oracle connect by用法以及with递归
环境:11g
准备:
在oracle中start with connect by (prior) 用来对树形结构的数据进行查询。其中start with conditon 给出的是数据搜索范围, connect by后面给出了递归查询的条件;
涉及的伪列及函数:
– connect_by_isleaf 伪列
– connect_by_root()获取根节点
– sys_connect_by_path(a,b) 显示分层路径
– connect_by_iscycle 是否循环
语法:
[start with]
connect by [nocycle] prior 条件
[and]
-- 表结构
drop table menu;
create table menu(
mid varchar2(64) not null,
parent_id varchar2(64) not null,
mname varchar2(100) not null,
mdepth number(2) not null,
primary key (mid)
);
-- 初始化数据
-- 顶级菜单
insert into menu values ('100000', '0', '顶级菜单1', 1);
insert into menu values ('200000', '0', '顶级菜单2', 1);
insert into menu values ('300000', '0', '顶级菜单3', 1);
-- 父级菜单
-- 顶级菜单1 直接子菜单
insert into menu values ('110000', '100000', '菜单11', 2);
insert into menu values ('120000', '100000', '菜单12', 2);
insert into menu values ('130000', '100000', '菜单13', 2);
insert into menu values ('140000', '100000', '菜单14', 2);
-- 顶级菜单2 直接子菜单
insert into menu values ('210000', '200000', '菜单21', 2);
insert into menu values ('220000', '200000', '菜单22', 2);
insert into menu values ('230000', '200000', '菜单23', 2);
-- 顶级菜单3 直接子菜单
insert into menu values ('310000', '300000', '菜单31', 2);
-- 菜单13 直接子菜单
insert into menu values ('131000', '130000', '菜单131', 3);
insert into menu values ('132000', '130000', '菜单132', 3);
insert into menu values ('133000', '130000', '菜单133', 3);
-- 菜单132 直接子菜单
insert into menu values ('132100', '132000', '菜单1321', 4);
insert into menu values ('132200', '132000', '菜单1332', 4);
测试:
--看prior修饰的对象,如果是父id,则获取的是父节点数据,反之获取的是子节点数据
--1找指定节点的所有父节点(直接或间接)
select *
from menu aa
start with aa.mid = '130000'
connect by aa.mid = prior aa.parent_id;
--或者
select *
from menu aa
start with aa.mid = '130000'
connect by prior aa.parent_id = aa.mid;
--如果不用树查询,如何实现呢?
--需要知道查询的次数,然后不断的union all,比较麻烦
--或者更改表设计
select aa.* from menu aa where aa.mid='130000'
union all
select b.* from menu b where b.mid=(select aa.parent_id from menu aa where aa.mid='130000');
--2找到指定节点的所有子节点(直接或间接)
select *
from menu aa
start with aa.mid = '130000'
connect by prior aa.mid = aa.parent_id;
--或者
select aa.*, level 层级号
from menu aa
start with aa.mid = '130000'
connect by aa.parent_id = prior aa.mid;
--3.只获取指定节点的直接父节点
select * from menu aa
where aa.mid='130000';
--4.只获取指定节点的直接字节点,利用level限制
select *
from (select aa.*, level lev
from menu aa
start with aa.mid = '130000'
connect by aa.parent_id = prior aa.mid) tt
where tt.lev = 2; --注意:在外面限制,里面限制没用
--或者
select * from menu aa where aa.parent_id='130000';
--4.1 获取不是'130000'分支的树
select aa.*, level 层级号
from menu aa
connect by aa.parent_id = prior aa.mid
and aa.mid != '130000'
and aa.parent_id;
--5.获取指定菜单的子菜单的个数,包括自已
select count(1) from
(
select * from menu aa
start with aa.mid='130000'
connect by prior aa.mid = aa.parent_id
);
--5.1 获取每一个菜单的子菜单的个数(包括自已,包括直接或间接)
--思路: 先求出每个菜单的父菜单,再根据父菜单分组,即可得到每个菜单的子菜单个数
select aa.mid,max(aa.mname),count(1) 子菜单个数 from menu aa
group by aa.mid
connect by aa.mid=prior aa.parent_id
order by aa.mid;
--如果要不包括自已
select aa.mid,max(aa.mname),count(1)-1 子菜单个数 from menu aa
group by aa.mid
connect by aa.mid=prior aa.parent_id
order by aa.mid;
--6 形象展示菜单结构
--展示 130000的结构
-- connect_by_isleaf 伪列
-- connect_by_root()获取根节点
-- sys_connect_by_path(a,b) 显示分层路径
-- siblings by,能保持兄弟关系(层次),优先层次显示,同一层次的再按照字典顺序排序。
select aa.mid,
lpad('|-', level * 2, ' ') || aa.mname,
aa.parent_id,
decode(connect_by_isleaf, 0, '根节点', 1, ' 叶子节点') isleaf,
connect_by_root(aa.mname) 根节点,
sys_connect_by_path(aa.mname,'=>') 分层路径
from menu aa
start with aa.mid = '130000'
connect by aa.parent_id = prior aa.mid
order siblings by aa.mname;
--6.1展示 所有顶级节点的结构
select * from (
select aa.mid,
lpad('|-', level * 2, ' ') || aa.mname 菜单结构,
aa.parent_id,
decode(connect_by_isleaf, 0, '根节点', 1, ' 叶子节点') isleaf,
connect_by_root(aa.mname) 根节点,
connect_by_root(aa.mid) rootid
from menu aa
connect by aa.parent_id = prior aa.mid) tt
where tt.rootid in(select a.mid from menu a where a.parent_id='0')
order by tt.rootid,tt.mid;
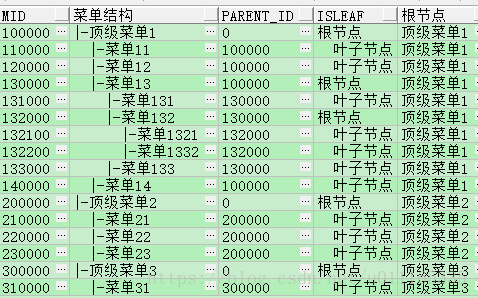
--6.2 如果要去掉某个分支呢? 先把全部的树查询出来,再minus掉指定分支;
--7. 获取指定范围的树形数据
--比如获取20部门的 顶级节点的子节点,已知 mgr=null在部门10
select * from emp e
where e.deptno=20
start with e.mgr is null
connect by prior e.empno=e.mgr;
--发现竟然有数据,说明这个查询肯定是不对的,因为此时的where作用的是整个树形的查询结果,而不是emp
--所有在查询的一开始就要限制范围
--正确写法
select *
from (select * from emp e where e.deptno = 20) e
start with e.mgr is null
connect by prior e.empno = e.mgr;
8.where过滤的问题,where的过滤条件针对的是树查询结果进行过滤的;
注意:这说的是where的过滤条件(带常量的),不是连接条件!!!
select *
from menu aa
where aa.mid!='130000'
start with aa.mid = '130000'
connect by prior aa.mid = aa.parent_id;

