4.多层感知机-2简化版
#pic_center
R 1 R_1 R1
R 2 R^2 R2
目录
- 知识框架
- No.1 多层感知机
-
- 一、感知机
-
- 1、感知机
- 2、训练感知机
- 3、图形解释
- 4、收敛定理
- 5、XOR问题
- 6、总结
- 二、多层感知机
-
- 1、XOR
- 2、单隐藏层
- 3、单隐藏层-单分类
- 4、为什么需要非线性激活函数
- 5、Sigmoid函数
- 6、Tanh函数
- 7、ReLU函数
- 8、多类分类
- 9、多隐藏层
- 10、总结
- 三、D2L代码注意点
- 四、QA
- No.2 模型选择+过拟合和欠拟合
-
- 一、模型选择
-
- 1、预测谁会偿还贷款
- 2、发现
- 3、训练误差和泛化误差
- 4、验证数据集和测试数据集
- 5、K-折交叉验证
- 6、总结
- 二、过拟合和欠拟合
-
- 1、过拟合和欠拟合
- 2、模型容量
- 3、模型容量的影响
- 4、估计模型容量
- 5、VC维
- 6、VC维的用处
- 7、数据复杂度
- 8、总结
- 三、D2L注意点代码
- 四、QA
- No.3 权重衰退
-
- 一、权重衰退
-
- 1、权重衰退
- 2、使用均方范数作为硬性限制
- 3、使用均方范数作为柔性限制
- 4、演示对最优解的影响
- 5、参数更新法则
- 6、总结
- 二、D2L代码注意点
- 三、QA
- No.4 丢弃法
-
- 一、丢弃法
-
- 1、丢弃法
- 2、动机
- 3、无偏差的加入噪音
- 4、使用丢弃法
- 5、推理中的丢弃法
- 6、总结
- 二、D2L代码注意点
- 三、QA
- No.5 数值稳定性+模型初始化和激活函数
-
- 一、数值稳定性
-
- 1、神经网络的梯度
- 2、数值稳定性的常见两个问题
- 3、例子:MLP
- 4、梯度爆炸
- 5、梯度爆炸的问题
- 6、梯度消失
- 7、梯度消失
- 8、梯度消失的问题
- 9、总结
- 二、模型初始化和激活函数
-
- 1、让训练更稳定
- 2、让每层的方差是一个常数
- 3、权重初始化
- 4、例子MLP
- 5、正向方差
- 6、反向均值和方差
- 7、Xavier初始化
- 8、假设线性的激活函数
- 9、反向
- 10、检查常用激活函数
- 11、总结
- 三、QA
- No.6 实战:kaggle房价预测+加州2020年房价预测
-
- 一、kaggle房价预测
- 二、加州2020年房价预测
- 三、AQ
知识框架
No.1 多层感知机
一、感知机
1、感知机
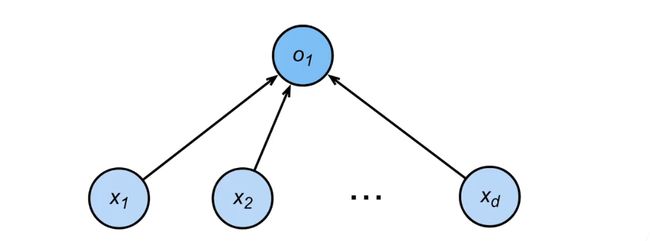
我们来讲感知机;这个是1960年的时候感知机的一个原型图;还可以看到这双每根线;它真的就是一根线连过去;所以它是一个特别巨大的一个模型;
然后呢我们来讲讲一下感知机;这个是人工智能最早的一个模型了;是 70年前嘛;感知机其实是一个很简单的模型;我们说给定输入x;x是一个向量;权重是一个w;也是一个向量;然后偏移呢;是一个标量;那么感知机的输出是;w和x做内积;就是你的权重和你的输入;两个向量做内积;加上你的b;然后呢再在上面做一个Sigma函数;
Sigma这里有很多种选择;第一个选择是说;你可以把它改成一个是;如果你的输入是大于0的话;我就是输出1;小于等于0的话;那我就输出0;就是说;感知机其实就是一个二分类的问题;如果你输入大于0就是一;正类;如果小于0;可以是 0;当然你可以改成0和一;当然你随便怎么改了;
我们当然可以改成说;比如说我们可以改成;-1也行;比如说;改成-1;比如说你输出正1和负1;所以感知机从;图形上来看;就是说你的输入是X1到Xd;假设你有第一个输入的话;你的输出就是你一个一;单一个元素;我们之前看过;就是单一个;元素的输出;你可以做成一个二分类的问题;所以跟我们之前的回归;线性回归的输出不一样;是说虽然它都是一个输出;但是线性回归是一个实数;这里我们输出的;是一个离散的类;
另外一个是说跟我们的Softmax的区别;是说Softmax如果有n个类的话;它就会输出n个元素;所以是可以是一个多分类的问题;而这里我们就输出一个元素;所以它只能最多做一个二分类的问题;


2、训练感知机
看一下;当年是怎么训练这个感知机的;这个算法也是非常简单;大家可以看一下;
首先呢w是0和B也是0;所以跟我们之前会不一样;我们之前w是一个随机的一个权重;这里就直接给0了;然后呢我们对一个样本i从0开始;一直到最后;假设当前是第i个样本;那就是如果你的yi就是你的标号;再假设是正1和负1两个标号;然后呢乘以w;和x做内积;加上B;如果它小于等于0;那是什么意思呢;意味着是说你分类;感知机把这个样本预测错了;
因为如果你是;首先看yi;假设这个项如果是大于0的话;那么就意味着你要分类成一个正类;那么呢假设你的YI是正1的话;那么它就是一个大于0的一个数;假设你小于等于0;那意味着YI那就是一个-1;所以就表示你分类分错了;反过来讲;如果你是小于等于0的话;但是呢你的;这样子你就预测应该是一个-1;如果呢;你的y你的真实的又是一个正1的话;那就是你分类又分错了;那就是满足这个情况的话;一定是说当前的权重;对我们的样本的分类是一个错误的;那么呢如果是分类错了;那我怎么做呢;
就是对w我们做一次更新;w等于w加上yi乘以Xi;就是说你的标号乘以你的样本;然后把它做权重更新;那么你的标量呢;就是你的偏差就是b等于b加上yi;然后就这一步就结束了;然后你一直做;一直做一直做;直到你所有的类都分类正确了;这也是个很有意思的一个停止条件;
那么它的等价于呢;就是说这个算法其实就是一个;梯度下降了;它等价于使用一个批量;大小为1的梯度下降;我们理解一下;PDR大小唯一;就是说每一次你拿一个样本去做;算梯度然后进行更新;然后我们没有说它是随机;梯度下降是因为;感知机最原始的模型;就是你不断一遍一遍的扫扫数据;没有说要随机去弄;如果你是使用梯度下降的话;那么感知机;那个就等在于使用下面这个梯度函数;下面这个损失函数;它的损失函数是说;首先你算一下标号y乘以w和x的累积;然后有个负号在这里;然后取了一个MAX;MAX是干嘛的呢;就是说MAX这个东西;这个东西就是说;我又换一个颜色;MAX其实是对应的这个if的语句;就如果你的分类正确的话;分类正确的话;那么说这一个项是要大于0的;那么你的负的话;那么就是一个负数;那么你的Max就输出是为0;那么你的梯度是一个常数;我就不会去做更新;就是对应的这个if;上面这个if语句不成立;那如果是说你分类错了的话;那么这时候你就有梯度了;就进入到上面那个if的语句里面;进行更新;所以说为什么你要加一个Max在里面;所以这个就是说;感知机等在于我们用这个损失函数;然后呢;使用批量大小为1做梯度下降;这就是当年60年代;我们发明的一个算法;怎么样对应到现在的;技术而且它之所以叫感知机;确实是因为跟神经网络;跟人的神经网络是相关的

