BUUCTF MISC 61 - 80
61、heikediguo
打开题目给的TXT文件发现很像文件的十六进制,导入010查看一下,发现是一个rar文件
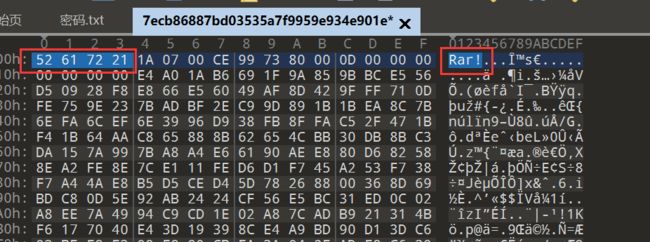
将文件另存为rar得到一个加密的压缩包,无任何提示,先尝试四位纯数字爆破

得到一张无法打开的图片,放入010查看

校验发现不是PNG文件,既然文件头有问题,尝试看一下文件尾FF D9

明显是JPG文件尾(PNG文件尾:AE 42 60 82),于是修改文件头为FF D8 FF

62、你能看懂音符吗
题目给出的压缩包无法打开,使用010查看文件
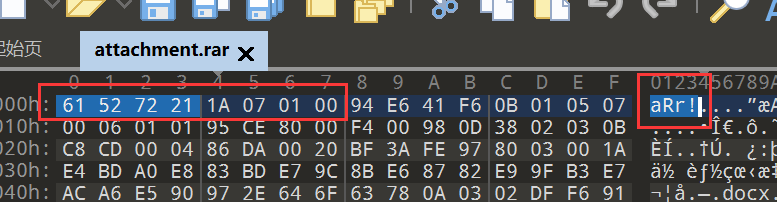
发现文件头格式顺序错误,RAR的文件头为52 61 72 21 1A 07 00(文件尾一般为C4 3D 7B 00 40 07 00)

正常打开后得到一个Word文档,打开后没有有效信息

尝试用formost提取,得到很多文件

在document.xml文件中发现一串奇怪的音符

使用音符在线解密即可
♭♯♪‖¶♬♭♭♪♭‖‖♭♭♬‖♫♪‖♩♬‖♬♬♭♭♫‖♩♫‖♬♪♭♭♭‖¶∮‖‖‖‖♩♬‖♬♪‖♩♫♭♭♭♭♭§‖♩♩♭♭♫♭♭♭‖♬♭‖¶§♭♭♯‖♫∮‖♬¶‖¶∮‖♬♫‖♫♬‖♫♫§=
63、caesar
题目提示凯撒加密,尝试用大佬的穷举脚本跑一下
def change(c,i):
num=ord(c)
if(num>=33 and num<=126):
num=33+(num+i-33)%(94)#126-33=93
return chr(num)
def kaisa_jiAmi(string,i):
string_new=''
for s in string:
string_new+=change(s,i)
print(string_new)
return string_new
#本题有种暴力解密感觉
def kaisa_jiEmi(string):
for i in range(0,94):
print('第'+str(i+1)+'种可能:',end=' ')
#区别在于 string 是该对象原本就是字符串类型, 而 str()则是将该对象转换成字符串类型。
kaisa_jiAmi(string,i)
#你要知道input输入的数据类型都是string
def main():
print('请输入操作,注意不是平常26种:')
choice=input('1:恺撒加密,2:凯撒穷举解密.请输入1或2:')
if choice=='1':
string=input('请输入需要加密字符串: ')
num=int(input('请输入需要加密的KEY: '))
kaisa_jiAmi(string,num)
elif choice=='2':
string=input('请输入需要解密字符串: ')
kaisa_jiEmi(string)
else:
print('输入错误,请重试')
main()
if __name__=='__main__':
main()
64、低个头

哈哈哈低个头,看键盘嘛

65、single dog
用foremost提取一下图片,得到一个TXT文本

发现是AAEncode加密

AAEncode加密
https://www.cnblogs.com/rainforwind/articles/15358505.html
将js代码转换为颜文字的混淆工具(混淆:输出的一段颜文字可以直接执行并且得到与原js相同的结果)

或者控制台解密:去掉最后一行末尾的(‘_’)

