STL——list详解

一、list基本使用

1.1 初始化

在C++11之前,std::list容器没有提供初始化列表的构造函数,因此需要使用push_back或push_front函数向列表中添加元素。以下是一些常见的std::list初始化方式:
- 使用默认构造函数创建空列表
std::list<int> mylist;
- 使用列表初始化语法创建列表
std::list<int> mylist = {1, 2, 3};
- 使用指定大小和默认值创建列表
std::list<int> mylist(5, 0); // 创建一个包含5个0的列表
- 使用迭代器创建列表
int arr[] = {1, 2, 3};
std::list<int> mylist(arr, arr+3);
- 复制另一个列表来创建一个新列表
std::list<int> mylist1 = {1, 2, 3};
std::list<int> mylist2(mylist1);
- 使用移动语义从另一个列表创建一个新列表
std::list<int> mylist1 = {1, 2, 3};
std::list<int> mylist2(std::move(mylist1));
注意,使用移动语义可以更高效地将一个列表复制到另一个列表中,因为它避免了在内存中进行大量的数据复制。
经过std::move操作后,mylist1的内部资源所有权已经被转移,因此mylist1不再拥有自己的数据。使用mylist1的任何操作(如访问、修改、遍历等)都将导致未定义行为。因此,如果需要继续使用mylist1,应该在std::move之前将其清空,或者将其重新初始化为一个新列表。
1.2 常用接口
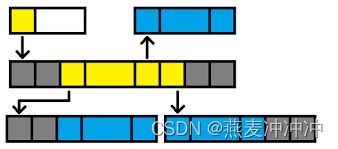
std::list是C++ STL标准库中的一个容器,它实现了一个双向链表。以下是一些常见的std::list的使用方式:
- 在列表的末尾添加元素
std::list<int> mylist;
mylist.push_back(1);
mylist.push_back(2);
mylist.push_back(3);
- 在列表的开头添加元素
std::list<int> mylist;
mylist.push_front(1);
mylist.push_front(2);
mylist.push_front(3);
- 遍历列表中的元素
std::list<int> mylist = {1, 2, 3};
for (auto it = mylist.begin(); it != mylist.end(); ++it) {
std::cout << *it << " ";
}
// Output: 1 2 3
- 在指定位置插入元素
std::list<int> mylist = {1, 2, 3};
auto it = mylist.begin();
++it;
mylist.insert(it, 4);
// mylist: {1, 4, 2, 3}
- 删除指定位置的元素
std::list<int> mylist = {1, 2, 3};
auto it = mylist.begin();
++it;
mylist.erase(it);
// mylist: {1, 3}
- 反转列表中的元素
std::list<int> mylist = {1, 2, 3};
mylist.reverse();
// mylist: {3, 2, 1}
- 排序列表中的元素
std::list<int> mylist = {3, 1, 2};
mylist.sort();
// mylist: {1, 2, 3}
二、list接口使用注意事项
2.1 list等stl容器要交换时,尽量使用自身成员函数swap

如果您要交换两个 std::list,建议使用 std::list::swap,因为它可以更高效地交换两个链表,而不需要将它们的元素逐个复制到另一个链表中。
当您调用 std::list::swap 时,它只需要交换两个指针,这样就可以快速地完成操作。但是,当您使用 std::swap 时,它会使用元素类型的默认交换操作来交换两个链表的内容,这将导致每个元素都需要进行拷贝构造、移动构造、析构等操作,相对来说是一种低效的方式。
std::list<T> lt1, lt2;
swap(lt1, lt2);
lt1.swap(lt2);
2.2 list排序sort的使用

//排升序
std::list<int> lt;
lt.sort();
//排降序
#include 三、迭代器分类及意义
3.1 按使用的功能
正向(const)迭代器
反向(const)迭代器
3.2 按底层结构
单向:只能++(单链表、哈希表)
双向:++/- -(双向链表、map)
随机:++/- -/+/-(string、vector、deque)
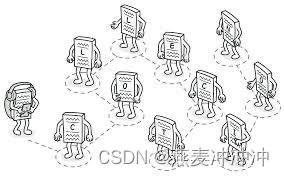
3.3 意义
迭代器的意义在于它提供了一种抽象的访问容器元素的方式,使得我们不需要关心容器内部的实现细节,只需要通过迭代器即可遍历容器中的元素,这样就大大降低了代码的复杂度和维护难度。
除此之外,迭代器还具有以下的优点:
- 与容器的实现相独立,使得可以将相同的代码应用于不同类型的容器。
- 可以使用迭代器算法来对容器中的元素进行排序、查找、删除等操作。
- 迭代器的使用可以提高代码的可读性和可维护性,使代码更加简洁明了。
总之,迭代器屏蔽了底层的算法,让容器的使用更加方便。所以迭代器是容器和算法的胶合剂。
3.4 单参数的构造函数支持隐式类型转换

