数据类型与变量—Javase
1.字面常量
在上节课HelloWorld程序中, System.Out.println("Hello World"); 语句,不论程序何时运行,输出的都是Hello
World,其实"Hello World"就是字面常量。
常量即程序运行期间,固定不变的量称为常量,比如:一个礼拜七天,一年12个月等。

字面常量的分类:
1. 字符串常量:由""括起来的,比如“12345”、“hello”、“你好”。
2. 整形常量:程序中直接写的数字(注意没有小数点),比如:100、1000
3. 浮点数常量:程序中直接写的小数,比如:3.14、0.49
4. 字符常量:由 单引号 括起来的当个字符,比如:‘A’、‘1’
5. 布尔常量:只有两种true和false
6. 空常量:null
注意:字符串、整形、浮点型、字符型以及布尔型,在Java中都称为数据类型。
2.数据类型
在Java中数据类型主要分为两类:基本数据类型和引用数据类型。
基本数据类型有四类八种:
1. 四类:整型、浮点型、字符型以及布尔型
2. 八种:
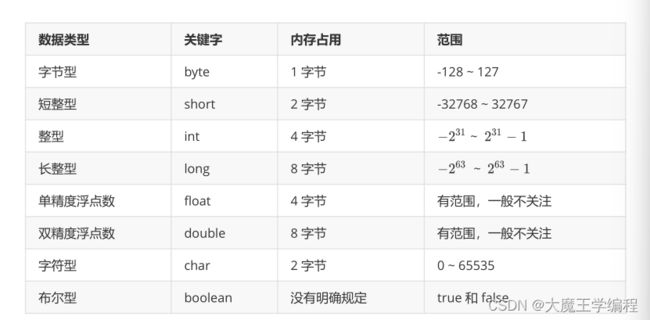
注意:
不论是在16位系统还是32位系统,int都占用4个字节,long都占8个字节
整形和浮点型都是带有符号的
整型默认为int型,浮点型默认为double
字符串属于引用类型。
什么是字节?
字节是计算机中表示空间大小的基本单位.
计算机使用二进制表示数据. 我们认为 8 个二进制位(bit) 为一个字节(Byte).
我们平时的计算机为 8GB 内存, 意思是 8G 个字节.
其中 1KB = 1024 Byte, 1MB = 1024 KB, 1GB = 1024 MB.
所以 8GB 相当于 80 多亿个字节
3.变量
3.1变量概念
在程序中,除了有始终不变的常量外,有些内容可能会经常改变,比如:人的年龄、身高、成绩分数、数学函数的
计算结果等,对于这些经常改变的内容,在Java程序中,称为变量。而数据类型就是用来定义不同种类变量的。
3.2 语法格式
定义变量的语法格式为:
数据类型 变量名 = 初始值;

3.3整型变量
3.31整型变量
// 方式一:在定义时给出初始值
int a = 10;
System.Out.println(a);
// 方式二:在定义时没有给初始值,但使用前必须设置初值
int b;
b = 10;
System.Out.println(b);
// 使用方式二定义后,在使用前如果没有赋值,则编译期间会报错
int c;
System.Out.println(c);
c = 100;
// int型变量所能表示的范围:
System.Out.println(Integer.MIN_VALUE);
System.Out.println(Integer.MAX_VALUE);
// 注意:在定义int性变量时,所赋值不能超过int的范围
int d = 12345678901234; // 编译时报错,初值超过了int的范围

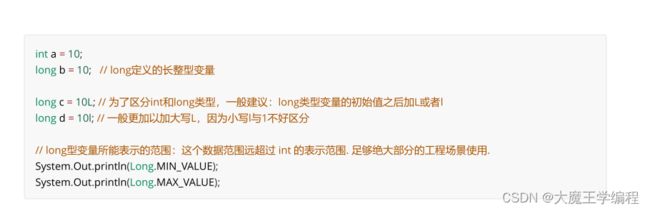
3.3.2长整型变量

3.3.3短整型变量
.
注意事项:
1. short在任何系统下都占2个字节
2. short的表示范围为:-32768 ~ 32767
3. 使用时注意不要超过范围(一般使用比较少)
4. short的包装类型为Short
3.3.4字节型变量


3.4浮点型变量
3.4.1双精度浮点型

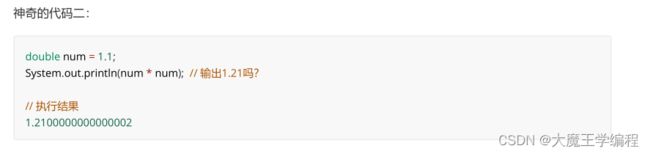
神奇的代码一:
int a = 1;
int b = 2;
System.out.println(a / b); // 输出 0.5 吗?
在 Java 中, int 除以 int 的值仍然是 int(会直接舍弃小数部分)。如果想得到 0.5, 需要使用 double 类型计算.
double a = 1.0;
double b = 2.0;
System.out.println(a / b); // 输出0.5


