从 malloc 分配大块内存失败 来简看 linux 内存管理
文章目录
-
- 背景
- Glibc Malloc
- Malloc 分配大块内存失败原因
- Overcommit_memory 实现
- OOM (Out Of Memory) 的实现
背景
应用进程 malloc 返回了null,但是观察到的os 的free内存还有较大的余量 ,很奇怪为什么会这样?
不可能是oom导致的(当然也没有 os 的oom 日志),free还有余量,系统也没有cgroup的应用隔离。
Glibc Malloc
我们linux上使用的库函数 malloc 基本都是用glibc库实现的malloc函数(当然如果binary 链接了 tcmalloc或者jemalloc 则malloc函数就是对应库的实现逻辑),之前其实介绍过 tcmalloc (Thread-Caching malloc) 的基本实现,glibc 的 ptmalloc(pthread malloc)也基本相差不大。
ptmalloc 在 需要分配的内存大小超过 128k 时会调用mmap 系统调用进行分配,不超过 128K 的则通过brk 系统调用进行内存申请。
因为 brk 系统调用是在堆上申请的内存,堆上申请的内存是会直接从os申请对应的物理内存;而且ptmalloc 会缓存通过brk 申请的内存,防止频繁得从os通过page_fault 申请内存,而且也能够利用thread-cache 来加速申请。
通过mmap 方式则会在用户空间的文件映射区开辟 用户需求的内存空间,用户实际需要向这一部分内存区域填充数据的时候则会触发缺页中断,通过page_fault完成实际真正的物理内存页的申请,建立物理内存和mmap 映射到进程空间的虚拟内存的映射。
当我们申请小于 128K 的内存空间时,可以看到是从heap 堆上分配的内存,并且物理内存和实际的内存大小一样。

而当我们申请大于128K 的内存空间时,则主要通过mmap 申请,并在用户态建立对应的文件映射区
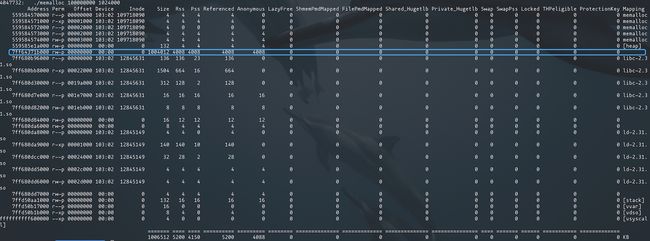
我们的应用程序是在分配大块(超过128K)时失败的,所以重心应关注为什么mmap 失败了?
这种场景不会是 oom 导致的本质原因是:oom 已经是在处理缺页异常期间无法分配内存而由kernel触发的进程kill 逻辑,我们的程序还没有到触发缺页异常的过程。当然,系统日志里也没有oom-killer的相关日志。
从上图可以看到 mmap 申请的size 和 实际的 物理内存 Rss 差异很大,mmap 申请到文件映射区的内存大小是虚拟内存,如果用户还没有占用实际的存储空间,则不会从物理内存上分配对应的物理内存页,当用户在申请的内存区域有存储需求时会触发 page_fault,然后kernel会 通过do_page_fault 完成物理内存页的申请,此时才会将申请到的物理内存页的大小加到 Rss中,也即 free 命令的 used指标中。
所以 在我们的应用场景 malloc 分配失败的本质是说 mmap 建立指定大小的用户态虚拟内存映射时失败了。
Malloc 分配大块内存失败原因
所以猜测当前问题肯定与os 某一些虚拟内存相关的系统配置有关系。
后续也就是简单梳理了一下 /proc/sys/vm 下的kernel 内存管理相关的配置,其中有几个简单提一下:
min_free_kbytes标识linux kernel 可以保留的最小的内存大小,kernel 会通过这个值来计算每一个 mem-zone 的 watermark[WMARK_MIN] 来作为调度kswapd kernel 线程进行内存回收的阈值。overcommit_memory用来标识 os 内存是否允许过度分配,超过 申请的内存大小 超过os内存总大小 。0 标识在 内存允许过度分配,但是会利用启发式算法检测分配是否合理,不合理的话会返回分配失败。1 标识 总是允许过度分配 且不做任何检测。 2 禁止过度分配,用户申请的内存 总大小 小于 os 内存总大小。overcommit_kbytes和overcommit_ratio都用于计算CommitLimit指标,即允许用户申请的 os 内存总大小。
其中与本文提到的 free 还有余量但是分配内存失败相关的 内核配置就是 overcommit_memory,因为我出现问题时该参数为2,即不允许os 出现内存的过度分配(因为这个配置默认是0,可能以前我做了什么将它修改为了2)。
对于 overcommit_memory 为 2 的情况,os 是通过什么指标来判断用户不能过度分配呢?
