操作系统实验(二)——进程通信与置换算法
目录
一、实验内容
二、实验成果与结论
2.1 进程的软中断通信
2.1.1 关于lockf函数的研究
2.1.2 改进方法
2.1.3 实验结论
2.2 进程中的管道通信
2.2.1 管道的创建与关闭
2.2.2 read函数
2.2.3 write函数
2.2.4 管道通信的最终实现:
2.2.5 结论
2.3 置换算法
2.3.1 FIFO算法
2.3.2 LRU算法
一、实验内容
1、完成进程的软中断通信;
2、完成进程的管道通信;
3、内存分配与回收;
二、实验成果与结论
2.1 进程的软中断通信
为了解决中断处理执行过长和中断丢失的问题Linux将中断分为了上下两个部分:
·上半部用来快速处理中断,在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作;
·下半部分用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
软中断信号(signal)用来通知进程发生了什么,软件之间可以调用kill来发送软中断信号。
#include
#include
#include
#include
#include
void waiting(),stop(),alarming();
int wait_mark;
int main()
{
int p1,p2;
if(p1=fork())//创建子进程p1
{
if(p2=fork())//创建子进程p2
{
wait_mark=1;
//设置信号的处理方式。
signal(SIGINT,stop); //接收到键盘中断信号,转stop函数
signal(SIGALRM,alarming);//接受SIGALRM,转alarming函数
//设置程序对信号的处理方式。
kill(p1,16); //向p1发软中断信号16
kill(p2,17); //向p2发软中断信号17
wait(0);
wait(0);//同步,等待前面的所有子进程全部执行完才继续
printf("parent process is killed!\n");
exit(0);//进程自我终止
}
else
{
wait_mark=1;
signal(17,stop);
signal(SIGINT,SIG_IGN);//如果发生SIGINT信号则中断,转去执行SIG_IGN函数。
printf("child process2 is killed by parent!\n");
exit(0);//进程自我终止
}
}
else
{
wait_mark=1;
signal(16,stop);
signal(SIGINT,SIG_IGN);//如果发生SIGINT信号则中断,转去执行SIG_IGN函数。
printf("child process1 is killed by parent!\n");
exit(0);
}
return 0;
}
void alarming()
{
wait_mark=0;
}
void stop()
{
wait_mark=0;
} 我们对源码进行分析:使用系统调用fork()创建两个子进程,再用系统调用signal()让父进程捕捉键盘上来的中断信号,捕捉到中断信号后,父进程用系统调用kill()向两个子进程发出信号,子进程捕捉到信号后分别输出:
child process1 is killed by parent!
child process2 is killed by parent!父进程等待两个子进程终止之后,输出以下信息后终止:
parent process is killed!该段程序中使用了大量的signal函数,具体的做出解释:
SIGINT——程序终止信号,用户键入Ctrl+C发出,用于通知前台进程组终止进程。
SIGALRM ——安装SIGALRM信号之后就可以利用Linux提供的
定时器功能该定时器提供了以秒为单位的定时功能。在定时器设置的超时时间到达后,调用alarm的进程将收到SIGALRM信号。
因此,当我们执行程序时,会出现下面的情况:

2.1.1 关于lockf函数的研究
lockf()函数:对指定区域(有size指示)进行加锁或解锁,以实现进程的同步或互斥。
lockf(fd,mode,size)其中:
·fd:文件描述字;
·mode:锁定方式,mode=1表示加锁,mode=0表示解锁;
·size:指定文件fd的指定区域,用0表示从当前位置到文件结尾。
可以设计一个程序达成实验目的:首先在父进程中创建了一个子进程,子进程需要输出3次文本信息,并且在输出语句执行之前,将标准输出设备锁住,在输出语句执行之后,将标准输出设备解锁。同样,父进程也是要输出3次文本信息,对标准输出的操作同子进程。
因此,我们预期,实验结果不会出现在输出“Parents process: a”的时候,中间穿插有“This is child process : b”
#include
#include
#include
int main()
{
int pid ,i;
if((pid = fork())<0)
{
printf("child fails to create\n");
return 0;
}
else if (pid ==0)
{
lockf(1,1,0);
