1、cloudera impala的介绍、与hive的异同、两种部署方式以及内外部命令
cloudera impala 系列文章
1、cloudera impala的介绍、与hive的异同、两种部署方式以及内外部命令
2、cloudera impala sql语法与示例、impala的数据导入的4种方式、java api操作impala和综合示例比较hive与impala的查询速度
文章目录
- cloudera impala 系列文章
- 一、Impala介绍
-
- 1、介绍
- 2、impala与Hive
-
- 1)、Impala依赖Hive
- 2)、Impala与Hive比较
-
- 1、Impala使用的优化技术
- 2、执行计划
- 3、数据流
- 4、内存使用
- 5、调度
- 6、容错
- 7、应用场景
- 3、Impala架构
-
- 1)、Impalad
- 2)、Impala State Store
- 3)、CLI
- 4)、Catalogd
- 4、Impala查询处理过程
- 二、Impala安装部署
-
- 1、安装前提
- 2、下载安装包、依赖包
- 3、配置本地yum源
- 4、节点规划
-
- 1)、主节点安装
- 2)、从节点安装
- 5、修改Hadoop、Hive配置
-
- 1)、修改hive配置
- 2)、修改hadoop配置
- 3)、重启hadoop、hive
- 4)、复制hadoop、hive配置文件
- 6、修改impala配置
-
- 1)、修改impala默认配置
- 2)、添加mysql驱动
- 3)、修改bigtop配置
- 7、启动、关闭impala服务
- 8、impala web ui
- 三、Impala-shell命令参数
-
- 1、impala-shell外部命令
- 2、impala-shell内部命令

本文简单的介绍了impala的功能、与hive的异同、安装以及命令。
本文分为三个部分,即impala的介绍、部署与验证、命令介绍。
一、Impala介绍
1、介绍
官网:https://impala.apache.org/
Lightning-fast, distributed [SQL] queries for petabytes of data stored in Apache Hadoop clusters.
Impala is a modern, massively-distributed, massively-parallel, C++ query engine that lets you analyze, transform and combine data from a variety of data sources:
- Best of breed performance and scalability.
- Support for data stored in [HDFS], [Apache HBase]and [Amazon S3].
- Wide analytic SQL support, including window functions and subqueries.
- On-the-fly code generation using [LLVM] to generate CPU-efficient code tailored specifically to each individual query.
- Support for the most commonly-used Hadoop file formats, including the [Apache Parquet] project.
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具
impala是参照谷歌的新三篇论文(Caffeine–网络搜索引擎、Pregel–分布式图计算、Dremel–交互式分析工具)中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应HBase和已经学过的HDFS以及MapReduce
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点
2、impala与Hive
1)、Impala依赖Hive
- impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,并且还需要启动hive的metastore服务。
Hive元数据包含用Hive创建的database、table等元信息。元数据存储在关系型数据库中,如Derby、MySQL等。
客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
nohup hive --service metastore >> ~/metastore.log 2>&1 &

- Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
2)、Impala与Hive比较
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。
但是Impala跟Hive最大的区别在于没有使用 MapReduce进行并行计算。与 MapReduce相比,Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。

1、Impala使用的优化技术
- 使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。(C++特性)
- 充分利用可用的硬件指令(SSE4.2)
- 更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum
- 通过选择合适数据存储格式可以得到最好性能(Impala支持多种存储格式)
- 最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递
2、执行计划
- Hive:依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。
如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间
- Impala:把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询