66、我吃三明治
得到一张图片,用foremost提取分析发现有两张图片

010单看两张分离的图片没有什么特别之处,再查看原图,因为是两张JPG拼接,于是之前搜索FF D9查看拼接处是否藏有信息

在拼接处发现可能是base32的字符串,解码即可
Base编码
https://www.cnblogs.com/0yst3r-2046/p/11962942.html
(1)base16
使用16个ASCII可打印字符(数字0-9和字母A-F),对任意字节数据进行编码。
先获取输入字符串每个字节的二进制值(不足8比特在高位补0),然后将其串联进来,再按照4比特一组进行切分,将每组二进制数分别转换成十进制。

可以看到8比特数据按照4比特切分刚好是两组,所以Base16不可能用到填充符号“=”。
换句话说:Base16使用两个ASCII字符去编码原数据中的一个字节数据。
Base16编码是一个标准的十六进制字符串(注意是字符串而不是数值),更易被人类和计算机使用,因为它并不包含任何控制字符,以及Base64和Base32中的“=”符号。
(2)base32
Base32编码是使用32个可打印字符(字母A-Z和数字2-7)对任意字节数据进行编码的方案,编码后的字符串不用区分大小写并排除了容易混淆的字符,可以方便地由人类使用并由计算机处理。
Base32主要用于编码二进制数据,但是Base32也能够编码诸如ASCII之类的二进制文本。
Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。

(3)base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。每6个比特为一个单元,对应某个可打印字符。3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。
在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法。
它可用来作为电子邮件的传输编码。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。

(4)base85
使用五个ASCII字符来表示四个字节的二进制数据,使用四个字符来表示三个字节的数据。
用途是Adobe的PostScript和Portable Document Format文件格式,以及Git使用的二进制文件的补丁编码。
与Base64一样,Base85编码的目标是对二进制数据可打印的ASCII字符进行编码。但是它使用了更大的字符集,因此效率更高一些。具体来说,它可以用5个字符编码4个字节(32位)。
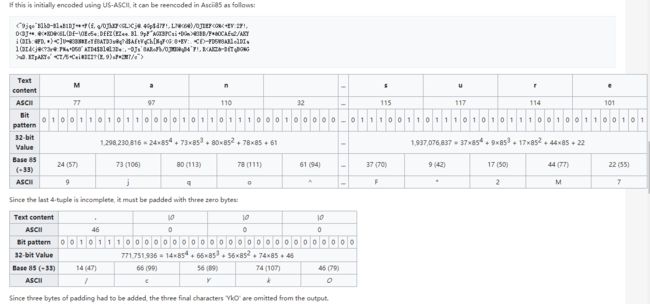
(5)base36
Base36是一个二进制到文本编码表示方案的二进制数据以ASCII通过将其转化为一个字符串格式基数 -36表示。选择36十分方便,因为可以使用阿拉伯数字 0–9和拉丁字母 A–Z [1](ISO基本拉丁字母)表示数字。
每个base36位需要少于6位的信息来表示。(只支持整数)
(6)base58
Base58是用于Bitcoin中使用的一种独特的编码方式,主要用于产生Bitcoin的钱包地址。
相比Base64,Base58不使用数字"0",字母大写"O",字母大写"I",和字母小写"l",以及"+“和”/"符号。
设计Base58主要的目的是:
- 避免混淆。在某些字体下,数字0和字母大写O,以及字母大写I和字母小写l会非常相似。
- 不使用"+“和”/"的原因是非字母或数字的字符串作为帐号较难被接受。
- 没有标点符号,通常不会被从中间分行。
- 大部分的软件支持双击选择整个字符串。