$ cat /proc/meminfo|grep -i commit
CommitLimit: 60616680 kB
Committed_AS: 11544208 kB
如果 Committed_AS 超过 CommitLimit,则 os 认为出现了过度分配,应该阻止。
从 kernel 2.6 版本开始 CommitLimit 的计算如下:
$ CommitLimit = (total_RAM - total_huge_TLB) * overcommit_ratio / 100 + total_swap $
total_RAM是 os总内存total_huge_TLB大页内存的大小overcommit_ratio是/proc/sys/vm/overcommit_ratio的值,默认是95total_swap是划分的磁盘 swap 分区的大小,mm 会将不经常访问的且主存空间不足无法存放的内存页换出到 swap存储。
在 kernel 3.14 版本,增加了一个配置 overcommit_kbytes ,默认是0,如果配置了则会用其单独计算 CommitLimit的值:
$ CommitLimit = overcommit_kbytes + total_swap $
Committed_AS 代表什么呢?
它是 代表的是当前用户程序 在 os 上申请的总内存大小,其中包括 申请但未使用的内存。 比如 malloc(1G),会mmap 在用户态进程空间分配 1G 的虚拟内存,后续用户需要向内存空间存储实际的数据,则才会建立实际的物理内存页的映射。申请了 1G ,最后实际使用 300M,则 1G 会被加到 Committed_AS 中,但是 os 的 used 指标 仅会加 300M。
这也是为什么会看到 Committed_AS 会大于 CommitLimit 的情况,如果设置了过度分配 比如 0,则Committed_AS 代表当前系统用户程序申请的内存大小的总和,即用户进程的虚拟内存大小很大概率会超过物理内存大小。
在确认了 overcommit_memory 含义之后,修改其为 0,即允许 os 可以执行 过度内存分配:
sudo sysctl vm.overcommit_memory=0
后续再观察其内存分配情况,会发现 Committed_AS 远远超过 CommittLimit 也不会有 malloc失败的问题,不过这个时候可能会出现 OOM,因为os 已经不限制内存申请了,但是如果实际占用的内存 used 确实达到了 总内存的上限,则会触发 oom killer,根据进程 nice值,直接杀掉内存占用较高的进程。
后续介绍的相关内核代码的版本是基于 5.19 版本
Overcommit_memory 实现
在当前内存分配的场景,glibc-malloc 函数分配的是超过128K 的内存,则用的是 mmap 系统调用。 mmap 实现链路检测内存分配情况的调用栈如下:
__do_sys_mmap
ksys_mmap_pgoff
vm_mmap_pgoff
do_mmap
mmap_region
security_vm_enough_memory_mm
__vm_enough_memory
mmap的过程是在用户进程空间建立虚拟内存映射区,包括.so这样的文件都是通过mmap映射到进程空间,最终是通过 mmap_region 进行。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
...
/* 检查现有的虚拟内存空间是否足够,如果不够,尝试扩容虚拟内存空间 */
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) {
unsigned long nr_pages;
/*
* 扩容的方式是尝试移除一些和当前虚拟内存空间要占用的地址有覆盖的pages,将这一些
* 覆盖的pages划分到用户想要占用的这一部分空间内。
*/
nr_pages = count_vma_pages_range(mm, addr, addr + len);
if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}
/* 正常情况是不需要扩容的,这里会清理掉要占用的这一部分虚拟内存空间的 flags */
if (munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf))
return -ENOMEM;
/*
* 检查当前可用的物理内存空间是否足够
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
...