不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle
3、数据流
- Hive:采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点
- Impala:采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用
4、内存使用
- Hive:在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。
每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作
- Impala:在遇到内存放不下数据时,版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一定的限制,最好还是与Hive配合使用。
5、调度
- Hive:任务调度依赖于Hadoop的调度策略
- Impala:调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器
调度器目前还比较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前
Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度
6、容错
- Hive:依赖于Hadoop的容错能力
- Impala:在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误
这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败, 再查一次就好了,再查一次的成本很低
7、应用场景
- Hive:复杂的批处理查询任务,数据转换任务
- Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析
3、Impala架构
Impala主要由Impalad、 State Store、Catalogd和CLI组成。
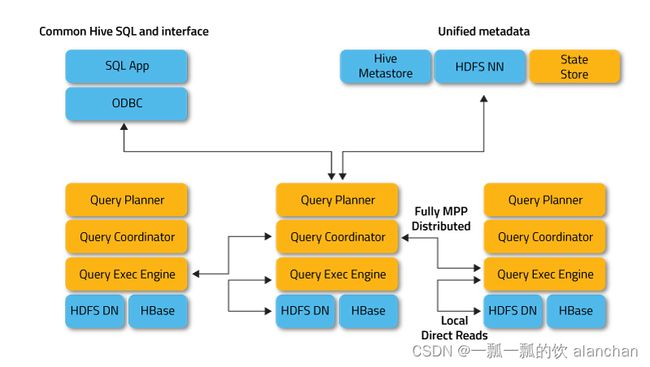
1)、Impalad
Impalad与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。
在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
2)、Impala State Store
Impala State Store跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
3)、CLI
CLI提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。
4)、Catalogd
Catalogd作为metadata访问网关,从Hive Metastore等外部catalog中获取元数据信息,放到impala自己的catalog结构中。impalad执行ddl命令时通过catalogd由其代为执行,该更新则由statestored广播。
4、Impala查询处理过程
Impalad分为Java前端与C++处理后端,接受客户端连接的Impalad即作为这次查询的Coordinator,Coordinator通过JNI调用Java前端对用户的查询SQL进行分析生成执行计划树。
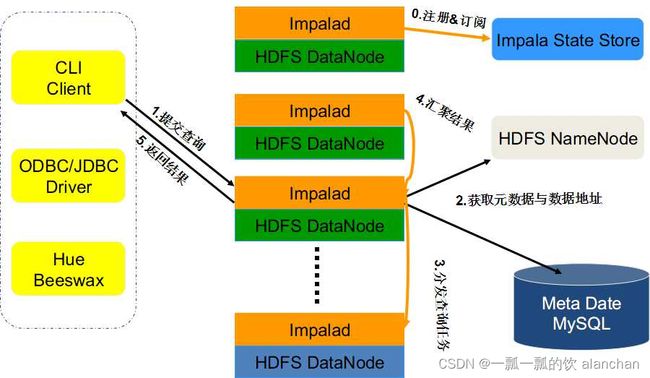
Java前端产生的执行计划树以Thrift数据格式返回给C++后端(Coordinator)(执行计划分为多个阶段,每一个阶段叫做一个PlanFragment,每一个PlanFragment在执行时可以由多个Impalad实例并行执行(有些PlanFragment只能由一个Impalad实例执行,如聚合操作),整个执行计划为一执行计划树)。
Coordinator根据执行计划,数据存储信息(Impala通过libhdfs与HDFS进行交互。通过hdfsGetHosts方法获得文件数据块所在节点的位置信息),通过调度器(现在只有simple-scheduler, 使用round-robin算法)Coordinator::Exec对生成的执行计划树分配给相应的后端执行器Impalad执行(查询会使用LLVM进行代码生成,编译,执行),通过调用GetNext()方法获取计算结果。
如果是insert语句,则将计算结果通过libhdfs写回HDFS当所有输入数据被消耗光,执行结束,之后注销此次查询服务。
二、Impala安装部署
impala部署有2种方式,即在cdh环境中安装impala,非常简单,可以类似参考kudu的cdh方式部署kudu,推荐该种部署方式。
下文介绍直接下载文件安装impala,一般不推荐该种部署方式,比较麻烦,且容易出错。
1、安装前提
- 集群提前安装好hadoop,hive。
- hive安装包scp在所有需要安装impala的节点上,因为impala需要引用hive的依赖包。
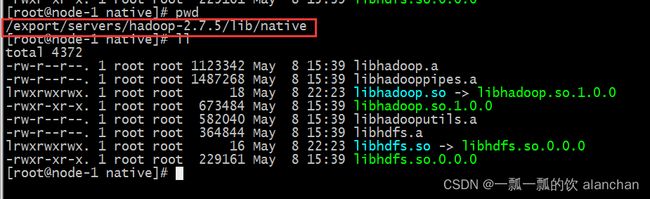
- hadoop框架需要支持C程序访问接口,查看下图,如果有该路径下有这么文件,就证明支持C接口。
2、下载安装包、依赖包
由于impala没有提供tar包进行安装,只提供了rpm包。因此在安装impala的时候,需要使用rpm包来进行安装。rpm包只有cloudera公司提供了,所以去cloudera公司网站进行下载rpm包即可。
但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,也可以将所有的rpm包下载下来,制作成本地yum源来进行安装。这里就选择制作本地的yum源来进行安装。
所以首先需要下载到所有的rpm包,下载地址如下
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
3、配置本地yum源
参考kudu的配置本地yum源方式,参考本作者专栏链接:https://blog.csdn.net/chenwewi520feng/article/details/131429237
4、节点规划

1)、主节点安装
在规划的主节点server-3执行以下命令进行安装:
yum install -y impala impala-server impala-state-store impala-catalog impala-shell