(7)base91
base91需要91个字符来表示ASCII编码的二进制数据。 从94个可打印ASCII字符(0x21-0x7E)中,以下三个字符被省略以构建base91字母:
-(破折号,0x2D)
\(反斜杠,0x5C)
'(撇号,0x27)
base91是将二进制数据编码为ASCII字符的高级方法。
它类似于UUencode或base64,但效率更高。 base91产生的开销取决于输入数据。 它的数量最多为23%(而base64为33%),范围可以降低到14%,通常发生在0字节块上。
这使得base91对于通过二进制不安全连接(例如电子邮件或终端线)传输较大的文件非常有用。
(8)base92
为了超越base82,尝试创造base92
在编码字符串时,```和“与普通引号'太相似,以使其舒适。在区分l / 1和0 / O时使用的字体好。将〜用作特殊符号(空字符串)。有94个可打印的ascii字符,因此最终得到91个字符,或每个字符6.5位。一旦包含〜,则将有92个字符。
一旦每个字符有6.5位,则可以一次使用13位,并使用类似于base85的除法和取模方案,用它们产生两个输出字符。这可能意味着,与base92编码相比,它更能抵抗损坏,因为任何损坏都更加局限(一位更改仅影响2-3个字节,而不影响4个字节)。
注意:在某些需要某些输出的情况下,可能需要将〜用作空字符串分号:
base64和base85更加优雅,将一个较小的字节整数干净地映射到另一个较小的字节整数。base92将13个字节映射为16个字符,从大小的角度来看,这比base85的4至5个字符更好,但是相当不雅观。
(9)base62
Base62编码将数字转换为ASCII字符串(0-9,az和AZ),反之亦然,这通常会导致字符串较短。
26个小写字母+26个大写字母+10个数字=62
- 62进制与10进制的互相转化
62进制转10进制与2进制转10进制相似。
2进制转10进制过程为: 从右到左用二进制的每个数去乘以2的相应次方,次方要从0开始。
62进制转10进制也类似,从右往左每个数*62的N次方,N从0开始。
那么,10进制转62进制也与10进制转2进制类似。 即:不断除以62取余数,然后倒序。
- 关于短Url的转换
主要思路,维护一个全局自增的id,每来一个长url,将其与一个自增id绑定,然后利用base62将该自增id转换为base62字符串,即完成转换。

67、sqltest
https://www.cnblogs.com/yunqian2017/p/15124198.html
题目为SQLtest,猜测可能和SQL注入有关,打开流量包先追踪一波HTTP流
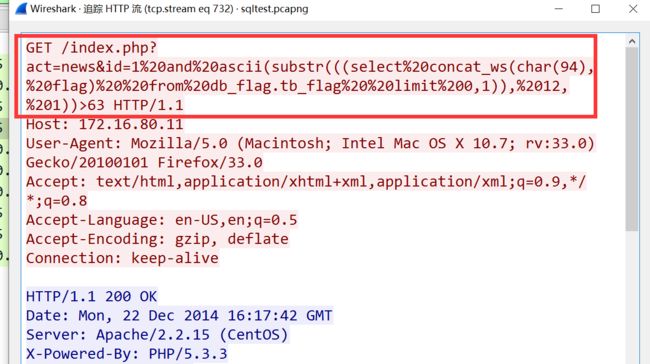
盲注那就应该有很多注入语句,直接导出HTTP对象

导出后确实发现了很多盲注语句,但是阅读起来很困难

于是尝试用tshark提取
tshark -r sqltest.pcapng -Y"http.request" -T fields -e http.request.full_uri > data.txt
:::info
-r 读取文件
-Y 过滤语句
-T pdml|ps|text|fields|psml,设置解码结果输出的格式
-e 输出特定字段
http.request.uri http请求的uri部分
:::
分析提取出的注入语句:
- 获取数据库库名
第九行获取information_schema.SCHEMATA中数据行数的长度(为1)

第18行获取information_schema.SCHEMATA中数据行数,chr(53) = '5',即infomation_schema.SCHEMATA有5行数据

