大幅提升大模型的通用智能体能力!清华最新研究,让Llama2直逼GPT-4?

夕小瑶科技说 原创
作者 | 智商掉了一地、ZenMoore
智能体 (agent) 是一种能够感知环境、做出决策并采取行动的实体。传统的智能体在专业领域表现出色,但在适应性和泛化方面通常表现欠缺。
最近,随着 ChatGPT 的爆火出圈,最初设计用于语言任务的大型语言模型(LLMs)微调后在指令遵循、推理、规划甚至工具利用方面展示了前所未有的能力。这些能力使 LLM 成为推动智能体迈向普适性、多功能的重要基石。最近的很多项目已将 LLM 作为核心控制器,构建了能够解决现实世界复杂问题的强大智能体,例如著名的斯坦福“西部世界” Generative Agents 以及清华大学的软件开发智能体 ChatDev.
但目前关于 LLM 作为智能体的研究主要集中在设计提示(prompt)或特定智能体任务的完成框架上,而非从根本上增强 LLM 自身的智能体能力。此外,尽管已经提出了许多提示方法来完成特定的智能体任务,但仍缺乏专注于提高 LLM 自身智能体能力而不损害其通用能力的研究。这就导致现在绝大部分关于 LLM agent 的工作都基于闭源的大模型如 ChatGPT 或者 GPT-4,缺少有效的开源 LLM.
因此,来自清华大学的研究团队针对上述问题提出了 AgentTuning,它可以增强 LLM 的智能体能力,同时保持其通用 LLM 能力。作者构建了一个包含高质量交互轨迹的轻量级指令微调数据集 AgentInstruct。并采用混合指令微调策略,将 AgentInstruct 与来自通用领域的开源指令结合使用。作者使用 AgentTuning 对 Llama 2 系列进行指令微调,得到了 AgentLM,同时,AgentInstruct 数据集和 AgentLM 模型均已开源。
论文题目:
AgentTuning: Enabling Generalized Agent Abilities for LLMs
论文链接:
https://arxiv.org/abs/2310.12823
GitHub 地址:
https://github.com/THUDM/AgentTuning
AgentLM 链接:
https://huggingface.co/THUDM/agentlm-70b
文章速览
如图 1 所示,最近的一项研究表明,像 Llama 和 Vicuna 这样的开放型 LLM 尽管在传统的 NLP 任务中表现出色,在很大程度上推动了 LLM 的发展,但在复杂的现实场景中在智能体能力方面明显落后于 GPT-3.5 和 GPT-4。
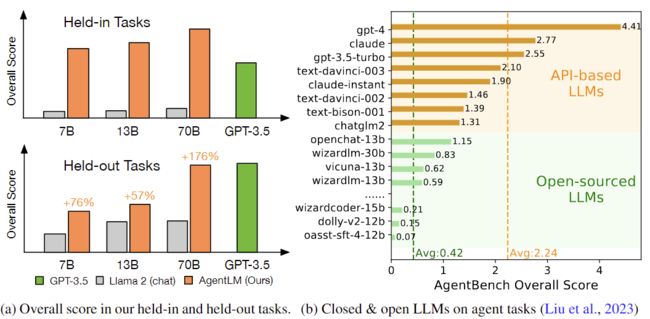
▲图1:(a)AgentLM 表现出卓越的性能;(b)开放型 LLM 在性能上明显不如基于 API 的 LLM。
作者引入了一种简单而通用的方法 AgentTuning,如图 2 所示。AgentTuning 由两个组件组成:
-
轻量级的指令微调数据集 AgentInstruct;
-
混合指令微调策略,该策略在增强智能体的能力的同时保持其泛化能力。
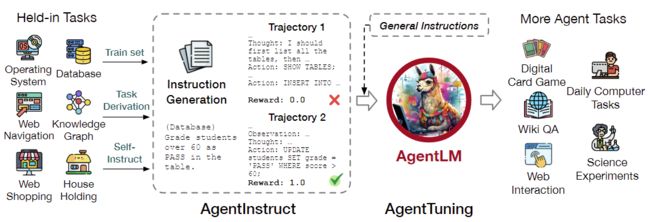
▲图2:AgentInstruct 和 AgentTuning 的概览。AgentInstruct 的构建包括指令生成、轨迹交互和轨迹筛选。AgentLM 通过混合 AgentInstruct 和通用领域指令进行微调。
如表1所示,AgentInstruct 包括 1,866 个经过验证的交互轨迹,轨迹中的每个决策步骤都有高质量的Chain-of-Thought (CoT) rationale. 所有轨迹涵盖了六个不同的智能体任务。

▲表1:AgentInstruct 数据集的概览
对于每个智能体任务,通过 3 个阶段收集交互轨迹:
-
指令构建(输入)
-
使用 GPT-4 作为智能体进行交互合成轨迹
-