3、图形解释
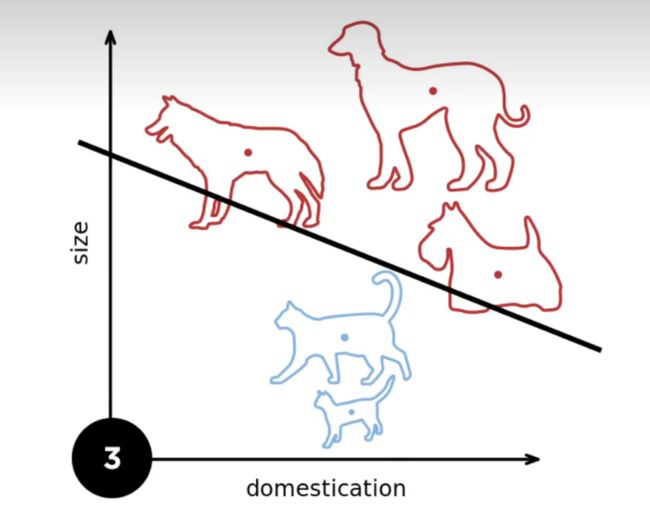
好接下来我们看一个例子;首先我们假设两个;我们要分狗和猫;然后呢我们要两个轴;一个轴和第二个轴;就是一个二元的输入;假设我们有一个狗;和一个猫;那么呢我们权重;现在的分类就是我们的一个;这根黑色的线;下一次假设来了一只新的狗;那么刚刚那个线;如果我们还画在这里的话;刚刚这个线大概是在;这个地方指的样子;那么就是说;你会发现他他对狗分类分错了;那么就是说我会对样本做一次更新;就把这个线往下移一点点;就说因为狗在下面嘛;然后你这个压;你这个分割面加上这个狗的拳头;它就会把这个分解面往下拉;然后你再来一只狗;它就再往下拉;你下面一只猫也会往回推一点点;然后你再不断的做几次;基本上就是;你可以一直做做做;做到最后;发现所有的样本看完;所有的分类都没问题;那么我们就可以停止了;所以这一个奇怪的停止条件是说;你得对所有的类都分类正确;
4、收敛定理
他的收敛定理是什么样子;所谓的收敛定理是说;我什么时候能够停;我是不是真的能够停;感知机是一个很简单的模型;所以它呢有一个很好的收敛定理;我们做这么几个假设;假设我们的数据;在一个半径为r的一个区域里面;就是说;假设这个区域是它是为r的;然后呢我假设有个余量ρ;使得我存在一个分解面;存在一个一个这样子的分解面;它的权重的l;two long加起来是小于等于一的;使得我这个;分界面能够对所有的分类都是正确的;记得吗;这个东西要大于等于0;才是分类正确的;就是说对它所有东西都分类正确;而且它是有一定余量的;就是说你看到是;这有个ρ;ρ是一个大于0的东西;就是说你可以对应的话;就是就是这一个头像换一换一点点;就说这个地方是有个ρ在这里的;就存在一个;margin;使得我刚好能够把所有的类都分开;那么如果是;这样的情况下;感知机确信能够找到我们的最优解;而且它保证我只会在;r平方加上e除以r平方之后;收敛就是会停止;这个地方可以大家理解一下;这个就说r的话;就是说你的数据的大小;当你是一个很大很大的区域的时候;当然你的收敛就会变慢对吧;假设你要在一个很大区域;一开始我们的w是0;所以就说;假设你的数据在一个很大区域的话;那我肯定要走很多步;第二个是说你的ρ;就说看你的这个;数据是不是很好;很好的话;就是说我能够真的两个点分的特别开;如果分的很开的话;当然我这就很简单的数据;我很快就收敛了;如果你不行的话;那么就是说;如果你的分割面特别小;那么要找到这个地方;就会花更多的时间;这就是感知机的收敛;我们这里就是解释一下感知机在;收敛定定理长什么样子;我们不讲证明了;大家有兴趣的话可以作为一个练习题去看一下这个怎么证明;它的证明其实也是挺简单的;大概可能10行代码不行;10行公式能够搞定;好;所以我们刚刚讲到的是;感知机的一个收敛定理
[感知机的收敛定理的证明](感知机模型(Perceptron)的收敛性解读 | 统计学习方法 - 知乎 (zhihu.com))

5、XOR问题
感知机它不能拟合XOR这个函数;XOR这个是什么意思呢就是说;假设我们我们来画一下;假设我这里画一个两个轴的话;就是x和y的话;那么这个点是一;这个点是一;这个点是-1-1 X 2;是说当我的输入x和y都是一的时候;那么它的它就是一个-1类;就是不一样;我就是出;出0就出一个0;我就认为是一个-1类或者0类都没关系;如果是相;不相同的话;那就是正一类;就说这也就是是说;红色两个点是同样一个类;绿色两个点呢;是同样一个类;感知机大家知道;如果是二维的输入的话;
那么它的分割面;因为它是一个线性模型;一定是一道线;
可以看到是说你不管怎么切它;你都无法在一条线;把整个数据给分对;比如说你切在这个地方;这个地方的话;那么你的;红色在一边;但是绿色就分开了;如果你切在下面的话;如果是绿色分对了;但是红色有一个是错误的;所以就是说;感知机不能拟合XOR的函数;因为它只能产生线性分割面这;个是Miski和在1969年提出的;一个说你们感知机什么时候不work好;这个事情直接导入了;导致了AI的第一个寒冬;他觉得哎;你这个模型搞那么复杂;我建一个那么大的机器;结果发现;我连个最简单XOR函数都不能做的话;那么我用;你们这一套干什么;因为接下来;大家就会去转到一个别的一个方向去;这个方向我们不会在这里介绍了;就是说在;神经网络这一块;甚是甚至是机器学习这一块;在1969年;因为大家发现感知机不能拟合XOR函数;导致大家哈哈哈;都去转行了;OK;所以呢;到10年还是15年之后;大家才发现;我其实有办法来做这个事情了;做这个事情的办法叫做;多成干自己


6、总结
我们先总结一下;感知机是一个off类的模型;就是它输出;一或者0或者一或者-1;它是最早的AI模型之一;它的求解算法当时候就是感知;其有自己的算法;现在来看就是等价于一个;批量大小;1的一个梯度下降;但是因为感知器过于简单;它不能拟合XOR函数;导致了我们第一次AI的寒冬;这就是一个总结;;

二、多层感知机
1、XOR
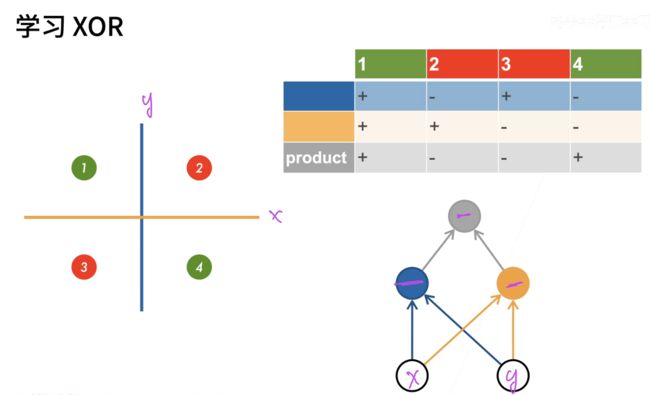
多层感知机;这个是我们现在深度学习;也是经常使用的一个模型;我们先把多层感知器过了之后;我们统一来回答问题;所以我们还是回到我们的XOR这个问题;我们来看一下;我们怎么样来解决这个问题;这样我们有;这个4个点;然后呢我们想要把它完全分类的话;那么你肯定是走;单线性模型是不行的;那么我们现在可以通过几个几步;来完成它;我们先看第一步;第一步我们学习一条蓝色的线;就是这个蓝色的线;蓝色的线呢;就是说;当你x是1的时候;那么全部放在这一边;你x小于0的时候;全部走这一边;所以是蓝色的分隔面干的事情;所以它对应的是说;这一行你可以看到是;蓝色这个线对1和4;2和3;1和3我们就给的是一个正号;就2和3给的是一个负号;在这个地方看见没有;
然后呢我们再学习一根黄色的线;黄色的线就是说你根据y的值来看;y的值你可以看到是说;当你1和2;就1和2;我们给一个正的;然后3和4;3和4我们是给一个负的值;那么有了;蓝色的分类器和黄色的分类器;结果的话;我们再对两个结果做乘法;可以看到是说;相同的值;我们就是做;看你是不是一样;就说你是一样的话;那么就是说正正我们是得正;如果你负负的话也得正;如果你不一样的话;那我们就是得成;做成一个负一;
所以这样子的话;那么我们就可以对它做一个分类了;可以看到这个图;我们假设我们要把这个图画出来的话;那就是;我们这里是x;这里是y;那我们先进入我们的蓝色的一个蓝色;分再进入我们的黄色分;最后它的结果进入我们的灰色分;灰色感知机;我们就可以得到我们正确的结果;所以说;这什么意思呢;就是说假设你一次做不了;那我先学一个简单一点的函数;再学一个简单函数;然后再用另外一个简单函数;组合两个函数;那么就是说我们就从一层变成了多层;这就是多层感知机所来干的事情;
2、单隐藏层
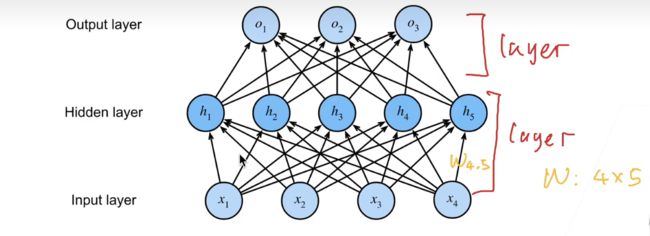
简单来讲它就是一个这样子一个图;首先呢我们的输入是;有X1 X2 X3 X4四个;然后呢我们加入了一个隐藏层;就是说它是一个;假设我们有五个隐藏层的话;那么就是说;所有的第一个X1到X4的话;先进入算第一个H1;然后算到H1直到H5;然后它的输出再作为输入;放到一个下一个层;所以隐藏层的大小是一个超参数;
为什么呢;是因为输入的大小你是不能改的;因为你数据有纬度;有多大那就有多大;然后呢但是你的输出的话;你就是看你有多少类了;你的输出的大小等于多少类;所以都是你的数据决定了;所以你唯一能干的事情就是说;我能够设置我的隐藏层是有多大;

