Dubbo-聊聊Dubbo协议
前言
Dubbo源码阅读分享系列文章,欢迎大家关注点赞
SPI实现部分
-
Dubbo-SPI机制
-
Dubbo-Adaptive实现原理
-
Dubbo-Activate实现原理
-
Dubbo SPI-Wrapper
注册中心
-
Dubbo-聊聊注册中心的设计
-
Dubbo-时间轮设计
通信
-
Dubbo-聊聊通信模块设计
什么是协议
在网络交互中是以字节流的形式传递的,对于字节流都是二进制格式,这样我们就面临一个问题就是如何转化为我们可以识别的字符,协议就是来解决这个问题的,协议用通俗易懂地解释就是通信双方需要遵循的约定。 在日常开发中,我们常见的网络传输协议有TCP、UDP、HTTP。常用的中间件也会定义对应的协议,如Redis、Mysql、Zookeeper等都有自己约定的协议,同样Dubbo的通信也采用一种协议,这些都是应用层协议,都是基于TCP或者UDP设计的。
如何定义协议
应用层协议一般的形式有三种:定长协议、特殊结束符和变长协议,聊到这里就可以抛出来一个常见的面试题,如何解决网络通信粘包和拆包的问题?该问题的解决方案也就是通过约定协议,下面我们就来聊聊这三种模式优缺点以及使用场景。
定长协议
定长的协议是指协议内容的长度是固定的,比如协议byte长度是50,当从网络上读取50个byte后,就进行decode解码操作。
优点
定长协议在读取或者写入时,效率比较高,因为数据大小都是确定的。
缺点
定长协议的缺点在于适应性不足,网络传输中传输的内容的大小不可能都是相同的,因此对于一些长度不够的消息,明显过于的浪费带宽。
特殊结束符
特殊结束符就是在每次传输结束的时候使用一个特殊的结束符,在Redis中的协议采用了特殊结束符,客户端和服务器发送的命令一律使用\r\n(CRLF)结尾。
优点
与定长协议一样读取或者写入时,效率比较高,同时解决定长协议的尴尬。
缺点
特殊结束符方式的问题是必须要有一个完整的消息体才能进行传输,除此之外必须要防止用户传输的数据不能同结束符相同,否则就会出现紊乱。
变长协议
变长协议由定长以及不定长两部分组成,定长部分一般是协议头,此部分会包含变长部分的描述,变长协议我们经常使用的HTTP协议采用变长协议,HTTP请求报文格式是由三部分组成:
-
请求行:包括Url、Version等,由空格分隔,\r\n结尾;
-
请求头:多行,每行是key:value的格式,以\r\n结尾;
-
请求体:请求头与请求体直接由一个空白行分隔,请求体的长度在请求头中由content-length给出;
优点
灵活性比较高,解决了定长协议以及特殊结束符的所有缺点。
缺点
复杂性比较高,需要自定义一套标准,所有消息都需要按照该格式发送以及解析。
Dubbo协议
Dubbo框架支持很多协议,默认采用Dubbo协议,Dubbo协议采用的是变长协议的设计,整体的格式如下:
-
0~7位和8~15位分别是Magic High和Magic Low,是固定魔数值(0xdabb),我们可以通过这两个Byte,判断是否为Dubbo协议;
-
16位是Req/Res标识,用于标识当前消息是请求还是响应;
-
17位是2Way标识,用于标识当前消息是单向还是双向,如果需要来自服务器的返回值,则设置为1;
-
18位是Event标识,用于标识当前消息是否为事件消息;
-
19~23位是序列化类型的标志,用于标识当前消息使用哪一种序列化算法;
-
24~31位是Status状态,用于记录响应的状态,当Req/Res为0时才有用;
-
32~95位是Request ID,用于记录请求的唯一标识;
-
96~127位是序列化后的内容长度,该值是按字节计算;
-
128位之后是可变的数据,被特定的序列化类型序列化后,每个部分都是一个 byte [] 或者byte,如果是请求包,则每个部分依次为:Dubbo version、Service name、Service version、Method name、Method parameter types、Method arguments 和 Attachments。如果是响应包,则每个部分依次为:返回值类型、返回值;

image.png
优点
Dubbo协议整体设计比较简洁,能采用1个bit表示的,不会用一个byte来表示;此外请求头和响应头一致,整体采用一套解析标准就可以,代码实现起来相对简单。
缺点
由于整体的设计相对简洁,导致扩展性不够;
Dubbo协议是如何解析的
在通信篇中我们讲过Codec2该接口,该接口提供了encode和decode个方法来实现消息与字节流之间的相互转换,关于该接口的实现我们没有讲解,这里我们来看看此部分和Dubbo协议有什么关系。
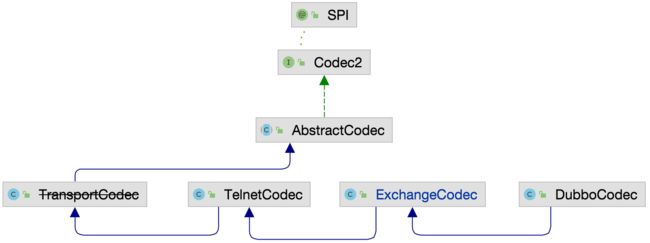
AbstractCodec抽象类没有实现Codec2中定义的接口方法,而是提供了几个给子类用的基础方法。
-
getSerialization方法:通过SPI获取当前使用的序列化方式;
-
checkPayload方法:检查编解码数据的长度,如果数据超长,会抛出异常;
-
isClientSide、isServerSide方法:判断当前是Client端还是Server端;
接下来我们就来聊聊子类如何被解析的,我们可以看到四个子类的继承关系,重点介绍的是ExchangeCodec和DubboCodec,其他就是做一下简单介绍。 TransportCodec该类已经被标注为弃用,该类内部也就是根据getSerialization方法选择的序列化方法,对传入消息或ChannelBuffer进行序列化或反序列化。 TelnetCodec继承了TransportCodec的能力,该类主要是提供了对Telnet命令处理的能力,该功能主要是对服务进行治理的功能,这里后续我们画一点时间来进行介绍。
ExchangeCodec
ExchangeCodec继承了TelnetCodec,在该类基础上增加Dubbo协议头的处理能力,接下来我们首先来看下其核心字段,
//协议头长度
protected static final int HEADER_LENGTH = 16;
//魔数 判断是否是Dubbo协议
protected static final short MAGIC = (short) 0xdabb;
protected static final byte MAGIC_HIGH = Bytes.short2bytes(MAGIC)[0];
protected static final byte MAGIC_LOW = Bytes.short2bytes(MAGIC)[1];
//设置请求响应标志位
protected static final byte FLAG_REQUEST = (byte) 0x80;
//单向还是双向标志位
protected static final byte FLAG_TWOWAY = (byte) 0x40;
//是否事件消息标志位
protected static final byte FLAG_EVENT = (byte) 0x20;
//序列化协议标志位
protected static final int SERIALIZATION_MASK = 0x1f;