}
最终的检查是通过 security_vm_enough_memory_mm --> __vm_enough_memory 函数完成的。
__vm_enough_memory 检查是否有可用的物理内存逻辑如下:
- 如果 overcommit_memory 为1 ,即
OVERCOMMIT_ALWAYS,不做任何检查,直接返回。这种模式下不论用户申请多少内存,内核都不会做限制。 - 如果 overcommit_memory 为0,即
OVERCOMMIT_GUESS,会检查用户当前申请的内存大小是否超过total_RAM+total_Swap,如果超过了就会返回失败ENOMEM,否则返回成功。即在 内核允许 用户进程过度分配的情况下,只会检查单次分配的大小是否有超过 os 总内存的大小,并不会做其他的检查了。 - 剩下的逻辑都是在处理 overcommit_memory 为2的情况,即不允许过度分配内存。此时会通过
vm_commit_limit先计算当前内核允许分配的物理内存大小(CommitLimit):- 如果
sysctl_overcommit_kbytes不为0,则 算出来允许分配的pages 个数 allow 为: sysctl_overcommit_kbytes / 8 + total_swap_pages - 否则 allow 就是 (totalram_pages - hugetlb_total_pages) *
sysctl_overcommit_ratio/100 + total_swap_pages
- 如果
- 此时 allow 还需要确保排除 root 以及 user 预留的内存空间, allow - sysctl_admin_reserve_kbytes/8 - sysctl_user_reserve_kbytes/8
- 此时 allow 的结果可以理解为 CommitLimit的值,如果 atomic read
vm_committed_as< allow ,则才允许用户继续申请 内存。
int __vm_enough_memory(struct mm_struct *mm, long pages, int cap_sys_admin)
{
long allowed;
vm_acct_memory(pages);
/*
* Sometimes we want to use more memory than we have
*/
if (sysctl_overcommit_memory == OVERCOMMIT_ALWAYS)
return 0;
if (sysctl_overcommit_memory == OVERCOMMIT_GUESS) {
if (pages > totalram_pages() + total_swap_pages)
goto error;
return 0;
}
allowed = vm_commit_limit();
/*
* Reserve some for root
*/
if (!cap_sys_admin)
allowed -= sysctl_admin_reserve_kbytes >> (PAGE_SHIFT - 10);
/*
* Don't let a single process grow so big a user can't recover
*/
if (mm) {
long reserve = sysctl_user_reserve_kbytes >> (PAGE_SHIFT - 10);
allowed -= min_t(long, mm->total_vm / 32, reserve);
}
if (percpu_counter_read_positive(&vm_committed_as) < allowed)
return 0;
error:
vm_unacct_memory(pages);
return -ENOMEM;
}
所以,如果 overcommit_memory为2的话,基本限制死了用户能够申请的内存的大小是小于当前os的total内存大小,那64bits 的虚拟进程空间完全就用不到了… 因为现代应用程序(数据库/编译器)为了减少系统调用,防止频繁陷入内核,内存管理上都会在自己的用户态维护一个allocator,用来加速自己的服务对os的内存访问 以及 提升内存利用率。内存分配器都会预先分配一批内存,等用户需要用的时候再交给用户,这本身就是过度分配。所以,这个配置应以 overcommit_memory 0 为主,当然可能出现的风险 比如 OOM 就需要用户自己去处理了,虽然相比于 overcommit 为1 也没有太多的限制(只是说不允许单次申请超过 os 内存总大小而已),有限制肯定更好一些。
OOM (Out Of Memory) 的实现
前面提到了 内核的内存管理如果采用 overcommit_memory 为0 或者 1 的过度分配模式时可能出现OOM,再看看 OOM 的 kernel实现,如何判定需要 对某一个进程执行 OOM killer 呢?
直接看一个 OOM 的内核栈,能够得到一些基本信息:
[Thu Jul 20 14:39:44 2023] dump_stack_lvl+0x4a/0x63
[Thu Jul 20 14:39:44 2023] dump_stack+0x10/0x16
[Thu Jul 20 14:39:44 2023] dump_header+0x53/0x225
[Thu Jul 20 14:39:44 2023] oom_kill_process.cold+0xb/0x10
[Thu Jul 20 14:39:44 2023] out_of_memory+0x1dc/0x530
[Thu Jul 20 14:39:44 2023] __alloc_pages_slowpath.constprop.0+0xd32/0xe30
[Thu Jul 20 14:39:44 2023] __alloc_pages+0x2cc/0x310
[Thu Jul 20 14:39:44 2023] alloc_pages_vma+0x95/0x270
[Thu Jul 20 14:39:44 2023] do_anonymous_page+0xf8/0x3b0
[Thu Jul 20 14:39:44 2023] __handle_mm_fault+0x804/0x840
[Thu Jul 20 14:39:44 2023] handle_mm_fault+0xd8/0x2c0
[Thu Jul 20 14:39:44 2023] do_user_addr_fault+0x1c2/0x660
[Thu Jul 20 14:39:44 2023] exc_page_fault+0x77/0x170
[Thu Jul 20 14:39:44 2023] asm_exc_page_fault+0x27/0x30
[Thu Jul 20 14:39:44 2023] RIP: 0033:0x7fa0c11a273c
很明显,这个栈是在处理 mem_fault,即缺页中断的过程。缺页中断的触发是说 用户向os 申请了虚拟内存,并通过 比如 mmap 这样的系统调用完成了虚拟内存的到物理内存的映射。但是并没有分配物理内存页,当用户想要访问某一个分配好的虚拟内存的地址时发现没有对应的物理内存页,就会触发缺页中断,通过 page_fault相关的函数 来申请物理内存页。
因为这个 OOM 是由于用户态程序想要访问物理内存页而触发的缺页,则会由用户态进入缺页中断的处理(虽然最终都是走 handle_mm_fault)
handle_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
trace_page_fault_entries(regs, error_code, address);
if (unlikely(kmmio_fault(regs, address)))
return;
/* 通过处理缺页中断的系统调用传入的地址空间来区分时用户态还是内核态 */
if (unlikely(fault_in_kernel_space(address))) {
/* 直接处理内核态触发的缺页中断,底层是通过vmalloc、kmap_atomic完成的 */
do_kern_addr_fault(regs, error_code, address);
} else {
/* 我们走的时用户态的处理 */
do_user_addr_fault(regs, error_code, address);
/*
* User address page fault handling might have reenabled
* interrupts. Fixing up all potential exit points of
* do_user_addr_fault() and its leaf functions is just not
* doable w/o creating an unholy mess or turning the code
* upside down.
