一张图讲清楚业务稳定性要如何做:SRE体系化稳定性方案
概述:作为一个SRE、运维工程师,当我们在治理系统稳定性时,方法有很多,但往往无从下手。本文以一张逻辑图的形式,为读者提供治理稳定性的体系化思路。
先上图:

1、治理目标
我们做稳定性的目标,借用GoogleSRE提出的一个理念:故障无感化。我们不是要消除故障,且故障也没法消除,只要这世上还有bug存在,故障就无法消除。
所谓故障无感化,就是指我们可以对故障抱着更加open的态度,当故障发生时,一切有序地执行、恢复、整改,就像它不曾发生一样。当然做到这个的前提,是要将稳定性建设做到比较好的程度。
2、治理对象
有上可知,我们治理的对象就是故障,那么问题来了,如何定义一个故障?我们需要一个基线,于是故障等级定义由此而来。
2.1 故障等级定义
故障等级定义要表达清楚具体业务域下某业务指标影响范围和影响时长,举例如下:
- P0:订单交易成功量下跌10%
- P1:首页打开错误率大于5%
制定的逻辑可先定场景,再定影响。场景代表客户真是的体感,可由业务团队明确;有了场景就可以搜罗对应的监控,并按周、按月观察监控趋势,以影响客户数量为基准确定故障等级。举例:订单交易成功量下跌的数量、支付失败的数量、履约失败的数量必须一致或同一量级,可归为同一个故障等级。

2.2 故障生命周期
故障生命周期可归纳为:发生--发现--响应--恢复--复盘
2.2.1 发现阶段
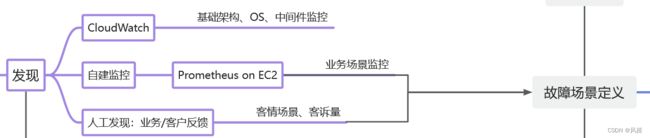
在发现阶段,我们主要依赖于三类型的监控:基础架构、业务监控、客户反馈/投诉。基础架构的监控一般不会直接影响到业务指标,主要还是依靠后两者。是不是发现和故障等级定义串起来了?
2.2.2 响应阶段
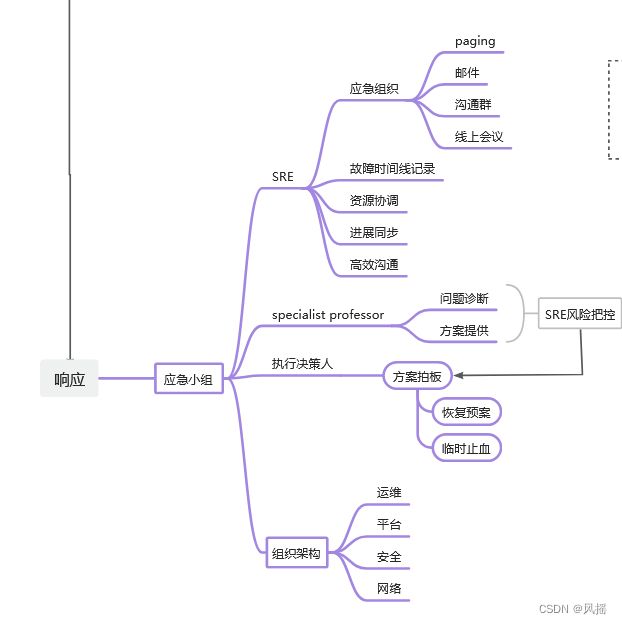
在响应阶段,要明确应急小组里的每个角色以及指责。试想下,当你们公司交易下跌10%时,一时间call上来过多少人?每个人七嘴八舌没有组织,恢复效率可想而知。
应急小组主要由:SRE、领域专家、决策人、其他组织架构构成。
SRE作为响应阶段的控场人物,首先要发起组织,其次记录故障时间线并间歇同步,同时以最小化原则协调资源,并在恢复会议或者沟通群中控制所有人的发言,避免信息泛滥。在排查问题时把控方向,并在关键时刻找到特殊领域专家帮助定位,同时在执行方案上做风险把控。
2.2.3 恢复执行
恢复执行没什么好说的,重点是观测业务指标的回升,以及准备好回滚方案。
2.2.4 复盘
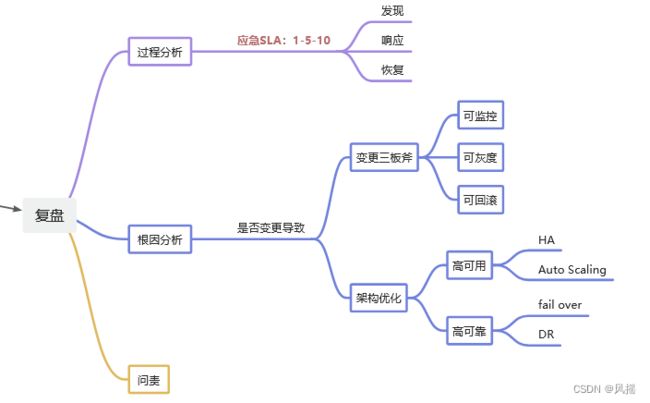
复盘重点关注过程分析和根因分析。
过程分析即发现、响应和恢复的过程中具体指标是多少,比如阿里提出的1-5-10指标:1分钟发现、5分钟响应、10分钟恢复。在复盘中问自己三个问题:发现阶段有没有监控覆盖?响应阶段有没有高效执行?恢复阶段有没有应急预案?
根因分析围绕是否变更导致。如果是变更导致,那需要review变更的三板斧是否有对应策略和方案;如果不是变更导致,则需思考从架构层面的高可用和高可靠性是否做的充分。
3、治理专项
到此,大家应该也能大致猜到专项治理是要治理什么了,我们不妨以应急SLA:1-5-10作为目标,从监控覆盖、应急预案、应急演练三个方向展开治理。

3.1 监控覆盖
以故障等级定义为基线,整体review所有的故障等级定义是否都有相应的业务监控覆盖,可以是多个监控对应一个故障场景。
3.2 应急预案
同样是以故障等级定义为参考,是否每个条目都有对应的预案可以及时恢复,就算有的场景实在恢复不了,是否有止血方案可以组织故障影响的扩大。
3.3 应急演练
再做足监控覆盖和应急预案之后,不定期地组织演练。演练需要关注两个点:我们的应急组织是否完善、各个角色的应急响应是否及时;方案是否有效,是否可以自动化执行,方案的可读性是否足够高能让任何一个工具人都可以执行恢复。
总结:
稳定性治理,依托于故障等级定义、围绕着故障生命周期展开。故障的生命周期中每个节点都是我们可以去展开、去思考如何做的更优,并同时反哺到故障等级定义中,二者相辅相成,密不可分。希望本文对在做稳定性的读者们有所启发。