python爬虫基础(一)
目录
知识点回顾
urllib发送post请求
动态页面获取数据
ssl证书验证失败处理
伪装自己的爬虫——请求头
fake-useragent模块
知识点回顾
urllib的基本使用:
request.urlopen的三个参数传递url,data,timeout
read(),getcode(), geturl(), info()的使用
使用request对象进行封装修改达到伪装用户的效果
以及urllib发送get请求
详细看:简单的爬虫程序(详解)_我还可以熬_的博客-CSDN博客
urllib发送post请求
POST请求的参数需要放到Request请求对象中,data是一个字典,里面要匹配键值对
在浏览器中,登录界面的表单就是用post请求
那么如何发送post请求呢,就是传递data
data = {
'next': '/login/?next=%2F',
'login_type':'1' ,
'username': '用户名',
'passwd': '密码',
}data里的参数应该传递什么

有数据的就传递,直接复制过来就行,没有的就不用。
但是不能直接传递字典,要传递bytes:
可以用urlencode来转化
tru_data = urlencode(data).encode()完整代码如下:
from urllib.request import urlopen,Request
from urllib.parse import urlencode
url = 'https://www.kuaidaili.com/login/'
# 封装数据
data = {
'next': '/login/?next=%2F',
'login_type':'1' ,
'username': '用户名',
'passwd': '密码',
}
tru_data = urlencode(data).encode()
# 封装头信息
headers = {'User_Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.12022 SLBChan/103'}
# 封装Request对象
req = Request(url,data=tru_data,headers=headers)
# 发送请求
resp = urlopen(req)
# 打印结果
print(resp.read().decode())动态页面获取数据
有时候发送请求后,并不能获取到想要的数据,其中一个原因就是,当前的页面是动态的,数据会可以随时变动。
目前网络的页面分为两大类:
静态页面:访问有UI页面URL,可以直接获取数据。
动态页面:访问有UI页面URL,不能获取数据。需要抓取新的请求获取。
有些网页内容使用AJAX加载,而AJAX一般返回的是JSON,直接对AJAX地址进行post或get,就返回JSON数据了
以虎扑为例子:

从图中我们可以看到,url地址是不变的仍然是http://hupu.com/app/,但是通过检查我们可以发现页面内的信息返回的url地址不是这个,所以我们获取不到想要的信息,这时候就要用返回的url地址来发送请求。
from urllib.request import urlopen,Request
url = 'https://www.hupu.com/home/v1/news?pageNo=5&pageSize=50'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.12022 SLBChan/103'}
req = Request(url,headers=headers)
resp = urlopen(req)
print(resp.read().decode())这样就可以获取到动态页面的数据:

ssl证书验证失败处理
虽然说windows操作系统很少碰见这样的情况,但是我前两天就碰到了,我用谷歌浏览器访问GitHub的时候就发生了,虽然但是我也不能理解这个情况是我的系统问题还是那个时间点网站的安全证书的问题。
现在随处可见 https 开头的网站,urllib可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问。
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,会警告用户证书不受信任。
处理方法:
from urllib.request import urlopen,Request
import ssl
url = 'http://baidu.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.12022 SLBChan/103'}
# 忽略ssl安全认证
context = ssl._create_unverified_context()
# 添加到context参数里
req = Request(url,headers=headers)
resp = urlopen(req,context=context)
print(resp.read().decode())直接引入python中自带的ssl,对ssl安全认证直接忽略。
伪装自己的爬虫——请求头
之前都是去浏览器找到User_Agent参数,然后直接复制粘贴,是有点麻烦的,而且一直使用同一个来访问网站的话,频率过高,这样也会被反爬。
所以我们要解决掉复制这个问题,还需要随机产生值。
方法:
fake-useragent模块
安装:
pip install fake-useragent使用:
ua = UserAgent()
headers = {
'User-Agent':ua.chrome
}完整代码:
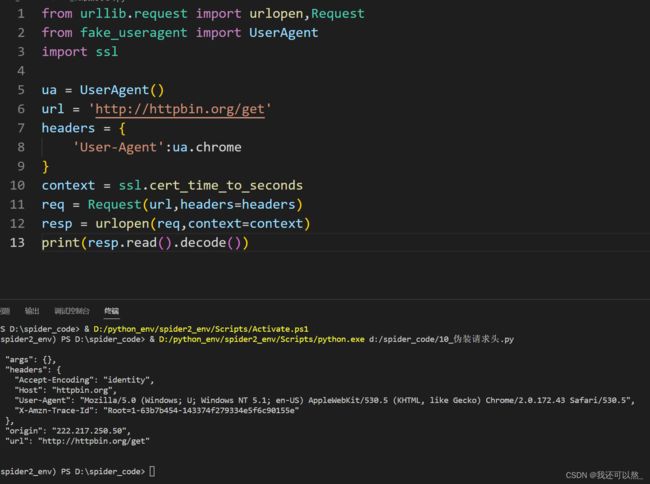
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
import ssl
ua = UserAgent()
url = 'http://httpbin.org/get'
headers = {
'User-Agent':ua.chrome
}
context = ssl.cert_time_to_seconds
req = Request(url,headers=headers)
resp = urlopen(req,context=context)
print(resp.read().decode())效果:
注意
fake-useragent在创建对象时,可能创建不了,多部分原因为服务器访问不到的原因解决方案
拷贝fake-useragent_version.json 的配置文件到用户目录
C:\Users\Feel\AppData\Local\Temp