3.5 字符型变量

注意事项:
1. Java 中使用 单引号 + 单个字母 的形式表示字符字面值.
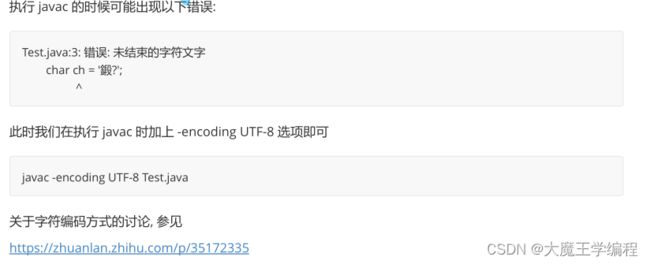
2. 计算机中的字符本质上是一个整数. 在 C 语言中使用 ASCII 表示字符, 而 Java 中使用 Unicode 表示字符. 因此
一个字符占用两个字节, 表示的字符种类更多, 包括中文..
char ch = '呵';
System.out.println(ch);
3.6 布尔型变量

boolean b = true;
System.out.println(b);
b = false;
System.out.println(b);


3. Java虚拟机规范中,并没有明确规定boolean占几个字节,也没有专门用来处理boolean的字节码指令,在
Oracle公司的虚拟机实现中,boolean占1个字节。
3.7类型转换
Java 作为一个强类型编程语言, 当不同类型之间的变量相互赋值的时候, 会有教严格的校验.

在Java中,当参与运算数据类型不一致时,就会进行类型转换。Java中类型转换主要分为两类:自动类型转换(隐式) 和 强制类型转换(显式)。
3.7.1自动类型转换(隐式)


3.7.2 强制类型转换(显式)
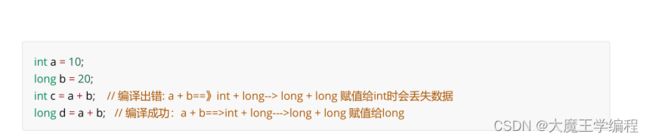
强制类型转换:当进行操作时,代码需要经过一定的格式处理,不能自动完成。特点:数据范围大的到数据范围小的。
int a = 10;
long b = 100L;
b = a; // int-->long,数据范围由小到大,隐式转换
a = (int)b; // long-->int, 数据范围由大到小,需要强转,否则编译失败
float f = 3.14F;
double d = 5.12;
d = f; // float-->double,数据范围由小到大,隐式转换
f = (float)d; // double-->float, 数据范围由大到小,需要强转,否则编译失败
a = d; // 报错,类型不兼容
a = (int)d; // int没有double表示的数据范围大,需要强转,小数点之后全部丢弃
byte b1 = 100; // 100默认为int,没有超过byte范围,隐式转换
byte b2 = (byte)257; // 257默认为int,超过byte范围,需要显示转换,否则报错
boolean flag = true;
a = flag; // 编译失败:类型不兼容
flag = a; // 编译失败:类型不兼容

3.8类型提升

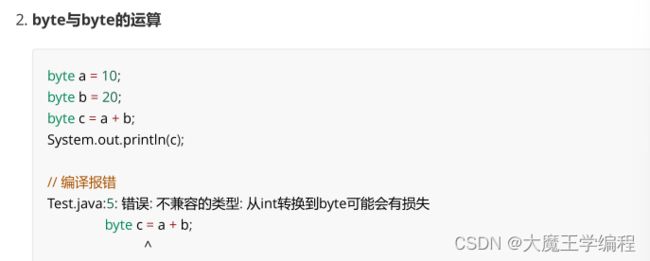
结论: byte 和 byte 都是相同类型, 但是出现编译报错. 原因是, 虽然 a 和 b 都是 byte, 但是计算 a + b 会先将 a
和 b 都提升成 int, 再进行计算, 得到的结果也是 int, 这是赋给 c, 就会出现上述错误.
由于计算机的 CPU 通常是按照 4 个字节为单位从内存中读写数据. 为了硬件上实现方便, 诸如 byte 和 short
这种低于 4 个字节的类型, 会先提升成 int, 再参与计算.
正确的写法:

【类型提升小结:】
1. 不同类型的数据混合运算, 范围小的会提升成范围大的.
2. 对于 short, byte 这种比 4 个字节小的类型, 会先提升成 4 个字节的 int , 再运算.
4.字符串类型
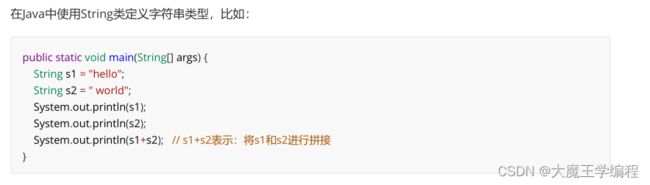
在有些情况下,需要将字符串和整形数字之间进行转换:
1. int 转成 String
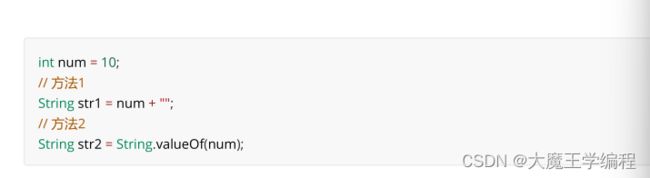
2.string转成int