3、单隐藏层-单分类
记得结合上面那张图 进行;;
看一下它是具体来讲是怎么做的;首先我们还是看到那个感知机的模型;我们考虑一个单分类的问题;输入我们跟之前一样的;是一个n维度的一个向量;隐藏层呢;就说;假设我们的隐藏层的大小是m的话;那我们的隐藏层它有一个W那就是一个m乘以一个n的一个矩阵;我的偏移;我有多少个隐藏层;那我就有多少个标量的偏移;所以它也是一个长为m的一个向量;输出层;这个是我们新的一个东西;输出层因为我们是做单分类;我们只输出一个的话;那么输出层就是一个很简单的;一个长m的一个向量;
因为我们的输入隐藏层的a;隐藏层是有m的话;那么隐藏层的输出就是m;长为m的一个向量;那么到对于输入层来讲;它的输入的维度就是m;但它是单分类嘛;所以它的输出就是一;这就是一个向量;那么它的偏移那也是一个B2;也是一个标量;那么具体怎么计算的话;
就是说;这个跟之前是一样的;跟我们的Softmax回归是一样的;就是说;输入乘以我们的权重;加上我们的偏移量;但是这里有一个东西;就是一个Sigma东西Sigma;我们可以之后再看是什么;这是一个激活函数;它是一个按元素做运算的一个函数;然后呢h是一个长为m的一个向量;它作为输入进入到输出层;那么就说输出层的权重是W2;那么它的转置乘以它向量做累积;加上我们的偏移;那么的输出就是一个标量;

4、为什么需要非线性激活函数
为什么我们要一个激活函数;而且;这个激活函数一定是要一个非线性的;你不能Sigma x就等于x是不行的;或者等于n倍x也是不行的;我们来看一下为什么;假设我们的激活函数是本身的话;那就是;等于x的话;那么你会变成什么样子呢;就是说我的h它就是等于你的输入了;你叫等于i了就是等于本身了;那么呢我如果把h带入到这个地方;那你可以看到是说我把这一项带进来;那就是;这第一项会变成了一个W2的转置;乘以W1乘以x;然后后面一项我就不管了;后面一项就是反正没有;反正是一个向量;跟一个另外一个项量做累积;再加上一个标量还是一个标量;就是说;假设Sigma是;我写一下;假设我Sigma x等于x的话;那么你这个地方呢它;的输出就是一个还是一个线性函数;因为你这个项你就等在于一个;比如说等在一个WPA的转制;它还是一个向量;说明还是一个线性模型;你可以换成一;比如说我再加一个a进来;加一个a进来也不会有什么变化;那就是再多一个a;就是说你的Sigma;就一定不能是一个线性函数;如果你是线性函数的话;你会发现它等价于一个;单层的;感知机;所以这个也是我们实现的时候;常犯的一个错误;就是说你不小心没有加激活函数;那么就说你把n个全体阶层剁在一起;最后发现;结果其实还是一个最简单的线性模型;

5、Sigmoid函数
最最简单也是最经典的;叫做sigmoid的函数;它就是说;对于x来讲;我不管你是什么值;我把你投影到一个0和1;的一个区间里面;而且是一个开区间;你可认为它就是一个sigmoid;就是说如果;记得我们之前的感知机讲的是什么;它就是;如果你的x大于0的话;那我就变成一;如果你不然的话就变成0;但是呢你如果你是这个函数的话;它很硬这个函数的话;它其实你要画出来就是一个;画出来就是一个;这样子的东西;它这么一个;大家我们之前有讲过;这个这个地方不好求导;这个地这个这一块;地方不好求导;所以呢就是sigmoid;其实它就是一个soft版本;就是说你可以看到是;我这也就是帮你这么给你;接过来了;就是比较平和的一个版本呐;这就是sigmoid;它的具体的定义就是你的x;我先做负x进去;然后这一个项把它变成一个正数;然后一加上一个正数;分级就是;一定是在一个0和一之间的区间里面;

6、Tanh函数
另外一个常用的激活函数叫做Tanh;区别是说;它是将输入;投影到一个-1和1的一个区间里面;;它的定义当然是1减去你的EXP;除以一加上EXP的;都是有个范围在里面;我们可能之后可以给大家解释一下;为什么要有个far;far就是说嗯;当然是说;你可以看到他人呢;他是一个;他是一个这个函数的;一个一个soft版本;如果我们就是把这个函数很硬的;拉到一个正1到负1的话;那其实是;不是那么的好;就是训练起来比较麻烦;

7、ReLU函数
是一个叫Relu的一个激活函数;它的真实的名字叫做rectified linear units;其实它就是一个Max (x和0);就是说整个深度学习;就是把一些东西给你重命名一下;就说back provation对吧;那其实就是一个自动求导领域的;一个很经典的模型就是说基本上;深度学习就是把很多旧的东西;我们重新;至少深度学习在我觉得在;2014年前;基本上都是一些经典的东西;把它从命名;但之后我们确实有新的东西出来;我大概就是;当然;你现在吐槽也就能吐到2014年的样子;OK所以;Relu函数;本身就是一个很简单的东西;它就是一个x和0;求Max;或一些;我们之前那个感知机是怎么回事;所以它的函数画起来;就是个这样子的东西;所以他的函数大家会记到求导是说;他这个项是这个项的导数是正1对吧;后面导数是0;就说如果他就;他就是一个很简很简单的;本来是你;你激活 x等于x肯定是不行的对吧;这个就那线性函数是不行;你怎么把它给线性去掉呢;就是把它弹一下对吧;就把那个小于0的话就放掉了;叫Relue其实呢
但是它的主要的好处是;什么呢它算起来很快;不要做指数运算;看一下回忆一下;之前之前我们要做两个指数运算;这里我们要做一个指数运算;指数运算是一件很贵的事情;在CPU上;一次指数运算;你可能要等价于算100次乘法运算的;成本GPU稍微好一点点;它有自己的单元来做指数;但还是很贵;但现在好了;我就一个Max搞定了;所以就是;这个就是为什么大家都用Relu;主要是它简单;

8、多类分类
好我们再做到多类的问题;就是刚刚我们讲的是softmax;是一个单类问题;我们可以做到多类;多类的话会怎么样呢;就是说;那么跟我们之前一样;跟多类;Softmax回归没本质区别;就是我假设我要做k类分类的话;那么呢我就是要输出;k个元素;然后我们呢;因为我们想要得到置信度的话;那我们就放到一个Softmax的一个操作;呃值里面拿到的是Y;一直到YK;Softmax大家还记得吧;就是他也不干什么事情;就是把所有的输入;拉到一个0和1之间的区域;然后使得他加起来;Y1一直加到YK;加起来等于一;就变成一个;概率这就是Softmax干的事情;所以你看到多类分类;跟Softmax没本质区别;是说我唯一加的就是这一块了;我来划一下;我唯一加的就是中间那一层;假使没有的话;那就是我们最简单Softmax回归;假设我加了一层隐;藏层;那么它就会就会变成多层感知机;OK这就是一个名字上的变化;那就是说你看到它就是在;Softmax回归里面加入了一层;


那么我们来看一下它的;定义定义跟之前没本质区别;就是唯一的区别就是;这里我们变成了k;就说因为我们的输出要有k个单元;所以我们的输出层的W2;就是一个m乘一个k的一个矩阵;那么偏移;那就B;也是一个常为k的一个向量;所以;另外一个跟之前的区别是说;所以这里面其实没区别;这就是说你从嗯;我们从一个;因为我们是这个这个写法;我们为了跟之前统一;所以我们把k放在后面;所以这里有个转置在这个地方;所以你这里就是从向量变成了矩阵;这里从标量变成了向量;另外一个区别是说对于你的output来讲;我们要做一次;Softmax这就是做多类分类的多层;多层感知机是长什么样子;

9、多隐藏层
那我可以做多隐藏层;比如说;你有一层还不够;我可以做很多层;这里就是一个很简单的一个图;说我可以做很多层;输入层在这个地方;第一个隐藏层;第二个隐藏层;第三个隐藏层;这是我们的输出;那么呢;数学上来说就是每一个隐藏层;它都有一个自己的w;和一个偏移b;
就是说第一层;我们假设这技术W1和B1的话;那么它的输出记得一下;这里有一个激活函数进入到一个;h e就是第一个隐藏层的输出;那么它呢就会嗯看到;它呢就会作为第二个隐藏层的输入;然后同样的话会跟权重做乘法;加上我们的偏移再做一次;激活函数;记得这个激活函数不能少;如果你少了一个;那么就层数就减一了;那同样的话它的输出是HR的话;它会进入下一个层;那么最后的话他会进入我们的输出;输出是不要激活函数的;因为激活函数;主要是用来避免我们的层数的塌陷;最后一层我们不需要激活函数;那么呢;跟之前的区别是说;我们的超参数有多大;
一个是说我们要选择要多少个隐藏层;第二个是说每个隐藏层它有多大;对吧;这里主要是说我们有三个隐藏层的话;那我们就是说一;我们要选个3这个数字;三个隐藏层;然后每个隐藏层比如说是M1;就是这是M3 M2 M1的话;就是说我们要配置好它;到底每一个层长什么样子;一般来说是有一些;技术的一些经验上的东西;就是说;一般来说是说;你把M1设的稍微大一点点;取决于我们可能会去会讲一下;就说我这里可以给大家简单的讲一下;当你说我越大;我的模型就越复杂对吧;我的模型就越大;所以呢根据你会感觉一下;你的输入的复杂度是;有多少;假设你觉得这个数据比较难的话;
那么呢你就有两个选择;一个选择是说我要把我;还是我用单隐藏层;一个选择;我先行我先不考虑的情况下;假设我要用多层感知机的话;那么呢;我一个选择是说我选单隐藏层;把这个m设的稍微大一点点;假设我输入维度是128;那我说隐藏层我可以做;64也行 128也行;甚至256也行;第二个选择呢;是说我可以把这个模型做的深一点点;就说比如说我就不用单隐藏层;我用三个隐藏层;那就说这有三个;M1 M2 M3;那么就是说我如果觉得之前的模型;单隐藏层模型;我的隐藏层的大小是128的话;那么如果你用三层的话;那当然你你最好不要用都是128;这个就太大了;所以你一般来说是说;相对于单隐藏层模型来讲;我的多隐藏层的M1可能会要小一点点;然后M2呢;又比下面小一点点;M3又比人家小一点点;你可以认为;
为什么会有这样子的一个操作;是说假设你的模型;假设你的数据比较复杂;那么通常来说你的纬度是比较高的;比如说128或者256;那么你的输出相对来说是比较少的;10类或者一类或者五类;就是说你要把一个128维的模输入;然后压缩;压缩压缩到一个;5维或者10维的一个空间的话;就本质上你机器学习就是做压缩对吧;你把一个很复杂图片也好;什么东西也好;压缩到一个一个很简单的一;个输出上面你要做压缩的话那你;你最好是慢慢的把它压缩回去;就说这个是最简单的一个做法;就说128的输入先压到64;再压到32;最后再压到16;然后8 然后最后到你的输出5;这是第一个做法对吧;
这也是一个;就说你不断的把你那个数据;进行提炼;那你还可以说;我可以在最下一层;稍微把那个数据给你expand一下;就你把128;我可以先把你做到256;然后再慢慢把你缩回去;但反过来讲;一般来说;你最下一层你可以稍微胖一点点;没关系就说这个例子;这个例子;我们其实是胖了一点点对吧;对本来是4个输入;我们是拿了5个隐藏层;但是大家不会反过来;你不会把它倒过来;你不会把它先压到2;然后再扩充;因为你压到2的时候;你很有可能损失很多信息;就你压缩太狠;损失的东西的话;你后面再还原是比较难的;但之后我们的cnn的话;大家会看到这种;先压缩再扩张的模型;就是说;你如果做的比较好的话;你这种压缩这种先把它压小一点;再把它扩张;就会避免我们模型态overfill;我们会讲overfill是什么意思;OK这就是;多隐藏层的一些简单的设计思路;

