在基于亚马逊云科技的湖仓一体架构上构建数据血缘的探索和实践

背景介绍
随着大数据技术的进步,企业和组织越来越依赖数据驱动的决策。数据的质量、来源及其流动性因此显得非常关键。数据血缘分析为我们提供了一种追踪数据从起点到终点的方法,有助于理解数据如何被转换和消费,同时对数据治理和合规性起到关键作用。特别是在 DSL(Data Security Law,数据安全法)和 PIPL(Personal Information Protection Law,个人信息保护法)等数据隐私法规的背景下,这种分析确保了数据的合规性,减少了法律风险。
但数据血缘在收集阶段存在诸多挑战,如数据来源的多样性、数据流的混合、数据质量等问题。尤其在数据湖与数据仓库结合的湖仓一体架构下,这些问题更为复杂。数据湖中的数据格式多样,从半结构化到非结构化,而数据仓库主要针对结构化数据。因此,跨多个系统和工具追踪数据路径、统一不同的日志和元数据,都成为了巨大的挑战。
数据血缘,简而言之,是对数据从其来源到其最终目的地的整个生命周期的追踪和可视化。在当前数据驱动的时代,数据血缘已经成为数据管理和数据治理的关键组成部分。数据血缘的意义:
透明性:数据血缘为组织提供了数据流的完整视图,使得数据工程师、分析师和业务用户都能清楚地了解数据的来源和转换过程。
增强信任:当组织能够清晰地追踪数据的来源和流动,它可以增强内部和外部利益相关者对数据的信任。
提高效率:数据问题可以迅速定位和解决,因为数据血缘提供了数据流的详细视图,从而减少了故障排查的时间。
支持创新:当数据可访问且其来源和质量都已知时,组织可以更自信地进行数据驱动的创新。
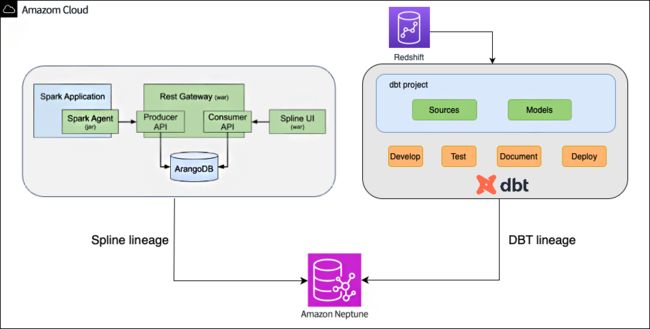
本文会为您介绍在湖仓一体架构下,如何将亚马逊云科技的数据湖 Amazon S3 在数据 ETL 处理过程中通过 Spline 捕获并产生在图数据库 ArangoDB 中的数据血缘和数据仓库 Amazon Redshift 通过 DBT 产生的数据血缘进行合并,并使用图数据库 Amazon Neptune 通过 DAG 图进行可视化展示。
架构设计
在大数据时代,湖仓一体架构逐渐成为数据管理的前沿。这种架构继承了数据湖和数据仓库的长处,为企业提供了一个集中、灵活、高效的数据存储和分析平台。这种架构使得结构化与非结构化数据能够在同一环境中无缝整合,从而消除了数据孤岛现象并提高了数据访问的一致性。同时,得益于云技术,湖仓一体具备了卓越的弹性和可扩展性,轻松应对数据的爆炸式增长。而数据湖的经济存储方式和数据仓库的高速查询性能的结合,进一步确保了企业在大数据处理上的成本效益。
在这样的背景下,使用 Amazon MWAA 基于 Amazon S3,Amazon Glue,Amazon Redshift,DBT 构建 data pipeline,并实现自动化的端到端的数据 ETL 处理,数据建模,以及数据可视化成为一种比较常见的架构实现方式。如下图所示,整个架构实现包括三个组成部分:第一部分,通过 Amazon Glue 实现数据从 data source 到 data staging 再到 data lake。第二部分,通过 DBT 基于Amazon Redshift 进行数据建模。第三部分,通过 Amazon MWAA 实现对 Amazon Glue 和 DBT 的自动化调度。