2)、从节点安装
在规划的从节点server-1、server-2执行以下命令进行安装:
yum install -y impala-server
5、修改Hadoop、Hive配置
需要在3台机器整个集群上进行操作,都需要修改。
hadoop、hive是否正常服务并且配置好,是决定impala是否启动成功并使用的前提。
1)、修改hive配置
可在server-1机器上进行配置,然后scp给其他2台机器。
vim /usr/local/bigdata/hive/conf/hive-site.xml
在hive配置好的基础上,安装impala,不需要修改hive的配置文件
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://192.168.10.44:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>12345666value>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>server-1value>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://server-1:9083value>
property>
<property>
<name>hive.metastore.client.socket.timeoutname>
<value>3600value>
property>
configuration>
将hive安装包cp给其他两个机器。
cd /usr/local/bigdata/
scp -r hive/ server-2:$PWD
scp -r hive/ server-3:$PWD
2)、修改hadoop配置
所有节点创建下述文件夹hdfs-sockets
mkdir -p /usr/local/bigdata/hadoop-3.1.4/hdfs-sockets
修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
dfs.client.read.shortcircuit 打开DFSClient本地读取数据的控制,
dfs.domain.socket.path是Datanode和DFSClient之间沟通的Socket的本地路径。
vim etc/hadoop/hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuitname>
<value>truevalue>
property>
<property>
<name>dfs.domain.socket.pathname>
<value>/usr/local/bigdata/hadoop-3.1.4/hdfs-sockets/dnvalue>
property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millisname>
<value>10000value>
property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabledname>
<value>truevalue>
property>
把更新hadoop的配置文件,scp给其他机器。
cd /usr/local/bigdata/hadoop-2.7.5/etc/hadoop
scp -r hdfs-site.xml server-2:$PWD
scp -r hdfs-site.xml server-3:$PWD
注意:root用户不需要下面操作,普通用户需要这一步操作。
给这个文件夹赋予权限,如果用的是普通用户hadoop,那就直接赋予普通用户的权限,例如:
chown -R hadoop:hadoop /var/run/hdfs-sockets/
因为这里直接用的root用户,所以不需要赋权限了。
3)、重启hadoop、hive
在server-1上执行下述命令分别启动hive metastore服务和hadoop。
cd /usr/local/bigdata/hive
nohup bin/hive --service metastore &
nohup bin/hive --service hiveserver2 &
cd /usr/local/bigdata/hadoop-3.1.4/
sbin/stop-dfs.sh | sbin/start-dfs.sh
4)、复制hadoop、hive配置文件
impala的配置目录为/etc/impala/conf,这个路径下面需要把core-site.xml,hdfs-site.xml以及hive-site.xml。
所有节点执行以下命令
cp -r /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
cp -r /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
cp -r /usr/local/bigdata/hive/conf/hive-site.xml /etc/impala/conf/hive-site.xml
6、修改impala配置
1)、修改impala默认配置
所有节点更改impala默认配置文件
vim /etc/default/impala
IMPALA_CATALOG_SERVICE_HOST=server-3
IMPALA_STATE_STORE_HOST=server-3
2)、添加mysql驱动
通过配置/etc/default/impala中可以发现已经指定了mysql驱动的位置名字。
使用软链接指向该路径即可(3台机器都需要执行)
ln -s /usr/local/bigdata/hive/lib/mysql-connector-java-5.1.32.jar /usr/share/java/mysql-connector-java.jar
3)、修改bigtop配置
修改bigtop的java_home路径(3台机器)
vim /etc/default/bigtop-utils
export JAVA_HOME=etc/jdk1.8.0_65
7、启动、关闭impala服务
主节点server-3启动以下三个服务进程
service impala-state-store start
service impala-catalog start