for(i = 0;i<3;i++)
printf("This is child (pid = %d)process:b\n",getpid());
lockf(1,0,0);
return 0;
}
else
{
lockf(1,1,0);
for(i =0;i<3;i++)
printf("Parent process:a\n");
lockf(1,0,0);
}
} 实验结果如下:

因此,我们可以认为lockf()函数具有实现进程互斥的功能
2.1.2 改进方法
按照ppt中的代码进行实验,我们会发现得到的结果并不完全满足预期,会出现“child process1 is killed by parent!”和“child process2 is killed by parent!”的输出顺序发生替换。这是因为两个子进程收到信号和退出的顺序发生了替换导致的,因此我们利用lockf函数实现进程之间的互斥和同步。
#include
#include
#include
#include
#include
void waiting(),stop(),alarming();
int wait_mark;
int main()
{
int p1,p2;
if(p1=fork())//创建子进程p1
{
if(p2=fork())//创建子进程p2
{
wait_mark=1;
//设置信号的处理方式。
signal(SIGINT,stop); //接收到键盘中断信号,转stop函数
signal(SIGALRM,alarming);//接受SIGALRM,转alarming函数
waiting();
//设置程序对信号的处理方式。
kill(p1,16); //向p1发软中断信号16
kill(p2,17); //向p2发软中断信号17
wait(0);
wait(0);//同步,等待前面的所有子进程全部执行完才继续
waiting();
printf("parent process is killed!\n");
exit(0);//进程自我终止
}
else
{
wait_mark=1;
signal(17,stop);
signal(SIGINT,SIG_IGN);//如果发生SIGINT信号则中断,转去执行SIG_IGN函数。
while (wait_mark!=0);
lockf(1,1,0);//上锁,完成进程互斥
printf("child process2 is killed by parent!\n");
lockf(1,0,0);//解锁
exit(0);//进程自我终止
}
}
else
{
wait_mark=1;
signal(16,stop);
signal(SIGINT,SIG_IGN);//如果发生SIGINT信号则中断,转去执行SIG_IGN函数。
while (wait_mark!=0)
lockf(1,1,0);//lockf(fd,1,0)是给fd文件上锁
printf("child process1 is killed by parent!\n");
lockf(1,0,0);//解锁
exit(0);
}
return 0;
}
void waiting()
{
sleep(5);//挂起
if (wait_mark!=0)
kill(getpid(),SIGALRM);
}
void alarming()
{
wait_mark=0;
}
void stop()
{
wait_mark=0;
} 2.1.3 实验结论
-
你最初认为运行结果会怎么样?
child process1 is killed by parent! child process2 is killed by parent! parnet process is killed ! -
实际的结果什么样?有什么特点?试对产生该现象的原因进行分析。
实际的实验结果并不满足预期,这是因为两个子进程收到信号和退出的顺序可能发生调换,子程序退出的顺序是不可预期的。其实质为进程执行的不可再现性和不可预知性。
-
kill 命令在程序中使用了几次?每次的作用是什么?执行后的现象是什么?
kill 系统调用在程序中使用了两次。
第一次是给子进程 1 发送 16 号软中断,执行后子进程 1 输出
child process1 is killed by parent!!之后退出。第二次是给子进程 2 发送 17 号软中断,执行后子进程 2 输出
child process2 is killed by parent!!之后退出。 -
使用kill 命令可以在进程的外部杀死进程。进程怎样能主动退出?这两种退出方式哪种更好一些?
使用
exit(错误码)可以使进程主动退出,错误码为零表示正常退出。我认为进程主动退出更好,因为进程可能持有了各种资源如文件、套接字、设备、互斥锁等。进程主动退出可以释放这些资源,避免资源没能正确释放导致系统进入异常状态。
-
如果程序运行,界面上显示“Child process 1 is killed by parent !! Child process 2 is killed by parent !!”,五秒之后显示“Parent process is killed !!”,怎样修改程序使得只有接收到相应的中断信号后再发生跳转,执行输出?