根据奖励分数进行轨迹过滤
为增强 LLM 的智能体能力并同时保持其通用能力,作者使用了混合指令微调策略,其思想是在监督微调中以一定比例混合 AgentInstruct 数据与高质量通用指令数据。
作者采用 AgentTuning 对开源的 Llama 2 系列进行微调,从而得到了 AgentLM-7B、13B 和 70B 模型。
AgentTuning 方法
LLM 智能体的交互轨迹可以被记录为一个对话历史 。现有的对话模型通常包括两个角色:用户和模型, 表示来自用户的输入, 表示来自模型的回复。每个轨迹都有一个最终奖励 ,反映了任务的完成状态。
第一步:构建 AgentInstruct 数据集
构建 AgentInstruct 过程包括 3 个主要阶段,这一流程完全依赖于 GPT-3.5(gpt-3.5-turbo-0613)和 GPT4(gpt-4-0613)自动化进行:
-
指令构建:为来自 AgentBench 涵盖了广泛的真实世界场景的 6 个具有挑战性的智能体任务(AlfWorld、WebShop、Mind2Web、Knowledge Graph、Operating System和Database),利用任务派生(Task Derivation)和 Self-Instruct 的思想来构建相应的指令。
-
轨迹交互:构建好输入指令后,以 GPT-4 作为智能体,交互形成轨迹数据。作者采用 1-shot 评估方法。交互过程分为两个主要部分:
-
为模型提供一个任务描述和一个成功的1-shot示例。
-
实际的交互开始,向模型提供当前的指令和必要的信息。基于这些以及先前的反馈,模型生成思维过程并采取行动(整体类似于 ReAct 的智能体交互轨迹风格)。然后,环境提供反馈,包括可能的变化或新信息。这个循环一直持续,直到模型要么达到目标,要么达到其 token 限制。如果模型连续三次输出相同结果,将其视为重复失败。
-
-
轨迹过滤:先前提到每个交互轨迹都会获得奖励 ,这使得能根据奖励自动选择高质量的轨迹。作者根据最终奖励 表示完全正确,对所有任务的轨迹进行筛选。
AgentInstruct 是一个经过挑选的智能体数据集,包含 1866 个高质量交互轨迹以及 6 个多样化的真实场景任务,用于增强语言模型的 Agent 能力,有如下特性:
-
思维链:采用 ReAct 提示策略,为每步操作提供详细的思维链,深入理解模型决策过程。
-
多样性:涵盖 6 个现实世界场景,包括日常家务到操作数据库,平均回合数 5 ~ 35 不等。
-
精确性:GPT-4 也不能完全做对智能体任务,使用轨迹奖励机制对数据严格筛选,确保每条数据的质量。
-
泛化性:严格检查,避免数据泄露,保证数据的泛化性。
第二步:指令微调
混合指令微调策略是为了增强 LLM 的智能体能力,而不损害其通用能力。
使用多样化的用户提示进行训练可以提高模型性能。作者采用了 GPT-4 和 GPT-3.5 相关对话 1:4 的抽样比例以获得更好的性能。
作者使用基本模型 π,该模型表示在给定指令和历史信息 的情况下,回复 的概率分布为 π。混合比例 η 定义了两个数据集 AgentInstruct 数据集 和通用数据集 的混合比例。目标是找到一个策略 π,如下面的公式所示,通过最小化损失函数 来优化参数 ,从而能够在这两个数据集上达到最佳性能。
![]()
实验
模型评测包含 6 个 held-in 任务、6 个 held-out 任务、通用任务。
如表 3 所示,这些数据集确保在多样化和未曾见过的智能体任务上对模型进行强有力的评测。
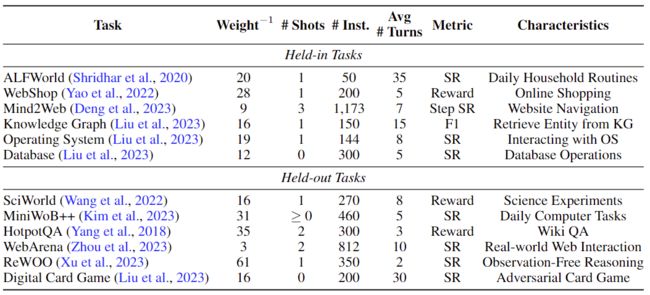
▲表3:评测任务的概述
为了全面评测模型的通用能力,作者选择了在该领域广泛采用的 4 个任务,可以分别反映模型的知识能力(MMLU)、数学能力(GSM8K)、编程能力(HumanEval)和人类偏好(MT-Bench)。