service impala-server start
从节点启动server-1与server-2启动impala-server
service impala-server start
查看impala进程是否存在
ps -ef | grep impala
启动之后所有关于impala的日志默认都在/var/log/impala
如果需要关闭impala服务 把命令中的start该成stop即可。
8、impala web ui
访问impalad的管理界面http://server-3:25000/
访问statestored的管理界面http://server-3:25010/
三、Impala-shell命令参数
1、impala-shell外部命令
外部命令指的是不需要进入到impala-shell交互命令行当中即可执行的命令参数。impala-shell后面执行的时候可以带很多参数。可以在启动 impala-shell 时设置,用于修改命令执行环境。
impala-shell –h可以帮助我们查看帮助手册。几个常见命令如下
#刷新impala元数据,与建立连接后执行 REFRESH 语句效果相同
impala-shell –r
#执行指的的sql查询文件
impala-shell –f 文件路径
#默认端口是 21000。你可以连接到集群中运行 impalad 的任意主机
impala-shell –i指定连接运行 impalad 守护进程的主机
#保存执行结果到文件当中去。
impala-shell –o保存执行结果到文件当中去。
2、impala-shell内部命令
内部命令是指,进入impala-shell命令行之后可以执行的语法。
[root@server7 lib]# impala-shell
Starting Impala Shell without Kerberos authentication
Opened TCP connection to server7:21000
Connected to server7:21000
Server version: impalad version 3.2.0-cdh6.2.1 RELEASE (build 525e372410dd2ce206e2ad0f21f57cae7380c0cb)
***********************************************************************************
Welcome to the Impala shell.
(Impala Shell v3.2.0-cdh6.2.1 (525e372) built on Wed Sep 11 01:30:44 PDT 2019)
The '-B' command line flag turns off pretty-printing for query results. Use this
flag to remove formatting from results you want to save for later, or to benchmark
Impala.
***********************************************************************************
[server7:21000] default> help;
Documented commands (type help <topic>):
========================================
compute exit history rerun shell unset version
connect explain profile select show use with
describe help quit set tip values
Undocumented commands:
======================
alter delete drop load src update
create desc insert source summary upsert
connect hostname 连接到指定的机器impalad上去执行。
[server7:21000] default> connect server6 ;
Opened TCP connection to server6:21000
Connected to server6:21000
Server version: impalad version 3.2.0-cdh6.2.1 RELEASE (build 525e372410dd2ce206e2ad0f21f57cae7380c0cb)
[server6:21000] default> show tables;
Query: show tables
Fetched 0 row(s) in 0.56s
refresh dbname.tablename增量刷新,刷新某一张表的元数据,主要用于刷新hive当中数据表里面的数据改变的情况。
invalidate metadata全量刷新,性能消耗较大,主要用于hive当中新建数据库或者数据库表的时候来进行刷新。
quit/exit命令 从Impala shell中弹出
explain 命令 用于查看sql语句的执行计划。
explain的值可以设置成0,1,2,3等几个值,其中3级别是最高的,可以打印出最全的信息
set explain_level=3;
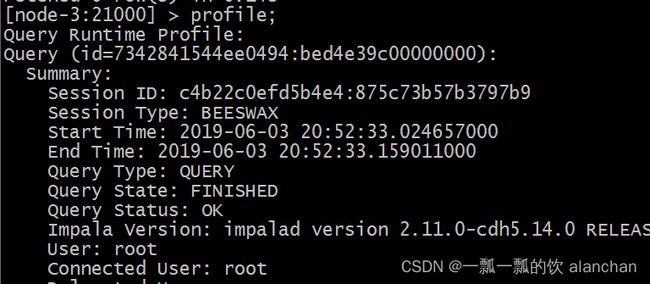
profile命令执行sql语句之后执行,可以打印出更加详细的执行步骤,主要用于查询结果的查看,集群的调优等。示例如下
- 如果在hive窗口中插入数据或者新建的数据库或者数据库表,那么在impala当中是不可直接查询,需要执行invalidate metadata以通知元数据的更新
- 在impala-shell当中插入的数据,在impala当中是可以直接查询到的,不需要刷新数据库,其中使用的就是catalog这个服务的功能实现的,catalog是impala1.2版本之后增加的模块功能,主要作用就是同步impala之间的元数据
- 更新操作通知Catalog,Catalog通过广播的方式通知其它的Impalad进程。默认情况下Catalog是异步加载元数据的,因此查询可能需要等待元数据加载完成之后才能进行(第一次加载)
以上,简单的介绍了impala的功能、与hive的异同、安装以及命令。