(第19行-第61行+第65,66行)获取每一个数据库的长度

(62,63,64,第67-417行)获取每一个数据库库名

418行已经获取到了库名

- 表
第426行表名个数的长度(为1)
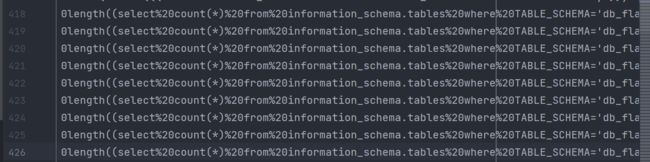
第435行表名个数

第444行表名长度

445-510行表名

第511行已经得到表名了
![]()
- 字段
第519行字段个数长度

第527行字段个数

第545行每个字段长度

546-601行获取每个字段字段名

- 值
第610行获取值个数的长度

第619行值的个数

第627行值的长度

628-972行获取我们需要的flag
这位大佬的python脚本
注入语句为:
id=1 and ascii(substr(((select concat_ws(char(94), flag) from db_flag.tb_flag limit 0,1)), {第i个字符}, 1))>{字符的ascii值}
把第i个字符和ascii值提取出来,取i变化时的值:
import urllib.parse
f = open("data.txt","r").readlines()
s = []
for i in range(627,972):
data = urllib.parse.unquote(f[i]).strip()
payload = data.split("and")[1]
positions = payload.find("from db_flag.tb_flag limit 0,1)), ")
data1 = payload[positions+35:].split(",")[0]
data2 = payload[positions+35:].split(">")[1]
s.append([data1,data2])
for i in range(1,len(s)):
if s[i][0]!=s[i-1][0]:
print(chr(int(s[i-1][1])),end="")
print(chr(int(s[-1][1])))
或者提取出数据放入一个文本
with open('2.txt','r') as f:
data = f.readlines()
for i in data:
print(chr(int(i)),end="")
68、你有没有好好看网课?
下载压缩包得到两个加密的压缩包,flag2没有密码提示也不是伪加密先不管,flag3提示六位纯数字密码,直接爆破得到一个Word文档和视频

打开文档发现有两串数字520和711可能和视频相关

RV打开视频也只有13s于是着重看一下5.20s和7.11s处,得到两处提示


第一处为敲击码
基于5×5方格波利比奥斯方阵来实现的,不同点是是用K字母被整合到C中,因此密文的特征为1-5的两位一组的数字,编码的范围是A-Z字母字符集,字母不区分大小写。
..... ../... ./... ./... ../

解码得到w l l m
第二处为base64解码即可:dXBfdXBfdXA=

结合可得字符串wllmup_up_up尝试打开flag2得到一张图片,010查看,在文件尾得到flag

69、NTFS数据流
解压题目给出的压缩包得到很多txt文本

提示NTFS数据流,直接使用NtfsStreamsEditor工具扫描flag文件夹

70、john-in-the-middle
思路一:
得到一个流量包,先尝试用foremost分离一下,得到一堆图片

发现第一张图片下面好像缺了什么

用ste查看图片在green通道1和0处即可得到flag


思路二:
发现流量包里都是HTTP数据包,直接导出HTTP对象

在导出的文件中发现两张特别的图片

打开scanlines.png,在很多通道中都发现了一条线

logo.png图片中似乎缺了一块

将两张图片使用ste的Image Combiner对比,在相减时得到flag

71、swp
打开题目给的流量包,数据包太多了,先导出HTTP对象看看

导出文件中发现一个secret.zip加密压缩包

先尝试看看是不是伪加密

打开压缩包里的flag文件即可得到flag

72、喵喵喵
拿到题目给的图片后尝试提取、查看十六进制都没有什么线索,于是再尝试用ste查看是否是LSB隐写



在RGB的0通道中发现不同,于是尝试用Data Extract提取

由上图可知明显是一张PNG但是文件头多了FF FE,先保存文件用十六进制器处理,得到半张二维码

得到的图片明显高度有问题,直接十六进制器修改即可

得到一张二维码,虽然正常需要反色再扫,但是QR可以直接扫不用反色
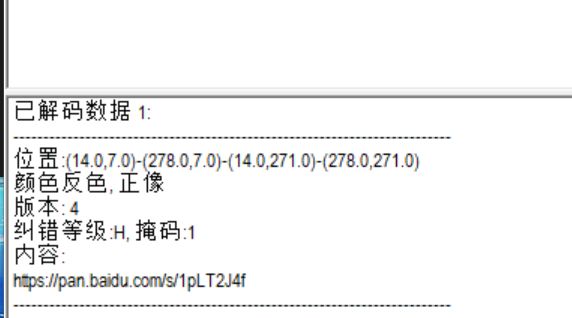
访问给出的网址,得到一个压缩包

