array[lab,:] = emb
label_check_array[lab] = 1
print('%.3f' % (time.time()-start_time))
assert(np.all(label_check_array==1))
_, _, accuracy, val, val_std, far = lfw.evaluate(emb_array, actual_issame, nrof_folds=nrof_folds)
if np.mean(accuracy) > g_accuracy:
g_accuracy = np.mean(accuracy)
tmpsubdir = datetime.strftime(datetime.now(), '%Y%m%d-%H%M%S')
tmpsubdir = tmpsubdir +str(np.mean(accuracy))
model_result_dir = os.path.join(os.path.expanduser(models_base_dir), tmpsubdir)
if not os.path.isdir(model_result_dir): # Create the model directory if it doesn't exist
os.makedirs(model_result_dir)
mycopy(model_dir,model_result_dir)
print('Accuracy: %1.3f+-%1.3f' % (np.mean(accuracy), np.std(accuracy)))
print('Validation rate: %2.5f+-%2.5f @ FAR=%2.5f' % (val, val_std, far))
lfw_time = time.time() - start_time
# Add validation loss and accuracy to summary
summary = tf.Summary()
#pylint: disable=maybe-no-member
summary.value.add(tag='lfw/accuracy', simple_value=np.mean(accuracy))
summary.value.add(tag='lfw/val_rate', simple_value=val)
summary.value.add(tag='time/lfw', simple_value=lfw_time)
summary_writer.add_summary(summary, step)
with open(os.path.join(log_dir,'lfw_result.txt'),'at') as f:
f.write('%d\t%.5f\t%.5f\n' % (step, np.mean(accuracy), val))