单参数的构造函数可以支持隐式类型转换。这是因为当调用一个函数时,编译器会尝试自动将传入的参数转换为函数所需的参数类型,这被称为隐式类型转换。如果构造函数可以接受一个参数的隐式类型转换,那么编译器会自动将传入的参数转换为构造函数所需的类型,并且使用转换后的参数创建一个新对象。
例如,假设我们有一个类MyClass,它有一个单参数的构造函数,该参数为int类型。我们可以使用以下代码创建一个新的MyClass对象:
MyClass obj = 42;
在上面的代码中,整数42被隐式转换为MyClass对象,并使用该值调用MyClass类的单参数构造函数。这种隐式类型转换可以简化代码,并且可以使代码更容易阅读和理解。
比如下面模拟实现的list,在insert中,返回值直接返回newnode,返回值类型虽然是iterator,newnode类型为Node*,却依旧可以成功。
原因在于iterator的构造函数为单参数,参数类型为Node*,支持隐式类型转换,即将newnode转换为一个iterator对象。
3.5 迭代器的类模版深拷贝问题
迭代器类模版需要拷贝构造和赋值重载吗?需要重载析构函数吗?
都不需要。
迭代器的拷贝构造或者直接赋值,只需要浅拷贝即可。
只有在特定情况下,例如迭代器类模板的数据成员不是浅拷贝或其中包含指针等需要深拷贝的数据成员时,才需要手动实现拷贝构造函数和赋值运算符来确保正确的复制和赋值行为。
因此,是否需要手动实现拷贝构造函数和赋值运算符取决于具体情况,如果数据成员是浅拷贝的,可以使用默认的拷贝构造函数和赋值运算符,否则就需要手动实现它们。
四、list模拟实现
4.1 代码
这段代码实现了一个双向链表模板类 list,其中包含了节点结构体__list_node和迭代器结构体 __list_iterator。
__list_node 结构体的成员变量包括指向前驱节点和后继节点的指针 _prev 和 _next,以及存储数据的变量 _data。__list_node 还定义了一个带默认参数的构造函数,用于初始化_data变量。
__list_iterator 结构体的成员变量是指向__list_node的指针 _node,迭代器的作用是通过指向当前节点的指针 _node 访问当前节点的数据成员 _data,以及移动到前驱或后继节点。__list_iterator 还重载了迭代器操作符,如 *,->,==,!=,++ 等。
list 类使用了__list_node和 __list_iterator,实现了双向链表的操作,如构造函数,迭代器 begin 和 end,插入元素的 insert 函数,删除元素的 erase 函数,清空链表的 clear 函数,以及赋值操作符 =。其中,赋值操作符 = 还使用了 std::swap 函数实现了高效的交换操作。
在代码的最后,定义了一个打印链表的函数 print_list,它接受一个 const 的list类型的引用,使用const_iterator遍历链表并输出每个元素。
namespace yfy
{
template<class T>
struct __list_node //list类中的节点结构体
{
//带默认参数的构造函数
__list_node(const T& x = T())
:_next(nullptr)
,_prev(nullptr)
,_data(x)
{}
__list_node<T>* _next;
__list_node<T>* _prev;
T _data;
};
template<class T, class Ref, class Ptr>
struct __list_iterator //list类中的迭代器结构体
{
typedef __list_node<T> Node;
typedef __list_iterator<T, Ref, Ptr> self;
__list_iterator(Node* node) //构造函数
:_node(node)
{}
Ref operator*() {
return _node->_data;
}
Ptr operator->() {
return &(_node->_data);
}
bool operator==(const self& it)const {
return _node == it._node;
}
bool operator!=(const self& it)const {
return _node != it._node;
}
// 前置++
self& operator++() {
_node = _node->_next;
return *this;
}
// 后置++
self operator++(int) {
self tmp(*this);
//self tmp(_node);
_node = _node->_next;
return tmp;
}
Node* _node; //迭代器唯一的成员变量:__list_node结构体对象的指针
};
template<class T>
class list
{
public:
typedef __list_node<T> Node;
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
list()
{
_head = new Node; //调用__list_node的构造函数
_head->_next = _head;
_head->_prev = _head;
}
template <class InputIterator>
list(InputIterator first, InputIterator last) {
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
while (first != last) {
push_back(*first);
first++;
}
}
list(const list<T>& lt) {
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
list<T> tmp(lt.begin(), lt.end());
std::swap(_head, tmp._head);
}
iterator begin() {
return iterator(_head->_next);
}
iterator end() {
return iterator(_head);
}
const_iterator begin()const {
return const_iterator(_head->_next);
}
const_iterator end()const {
return const_iterator(_head);
}
iterator insert(iterator pos, const T& val) {
Node* newnode = new Node(val);
Node* cur = pos._node;
Node* prev = cur->_prev;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
void push_back(const T& x) {
insert(end(), x);
}
iterator erase(iterator pos) {
assert(pos != end());
Node* cur = pos._node;
Node* next = cur->_next;
Node* prev = cur->_prev;
delete cur;
prev->_next = next;
next->_prev = prev;
return iterator(next); //返回被删除节点的下一位置
}
void clear() {
iterator it = begin();
while (it != end()) {
it = erase(it);
}
}
list<T>& operator=(list<T> lt) {
swap(_head, lt._head);
return *this;
}
private:
Node* _head;
};
void print_list(const list<int>& lt) {
list<int>::const_iterator it = lt.begin();
while (it != lt.end()) {
cout << *it << " ";
it++;
}
cout << endl;
}
}
4.2 相关知识点