10、总结
总结一下;多层感知机;它其实就是使用一个隐藏层;和激活函数;来得到一个非线性模型;它解决了感知机它是一个线性模型;不能和XOR的一个一个局限性;它通过一个加入隐藏层;再加入一个非线性的激活函数;得到一个非线性性;然后呢它常用的激活函数是sigmoid;Tanh和reLu;一般来说因为reLu很简单;所以大家用reLu是用的比较多一点;所以大家假设没有别的想法的话;就用reLu就行了;如果你要做多分类的问题的话;那你就使用Softmax;那就是跟我们之前Softmax回归;其实是没本质区别;就是在中间加入了隐藏层;我们的超参数就是有隐藏层的层数;就是你要放几个;然后和隐各个隐藏层到底要多大;就是你那个要多宽要多窄;OK这就是多;多层感知机;我们讲了一下;从感知系到多层感知机的概念;;

三、D2L代码注意点
无
四、QA
这里的σ函数并不是激活函数;仅仅是设置的 类似 softmax类型的函数;;是作用到输出层的;
输出层并不需要激活函数的;
问题一是说;x大于0 为什么输出是1;通过设计w和b吗;还是通过训练:?
x大于0的时候;就是说我;我不是说x大于0;是说那个σ;那个函数;然后我可以回到我们的;回到我们的那个;对于说哦不;这个x;和我们的输入x不是一个东西;就老师说;这个x是说这个函数的数x;和这个x本质上不是一个东西;它这个x;其实是说你这个整个这个的计算;所以大家可能;这里有一点点误会;所以是说;但是通过学习WB;使得你进入我们的σ;如果是大于0输出为一;我们分类正确;
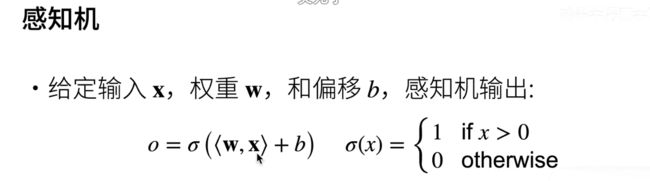
第二个问题是说;请问神经网络中的一层网络;到底是指什么;是指一层神经元经过线性变化后;成为一层网络;还是说一层神经元通过线性变化;加非线性;成为一层?
一般来讲;我们是一层;是包括了那个激活函数的;我们回到我们的在这个;换一个比如说一层;通常的一层呢;我们是讲;带权重的一层;所以这里是有两层;所以我们写呢是写三层呢;但实际上呢;说你怎么看呢;看你怎么看都行;一个看法是说;我假设隐藏层;我把一层画在这个地方;就是这是一个layer;这个这个呢;又是一个layer;就是说输入层我就不算成了;因为它就是一个输入;就是没没什么东西;然后它里面包含什么呢;包含你会发;现每一个箭头;这里每一个箭头它就是一个w;一个;其实它每个箭头包括了就是一个;一个可以学习的一个权重;理解吗就是说我们这个隐藏层;因为你的输入是4;输出是5的话;那么它的权重它就是一个4乘以5;或者5乘4;反正正着写反着写都没关系;然后呢就是说;所以你每一个元素它;对呢是这里面的一根箭头;然后呢当然你这里还有一个SEG嘛;对吧你的SEG;你的h是在计划函数之后的;所以我所谓的一层;通常是说;你这个权重;加上你的激活函数;和它的计算是怎么做的;所以这个里面我们说我们要两层;就是意思是说;我们需要两层可以学习的;层里面带了权重了;但以后我们讲卷积成就网络;也是差不多是一个概念;就是一个层;输入层在这个定义里面;输入层我们就不算层了;反过来讲;你也可以说我可以把这个;这我可以把;那我可以把这个东西归入;输入层对吧;那我就是输输出;那我就是不算层;也可以;反正就是你这因为只要两个w在这里;所以你只要两层;OK;
另外一个问题;是说你的数据的区r是怎么测量;或者统计;ρ怎么定??
;实际中我们确实要找到数据分布的区;可以找到吗;所以呢;所以呢;这个这个就是统计和机器学习的区别;统计我们是不管的;从从统计的角度来讲;我的ρ是定义出;来东西你像数学;我数学我会记;关注你怎么计算吗;我不关注的;我都是假设数据怎么样;假设这个怎么样;所以我的收敛定理;从来都是一个统计上的一个东西;;收敛那一块东西整个是统计上的;统计机器;可以说统计学习吧;嗯但是机器学习呢;或者说深度学习;它可以认为是统计的一个计算面;如果统计;你可以认为是数学的一块的话;那么就是机器学习;对应的是统计的计算机的那一个分支;所以机器学习里面;我们当然就如果是计算;你如果是;学CS的话;你当然不知道ρ怎么算;ρ算起来很难;你当你会去想ρ怎么算;这个怎么算;实际上你算不出来;但我们可以做一点假设;我们可以做人工生成的数据;我是能生成的;但实际上是做不了的;这个只是一个收敛定理;这是一个统计上的一个数学;不能太指导你的实际生产;
问题四是说;请问;是说正是因为感知机只能产生XOR函数;所以人们才会使用SVM吗?
;嗯;其实感知机这个问题还不是SVM;是是上个世纪90年代出来的感知机;其实那一块;当年 60年代;70年代;基本上被冬天来说;SVM还中间还;其实还有几十年;大家其实后面是慢慢多层感知机应该是在SVM之前的;所以是说;但是呢;我们没有;我们这个课不讲SVM;你可认为是说SVM替代了感知机;不能说是SVM;是因为x叫感知机;多层感知机解决了感知机XOR的问题;但是呢之后没有流行;是因为两个问题;第一你得选;超参数你得选那个;嗯你得选那个;要多个隐藏层;每个隐藏层长多大;那个是老中医了;怎么怎么调这个东西;而且收敛也不好收敛;就是说;我们也知道要调各种学习率;才能收敛;然后呢SVM的好处就是说;它没有那么多超参数可以选;它对超成数不敏感;比如说基于科隆和的SVM;它对它你呢;调宽一点;调窄一点都没关系;第二个是说SVN它优化会;接起来比较容易一点点;相对来说不要;不需要用;SGD或者怎么样;第三个可能更重要的是说;对学术界来讲;假设你两个模型的效果差不多;SVM和多层感知机其实就是在现在;其实也是差不多的;就说我没有说多层感知机会比SVM好;没有了;就是说;如果两个模型在实际效果上都差不多;精度都差不多;可能神经网络还好一点点;就仔细调仔细调能调出来;但是呢SVM用起来更简单;就说不用调那么参数;第二个最重要的是说;SVM它的数学很好;现在之所以说我不建议大家用SVM;也没有说SVM不好;就是说你用MLP的话;你试一下;反正如果你想改成一个别的神经网络;你就是你就改一下模型就过去了;优化算法什么东西都不用变;什么东西都不用变;就是改几行就过去了;但是用SVM的话;整个优化都得换;什么东西都得重新学;所以就是说相对来说没那么容易;所以就是说我们这里只讲了MLP;没有;就是多层感知机没有讲SVM的原因;
另外一个是说;XOR函数有什么应用吗?
没有什么应用;就是我给你;就是我给你;举个反例;就是说是什么意思呢就是;就当年做感知机的一帮人说;我这个东西多多厉害对吧;我硬件给你搭出来了;就是你可以看到说;当年感知机我给你做了个硬件;和现在深度学习用GPU也好;做AI芯片也好;没本质区别;就是你的计算跟不上;我给你搭个硬件;所以呢就是说我们催催催;就跟现在深度学习一样的;就是说我可以给你催催催催催催;说我这个东西多好;但是突然有个人跑过来说;其实你这东西有局限性;我给你举个反例;XOR函数简单吧;你不能不能拟合对吧;就是会给你举个反例;让大家一下;就没人没兴没兴趣了;搞半天简单还是多;不能拟合;所以;但是之后你多层感知机你可以证明;是说只要是只要有一个隐藏层;你是可以拟合一个任意函数的;就理论上;你可以拟合任意函数;就是你和你可以一层感知机;能拟合整个世界;就是理论上;实际上做不到;因为优化算法解不了这实际的问题;
第六个问题;是说假设你的x;x轴是特征一;y轴是特征2;那么红蓝是它的label?
对的是这;样子的就是说这是一个x actor函数;就是你有个你可认为是有两个输入嘛;两个特征;所以它的红和蓝是它的label;就是XOR它的输出;所以它的每一个对应的是一条数据;对吧因为四个点;XOR就四个点就定义好了;对吧所以四个点每个点是一个数据;所以说;就是说;我的Excel函数会通过4个样本来一个;4个样本;每个样本是二维;输出是一个正义负义来给定;所以呢就是说;我对一个很简单的4个样本;两维特征的数;你都不能;拟合就说;所以就说;感知机的局限性;就是你理解是没错的;
第七个问题挺好的;就是说你;为什么神经网络要增加隐藏层的层数;而不是神经元的个数;是不是有些神经元万有近似性质吗?
