MySQL - redolog 图文详解
一 前言
和 bin log 不同,redo log 不是二进制日志。它是物理日志,记录数据页的物理修改。用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
redo log 是 innodb 为了支持崩溃恢复而出现的,只记录 innodb 存储引擎中表的修改。bin log 和 inndb 总的来说有如下不同:
- 层面不同 bin log MySQL 本身实现的日志模块,而 redo log 是 innodb 引擎层实现的。
- 记录内容不同 bin log 记录的是逻辑性语句,即便是行格式形式。而 redo log 记录在物理上更改的日志,它记录的是数据库中每个页的修改。
- 写入形式不同 bin log 每次(看具体写入时机)事务提交的时候一次性写入缓存中,而 redo log 是分为两阶段写入:1. 准备阶段写如 redo log 缓存中。2. 然后当 innodb buffer 数据更新完成且事务提交后,再向 redo log 缓存中写入提交动作。也就是两阶段提交,后续章节会详解。
- 写入时机不同 bin log 在事务提交的时候一次性写入,故日志中的记录方式和提交顺序有关,且一次提交对应一次记录。而 redo log 记录的是物理页的修改,同一个事务中可能有多次记录。最后提交的事务会覆盖所有未提交的事务记录。如有事务A 有多个版本的操作记录 v-1、v-2、v-3,v-3 代表的记录是最后的操作结果,所以数据页最终的结果就是 v-3 操作的。redo log 是并发写入的,不同事务之间的不同版本的记录会穿插写入到 redo log文件中。
- redo log 具有幂等性,而 bin log 是记录所有影响数据的操作,记录的内容较多。
二 用途
如名所示,redo log 是重做日志,提供前滚操作。让 inndb 具有崩溃恢复能力从而支持事务,保证数据的持久性与完整性。
三 redo log 构成
redo log 由两部分组成:1. 处于内存中的日志缓存(redo log buffer); 2. 位于磁盘中的重做日志文件(redo log file)。如下图所示:
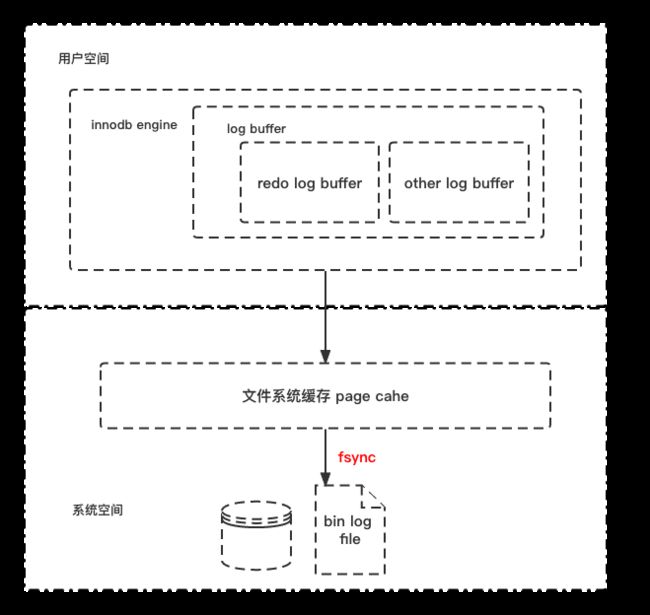
redo log 以块为单位进行存储的,每个块占512字节,称之为 redo log block。不管是存于缓存中 redo log 还是位于磁盘文件中的 redo log 都是以512字节为一块存储的。
3.1 日志块(log block)
每个redo log block由3部分组成:日志块头、日志块尾和日志主体。其中日志块头占用12字节,日志块尾占用8字节,所以每个 redo log block 的日志主体部分只有512-12-8=492字节。

日志块头包含4部分:
- log_block_hdr_no:(4字节) 记录该日志块在redo log buffer中的位置ID。
- log_block_hdr_data_len:(2字节) 记录该log block中已使用的log大小。写满该log block时为0x200,表示512字节。
- log_block_first_rec_group:(2字节) 记录该log block中第一个log的开始偏移位置。
- lock_block_checkpoint_no:(4字节) 记录写入检查点信息的位置。
3.2 日志组(log group)
log group 表示的是 redo log group,一个组内由多个大小完全相同的 redo log file 组成。
组是一个逻辑的概念,并没有真正的文件来表示这是一个组,但是可以通过变量 innodb_log_group_home_dir 来定义组的目录,redo log file 都放在这个目录下,默认是在datadir下。
组内 redo log file 的数量由变量 innodb_log_files_group 决定,默认值为2,即两个 redo log file。
-rw-r----- 1 mysql mysql 100663296 Jun 26 09:45 ib_logfile0
-rw-r----- 1 mysql mysql 100663296 Jun 26 09:45 ib_logfile1