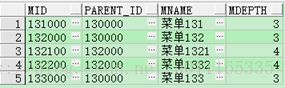
这个时候有5条记录;相当于把’130000’的直接父节点的记录删除掉了;
从执行计划可以看到,是在最后把结果求出来后,再过滤的;
--如果把条件放在connect by后面呢?
select *
from menu aa
start with aa.mid = '130000'
connect by prior aa.mid = aa.parent_id
and aa.mid!='130000';

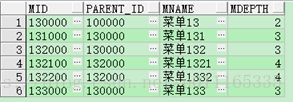
发现结果没有变化,为啥呢?
猜测是在递归循环的过程中,无法过滤start with的mid节点条件;
导致过滤无效;下面的列子会说明的;
再看:
select *
from menu aa
start with aa.mid = ‘130000’
connect by prior aa.mid = aa.parent_id
and aa.mid!=‘132000’;

这个是在递归循环过程中的过滤条件,在把mid!='132000’时,源头132000没了.那么涉及的parent_id自然没有132000;
等价于把的mid为132000以及parent_id为132000的全部去掉;
这种在循环的过程中进行过滤的,过滤效果相对于where过滤条件,过滤的更多;
select * from emp e
where e.deptno=20
start with e.mgr is null
connect by prior e.empno=e.mgr;

select * from emp e
start with e.mgr is null
connect by prior e.empno=e.mgr
and e.deptno=20;

也可以看到,connect by 后的and条件无法过滤掉start with的开始条件;
--9.cconnect by不要prior呢,可以用来创建数据;
select * from menu aa
start with aa.mid='130000'
connect by aa.mid = aa.parent_id;
--此时等价于
select * from menu aa
where aa.mid='130000';
select rownum,level from dual connect by rownum<500;
对于上面的递归查询,在11g之前只能用start with ... connnect by prior来实现,
从版本11GR2开始,ORACLE支持递归的WITH, 即允许在WITH子查询的定义中对自身引用。
其他数据库如DB2, Firebird, Microsoft SQL Server, PostgreSQL 都先于ORACLE支持这一特性;
语法:
WITH
① query_name ([c_alias [, c_alias]...])
② AS (subquery)
③ [search_clause]
④ [cycle_clause]
⑤ [,query_name ([c_alias [, c_alias]...]) AS (subquery) [search_clause] [cycle_clause]]...
①这是子查询的名称,和以往不同的是,必须在括号中把这个子查询的所有列名写出来。
②AS后面的subquery就是查询语句,递归部分就写在这里。
③遍历顺序子句,可以指定深度优先或广度优先遍历顺序。
④循环子句,用于中止遍历中出现的死循环。
⑤如果还有其他递归子查询,定义同上。
SELECT empno,
ename,
job,
mgr,
deptno,
level,
SYS_CONNECT_BY_PATH(ename, '\') AS path,
CONNECT_BY_ROOT(ename) AS top_manager
FROM EMP
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
等价:
WITH T(empno, ename, job, mgr, deptno, the_level, path,top_manager) AS ( ---- 必须把结构写出来
SELECT empno, ename, job, mgr, deptno ---- 先写锚点查询,用START WITH的条件
,1 AS the_level ---- 递归起点,第一层
,'\'||ename ---- 路径的第一截
,ename AS top_manager ---- 原来的CONNECT_BY_ROOT
FROM EMP
WHERE mgr IS NULL ---- 原来的START WITH条件
UNION ALL ---- 下面是递归部分
SELECT e.empno, e.ename, e.job, e.mgr, e.deptno ---- 要加入的新一层数据,来自要遍历的emp表
,1 + t.the_level ---- 递归层次,在原来的基础上加1。这相当于CONNECT BY查询中的LEVEL伪列
,t.path||'\'||e.ename ---- 把新的一截路径拼上去
,t.top_manager ---- 直接继承原来的数据,因为每个路径的根节点只有一个
FROM t, emp e ---- 典型写法,把子查询本身和要遍历的表作一个连接
WHERE t.empno = e.mgr ---- 原来的CONNECT BY条件
) ---- WITH定义结束
SELECT * FROM T
;
with循环参考:https://blog.csdn.net/cacasi2568/article/details/55224422
好,用法就介绍到这了,不知道内有没收获呀
下一篇将介绍connect by的优化,这个是个难点;
end by ysy