通过核心字段我们可以发现其实和我们介绍的Dubbo的协议是一致的,因此接下来的encode和decode就是对Dubbo协议头的解密和编码,我们来下看encode方法,在encode方法中会根据需要编码的消息类型进行分类, 分为三类:Request、Response、telenet,encodeRequest方法专门对Request对象进行编码,encodeResponse方法对Response对象进行编码。
@Override
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
//Request
if (msg instanceof Request) {
encodeRequest(channel, buffer, (Request) msg);
//Response
} else if (msg instanceof Response) {
encodeResponse(channel, buffer, (Response) msg);
} else {
//telenet
super.encode(channel, buffer, msg);
}
}
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel, req);
//存储协议头
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
Bytes.short2bytes(MAGIC, header);
//设置协议头标志位
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
//记录请求ID
Bytes.long2bytes(req.getId(), header, 4);
//序列化请求 并统计序列化以后字节数
int savedWriteIndex = buffer.writerIndex();
//将写入位置后移16位
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
//请求序列化
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
//是否心跳检查 为空就是心跳检查
if (req.isHeartbeat()) {
// heartbeat request data is always null
bos.write(CodecSupport.getNullBytesOf(serialization));
} else {
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
//事件序列化
if (req.isEvent()) {
//事件序列化
encodeEventData(channel, out, req.getData());
} else {
//Dubbo请求序列化
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
bos.flush();
bos.close();
//获取字节数
int len = bos.writtenBytes();
//检查字节长度
checkPayload(channel, len);
//将字节数写入header数组中
Bytes.int2bytes(len, header, 12);
//重置写入位置
buffer.writerIndex(savedWriteIndex);
//写入消息头
buffer.writeBytes(header);
//buffer写出去的位置从writeIndex开始 加上header长度 数据长度
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}
protected void encodeResponse(Channel channel, ChannelBuffer buffer, Response res) throws IOException {
int savedWriteIndex = buffer.writerIndex();
try {
//序列化
Serialization serialization = getSerialization(channel, res);
//协议头 长度为16字节
byte[] header = new byte[HEADER_LENGTH];
//魔数
Bytes.short2bytes(MAGIC, header);
//序列化方式
header[2] = serialization.getContentTypeId();
//心跳还是正常消息
if (res.isHeartbeat()) {
header[2] |= FLAG_EVENT;
}
//响应状态
byte status = res.getStatus();
header[3] = status;
//设置请求ID
Bytes.long2bytes(res.getId(), header, 4);
//写入时候真需要加上协议头长度
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
//对响应信息进行编码
if (status == Response.OK) {
if(res.isHeartbeat()){
//心跳
bos.write(CodecSupport.getNullBytesOf(serialization));
}else {
//正常响应
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (res.isEvent()) {
encodeEventData(channel, out, res.getResult());
} else {
encodeResponseData(channel, out, res.getResult(), res.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
} else {
//错误消息
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
out.writeUTF(res.getErrorMessage());
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
bos.flush();
bos.close();
//写入的长度
int len = bos.writtenBytes();
//检查消息长度
checkPayload(channel, len);
Bytes.int2bytes(len, header, 12);
//重置写入位置
buffer.writerIndex(savedWriteIndex);
//写入消息头
buffer.writeBytes(header);
//buffer写出去的位置从writeIndex开始 加上header长度 数据长度
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
} catch (Throwable t) {
// clear buffer
buffer.writerIndex(savedWriteIndex);
// send error message to Consumer, otherwise, Consumer will wait till timeout.