如本文开头所述,在这样的架构设计下,数据血缘的收集是非常重要的,同时也面临着比较大的挑战。为了解决这个问题,本文采取了分段搜集,再进行数据血缘合并以及可视化呈现。其中通过 Amazon Glue 运行数据 ETL 的部分,采用了 Spline 进行数据血缘的收集,使用 DBT 在 Amazon Redshift 数据建模的部分,通过 DBT 的 Document 功能获取了血缘数据,数据血缘的合并以及可视化,在图数据库 Amazon Neptune 中完成。
什么是 Spline?
Spline 即 Spark Lineage,是一个专注 Spark 的数据血缘追踪工具,Spline 的目标是创建一种简单且高效的方法捕获 Spark 血缘,同时提供 API,方便第三方去扩展和开发。
Spline 在架构上可以分为四部分:
Spline Server
Spline Agent
ArangoDB
Spline UI
Spline Server 是 Spline 的核心。它通过 producer api 接收来自 agent 的血缘数据,并将其存储在 ArangoDB 中。另一方面,它为读取和查询血缘数据提供了 Consumer API。消费者 API 由 Spline UI 使用,但也可以由第三方应用程序使用。
Spline Agent 从数据转换管道中捕获沿血缘和元数据,并通过使用 HTTP API(称为 Producer API),以标准格式将其发送到 Spline server,最终血缘数据被处理并以图的形式存储,并且可以通过另一个 REST API(称为 Consumer API)访问。
ArangoDB 是一个原生多模型数据库,兼有 key/value 键/值对、graph 图和 document 文档数据模型,提供了涵盖三种数据模型的统一的数据库查询语言,并允许在单个查询中混合使用三种模型。基于其本地集成多模型特性,您可以搭建高性能程序,并且这三种数据模型均支持水平扩展。
Spline UI 是可视化渲染数据血缘的 endpoint,可以按 application 绘制作业的表血缘,字段血缘,以及每一个 stage 的输入输出 schema。
什么是 DBT?
DBT(Data Build Tool)是一个开源软件,用于转换和加载数据仓库中的数据。它允许数据工程师和分析师编写、维护和测试 SQL 查询,从而实现数据的转换和建模。DBT 提供了一个框架,使用户能够使用版本控制、测试和文档化来管理 SQL 代码。它与现代云数据仓库如 Snowflake、EMR 和 Redshift 等紧密集成,使得数据团队可以更加高效地进行数据转换和分析。DBT 的主要目标是将数据从源系统转换为易于分析的结构,同时确保数据的质量和准确性。
什么是 Neptune?
Amazon Neptune 是亚马逊云科技发布的一款托管图数据库产品,它支持流行的图模型,如属性图和 W3C 的 RDF,以及相应的查询语言,如 Apache TinkerPop 的 Gremlin、openCypher 和 SPARQL。Neptune 旨在为高度连接的数据集构建查询,提供高性能的图模型处理。它与其他亚马逊云科技产品如 Amazon S3、Amazon EC2 和 Amazon CloudWatch 等紧密集成,确保数据安全和高效处理。
在本方案中,Spline 的血缘数据保存在 ArangoDB 的 Collection 中,DBT 的血缘数据保存在 manifest.json 中。由于 ArangoDB 是一种图数据库,并且遵循了和图数据库 Amazon Neptune 不同的协议,使用了和 Amazon Neptune 不同的数据结构,而且目前没有工具可以实现 ArangoDB 到 Amazon Neptune 的直接数据导入,因此本方案通过数据解析将 ArangoDB 的 Collection 和 DBT 的血缘数据进行转换,生成中间文件后,在 Amazon Neptune 图数据库进行了数据血缘的合并。
方案介绍
1、 Spline 搭建
1)我们采用在 EC2 上以 docker compose 的方式容器化部署 Spline,需提前安装好 Docker 和 Compose。也可以参考这篇亚马逊云科技博客中介绍的在亚马逊云上部署 Spline 的详细例子。
博客链接:
https://aws.amazon.com/cn/blogs/china/using-spline-to-collect-spark-data-kinship-practice/?nc1=h_ls
部署完成后,通过 Amazon Glue 构建一个 Job,启动 Spline UI 查看血缘数据,我们看到 Spline 分为 Execution Events,Data Sources,Execution Plans 几个部分。
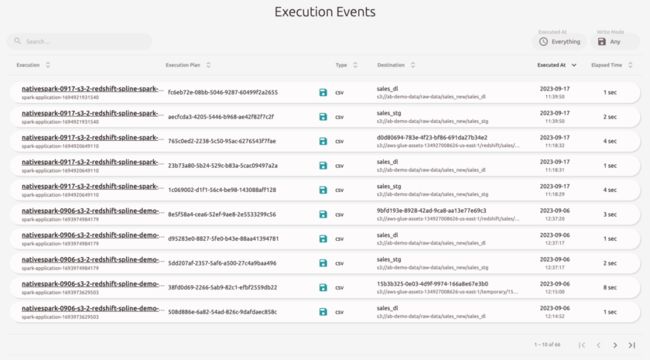
2)点击一个测试生成的 Execution event,可以看到 Spline 采集的数据血缘 DAG 图。