没有任何提示只有一个TXT那就尝试一下NTFS数据流,直接使用NtfsStreamsEditor工具扫描flag文件夹

果然得到一个pyc文件,直接反编译,或者使用uncompyle库
uncompyle6 1.pyc > main.py

得到反汇编出的代码
# uncompyle6 version 3.8.0
# Python bytecode 2.7 (62211)
# Decompiled from: Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit (AMD64)]
# Embedded file name: flag.py
# Compiled at: 2017-12-05 23:42:15
import base64
def encode():
# 加密函数
flag = '*************'
ciphertext = []
for i in range(len(flag)):
s = chr(i ^ ord(flag[i]))
# i与flag中第i个元素的ASCII的十进制异或
# 再把上述结果转换为ASCII
if i % 2 == 0:
s = ord(s) + 10
else:
s = ord(s) - 10
# 如果i能被二整除就叭ASCII转换为十进制再+10,否则-10
ciphertext.append(str(s))
# 得到的数加入列表
return ciphertext[::-1]
# 倒着输出
# 根据encode加密得到的列表
ciphertext = [
'96', '65', '93', '123', '91', '97', '22', '93', '70', '102', '94', '132', '46', '112', '64', '97', '88', '80', '82', '137', '90', '109', '99', '112']
# okay decompiling 1.pyc
解密脚本
# 密文
ciphertext = [
'96', '65', '93', '123', '91', '97', '22', '93', '70', '102', '94', '132', '46', '112', '64', '97', '88', '80',
'82', '137', '90', '109', '99', '112']
# 先把密文倒着排序
ciphertext = ciphertext[::-1]
flag = []
for i in range(len(ciphertext)):
# 如果i能被二整除就给十进制数 - 10,否则 + 10
if i % 2 == 0:
s = int(ciphertext[i]) - 10
else:
s = int(ciphertext[i]) + 10
# 异或然后再转换为ascii
flag.append(chr(int(i ^ s)))
# 打印flag
print("".join(flag))
73、SXMgdGhpcyBiYXNlPw==
题目标题为base64先解密

打开题目给出的flag.txt

又是多串base64,直接上大佬的base64隐写脚本
def base64value(c):
table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
for i in range(64):
if table[i] == c:
return i
return 0
def base64stego():
f = open("flag.txt","rb")
lines = f.readlines()
x = ''
for line in lines:
l = str(line, encoding = "utf-8").strip()
if l[-1] == '=':
if l[-2] == '=':
x += bin(base64value(l[-3]))[-4:]
else:
x += bin(base64value(l[-2]))[-2:]
flag = ''
for i in range(0, len(x), 8):
flag += chr(int(x[i:i+8],2))
print(flag)
if __name__ == '__main__':
base64stego()
74、间谍启示录
下载得到镜像文件,先尝试用foremost分离
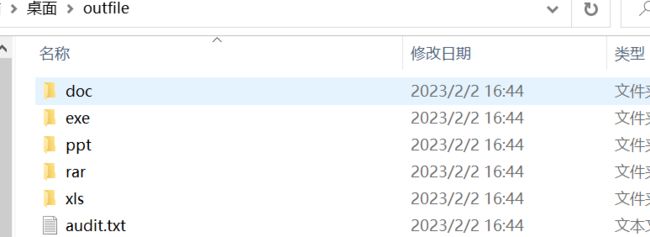
发现只有压缩包提供了有效信息

运行flag.exe得到一个机密文件(需要打开文件夹的隐藏显示)


75、docx
得到Word文档内容没什么提示,于是用010查看,发现文件头为50 4B 03 04这不就是压缩包嘛,直接改后缀RAR

在media文件夹中发现flag

76、Mysterious
题目提示需要逆向分析,首先用PEiD看看是否加壳

未加壳,32位程序,用IDA进行分析,打开后用快捷键shift+F12(string window),发现了个很特别的字符串well done(一般过关后会有类似字符串)