就说这里是一个很好玩的一个东西;就是说;我回到让我来回到我们的slides;好我们回到这个地方;就是说你;我们刚刚讲过;是说你要两种可能;一个是说你变得很胖;就你变得很;就是说我换两个图;就说一个选择输入你的输入进来;我会用一个很胖的一个东西来学;然后输出;ou和in的话;再就是我做一个窄一点的;带胖一点的东西;我还有个选择;是说我同样的模型;我要达到同样差不多的;就是模型复杂度;我们没有讲模型复杂度;你可以认为简单;认为就是我的模型的能力;就是说我可以;可以说我可以做的;这样子做深一;点对吧;每一层搞小一点;就说这个是out;这个心;就说你有两种做法;一种是但是这两个的模型复杂度;其实可认为是可以几乎是等价的;就是说它的capacity;它几乎几乎认为是相等的;从理论上来讲;我们可以证明;它也可以通过合适的理论上相等;但是问题是这个模型不好训练;就是这哪个模型不好训;这个模型;不好训练;这个模型好训练一些;这就这个模型叫深度学习;这个东西叫深度学习;这个东西叫浅度学习;哈哈就那么点东西;就是说;为什么他好训练一些呢;是因为说这个东西;这个东西特别容易overfitting(过拟合);就特别容易过拟合;因为它就是说;就是说你可以认为;就是说我要一次性吃个胖子;在这个地方;因为他每个神经元是一个并行的东西;就说你说;我所有的并行学东西;每个神经元要协调好;一起大家一起合作;学个东西很难;就说理论上可以;但是我们做不了理论解;对吧实际操作特别难;所以他学习起来不好学;但这个东西呢;就好一点点;就怎么意思呢;就是说你要学一个东西;你要学一个很复杂的东西;你怎么学;你不能一开始就把哐哐哐就跳进去;对吧所以你先从简单开始学;比如说;这举一个十贯上例子;这个东西没有理论依;太多依据;我要学一个;比如说我把一只猫的图片;和一只狗的图片;猫猫猫;比如说这是猫狗;我要学一个猫和狗的一个图片;我最后学学;这是个猫;一个cat一个dog;我要把这个东西把一个;就是我要学一个函数;把它从转过去;我怎么转呢;我我不能一次性转;我先说;我先学一点点;学一点把耳朵学出来;学个嘴巴;耳朵可能学耳朵太难了;就学一点简单东西;然后再学个头;对吧学个头;那就是说每一次每一层;你可以把它;做一个简单点的任务;学一点点东西;然后慢慢慢慢的学的;学的学的;学的越来越好;最后学到我的东西去;就是说这是我们的一个;我们的一个;怎么说呢;就是我们觉得神经网络你应该怎么做;但实际上来说;确实深一点的话;他训练起来方便一点;容易更容易找到一个比较好的解;这就是;为什么叫深度学习;所以整个深度学习;你可认为在2004年之前;跟之前没区别;我们之后会讲到;他跟60年代70年代没本质区别;就是说只是做的更深了;那是因为他更深;所以导致他训练起来更容易;所以就是;效果更好;
来看一下;神经元和卷积核有什么关系;?
神经元和卷积核;我们下次讲;卷积我们;我们会讲卷积是怎么从我们现在的;这个多层感知机器;一直过去的;它其实很容易过去的;一个东西就没什么特别Fancy的;
就Relu为什么管用;它在大于0的部分也是一个线性变化;为什么能促进学习呢?;激活的本质是;什么不是引入非线性性吗?
Relu是一个非线性模型;非线性函数;不是一个线性函数;理解吗;比如说所谓的线性函数是一根线;relu它虽然是个直的;但它不是一根线;它是一个折线;折线不是线性函数;线性函数是;线性函数一定是FX等于ax加上b;这是线性函数;线性函数不管怎么样;它就是一根线;Relu虽然它是一根;它是一根直的;但它不是一根线;它是一个;它是一个这样子的东西;所以它不是一个线性函数;它它是很;它是一个peacewise Linear;它是一个分段线性函数;但它不是线性;所以加入Relu之后;对吧所以确实;激活函数的本质是引入非线性性;他不要干别的事情;就是我们之后会稍微解释一下;激活函数;你可以认为它本质就是把非线性打乱;你可以加一个别的模型;都没关系;就说你可以随便加一个;我可以设计任何东西都行;我可以写一点;可以对吧;哦这个斜线描画好;我可以这么写一点点对吧;我我我往上翘也可以;其实没本质区别;我可以我可以这么来这么去;都没关系都;其实都没关系;不要觉得它很玄乎;它唯一的有关系的是;在我们之后会讲;我们预告太多了;就在这个点的之后;梯度会有一点点影响;但是没本质关系;你可以随便选;
不同任务下的激活函数;是不是都不一样哎;是通过实验来确定的吗?
其实都差不多;哈哈你不要激活函数;我觉得就是说;激活函数;它远远没有选择隐藏层大小;那些超参数来的重量;所以大家就;就用Rule吧;就尽量不要用别的吧;就说就说;你可以选;但本质上没有太多区别;;
模型的深度和宽度哪一个更影响性呢;有理论指导吗;是不是加深哪个更有效;怎么根据输入空间;选择最右的深度和宽度?
确实是说理论上来讲没有区别;但实际上来说;深一点的会好一点点;最优这是个最优;最优就比较难了;没有最优;哈哈哈这个东西哪有最优;你可以我们;我们可能会;你可以我们会;我们会有;比赛大家来试一下;是真的要实际来我的;嗯个人的经验;那假设我有一个数据;嗯假设我有一个数据;我想要去做一个;多层感知机;就也叫MLP吧;multilayer perception;我做一个MLP的话;那我一开始肯定不会做很深;我也不会做很宽;假设我还是举个例子;我的数我的输入假设是128;我的输入假设是128;去简单一点;那么我第一步要干的事情是说;我先我先试一下线性的行不行;你就跑一下嘛;线性就没有隐藏层;接下来呢;我来做一个有隐藏层的;就是把一个隐藏加一个隐藏层;那么加个隐藏层;一开始我不会做很大;我做一个16;因为他是128-2嘛;那么16也不错;我换一下吧;我假设我要把128变到一个2; 128-2;我第一个;第一步我会就直接不要隐藏层;直接128-2直接过去;第二次呢我如果觉得我先试一下;第二次我会加一个隐藏的18;比如说老二我加一个16;然后呢 165会再试32;再试比如说再试64;再试128 都可以;那么这个是第二步;就单隐藏色;我会再去看一下;第三步第三步那么就128;假设我这假设;我是说;128效果不行;16也效果不行;这个太简单;这个太复杂;32-24还可以的话;那么第三次我会加一个两个隐藏层;比如说我还是我是用一个32再加一个8;就新加了一个8在这个地方对吧;比这个32稍微复杂一点;那我当然可以;这个也可以改成16对吧;我这个也可以改成64;我这个改成;我还是用回8176;就是说你可以去多试几次;比如说你没有;就是说你从简单开始;慢慢的把它变复杂;你可以通过加宽;加深都可以;就是说你最后去试一下;最后你就是写一个for loop来变一下;所有东西都训练一遍;就是就完事了;但是这个是你最早;你当然你没有什么想法;怎么做时候你就怎么做;如果你接下来;慢慢的有了一些直观上的理解;这个理解我我当然有一些我的理解;但是我不好直接说出来;因为一不好说出来就不好怎么总结;第二个是说过去获得直觉不一;定是对的;所以大家就是老中医;大家试一遍就有感觉了;OK我们还有挺多问题;
为什么多层感知机后面的W2;W3没有转置?
这个东西看你怎么定义啦;就看你定义是m乘n还是n乘m啦;就有我还没仔细看;也可能我数学是错的;写错了就是说转质没转质都没关系;就是说最后看你是W2是定义是从;顺则来还是竖则来;
第15怎么让感知机理和所有函数;又保持动态性能;就像泛化性能;要打造动态神经网络吗;;要不训练完参数是死永远是死的?
是的训练完之后参数是要固定的;就你不要做动态;为什么不要做动;所谓动态;我理解就是说我给一个新我;我给一个同样的样本;我每次做预测的结果会不一样;那就是动态吧;但是这个不行;那个这个东西会有问题;比如说;Google出过一个很大的事情;在很在很早以前;他的图片的分类;把一个黑人分成一个星星;这是一个非常大的问题;在美国所以说你叫种族歧视嘛;等于是你把你把我;我上传一个股图片的Google;你把我分类成一个新星;我把分类成金丝猴;对不对;那我就不高兴;你千万不能让神经网络在分类的时候;有Ren的;心脏里面有会出问题的;就是说你我;比如说我假设有动态性;那我实际测下来;我自己在自己测没问题;感觉每次都分类正确;但实际上deploy的时候;部署的时候发现有一定随机量;因为我可能长得跟金丝猴就是有点像;它本来两个指很像;但是有一定一定的抖动性;使得我变成金丝猴了怎么办;对吧所以;所以你最好是不要有动态性在里面;
但是反过来讲;你所谓的泛化性就是另外一个东西;就是说所谓的鲁棒性;是说我的假设;我我我我在这里我给我分类;分类正确是人;假设我换一下头或者抬一下头;就变成了金丝猴;那是不行的;这数据有变有干扰;有东西变化时候;我的输入应该是要保持比较稳定的;这个是;我觉得;这个就是要比较重要的一个事情;但这个东西;我们我们这个课不会讲稳定性;讲太多这是一个robustness;是一个比较重要的一个话题;我们会讲一些;就是我们整个神经网络设计都是有;要使得它更稳定;但是实际上稳稳定性是有专门的;现在有一个领域在研究;就还是挺新的一个领域;如果你是想做相关研究的话;我觉得是OK的;而且相对很多来医;医疗无人车稳定性都非常重要;就是说医疗你稳定性没搞好;出人命了;无人车你没搞好;出人命了;
在网络训练中;前几次迭代的训练准确率高于验证机;有什么可以解释的办法吗?
有的;我们会;明天会讲;
在设置隐藏层的时候;会人为固定评估特征的数量;然后再设置层数和单元数吗?
其实这个这个是这个;你会用一个验证数据集来做这个事情;你就说你你;你可以猜;猜完之后你得去试;你真的拿数据去遛一遛对吧;所以这个我们也会讲一下;大概你会怎么样做;调参这个就是调参呐;那调参就是整个是整个神经网络的;机器学习的;整个的一个;就是你数据科学家;80%实验在搞数据;80%实验在调参;
No.2 模型选择+过拟合和欠拟合
一、模型选择
1、预测谁会偿还贷款
首先我们讲模型选择;先介绍一下我们怎么样去选超参数;我们从一个简单的例子开始;就我们这里有一个例子;就预测谁会偿还贷款;就假设银行雇你来调查谁会还贷款;你呢拿到了100个申请人的信息;就是他所有的去申请这个贷款的;所有的信息;其中;你发现有5个人在三年之内违约了;就是他;还不清贷款了;所以你的任务是把这五个;把这样子的人找出来;因为对银行来说;你不还贷款还挺麻烦的对吧;然后呢你就去看这100个人的申请信息;然后你发现说;