在 innodb_log_group_home_dir 配置的路径下可以看到两个 ib_logfile 开头的文件,它们就是 log group 中的 redo log file。大小完全一致且等于变量 innodb_log_file_size 定义的值。
innodb 将 log buffer 中的 redo log block 刷到 log file 中时,会以追加写入的方式循环轮询写入。
即先在第一个log file(即ib_logfile0)的尾部追加写,直到满了之后向第二个log file(即ib_logfile1)写。当第二个log file满了会清空一部分第一个log file继续写入。
一个完整的 redo log block 如下图所示:
- 每个组的第一个 redo log file 前 2KB 不用来存储 log block, 而是用于记录一些特定的信息。
- 除了第一个 redo log file 会记录之外,同组的其他 file 会空出这部份空间不做使用。

四 redo log 格式
众所周知 Innodb 是以页为单位存储数据,redo log 也是一样的(buffer 和 磁盘中均是如此)。 innodb 默认页大小是 16 KB , 所以是一个页是可以存储很多 log block(图 5-2 呈现 log block 的结构)。
每个 log block 中有 492 字节是可以用来存储数据页变化信息的 body 部分,其可分为 4 部分:
- redo_log_type:(1字节)日志类型。
- space :(4字节)表空间ID。
- page_no: 页偏移量。
- redo_log_body: redo log 真正存储数据部分。
尽管大致上结构是一致的,但是如 insert 和 delete 还是有着些差异:

五 刷盘时机
我们都知道 redo log 是先写到 redo log buffer 中,由参数 innodb_log_buffer_size 控制 redo log buffer 大小,默认 16 MB。这个值其实已经够大了,毕竟是记录页的物理修改信息。
未刷到磁盘的日志称为脏日志(dirty log),满足一些时机就会触发持久化到磁盘中。其中以下几种时机会触发写入到磁盘中:
- 由参数 innodb_flush_log_at_trx_commit 设置, 如 =1 代表事务每次提交的时候都会刷事务日志到磁盘中。
- 由参数 innodb_flush_log_at_timeout 设置,默认 1 秒刷新一次到磁盘中,该频率不受事务是否提交的影响。
- 已使用的内存超过 redo log buffer 一半时。
- checkpoint 动作发生时,该内容较为重要将在下一小节详细介绍。
- MySQL 正常关机时。
六 checkpoint
checkpoint 是一个将 buffer pool 中脏数据页和脏日志页刷到磁盘的动作,因为 buffer pool 的容量是有限的,不可能将所有 redo log 存放在缓冲池中。
分为两种类型:
- sharp checkpoint :重用redo log文件(例如切换日志文件)的时候,将所有已记录到 redo log 中对应的脏数据刷到磁盘。
- fuzzy checkpoint :每次只刷部分到磁盘,其中又分为几种情况:
2.1 master thread checkpoint:master线程控制,每秒或每10秒刷入一定比例的脏页到磁盘。
2.2 flush_lru_list checkpoint:MySQL5.6开始可通过参数 innodb_page_cleaners 指定脏页刷盘的 page cleaner 线程的个数,该线程的目的是为了保证 lru 列表有可用的空闲页。
2.3 async/sync flush checkpoint:异步/同步刷盘。
2.4 dirty page too much checkpoint:过多的脏页触发刷盘,由参数 innodb_max_dirty_pages_pct 控制。如:MariaDB-10 值为 90 ,代表脏页使用缓冲池 90% 将强制将部分脏页刷到磁盘中。
可以用下图来描述 redo log 和 checkpoint 动作是如何循环写的。假如启用了 4个 redo log,从 0 号文件向 3 号文件方向写,其中:
- write pos 是当前记录的位置,一边写一边后移。
- check point 是当前要刷盘的位置,也是往后推移并且循环的。
- write pos 和 checkpoint 之间绿色部分是代表空闲的,黄色部分代表已经写满了脏页,等待刷入磁盘。

write pos 表示 redo log 当前记录的 LSN (逻辑序列号) 位置,一边写一遍后移。
check point 表示数据页更改记录刷盘后对应 redo log 所处的 LSN (逻辑序列号) 位置,也是往后推移并且循环的。
七 LSN 分析
LSN (log sequence number) 日志的逻辑序列号,占用 8 个字节,其值会随日志的不断写入而增加。
用于实现 crash-save ,如 innodb 重启时会检查磁盘中数据页的 LSN,如小于日志中 check point (见图 5-5)的 LSN 。则将会重 check point 点开始重放恢复数据。
LSN 存在于数据页(包括 buffer pool 和磁盘中)、redo log(包括 buffer pool 和磁盘中)。
使用 show engine innodb status 查看当前各种 LSN 情况:
mysql> show engine INNODB STATUS;
...
# 省略一些与本节不相关的的信息
LOG
---
Log sequence number 59816
Log flushed up to 59816
Pages flushed up to 56169
Last checkpoint at 53898
0 pending log flushes, 0 pending chkp writes
17 log i/o's done, 0.40 log i/o's/second
从上面信息可直观的到有 4 种 LSN:
- Log sequence number: redo log 当前在 buffer 中的 LSN。
- Log flushed up to:redo log 当前刷到磁盘中的 LSN。
- Pages flushed up to:数据页当前刷到磁盘中的 LSN。
- Last checkpoint at:上一次检查点所在位置的 LSN。
为了便于直观了解上述请在在一个事务过程中的情况,下面将定义几种 LSN 并体现在一个时序图中情况。
- data_lsn_in_buffer : buffer 中数据页 LSN。事务开始修改 buffer 中数据页,并在 buffer 中记录数据页 LSN。
- data_lsn_on_disk: 磁盘中数据页 LSN。
- redo_log_lsn_in_buffer:buffer 中 redo log LSN。修改数据页的同时,innodb 往 redo log in buffer 中写入redo log,并记录下对应的LSN 。
- redo_log_lsn_on_disk:磁盘中 redo log LSN。触发刷盘时机并将 buffer 中 redo log 刷到磁盘中。
- check_point_lsn:触发 checkpoint 将内存中的脏页(数据脏页和日志脏页)刷到磁盘,并在完成时在 redo log 中记住 checkpoint LSN 。
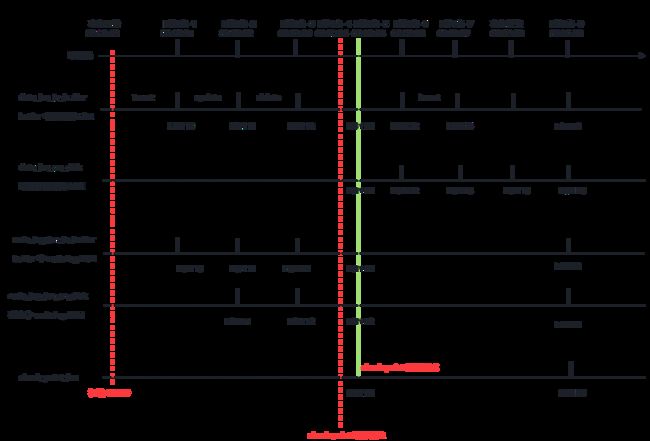
分析上图:
事务开始前,假设此时日志页和数据页都是全部刷到磁盘中,此时上面 4 种 LSN 的值都是相同的并等于 9 。
注意一个知识点: log flushed up to 和 pages flushed up to 的大小无法确定,所以 redo log 和数据页刷盘快慢是不确定的。但是 checkpoint 机制会控制 数据页刷盘速度慢于 redo log ,当数据页刷盘速度超过 redo log 时,将会暂时停止数据页刷盘,等待 redo log 刷盘进度超过数据刷盘。
- 事务开始并执行了一个 insert 操作,此时在 buffer 中的数据页和 redo log 都记录了插入后的新值 10。这时 4 种 LSN 的关系如下:
log sequence number(10) > log flushed up to(9) = pages flushed up to(9) = last checkpoint at(9)