*/
local_irq_disable();
}
}
在 do_user_addr_fault逻辑中,会先 通过 当前进程的 mm_struct 找到用户想要访问的虚拟内存地址所在的区域 vm_area_struct,然后通过 handle_mm_fault --> __handle_mm_fault 来建立其和物理内存的映射。
static inline
void do_user_addr_fault(struct pt_regs *regs,
unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
vm_fault_t fault;
...
vma = find_vma(mm, address);
/* 对拿到的 管理虚拟内存地址的数据结构 vma 做一些检查 */
...
fault = handle_mm_fault(vma, address, flags, regs);
...
}
在 __handle_mm_fault 中会先构造要访问的进程自管理的四级页表,再调用 handle_pte_fault 创建物理内存页 并 建立和页表的映射。
- PGD 是全局页目录项
- PUD 上层页目录项
- PMD 中间页目录项
- PTE 页表项 (通过
handle_pte_fault) 创建对应的页表项并分配物理内存页 和 该页表建立映射。
四级(现在应该是五级)页表期望用最小的内存占用 来为用户/内核 进程提供最为高效的物理内存页的访问,最终的页表形态如下:

static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.real_address = address,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
...
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
vm_fault_t ret;
/* pgd 分配,同时也会拷贝一份内核页表到当前进程的页表中,进程空间也有一部分内核空间被所有进程共享 */
pgd = pgd_offset(mm, address);
......
/* pud 分配 */
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
/* 分配物理页 */
return handle_pte_fault(&vmf);
}
在 handle_pte_fault 中会处理实际的内存页的分配,主要包含如下几种情况的处理:
- 如果这个页表项 从来没有被分配过,没有页表项,则会走匿名页的分配
do_anonymous_page。 - 如果有页表项,则认为是需要建立到文件的映射,通过
do_fault进行。 - 如果这个页表项原来出现过,说明物理页之前在内存存在过,又被换出(swap) 到磁盘,这次又想从磁盘加载回内存,通过
do_swap_page处理。 - 如果这个页表在 NUMA 模式下之前被分配到了远端的node,现在又想调度回本地的node,则通过
do_numa_page. 这个模式也是为了当代 NUMA( Non-Uniform Memory Access非一致性内存访问) 架构做的物理内存页调度的适配。
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
...
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
...
}
因为我们的 OOM的栈是在 匿名页的分配链路中,所以 看看 do_anonymous_page 的处理。
先通过 pte_alloc 分配一个页表项,再通过:
alloc_zeroed_user_highpage_movable
alloc_pages_vma
__alloc_pages //执行物理页的分配,如果当前从zone freelist 无法拿到空闲物理内存页,才会继续进入 __alloc_pages_slowpath
// 并唤醒一次 kswapd 来回收一波空闲内存页
__alloc_pages_slowpath
__alloc_pages_may_oom // 在 __alloc_pages_slowpath 链路中无法尽快分配到内存,需要检查是否可以触发 OOM
在 __alloc_pages_slowpath 中是整个分配内存页的各种尝试:
- 直接从 内存zone(管理物理内存页的结构)的freelist 中分配,如果有则直接返回
- 如果zone freelist 没有,意味着需要回收内存了(比如 大量的内存被page-cache消耗,zone 管理的freelist 实际的物理内存页确实也没有多少了)。如果允许 direct_reclaim,会先通过
__alloc_pages_direct_compact做一次 compact 回收内存页(这个功能看起来是新特性,需要开启CONFIG_COMPACTION编译选项?没看到有内核参数能直接控制。这个分配方式能够更为高效直接的回收内存碎片,但是会对正在运行的程序有内存分配的性能影响)。 - 如果不允许 direct_reclaim,则走kswapd 进程。通过
wake_all_kswapds唤醒所有的 后代回收进程,将没有被进程正在使用的内存页回收(比如page-cache中的),每一个kswapd 进程会负责一个 zone的内存回收。 - 如果回收之后通过
get_page_from_freelist还是分配不到内存,这就麻烦了,内核还在尽力。就是会尝试再试试 direct_reclaim 以及 compact(开启CONFIG_COMPACTION),如果还是拿不到物理内存页,也只能进入__alloc_pages_may_oom逻辑,检测是否需要进行 oom。
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
...