2、发现
发现有5个人;这5个人;都在面试的时候穿了蓝色的衬衫;在美国;这个蓝色的衬衫;其实是有一个隐含信号;就是一个蓝领;但不管是不是你的模型;也发现了这个很强的信号就是说;5个人都穿了蓝色衬衫;那我模型肯定会发现这个问题;那么当然会有问题这个事情;为什么呢;因为你想一想嘛;我面试的时候穿一个蓝色衣服;那我下次如果穿一个红色衣服;是不是你模型就不一样了;对吧;所以看上去挺有道理的一件事情;你仔细想想;其实是没道理的;但模型不知道;模型其实很容易去被这种信号给;忽略掉;所以呢;我们这里就要研究这个问题

3、训练误差和泛化误差
就是说我们去看这个问题的话;其最正常的是说;我们去看两种误差;就是你这个误差就是;你的损失;比如说我的精度;我的判断的错误;这里有两种误差;
第一种叫做训练误差;就是我的模型在训练数据集上的误差;第二种叫做泛化误差;就是我的模型在新的数据上的误差;就是我们关心的其实是泛化误差;我们其实不关心训练误差;
举个例子;假设说我们来;大家如果参加过高考的话;有模考这个事情对吧;就是模拟考试;然后呢;大家会去根据你模拟考试的分数;来预测未来考试的分数;所以说在模拟考试的时候表现的很好;其实是一种训练;它不代表以后考试一定会好;举个例子;就是说模拟考试的题;很有可能你是见过的;就说;虽然你可能没有看过这一次的卷子;但是你可能在;老师在上课讲过;或者是别的地方都不小心看到过;
所以如果有两个学生;一个学生是说我就是背他;我就把这个题背了;这个是大家常常用的策略;我把这个题给答案给背了;那么所以;你如果把所有的过去的问题都背好了;那么你模拟考试;很有可能你的成绩会很好;所以你会拿到很好的成绩;那学生b呢;假设我是能确实理解;这个题的解决思路是什么样子;所以;如果学生a和b都拿比较好的成绩;那么在真实的考试中;学生a很有可能比学生b要差;甚至是说学生b在考试中;你可能就打个80分;学生a如果是90分或95分;那么你学生;b那有很有可能是说;我大概真实水平就80%;那我真实的考试可能还是80%;但学生a呢;那可能你会比90要低很多;所以就是说;这里训练误差;是指我们在模型看到的数据上;有标号的数据上的误差;泛化误差是在新的数据上的误差;我们关心的其实是泛化误差;所以大家这个两个是一定不能去;搞搞混的


4、验证数据集和测试数据集
然后呢;所以;我们来怎么去计算我们的训练误差;和泛化误差呢;一般来说我们会有两种数据集;一种叫做验证数据集;一种叫做测试数据集;就说这个;其实我们经常容易搞混;所谓的验证数据集;是说我来评估一个模型好坏的数据集;就是我来看一下;我这个选择参数会怎么样;比如说我们昨天有讲过;我们调那个多层感知机的时候;你要取多大呀;你的学习率怎么取;这个东西;我是通过一个验证数据集来验证的;举个例子是说;经常我们将训练数据集分成一半;一半;然后呢;我们就把一半的一半的数据集;用来训练我们的模型;就是训练我们的那些模型参数;第二个第二半呢;也叫做验证数据集;我们就把我们训练好的模型;在验证数据数据集上;测一下我们的精度;我们的误差;我们根据那个精度来看;这个超参数可能不是很行;那么呢我们可能会再换一个超参数;就是我们换一下学习率;换一下模型的大小;然后再在这个验证数据集上;测一下精度;然后我们就可以比较说;这这两个超参数谁好谁坏;就因为是说;我们的验证数据集没有参加训练;所以呢在一定程度上;确实能够反映出;我们的超参数的选择好坏;这里有一个;大家常犯的错误;就是说验证数据集;一定不能跟训练数据集混在一起;这个是不管是新手还是老手;一直会在犯这个错误;
所以这里会引出一个新的概念;叫做测试数据集;就说test dataset;只是说测试数据集理论上来说;它只能被使用一次;你不能用它来调你的超参数;举个例子是说;你未来的一次考试是;就说你就是考试那一次的分数;就决定了;你的分数;你不能再去反过去再去重新考了;或者是说我们做房价;预测的时候;我出价的房子的实际成交价;那是我的测试数据集;一旦发生了就无法改变了;还有是说有时候在开国竞赛中;有一些有一些私有的排行榜的数据集;就说在最后的最后才会公布结果;一旦公布了;然后我们就这个排行榜就固定住了;就大家不会改了;所以是说;这里面测试数据机;理论上来说只能被试用一次;用过之后应该是说;我们就不会再看你下一次的结果了;所以我们上一次提到这个问题是说;用了我的测试数据集;把它作为验证数据集使用;这个是常犯的另外一个错误;当然在我们在接下来的情况中;我们;其实并没有真正意义上的测试数据集;所以很多时候我们在代码里面写哦;这是一个test data;很多时候它就是一个验证数据集;就是一个validation dataset;它不是真正的测试;就说真正的测试是一个新的数据集;甚至你都不知道标号的数据集;但是我们在这里讲清这两个概念;但是以后我们写代码的时候;有时候为了偷懒;就叫test data;或者大家也经常偷懒;就叫test data;其实你要意识到;其实这个只是一个验证数据集;验证数据集很有可能也是一个虚高的;因为你的超参数;很有可能是在验证数据集上调出来的;所以导致说验证出数据集的精度;不是真正的;代表你在新数据上的泛化能力;然后我们这里提到是说;我们在一个训练;数据集上可以拿出50%的数据作为训练;然后剩下的50%做验证;但是这里会有一个问题是什么呢;我们经常遇到