在两个子进程结束之后,调用sleep函数。
2.2 进程中的管道通信
进程与进程之间是相互独立的,各自运行在自己的虚拟内存之中,要想实现进程间通信就必须借助内核,在内核中开辟一个缓冲区,两个进程的信息在此区域进程交换或者传递。
在Linux系统中,常见的进程间通信有:管道通信、共享内存通信、信号量通信。本次实验使用管道通信。
管道主要用于父子进程或者兄弟进程之间的数据读取,命名管道可以在无关联的的进程间进程数据传递。值得注意的是,在Linux系统中的进程通信中,管道通信某一时刻只能单一方向传递数据,不能双向传递数据,采用半双工模式。
管道由Linux系统提供的pipe()函数创建,此函数只是创建了管道,要从管道中读取或写入数据,需要使用read()或write()函数,当管道通信结束之后,需要使用close()来关闭管道的读写端。
2.2.1 管道的创建与关闭
pipe()函数的原型为:int pipe(int filedes[2]);pipe()函数用于在内核中创建一个管道,在创建一个管道后,会获得一对文件描述符,用于读取和写入,然后将参数数组filedes中的两个值传递给获取到的两个文件描述符,filedes[0]指向管道的读端,filedes[1]指向写端。pipe()函数调用成功,返回值为0;否则返回-1,并且设置了适当的错误返回信息。
使用pipe()实现管道通信:
(1)在父进程中调用pipe()函数创建一个管道,产生一个文件描述符filedes[0]指向管道的读端和另一个文件描述符filedes[1]指向管道的写端。
(2)在父进程中调用fork()函数创建一个子进程。父进程的文件描述符一个指向读端,一个指向写端。子进程同理。
(3)在父进程关闭指向管道写端的文件描述符filedes[1],在子进程中,关闭指向管道读端的文件描述符filedes[0]。此时,就可以将子进程中的某个数据写入到管道,然后在父进程中,将此数据读出来。
2.2.2 read函数
read函数原型:ssize_t read(int fd,void *buf,size_t count)
函数返回值分为下面几种情况:
1、如果读取成功,则返回实际读到的字节数。这里又有两种情况:
一是如果在读完count要求字节之前已经到达文件的末尾,那么实际返回的字节数将 小于 count值,但是仍然大于0;
二是在读完count要求字节之前,仍然没有到达文件的末尾,这是实际返回的字节数等于要求 的count值。
2、如果读取时已经到达文件的末尾,则返回0。
3、如果出错,则返回-1。
2.2.3 write函数
·功能:向文件中写入数据
·头文件:#include
·函数原型:write(int fd, void *buf,size_t count)
·参数:fd:文件描述符;
buf:存放要写入的数据的缓冲区首地址;
count:想要写入的字节数
·返回值:大于0,成功写入;等于0,没写入;小于0,写入失败
2.2.4 管道通信的最终实现:
代码如下:
#include
#include
#include
#include
#include
#include
#include
int pid1, pid2;
char buf[100];
int main() {
int fd[2];
pipe(fd);
lockf(fd[1], 0, 0);
while ((pid1 = fork()) == -1);
if (pid1 == 0) {
// 子进程 1
sprintf(buf, "1");
for (int i = 0; i < 200; i++) {
lockf(fd[1], 1, 0);
write(fd[1], buf, 1); // 向管道写入数据
lockf(fd[1], 0, 0);
sched_yield(); // 让出执行权限
}
exit(0);
} else {
while ((pid2 = fork()) == -1);
if (pid2 == 0) {
// 子进程 2
sprintf(buf, "2");
for (int i = 0; i < 200; i++) {
lockf(fd[1], 1, 0);
write(fd[1], buf, 1); // 向管道写入数据
lockf(fd[1], 0, 0);
sched_yield(); // 让出执行权限
}
exit(0);
} else {
wait(0);
wait(0);
read(fd[0], buf, 400); // 从管道中读出数据
printf("%s", buf);
exit(0); // 父进程结束
}
}
return 0;
} 运行结果如下:
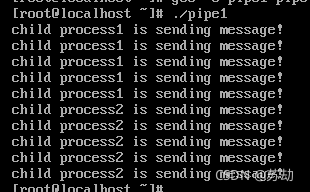
可以认为成果达到实验目标。
2.2.5 结论
1.你最初认为运行结果会怎么样?
Child process 1 is sending message!
Child process 1 is sending message!
Child process 1 is sending message!
Child process 1 is sending message!
Child process 1 is sending message!
Child process 2 is sending message!
Child process 2 is sending message!
Child process 2 is sending message!
Child process 2 is sending message!
Child process 2 is sending message!- 实际的结果什么样?有什么特点?试对产生该现象的原因进行分析。
实际结果满足预期。看到进程 1 先创建,所以进程 1 先输出。推测由于进程 1 在循环中没有 主动让出时间片,直接一连输出了五次。
-
实验中管道通信是怎样实现同步与互斥的?如果不控制同步与互斥会发生什么后果?