/* 先唤醒一波 kswapd 来回收内存 */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
/* 第一次尝试分配*/
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* 分配不到,利用compact 回收一波,并第二次尝试分配 */
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
...
retry:
/* 还是分配不到,再唤醒一次 kswapd */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, reserve_flags);
...
/* 第三次尝试 */
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* 再次直接回收,延长分配的执行链路为回收内存页延长时间, 并第四次尝试 */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* 第五次尝试,如果允许compact,则再次做一波 */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
...
/* 无力的 分配,只能进入 OOM阶段了 */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
内核实在给出不出内存了,只能选择进入 __alloc_pages_may_oom,进入之后再次尝试 get_page_from_freelist 拿不到则就会进入 out_of_memory 去做真正的 killing 选择了。
如果用户设置了内核参数
sysctl_panic_on_oom,则 当前进程会直接 panic,不会让内核自行选择需要被kill的进程。如果用户设置了 内核参数
sysctl_oom_kill_allocating_task,会oom_kill_process 当前分配内存的进程。这两个配置 主要用于用户进程在内存分配失败的情况下想要自主退出而不影响其他正在运行的重要进程。
后续 通过 oom_evaluate_task 遍历cgroup下的进程列表, 自主去挑选应该 kill 进程的规则如下:
- 内核进程忽略,因为重要,所以不会放在被 kill 的列表中
- 如果这个进程即使被kill ,也没有什么可以释放的内存,也会忽略(有这种进程吗?)
- 如果这个进程正在被kill,也没必要再kill一次了,也会忽略
- 进程 正在分配大量的内存且被标记为 killed,则优先选中,执行kill。
- 最后才会根据进程的 oom_score_adj ,越大越容易被选中。当然, 这个选择是一个动态调整的过程,以一个进程占用物理内存、swap 内存、pgtables 的总和大小做为基准计算一个 points * adj,最后的结果 比上一个kill 掉的进程基准值 大,则会优先kill当前进程。 也就是一个进程的 oom_score_adj 会影响被选中kill 的概率,adj越大,肯定最后计算的基准值也就越大,越容易被选中。
static int oom_evaluate_task(struct task_struct *task, void *arg)
{
struct oom_control *oc = arg;
long points;
/* 内核进程,跳过 */
if (oom_unkillable_task(task))
goto next;
/* 一个奇怪的判断,这个进程没有可以释放的物理内存... */
if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc))
goto next;
/* 如果这个进程正在被kill,已经是一个 victim,也没必要再kill一次了 */
if (!is_sysrq_oom(oc) && tsk_is_oom_victim(task)) {
if (test_bit(MMF_OOM_SKIP, &task->signal->oom_mm->flags))
goto next;
goto abort;
}
/* 进程 正在分配大量的内存且被标记为 killed,则优先选中,执行kill */
if (oom_task_origin(task)) {
points = LONG_MAX;
goto select;
}
/* 根据进程的 oom_score_adj 来计算是否应被选中干掉 */
points = oom_badness(task, oc->totalpages);
if (points == LONG_MIN || points < oc->chosen_points)
goto next;
...
}
到此,整个 OOM 以及 匿名页的内存分配链路也就比较清晰了。最开始 我们只是想知道为什么 以及 什么情况下进程会被 OOM,但这个问题是会涉及 OS 内存分配链路的核心。虽然也只是冰山一角:(
我们看到了 内核已经尽力到何种程度之后 才会做出 OOM kill 的无奈之举,也知道了可以利用一些小配置来 或早 (sysctl_panic_on_oom 和 sysctl_oom_kill_allocating_task) 或晚 ( oom_score_adj) 被kill。