3)测试场景的数据最终会从 Amazon S3 的 sales_dl 目录写入 Amazon Redshift 的 sales 表,由于 Spline 和 Amazon Redshift 集成存在一些限制,生成的血缘数据无法直接看到目标表名。这里考虑到 Amazon S3 在向 Amazon Redshift 写入数据时,会先写入到一个临时目录,通过这个特点进行数据解析获取到了完整的数据血缘信息。

2、 ArangoDB 数据结构以及数据解析
Spline 每次生成数据血缘时,会向 ArangoDB 写入一条 Log 信息,并保存在 22 个 collection 中,如下图所示:

通过数据解析 ArangoDB 的 collection 之间的数据关系,得到在 Spline 中看到的数据血缘信息。在本示例中,根据业务场景的需要,使用了其中的 operation 和 executionPlan 两个 collection 。本方案不着重介绍如何读取 ArangoDB,为方便演示,暂时直接把 json 数据保存成文件后进行解析,具体请参考文件 operation.json 和 executionPlan.json。
operation.json
https://github.com/Honeyfish20/data-lineage-demo/blob/main/arangodb/operation.json
executionPlan.json
https://github.com/Honeyfish20/data-lineage-demo/blob/main/arangodb/executionPlan.json
通过数据解析在 ArangoDB 的 executionPlan 文件中获取与 Glue Job 对应的唯一的 appName,该 appName 会根据业务场景的不同,对应到 Spline 的一条或者多条 Execution event。找到相互关联的 Execution event,并通过数据解析在 ArangoDB 的 operation 文件中获取数据的上下游关系。最后,通过 Amazon S3 的文件存储路径,判断 Amazon S3 写往 Amazon Redshift 的数据血缘,生成中间文件 spline_lineage_map.json,供 Amazon Neptune 进行数据血缘合并。本示例中的中间文件 spline_lineage_map.json 参考。
spline_lineage_map.json 参考:
https://github.com/Honeyfish20/data-lineage-demo/blob/main/spline/spline_lineage_map.json.json
import json
import os
def fetch_target_ids(execution_plan_path, target_name):
target_ids = []
with open(execution_plan_path, 'r') as f:
execution_plans = json.load(f)
for plan in execution_plans:
if plan.get('name') == target_name:
target_ids.append(plan['_id'])
print(f"Found target ID: {plan['_id']}")
return target_ids
def filter_operations(operation_path, target_ids):
filtered_operations = []
with open(operation_path, 'r') as f:
operations = json.load(f)
for operation in operations:
if operation.get('_belongsTo') in target_ids and operation.get('type') in ['Read', 'Write']:
filtered_operations.append(operation)
print(f"Filtered operation: {operation}")
return filtered_operations
def generate_and_transform_result_dict(filtered_operations):
new_data = {'lineage_map': {}}
read_file_name, write_file_name = None, None
read_belongs_to, write_belongs_to = None, None
for operation in filtered_operations:
belongs_to = operation.get('_belongsTo')
operation_type = operation.get('type')
if operation_type == 'Read':
input_source = operation.get('inputSources', [])[0] if operation.get('inputSources') else None
read_file_name = os.path.basename(input_source) if input_source else None
read_belongs_to = belongs_to
elif operation_type == 'Write':
output_source = operation.get('outputSource')
write_file_name = os.path.basename(output_source) if output_source else None
write_belongs_to = belongs_to
if read_file_name and write_file_name and read_belongs_to == write_belongs_to:
if read_file_name not in new_data['lineage_map']:
new_data['lineage_map'][read_file_name] = []
new_data['lineage_map'][read_file_name].append(write_file_name)
return new_data
def fetch_redshift_table(filtered_operations, new_data):
redshift_table = None
for operation in filtered_operations:
output_source = operation.get('outputSource', '')
if 'redshift' in output_source:
redshift_table = output_source.split('/')[-2]
print(f"Redshift table extracted from outputSource: {redshift_table}")
if redshift_table:
last_data_flow_file = None
for key in reversed(list(new_data['lineage_map'].keys())):
if new_data['lineage_map'][key]:
last_data_flow_file = new_data['lineage_map'][key][-1]
break
if last_data_flow_file:
new_key = f"{last_data_flow_file}"
new_data['lineage_map'][new_key] = [redshift_table]
if __name__ == "__main__":
execution_plan_path = "/path/to/executionPlan.json"
operation_path = "/path/to/operation.json"
target_name = 'Your appName in executionPlan.json'
target_ids = fetch_target_ids(execution_plan_path, target_name)
filtered_operations = filter_operations(operation_path, target_ids)
new_data = generate_and_transform_result_dict(filtered_operations)
fetch_redshift_table(filtered_operations, new_data)
with open("/path/to/spline_lineage_map.json", 'w') as f:
json.dump(new_data, f, indent=4)
print(f"New JSON data has been written to /path/to/spline_lineage_map.json")左滑查看更多
3、DBT 数据血缘解析
上述 Amazon Glue 作业执行后会将处理好的数据写入到 Amazon Redshift 的 public.sales 表,DBT 项目采用 sales 表和 event 表作为数据源进行后续的建模,最终生成 top_events_by_sales 表,DBT 原生的数据血缘参考如下:

运行以下命令可为 DBT 项目生成文档,DBT 项目下的 target 目录中的 manifest.json 文件存储了数据血缘相关信息,本示例中 manifest.json 参考。
dbt docs generate
可以通过解析 manifiest.json 文件中的 parent_map 或者 child_map 还原 DBT 的数据血缘,下面的代码示例解析 child_map 并生成中间文件 dbt_lineage_map.json 文件来描述 DBT 数据血缘。
manifest.json 参考:
https://github.com/Honeyfish20/data-lineage-demo/blob/main/dbt/manifest.json
dbt_lineage_map.json:
https://github.com/Honeyfish20/data-lineage-demo/blob/main/dbt/dbt_lineage_map.json
import json
dbt_sources = {}
dbt_models = {}
child_map = {}
lineage_map = {}
def get_node_name(node_name):
if node_name.startswith("source"):
return dbt_sources[node_name]["name"]
if node_name.startswith("model"):
return dbt_models[node_name]["name"]
with open("manifest.json") as f:
data = json.load(f)
dbt_sources = data["sources"]
dbt_models = data["nodes"]
child_map = data["child_map"]
for item in child_map:
parent_name = get_node_name(item)
child_list = []
for i in range(len(child_map[item])):
child_name = get_node_name(child_map[item][i])
child_list.append(child_name)
if len(child_list) > 0:
lineage_map[parent_name] = child_list
dbt_lineage_map["lineage_map"] = lineage_map
with open('dbt_lineage_map.json', 'w') as f:
content = json.dumps(dbt_lineage_map)
f.write(content)左滑查看更多
4、 将 Spline 和 DBT 的数据血缘
合并到 Amazon Neptune
解析本方案中前面步骤生成的中间文件,即 Spline 和 DBT 的数据血缘文件 spline_lineage_map.json 和 dbt_lineage_map.json,将两端的数据血缘插入 Amazon Neptune 进行拼接。代码示例参考如下:
from gremlin_python.process.anonymous_traversal import traversal
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
from gremlin_python.process.traversal import T
def build_data_lineage(data_lineage_map):
for node in data_lineage_map:
if not g.V().hasLabel('lineage_node').has('node_name',node).hasNext():
g.addV('lineage_node').property('node_name', node).next()
for i in range(len(data_lineage_map[node])):
child_node = data_lineage_map[node][i]
if not g.V().hasLabel('lineage_node').has('node_name',child_node).hasNext():
g.addV('lineage_node').property('node_name', child_node).next()
g.V().has('node_name', node).addE('lineage_edge').property('edge_name',' ').to(__.V().has('node_name',child_node)).next()
connection = DriverRemoteConnection('wss://{neptune cluster endpoint}:8182/gremlin', 'g')
g = traversal().withRemote(connection)
with open("spline_lineage_map.json") as f:
spline_lineage_map = json.load(f)
with open("dbt_lineage_map.json") as f:
dbt_linage_map = json.load(f)
build_data_lineage(spline_lineage_map["lineage_map"])
build_data_lineage(dbt_lineage_map["lineage_map"])
remoteConn.close()左滑查看更多
最后启动 Amazon Neptune Notebook,可视化查询最终合并好的完整的数据血缘图:
%%gremlin -d node_name -de edge_name
g.V().outE().inV().path().by(elementMap())左滑查看更多
查询效果如下:

后期展望
本方案从技术角度提供了集成 Spline 和 DBT 数据血缘的解决方案以及原型验证,在实际环境中应用此方案需要在此基础上引入工程化的能力:
1、Spline 的数据血缘存储在 ArangoDB 中,DBT 数据血缘文件存储在项目路径的 target 目录中,即上面提到的 manifest.json 文件,通常会通过 DataOps 发布到 Amazon S3 上。Amazon MWAA 作为此方案的顶层调度框架,Amazone Glue 和 DBT 作业执行完成后,可以实现额外的任务读取 ArangoDB 和 S3 文件,结合本方案中的示例代码,实现两端数据血缘的自动化集成。
2、在实际场景中,可能存在多个环境,如开发、测试、生产等,此时可以为不同环境创建单独的 Amazon Neptune 实例进行环境隔离。同时在同一个环境中,如果有多个 Amazon MWAA 调度作业,在一些极端的情况下,这些作业中可能存在部分相同的上下游结点。此时在同一个环境中写入数据血缘时,可考虑根据 Spline 在 ArangoDB 生成的 appName 和最新的时间查询出当前 DAG 执行后的血缘数据,当和 DBT 进行数据血缘合并时,利用全局标识比如 Amazon MWAA 的 DAG 名称等信息作为图数据库的结点属性,使得后续能够灵活的查询出符合业务实际情况的数据血缘关系图。
3、Spline 和 DBT 原生的数据血缘信息中,都包含数据血缘结点的类型,如文件、Table、View 等。在代码解析过程中,也可以将结点类型提取到临时的中间 Json 文件中,将结点类型作为 Label 写入到 Amazon Neptune 中,从而实现更加灵活的查询,以及更好的可视化效果,如一些主流的可视化查询工具,会根据结点 Label 显示为不同的颜色加以区分。
4、在复杂的业务场景下,Amazon Glue job 会在 Spline 会生成更多的 execution plan,并且每一个 execution plan 的数据关系 ,也会更加复杂,会产生更多的分支,呈现出更为复杂的树形结构,这种情况下,则需要考虑使用更多 ArangoDB 的 collation 文件,进行数据解析,包括使用 collection 文件 follows,去更加精准的判断每一个 execution plan 中的 operation 不同的 action 之间的执行先后次序,以及使用 collection 文件 attribute,通过不同的 execution Plan 的数据上下游之间的字段关系,解析出数据血缘。
5、Amazon S3 向 Amazon Redshift 的数据写入有多种方式,可以基于 Dynamic Frame 的方式,也可以使用 Spark Redshift connector,Spline 是 Spark 的一个组件,使用 Spark Redshift connector 或许可以提供更好的兼容性,在真实的场景中,Amazon Glue 从 Amazon S3 向 Amazon Redshift 中写入数据的场景也会更为复杂,未来可以尝试基于 Amazon Glue 4.0 使用 Spark Redshift connector 实现 Amazon S3 向 Amazon Redshift 的数据写入,收集更为丰富的数据血缘信息。
本篇作者

吴楠
亚马逊云科技解决方案架构师,负责面向跨国企业客户的云计算方案架构咨询和设计,客户覆盖医疗,零售等行业。

孙大木
亚马逊云科技资深解决方案架构师,负责基于亚马逊云科技云计算方案架构的咨询和设计,在国内推广亚马逊云科技云平台技术和各种解决方案。
星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!