通过
lockf()实现互斥。如果不控制互斥可能导致消息混乱,对于较短的消息(小于PIPE_BUF),Linux 内核保证了写入 pipe 的原子性。同时,对于读写进程,通过内核中的pipe缓冲区实现进程间同步;对于写者,pipe 满时阻塞写入,对于读者,pipe 空时阻塞读取,这样两个或多个进程之间可以实现同步。
2.3 置换算法
2.3.1 FIFO算法
FIFO 算法是一种比较容易实现的算法。它的思想是先进先出,这是最简单、最公平的一种思想,即如果一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。空间满的时候,最先进入的数据会被最早置换(淘汰)掉。
实现:维护一个FIFO队列,按照时间顺序将各数据(已分配页面)链接起来组成队列,并将置换指针指向队列的队首。再进行置换时,只需把置换指针所指的数据(页面)顺次换出,并把新加入的数据插到队尾即可。
缺点:判断一个页面置换算法优劣的指标就是缺页率,而FIFO算法的一个显著的缺点是,在某些特定的时刻,缺页率反而会随着分配页面的增加而增加,这称为Belady现象。产生Belady现象现象的原因是,FIFO置换算法与进程访问内存的动态特征是不相容的,被置换的内存页面往往是被频繁访问的,或者没有给进程分配足够的页面,因此FIFO算法会使一些页面频繁地被替换和重新申请内存,从而导致缺页率增加。因此,现在不再使用FIFO算法。
下面是具体实现:

这个说明一下为什么不用容器Queue。是因为queue并没有迭代器,所以无法去寻找里面是否含有某块页面。 直接使用线性表即可,方便简单且快速。实现代码如下:
#include
using namespace std;
#define MAX 20
class Work
{
public:
void seta()
{
int i = 0;
cout << "输入10个页面号,以任意符号结尾" << endl;
for(int i=0;i<10;i++)
{
cin>>a[i];
}
}
void geta()
{
cout << "10个页面号分别为: ";
for (int i = 0; i < 10; i++)
{
cout << a[i] << " ";
}
cout << endl;
}
int index(int i)
{
return a[i];
}
~Work()
{
cout<<"work 已被释放"<>num;
space s(num);
a.seta();
a.geta();
FIFO(a,s);
return 0;
} 运行编译后,结果如下:
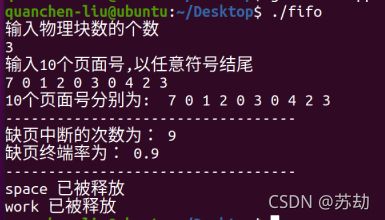
可以认为,达到实验目标。
2.3.2 LRU算法
LRU(The Least Recently Used,最近最久未使用算法)是一种常见的缓存算法,在很多分布式缓存系统(如Redis, Memcached)中都有广泛使用。
LRU算法的思想是:如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被置换(淘汰)。
实现:最朴素的思想就是用数组+时间戳的方式,不过这样做效率较低。因此,我们可以用双向链表(LinkedList)+哈希表(HashMap)实现(链表用来表示位置,哈希表用来存储和查找)。在实现时将其主要衡量指标设定为使用的时间,附加指标设定为使用次数
LRU Cache具备的操作:
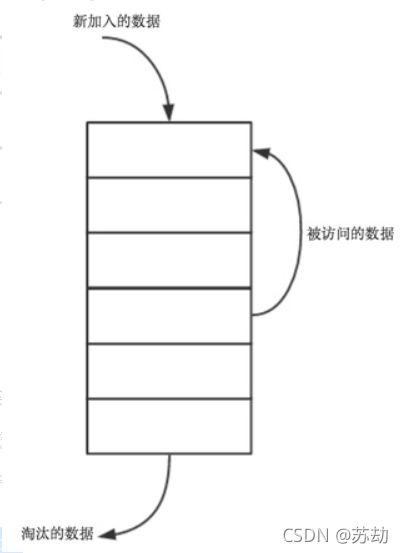
·set(key,value):如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。具体可见下图:
·get(key):如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;如果不存在,则返回-1。 具体代码实现如下:
#include
#include 在上面的程序中,我们设计的容器容量为2,key=2的热度为2,key=1的热度为1。因此,key=2在链表头部,key=1在链表尾部。当调用函数,令key=4时,将该节点插入链表头部,并删除链表尾部的key=1的节点。因此,预期输出结果为:
1 1 1 -1 1
实际输出结果如下:

可以认为达到目的。