点击进入此字符串在内存中的位置

点击sub_401090,查看调用这个字符串的函数,跳转到汇编图形界面,按f5反编译查看伪C代码。

分析这个关键函数:
int __stdcall sub_401090(HWND hWnd, int a2, int a3, int a4)
hwnd是句柄,a2是消息,a3,a4是其他消息。
memset(String, 0, sizeof(String));
Value = 0;
memset:将string中当前位置后面的sizeof(String)个字节用0替换并返回string
GetDlgItemTextA(hWnd, 1002, String, 260); # 获取输入
strlen(String);
if ( strlen(String) > 6 ) # 输入字符串不能大于6
ExitProcess(0); # 退出程序
atoi(String)=122所以sting的值为122xxx,接下来把3,5,4转化成ascii码看看,
S3=x,S5=z,S4=y
v4 = atoi(String); # atoi函数:将字符串转换成整型
Value = v4 + 1;
v4 == 122 && String[3] == 120 && String[5] == 122 && String[4] == 121
flag赋值给text,然后是置零操作
strcpy(Text, "flag");
memset(&Text[5], 0, 0xFCu);
v8 = 0;
v9 = 0;
_itoa(Value, Source, 10);
itoa函数的功能是将int转化为char,第一个参数是要转化的值,第二个参数是转化后值的储存地址,第三个数是要转化的值的进制,这里为10进制。
strcat(Text, "{");
strcat(Text, Source);
strcat(Text, "_");
strcat(Text, "Buff3r_0v3rf|0w");
strcat(Text, "}");
第一条代码使Text="flag{",接着第二条指令使Text="flag{123",到最后Text="flag{123_Buff3r_0v3rf|0w}"
MessageBoxA(0, Text, "well done", 0);
messagebox,标题为well done,内容为Text
77、黄金6年
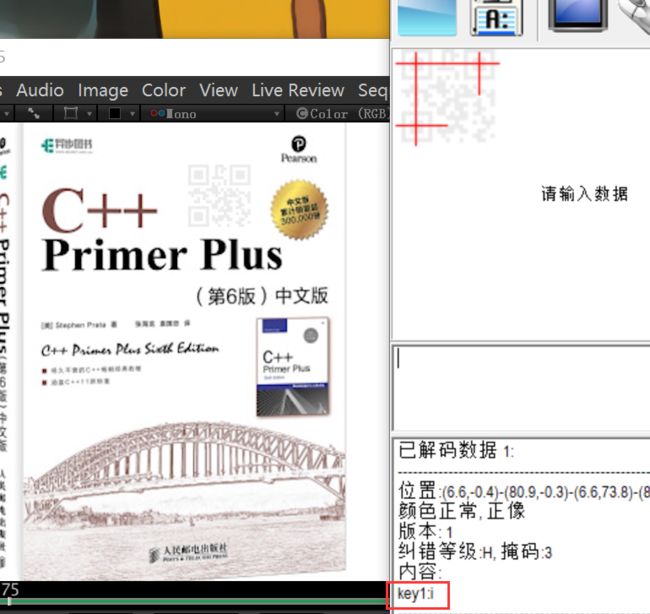
下载得到一个视频,发现有很多图书展示,用RV一帧一帧看看是否藏有东西
果然在第75帧发现一个二维码,得到key1:i
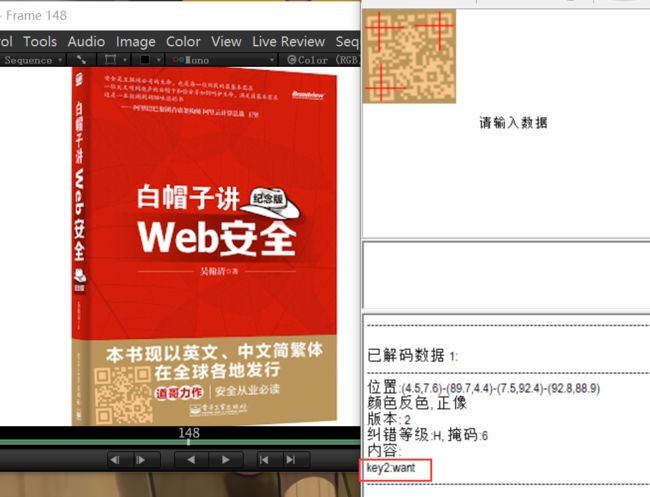
第148帧发现第二个二维码,得到key2:want
第246帧发现第三个二维码,得到key3:play