if (!res.isEvent() && res.getStatus() != Response.BAD_RESPONSE) {
Response r = new Response(res.getId(), res.getVersion());
r.setStatus(Response.BAD_RESPONSE);
if (t instanceof ExceedPayloadLimitException) {
logger.warn(t.getMessage(), t);
try {
r.setErrorMessage(t.getMessage());
channel.send(r);
return;
} catch (RemotingException e) {
logger.warn("Failed to send bad_response info back: " + t.getMessage() + ", cause: " + e.getMessage(), e);
}
} else {
// FIXME log error message in Codec and handle in caught() of IoHanndler?
logger.warn("Fail to encode response: " + res + ", send bad_response info instead, cause: " + t.getMessage(), t);
try {
r.setErrorMessage("Failed to send response: " + res + ", cause: " + StringUtils.toString(t));
channel.send(r);
return;
} catch (RemotingException e) {
logger.warn("Failed to send bad_response info back: " + res + ", cause: " + e.getMessage(), e);
}
}
}
// Rethrow exception
if (t instanceof IOException) {
throw (IOException) t;
} else if (t instanceof RuntimeException) {
throw (RuntimeException) t;
} else if (t instanceof Error) {
throw (Error) t;
} else {
throw new RuntimeException(t.getMessage(), t);
}
}
}
ExchangeCodec的decode方法是encode方法的逆过程,会先检查魔数,然后读取协议头和后续消息的长度,最后根据协议头中的各个标志位构造相应的对象,以及反序列化数据。
DubboCodec
在ExchangeCodecencode的encode方法中,不论是encodeRequest还是encodeResponse都调用encodeRequestData方法,该方法会对Boby内容进行编码,该方法实现是在DubboCodec中,因此DubboCodec是对消息体的编解码,接下来我们来看下encodeRequestData和encodeResponseData方法的实现,
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
RpcInvocation inv = (RpcInvocation) data;
//dubbo服务版本
out.writeUTF(version);
// https://github.com/apache/dubbo/issues/6138
String serviceName = inv.getAttachment(INTERFACE_KEY);
if (serviceName == null) {
//服务path
serviceName = inv.getAttachment(PATH_KEY);
}
//服务名
out.writeUTF(serviceName);
//版本号
out.writeUTF(inv.getAttachment(VERSION_KEY));
//方法名
out.writeUTF(inv.getMethodName());
//方法类型描述
out.writeUTF(inv.getParameterTypesDesc());
Object[] args = inv.getArguments();
if (args != null) {
for (int i = 0; i < args.length; i++) {
//参数值
out.writeObject(encodeInvocationArgument(channel, inv, i));
}
}
//附加属性
out.writeAttachments(inv.getObjectAttachments());
}
@Override
protected void encodeResponseData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
Result result = (Result) data;
//检验版本
boolean attach = Version.isSupportResponseAttachment(version);
Throwable th = result.getException();
if (th == null) {
Object ret = result.getValue();
if (ret == null) {
//空结果
out.writeByte(attach ? RESPONSE_NULL_VALUE_WITH_ATTACHMENTS : RESPONSE_NULL_VALUE);
} else {
//正常写入
out.writeByte(attach ? RESPONSE_VALUE_WITH_ATTACHMENTS : RESPONSE_VALUE);
out.writeObject(ret);
}
} else {
//异常
out.writeByte(attach ? RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS : RESPONSE_WITH_EXCEPTION);
out.writeThrowable(th);
}
if (attach) {
//Dubbo版本号
result.getObjectAttachments().put(DUBBO_VERSION_KEY, Version.getProtocolVersion());
out.writeAttachments(result.getObjectAttachments());
}
}
结束
欢迎大家点点关注,点点赞!