4.2.1 定义模版类格式
在C++中,定义模板类的格式如下:
template <typename T>
class MyClass {
public:
// class implementation
};
其中,typename T 表示模板类中的类型参数,可以根据实际需要自定义类型名称。
在模板类的实现中,可以使用类型参数 T 来定义类的成员变量和成员函数,以及对其进行操作。使用模板类时,需要在类名后面加上尖括号,指定类型参数的具体类型。
通过使用模板类,可以避免重复编写类似的代码,提高程序的复用性和可维护性。
类模版中的typename为什么可以替换为class?
typename 和 class 都可以用于指定模板参数的类型。
4.2.2 初始化列表
在C++中,定义构造函数时可以使用初始化列表,也可以不使用初始化列表。
如果在构造函数中不使用初始化列表,而是在函数体内分别给成员变量赋值,则会先调用成员变量的默认构造函数进行初始化,然后再进行赋值操作。这样会导致以下问题:
- 可能会造成不必要的性能开销。因为这种方式会先调用默认构造函数,再进行赋值操作,而使用初始化列表则可以直接在构造函数中完成初始化,避免了不必要的中间步骤。
- 对于const成员变量或者引用类型成员变量,如果不使用初始化列表,则无法在构造函数内部为其赋值。因为const成员变量必须在构造函数初始化列表中进行初始化,而引用类型成员变量也必须在构造函数初始化列表中指定其引用的对象。
因此,使用初始化列表可以避免不必要的性能开销,并且可以在构造函数内部初始化const成员变量和引用类型成员变量,使代码更加简洁和可读。
4.2.3 函数名后的const

在C++中,在函数声明和定义时可以在函数参数列表的括号后加上const关键字,表示该函数不会修改它所接受的对象的状态。这个const关键字称为常量成员函数,它的作用是告诉编译器,该函数不能修改对象的状态,从而在编译时进行一些优化。
常量成员函数具有以下特点:
- 常量成员函数不能修改类的成员变量,包括类的数据成员和非静态成员变量。
- 常量成员函数可以访问类的数据成员和非静态成员变量。
- 常量成员函数不能调用非常量成员函数,因为非常量成员函数可以修改类的状态,而常量成员函数不能修改类的状态。
使用常量成员函数可以提高代码的可读性和安全性,因为它明确表示该函数不会修改类的状态,从而避免了在代码中意外修改类的状态导致的错误。此外,使用常量成员函数还可以避免对常量对象进行非法的修改操作。
4.2.4 前置++和后置++
前置++是先++后使用,后置++是先使用后++,这个特性也就决定了它们重载的返回值。
前置++操作符会先对对象进行自增操作,然后返回自增后的对象。因此,返回的是对象的引用,以便可以在表达式中继续使用这个自增后的对象。
后置++操作符也会对对象进行自增操作,但是它会返回自增前的对象的副本,以便在表达式中使用原来的对象。因为它需要返回一个原来的对象的副本,所以返回的是对象的值。
前置++运算符的原型如下:
T& operator++();
该运算符返回一个T类型的引用,T是重载函数所属的类的类型。前置++运算符不需要任何参数。
后置++运算符的原型如下:
T operator++(int);
该运算符也返回一个T类型的值,但它需要一个int参数。这个int参数只是一个标记,用于区分前置和后置++运算符。
当编译器遇到一个++运算符时,它会检查参数列表,如果参数列表为空,则调用前置++运算符重载函数;如果参数列表为int,则调用后置++运算符重载函数。因此,即使前置++运算符和后置++运算符都返回一个T类型的值,它们的参数列表的不同也使得编译器可以区分它们并调用正确的函数。
4.2.5 MyList中const迭代器模版类型
第一个模版类型是T,不应该是const T,因为const_iterator中的const是修饰迭代器指向的数据类型,而不是修饰迭代器本身。
对于另外两个模版参数,在const_iterator中,Ref和Ptr分别表示迭代器指向的数据类型的引用和指针。由于const_iterator是const类型的迭代器,所以它不能修改迭代器指向的数据,但是需要能够访问到这些数据,因此需要使用const修饰Ref和Ptr,以保证它们能够指向const数据类型。
具体来说,const_iterator中的operator*()和operator->()函数返回的是const引用和const指针,以保证不能修改迭代器指向的数据。如果Ref和Ptr没有加const修饰,那么这两个函数返回的就是非const引用和非const指针,这将导致const_iterator无法正常工作。