5、K-折交叉验证
一个问题是说;我们没有那么多的训练数据;比如说回到最早的银行贷款的问题;我就有100个;100个申请人信息;如果我就拿50个人做验证的话;你会觉得很划不来对吧;那一半的数据就去做验证集了;所以在实际情况下;确实我们经常是没有足够多的数据;可以使用;如果你直接拿一半的数据集做验证;不参与训练模型的话;其实你会觉得比较亏;所以解决这个问题;常见的一个做法是一个叫k折;交叉验证的一个算法;这个算法其实也是比较简单;就是说;我们呢拿到一个训练数据集后;我们可以先把它随机打散一下;然后我们把它分割成k块;就所谓的k折;就是这一个k;我们把它分成k块之后;然后我们做k次这样子的计算;每一次我们将第K块那个数据集;作为验证数据集;其余的作为训练数据集;OK给大家画一下;就是说比如说我有一个;这是我的所谓的数据集的话;然后呢我把它画成;比如说我要做三则交叉验证吧;就画成三下;然后我第一次的画;那么就是说;我把第一块做为validation dataset;然后这一块做成train;对吧这两块做成犬;我在后面两块上训练;我的模型在我的第一;块数据器上进行验证一下我的精度;然后再第二次的话;那么我把这一块作为我的;variation数据集;然后呢这一块作为我的训练数据集;这块也可以作为我的训练数据集;我还可以做一次;第三次的话;那就是说我写到下面一点点;那我在最后一块做为一个;最后一块;最后最后一块作为我的验证数据记;前面两块呢;作为训练;这样的话;我们会拿到三个测试;验证的精度或验证的误差;我们把这三个精度做平均;就得到了我们的k折交叉验证的误差;所以常用来说;我们取k等于5或的10;当这个好处是说;你会发现;我们至少用了;如果是三者的话;我们用了66%的数据作为训练;嗯然后呢;但是我因为我的呃validation会变小的话;可能会存在一点误差;那么这个误差;我会通过来做三次来弥补;当一个极端的情况下是说;我做一个假设;我的数据长度是n的话;那我做一个n折交叉验证;就是每一次我留一个样本作为;我的验证数据集;剩下的所有作为训练;最后我重复n次;然后取平均;那么这一个极端的算法是说;我能够尽可能的;尽大的使用我的数据集;作为我的训练数据集;但它的代价是说你算起来特别贵;假设你是1万的话;你得跑1万次;所以常见来说;我们一般取5或者15或;5的意思是说;我其实是做了5次训练;等于说我要跑5遍数据;那如果你的;数据很大的话;你可能取k等于2或者3;小一点如果你的数据很小的话;你可以取10或者更高都可以;所以是说k是一个;你要权衡一个;你要用多少数据来作为训练;以及你能承受多少次;多少倍的训练的代价;好这就是k者交交叉验证;也是我们最常见的一个算法;来使用超参数的;


6、总结
所以我们这里有提出了三个概念;第一个概念是一个训练数据集;我们训练数据集;是用来训练我们的模型参数的;第二个数据集不参加训练;它是一个额外的数据集;我们是用来选择模型的超参数;对于非的大数据集上;我们通常会采用一个叫做;k者交叉验证的;一个算法;是每分成k份做k次;每一次留一份做验证;剩下的作为我们的训练集;来通过KXK者的平均的误差;来判断我一个超参数的好坏;所以实际情况就是说;我给你个数据集;我大概有10种不同的超参数;比如说所谓的一种;就是不同的隐藏大小;不同的学习率;不同的什么别的东西;然后呢我采用5折交叉验证;对每一个超参数;都会得到一个交叉验证的平均精度;然后我们把最好的那个精度选出来;作为我们的要采用的超参数;这也是我们常见的一个做法;OK这就是;第一个概念;

二、过拟合和欠拟合
1、过拟合和欠拟合
第二个概念是我们常见的一个现象;叫做过离合和嵌离合;英语上来就叫under fitting和over fitting;

就是我们这里很简单的总结一下;什么叫做过拟合和欠拟合;就我们画了一个表;第一个呢就是说我们的a;第一个是我们的模型的容量;就是我们有讲过模型容量;昨天就是你这个模型的复杂度;你复杂的模型可以学习更复杂的函数;你简单的模型可以;你就不那么好了;就说线性模型它就比较简单;你多层感知机就可以比较复杂;所以你的容量有一个低和一个高;低的话就简单模型了;高就是复杂模型;另外一个是你的数据;你可以有简单数据;你可以有复杂数据;简单数据;比如说我们其实一直在使用的;我们最简单是那个人工数据集;我们还记得;记不记得;就是几个星期前;我们讲过一个人人工数据集;我们的现在常用的是fashion list;它在于简单和复杂之间;算还算简单;里面比较还不错的数据集了;然后复杂的话;你当然可以说;image net或者实际的数据集;很有很有可能都是比较复杂的;所以是说;根据你的数据集的简单和复杂;我们应该来选择对应的模型的容量;最简单是说假设你的数据是简单的话;那么你应该选择比较低的模型容量;这会得到一个比较正常的结果;但如果你简单数据;使用了很复杂的模型容量的话;那就会出现过拟合;过拟合的意思是说你你在模型里;比如说我在一个很简单数据集上;用一个特别深的一个神经网络;那你过拟合就是说你的;你不管你的模型够复杂;我直接帮你每一个样本全部记住;那我记住样本很有可能判看到新样本;我并没有泛化性;第二个情况是说;当你的数据是复杂的情况下;假设你模型容量比较低的话;那你就比较麻烦;你训练不好那个模型;我们有讲过我们的异或函数;它不算复杂数据吧;但是你的模型过于简单;所以无法拟合异或函数;或者说我们做复杂一点;我们做一个就算是fashion list;假设你用个线性模型的话;很有可能你精度不那么好;所以当你的数数据比较复杂的时候;你应该选用比较;比较高一点的模型容量;这样子;你可以得到比较正常的一个模型;所以我们先来看一下;模型容量的一个具体的定义

2、模型容量
模型的容量是指;拟合各种函数的能力;就低容量的模型来拟合训练数据;高容量的模型;可以记住所有的训练数据;我们这里举了一个例子;就可以看到这里有些点就有些点;但是我们的数据;你可认为;我的这个轴是;这个轴是x;这个轴是我的label;那我要拟合这个函数的话;它其实就是一个很简单的线性回归吧;不是线性回归;就是一个回归;一元函数的回归;那么假设你的模型就是一个直线的;画一个线性的话;那么你是无法拟合这个函数;你就是只能算出这一根线的样子;但反过来讲;你的模型够复杂;你可以做一个非常复杂的一个曲线;的话;那么我的模型会会把整个数据给你;完全的拟合住;大家可以看到说;这两种情况都不是很好;就第一种情况过于简单;第二种情况大家知道;应该是比较合理的;范围应该是一根这样子的二次曲线;对吧;所以但是你在函数过于的;去拟合这个函数;把我的造影全部拟合住了

3、模型容量的影响
所以呢;一比较好的一个是这样子的一个东西;就是说嗯;我的x轴是我的模型的容量;这里是呃;这里是低;这里是高;那我的y轴是我的;误差就是我在我的这个模型;在数据上面的一个训练;就假设我们的数据集是固定的情况下;是一个中等数据集;那么我们可以从模型从低开始;从最简单模型一直做到最高的模型;这个其实也是我们常见的调参;的一个策略;看到会怎么样;首先是说假设你的模型比较低的时候;那么你的训练误差就会比较高;这是因为你这个模型过于简单;你无法拟合我这个也还算复杂的数据;那你的泛化误差一样的是高;然后随着你的模型的容量增加;那么你的训练的误差就是;我对数据的拟合能力是开始下降了;就说你降到最后你甚至可以降到0;这个地方;可以到0;就说你神经网络理;论上可以你可以你不管你数据有多大;我都可以帮你记住;那么但是你不是永远的记住;所有的数据;是好的数据里面大量的噪音;你记住数据可能没什么用;所以呢你会发现你的泛化误差;就是我们真正关心的误差;是随着一开始我会随着往下降;但是降到某一个点之后;他开始缓慢的往上升;这是因为你的模型过于的去关注细节;导致你真的来一个新的数据;你被一些无关的细节所困扰住了;所以呢你的泛化误差;其实是有一个比较大的一个gap;那么你会你会发现一个什么样的问题;是说;就是说你最优的点会在这个地方;就是你的泛号误差在往上升的时候;然后你在这里的话;你那就是过拟合;;这里的话就是过拟合;它中间这个gap;我们通常用来衡量这一个模型的;过拟合;和过拟合;的;一个一个区;一个程度;所以是说我们最右在这个情况;是在这个地方;当然是说;这是这一类模型;你可以通过不同的模型;你的核心;
你是要把这个我们的核心任务;第一个是说;其实我们的核心任务;是要这个点往下拉对吧;第二个任务是说;我们要尽量把中间这一块把它;不要弄特别大;所以你会发现;有时候我为了把这个模型;把我的泛化误差往下降;我不得不承受一一定程度的过拟合;这个也是深度学习所要的;就过拟合本质上不是一个很坏的事情;就说如果你的;就说你首先你的;模型容量得够;然后我们再去控制它的;容量这个是我们整个深度学习最核心的一个进度;
就是说你的模型先足够大;不大呢根本就没什么前途;对吧在足够大的情况下;我通过各种手段来控制你的模型容量;使得我最后能到得到泛化;误差的往下降;这是我们整个深度学习的一个核心;

4、估计模型容量
其实我们模型容量是可以估计的;就说但是呢;我们比较难以比较;在不同种类算法之间的模型容量;比如说;我们的树模型;一些随机森林和神经网络之间;这两种模型特别不一样;所以不好直接比较;但是说我给定一个模型的种类;一般来说我们可以认为;
有两个主要的因素;一个是说你参数的个数;就说你可以学习的参数的个数;就是说你看到我们这个线性模型;假设我们是有第一个数据的话;那么会有d+1个可以学习的;就一那个是那个偏移;所以呢;线性模型的参数的个数是d加1;如果我做了一个单层的隐藏层的话;假设隐藏层是m的话;那么我是d+1乘m加上m加一乘k;假设k是我的最后的分类的类别数;那么当然可以看到;只要m也很大的话;那么单层的单隐藏层的;感知机肯定是要大于;我的线性模型的;就说你可以简单通过;我的模型的参数的个数;来判断;两个模型是不是哪一个比哪一个;容量要高;
就第二个是参数值的选择范围;就说假设我一个参数;可以选择在一个很大的区域里面;选择值的话;那么的模型复杂度会比较高;假设我的这个参数;只能在一个很小的范围里面选值的话;那么的模型容量可认为是比较低的;OK所以就是说两个核心的东西;参数的个数;参数值的选择范围;我们今后会不断的看到这两个;我们怎么通过去调整这两个属性;来控制我们模型的复杂度;