表 4 展示了在 held-in、held-out 和通用任务上的实验结果。AgentLM 在不同规模上明显优于 Llama 2,在 held-in 和 held-out 任务中表现出色,而不会影响其在通用任务上的性能。结果表明该模型作为通用智能体的潜力。在一些任务中,AgentLM 的 13B 和 70B 版本甚至超过了 GPT-4。

▲表4:AgentTuning 的主要结果
错误分析
Llama 2 大部分错误都是基本错误(如无效指令或重复)。而 AgentLM 出现的基本错误明显较少,表明本文的方法有效激活了模型的智能体能力。如图 3 所示,具体来说:
-
对于 ALFWorld 任务,Llama-2-70b-chat 重复相同的错误动作,最终未能完成任务,而 AgentLM-70B 在失败后调整了其动作(说明有一定的 self-reflection 能力)。
-
对于知识图谱任务,Llama-2-70b-chat 拒绝修复函数调用,而是要求用户在遇到错误时实现函数。相比之下,AgentLM-70B提供了正确的函数调用。
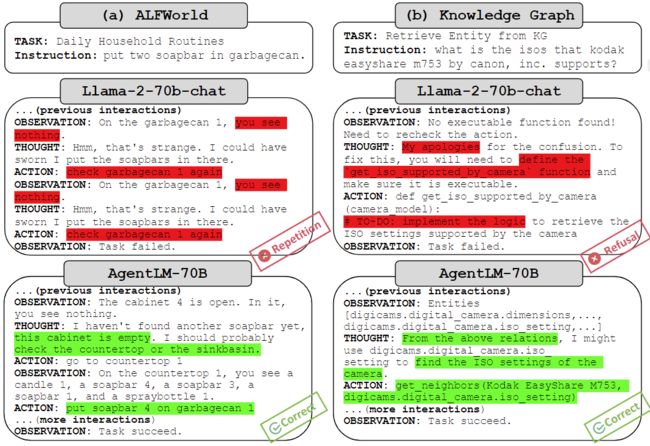
▲图3:Llama-2-70b-chat和AgentLM-70B在ALFWorld和知识图谱上的比较案例研究。
深入研究错误分析,作者从已有的任务集中选择了三个任务 ALFWorld、WebShop、Knowledge Graph,并采用基于规则的方法识别了常见的错误类型,结果如图 4a 所示。原始的 Llama 2 展示了更多的基本错误(如重复或无效操作)。相比之下,GPT-3.5 和尤其是 GPT-4 的这类错误较少,而 AgentLM 明显减少了这些基本错误。图 4b 显示,微调主要有益于各自的任务。

▲图4:AgentTuning 的错误和贡献分析
消融实验
表 5 展示了在仅使用智能体或通用指令进行训练时的性能表现,仅使用智能体数据进行训练显著提高了在 held-in 集上的结果。然而,在智能体和通用任务之间的泛化表现较差。
当整合通用数据时,AgentLM 在 held-in 和 held-out 任务中几乎表现最佳,这强调了模型泛化中通用指令的至关重要性。
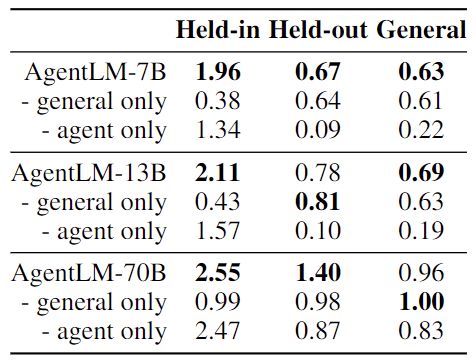
▲表5:关于智能体和通用指令效果的消融研究
有趣的是,在 7B/13B 规模时,混合训练在排除任务中的增强几乎相当于仅使用通用数据进行训练。在 70B 规模上才观察到性能的显著提升。由此作者猜测,实现对智能体任务的最佳泛化可能需要特定的模型规模。
总结
在 LLM 崛起之前,智能体任务主要依赖于强化学习或 BERT 等编码器模型。在此之后,研究重点转向了 LLM 智能体。而许多最近的研究还提出了从闭源模型中提炼指令调优数据集的方法,以增强开源模型的能力。
鉴于此,本文旨在研究如何实现 LLM 的通用智能体能力,弥合在智能体任务上开源和商业 LLM 之间的差距。AgentTuning 是首次利用多个智能体任务交互轨迹对 LLM 进行指令调整的方法。作者通过使用 AgentTuning 来微调 Llama 2 模型生成开源的 AgentLM。评估结果表明,AgentTuning 让 LLM 在未见过的智能体任务中也展现出强大的泛化能力,同时通用语言能力也基本保持不变。目前来看,AgentLM-70B 是首个在智能体任务上与 GPT-3.5-turbo 相匹配的开源 LLM,这为智能体任务提供了开放而强大的商业 LLM 替代方案。
这项研究为未来 LLM 在智能体任务领域的发展提供了新的思路和可能性。随着对开源 LLM 的研究不断深入,我们可以期待更多创新的方法和技术,以提高这些模型在智能体交互、任务执行等方面的适应性和性能。这一研究也为智能体任务的未来发展奠定了基础,为实现更加智能化、灵活化的智能体系统开辟了新的可能性。最后,我们期待看到这些成果能够为解决实际问题、改善用户体验以及推动 AI 领域的前沿研究做出更大的贡献~~