- 在时间点-1(00:00:01) 和 时间点-2(00:00:02) 间执行了更新操作,一秒后的时间点-2(00:00:02)触发了 redo log 一个刷盘机制( 假设 innodb_flush_log_at_timeout=1),此时 redo log 在 buffer 和 磁盘中 LSN 是一致的,数据页还没刷盘故是小于 redo log 中。 这时 4 种 LSN 的关系如下:
log sequence number(11) = log flushed up to(11) > pages flushed up to(10) = last checkpoint at(10)
- 在时间点-2(00:00:02) 和 时间点-3(00:00:03) 间执行了删除操作,LSN 增加到 12。在时间点-4位置发生了 check point ,此时会将 数据页和 redo log 进行刷盘。时间点-4~时间点-5之间是刷盘所需要的时间,在此期间 checkpoint 的 LSN 还是上一次的,但此时磁盘中数据页和 redo log 中 LSN 已经是新的 12。这时 4 种 LSN 的关系如下:
log sequence number > log flushed up to # 在此期间 redo log 在 buffer 中 LSN 是大于磁盘中的。
pages flushed up to > last checkpoint at # 在此期间 数据页的 LSN 是大于 checkpoint LSN (还停留在上一次的)。
- 在时间点-5(00:00:05) 时 数据页和 redo log 页刷盘完毕,所有 LSN 都是一致的。
- 在时间点-6(00:00:06) 时 发生了插入操作,LSN 增加为 13。接下来的 时间点-7时 的各种 LSN 状态和在时间点-1时一致。
- 在时间点-8(00:00:08) 时 事务提交了,默认情况下会触发 redo log 刷盘,但是不会触发数据页刷盘。这时 4 种 LSN 的关系如下:
log sequence number(13) = log flushed up to(13) > pages flushed up to(12) = last checkpoint at(12)
八 基于 checkpoint 恢复
需要知道的是:innodb 在每次启动时,不管上次关闭是正常还是异常的,都会进行尝试恢复操作。
innodb 启动时,磁盘中 checkpoint 代表已经完整刷到磁盘中数据页的 LSN,所以恢复时仅需从 checkpoint 开始的部分。
如:上次的 checkpoint LSN 为 100,且事务是已经提交状态(没有提交就没有必要恢复,不过也要看位于两阶段提交的那个时段)。此时发生宕机,在启动时候数据库会检查数据页中的 LSN,若小于 redo log 中的 LSN,则会从 checkpoint 进行重放 redo log 进行恢复。
如:checkpoint 时发生宕机且数据页刷盘进度大于 redo log 刷盘进度,此时数据页中 LSN 必然是大于 redo log 中 LSN。此种情况在恢复时候判断超过 redo log LSN 的部分不会进行重做(没有必要重放)。
九 相关参数
- innodb_flush_log_at_trx_commit={0|1|2} 指定何时将事务日志刷到磁盘,默认为1。
0 表示每秒将 log buffer 同步到 os buffer 且从 os buffer 刷到磁盘日志文件中。
1 表示每个事务提交都将 log buffer 同步到 os buffer 且从 os buffer 刷到磁盘日志文件中。
2 表示每个事务提交都将 log buffer 同步到 os buffer,但每秒才从 os buffer 刷到磁盘日志文件中。 - innodb_log_buffer_size: log buffer 的大小,默认 16M。
- innodb_log_file_size:事务日志的大小,默认 10M
- innodb_log_files_group =2:事务日志组中的事务日志文件个数,默认2个
- innodb_log_group_home_dir =./: 事务日志组路径,当前目录表示数据目录