第303帧发现第四个二维码(眼睛都快看瞎了),得到key4:ctf
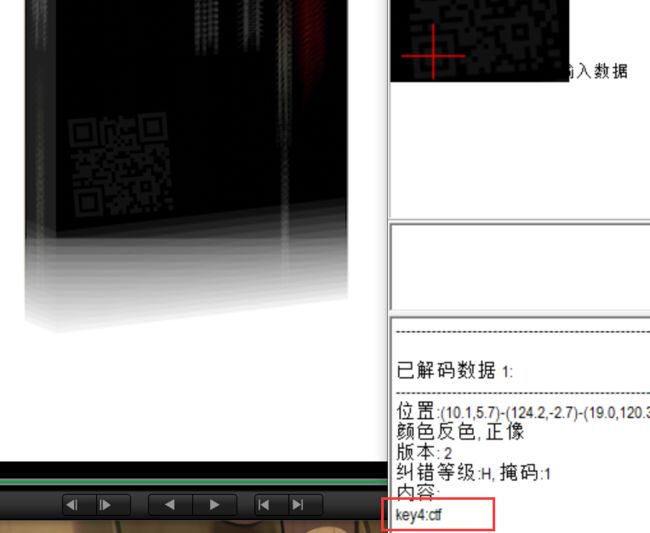
总结字符串为key:iwantplayctf
然后就没有任何有用信息了,尝试用winhex查看,直接拉到最后看一下,发现了一串疑似base64的字符串

尝试base64解码https://the-x.cn/base64:

另存为压缩包,得到一个加密的压缩包,尝试用之前得到的key = iwantplayctf即可解压得到flag
78、弱口令
下载得到一个加密的压缩包,提示弱口令,试了好几个不行,看一下压缩包注释,发现藏了一些东西

复制到sublime中,发现是莫斯密码(空格替换为.,Tab替换为-).... . .-.. .-.. ----- ..-. --- .-. ..- --得到明文HELL0FORUM

解压得到一张照片,额看了大佬博客才知道是LSB隐写(不知道怎么判断的)
隐写脚本
注:from Crypto.Cipher import AES
一直报错并且安装Crypto也无法解决,尝试pip install pycryptodome即可
根据提示弱口令进行猜测,当口令为123456可以分离出flag
python lsb.py extract 1.png new 123456

79、小易的U盘
解压得到的文件,得到很多文件,没有发现特别的提示,但是又有很多auto开头的文件,于是尝试用find命令进行字符串匹配find "flag{" auto*得到flag

或者是看大佬的另外一种解法:
直接查看inf文件发现在副本(32),于是将exe文件用IDA查看(使用快捷键Shift+F12)
inf文件中包含硬件设备的信息或脚本以控制硬件操作,inf是微软为硬件设备制造商发布其驱动程序推出的一种文件格式。inf文件中包含了硬件驱动安装的信息,比如、安装到哪一个文件夹中、怎样在注册表中加入自身相关信息、源文件在哪里等
80、alison_likes_jojo
打开题目给的提示As we known, Alison is a pretty girl.继续打开压缩包
发现里面有两张照片,用foremost分离一下:
先分离boki.jpg得到一个加密的压缩包,不是伪加密,那就老方法纯四位数爆破:

得到beisi.txt

有点像base加密,发现是base64三次编码killerqueen
到现在为止已经没有任何提示了,但是我们得到了一串像密钥的字符串以及一张分离等都无特别的图片,那就怀疑是outguess隐写
Outguess隐写
https://blog.csdn.net/qq_45784859/article/details/105057281
# 加密
outguess -k "my secret key" -d hidden.txt demo.jpg out.jpg
加密之后,demo.jpg会覆盖out.jpg,hidden.txt的内容是要隐藏的东西。
# 解密
outguess -k "my secret key" -r out.jpg hidden.txt
解密之后,紧密内容放在hidden.txt中
用kali里的outguess解密
outguess -k killerqueen -r jljy.jpg out.txt
//outguess -k “密码” -r 被加密.jpg 解密信息.txt
打开out.txt就是我们需要的flag