5、VC维
上理我们是有一些理论的;我们有简单的提到过统计学习理论;就是统计学习理论的一个核心思想;叫做VC维叫VC dimension;就是两个大脑的首字母的缩写;第一个是瓦普里克;就是说对一个分类模型来讲;我们简单介绍一下VC维;但我们还是说;整个课我们不会涉及到太多理论;对一个分类模型来讲;VC维等价于一个最大的数据集的大小;这个数据集呢;不管如何;我们给定它的标号;都存在一个模型;就是存在一个模型说;我们给定这个模型的参数;能对它进行完美的分类;这直观上也很容易对吧;假设我的模型;可以做一个很复杂的数据集;就说比如说我可以有100;给我100张图片;那么每个图片我不管它的标号;怎么变化;不管我的图片里面的值怎么选;我都可以;通过一个模型来对它进行分类;的话;那么其实它的模型角度;比一个;我只能对一个10张图片的数据集;不管怎么标号都能分类;当然来得快;或者是说你可认为是;我的模型复杂度的复杂度等在于;我能够完美的记住一个数据集;这个数据集最大的有多大;我们可以举几个简单的例子;就是说二维输入的感知机;回忆一下;感感知机;就是两个;二维的数;就是输入的特征是2;然后你的输出是一;它的VC为等于3;就是它可以任意分类两个点;就二位数是平面上点;可以看到;就假设全正;两个正一个负;两两个-1个正;你不管怎么样三个点;不管你怎么做标号;或者你的点怎么移动位置;我都可以画一根线把你圈出来;但是你不能做异或;异或就是在这里;我们有讲过;昨天有讲过;异或就说你一根线就不够了;一根平面线是不够的;你必须要一根曲线;所以就是说;二维的感知机;它的VC维是3;而不是4;所以对于4;这个异或;异或是一个4个点的时候;的一个具体的一个样例;它不能做分类;我们可以泛化到一点来说;支持n维输入的感知机的VC维是n+1;一些多层感知机的VC维是呃;n乘于log n;就是你可以认为就是;那就是比你的线性的要多一个;


6、VC维的用处
叫VC维的好处是说;它提供了一些理论的依据;说;我们就知道一个模型是好还是坏;特别是说;它其实衡量的;就是;你训练误差和泛化误差之间那个间隔;但是呢我们也提过;就统计学习理论;我们在深度学习中很少用;因为我们还没有把VC维这一块;能够很好地应用到深度学习上;因为它对它的衡量不是很准确;它就是一个一个low bound;另外一个是;深度学习模型的VC维算起来特别难;对些很简单的感知机;就是假设;激活函数比较简单;所有东西都比较简单情况下;我们能算;但是对于绝大部分常用的模型;我们其实算不出来的;所以就是说;就是有一个这样子的东西;大家以后遇到了知道是什么概念;

7、数据复杂度
这个是说数据的复杂度;就我们讲了模型复杂度;数据复杂度那更不好衡量了;就说只有一些直观上的一些理解;就数据复杂度;有多个比较重要的因素;
第一个是你样本的个数;你样本很少;100个样本和我100万个样本;当然就不一样了;
第二个是说每个样本的元素个数;我觉得这个二维的向量;还是一个比较大的图片;图片到底是一个很小图片呢;我们用的是2828;现在在整个测试里面但是image net是更大的;它应该是256256;至少是这样子;所以它image net它的图片会大很多;
第三个是说;我这个图片里面是不是有一些复杂的;时间的空间的结构;空间就是说图片等于空间结构;时间结构就是比如说股票预测了;当然有个时间的结构;还有很多数据是有时空都有的;比如说视频对吧;有时间轴;有空间轴;
另外一个是说;我这个数据的多样性有多大;就我这个类别;比如说我是做一个10类的分类;还是100类的分类;还是1,000类的分类;就是多样性;所以这一些都是一些比较重要的;数据的复杂度;大家去衡量一个数据的时候;可以通过这几块去大概衡量;但更重要的是说;这都是一个相对概念;比如说;你大概要通过不断的去对真实数据;去做一些训练;然后下一次碰到一个数据的时候;我大概有个直观的理解;说跟我之前遇到的那个数据集;复杂一点还是简单一点;这样子我能够选择合适的模型的;容量的模型去进行拟合;所以就是说;这个东西很多是一个直观的感觉;但是通过;大家要不断的对大量的数据做一些;调参;大家会得到一些直观上的感感受;但是现在我们目前阶段只能这样子;

8、总结
最后我们总结一;下;模型容量;需要匹配我们的数据复杂度;就你不匹配的话;容会导致欠拟合和过拟合;统计学习提供了一些数学工具;还有衡量模型的很复杂度;在实际中;我们其实主要是观察;我们的训练误差和验证误差的;之间的区别;来做一些实际上的一些;感觉

三、D2L注意点代码
后续再看
四、QA
第一个问题是说;感觉SVM从理论上来讲应该对分类;总体效果不错;和神经网络比缺点在哪里?
;SVM的它的一个缺点其实是;首先;SVM它是通过一个 核函数 来匹配我的;模型复杂度的;假设你是用了SVM的话;它其实算起来不容易;就是说SVM很难做到100万个数据集;但是对于多层感知机的话;我们通过随机梯度下降;很容易做到100万;1,000万就是说;就是说SVM当你数据不大的话;几万个点;几千个点;几万个点或10万个点都是可以做的;而且是比较容易解的;但是大的话;就挺难的;这就是SVM的一个主要的缺点;嗯;
另外一块就是SVM的缺点在;于是说他能调的东西不多;就是;反正就是一个很平滑的一个东西;就是说你可以调一些东西啦;比如说 “” 的那个;宽度;或者不同的“” ;但是实际上调来调去;大家觉得好像也没有太多效果;这也是他的;就说呃可调性不是很行;或者说或者反过来讲吧;就是说大家想了解它的缺点;或者;
你可以了解神经网络的优点是什么;神经网络的主要的优点对;我从我这里;这是一个很大的一个观点;我觉得神经网络比别的领域的优点在;于是说它是一个语言;就是说神经网络本身是一种语言;你通过它的语言来;那么也有一些语句;比如说不同的layer;它就是我的里面的一些小工具;然后不同的连起来;我可以写for loop;我可以把它一句一句写出来;就是说神经网络;通过神经网络这种语言;我们对它进行编程;来描述我们对整个物体整个世界;或者整个我们要解决问题的一种理解;这个里面很玄学;就是说它不是一个;不像编程语言一样的;真的就是;我一行一行写下来;很有逻辑性;就是说神经网络;其实是一个比较不那么直观的;但是呢他编程性特别好的一种框架;我可以做很灵活的编程;反正自动求导;把梯度求出来就行了;
所以你相对于说别的机器学习的模型;SVM也好它有很好的数学解释;但是它的可编程性会差很多;就SVM能解决的问题;它会比神经网络会少很多;但是如果纯从分类角度来讲;SVM确实问题不大;除了你scale不上去之外;就是说SVM做image net就很难很难;但神经网络;它确实可以做到很大的数据集;
另外一块我们会讲到;就是说神经网络会通过卷积;去做比较好的特征的提取;就说SVM你可以把它简单的看取;说SVM需要做特征的抽取;和SVM本身是个分类器;在神经网络;其实是说特征的提取和分类;它其实放在一起做了;就一起通过神经网络进行表达;可以做真正的原始数据集上的;一些and to and的一些训练;就我们不展开太多;我们慢慢的会给大家介绍;更复杂的神经网络;大家也会理解;他跟别的机器学习的算法;是什么样的区别;
就第二个问题;其实说我们除了权重衰退;dropout还能不能介绍BN;我们会介绍;BN是Bachelor azation;我们肯定会介绍;模型剪枝;我们distillation;模型剪枝和distillation;其实它你可认为它不是让你做;它其实不是真的给你做;规约就不是让你模型机动;介绍;只是说让你得到一个比较小的模型的;部署起来好一点;我们不会特别的讲部署;但是也许大家感兴趣的话;大家可以留言;
就说训练误差是training的;在training data set上的error;就泛化误差是在testing data set;这是没错的;但是你这个testing一定要解决;说我们经常说test data set;其实是一个validation;data set;就所谓的validation;我们是可以通过它;来去调我们的超参数;但是testing就是说;一定是用完一次就没了;就是我们打比赛;打比赛有一个;有一个;private的leader;leader board就是说大家不会公布成绩;到最后的最后大家一次性公布;然后就定了排行榜;这个是testing the asset或;者是说我训练一个模型;把它真正的部署到实际生产中;看明天的结果怎么样;这个是testing the asset;
所以;严格意义上说;泛化误差;是说在于未来;还没有;现在不在手上的ITA set上的泛化误差;
就是说我说训练;测试验证;三个数据集的划分的比例标准是什么?;如果是比赛的话;不知道测试数据集的分布;怎么设计验证集和验证数据集;有什么指导原则吗?
我们会有一个比赛;就是我们;可能在下周就来;就是我们;这个比赛我可以提前说一下;其其实是一个比较好玩的东西;是说;我给大家去预测我们的房价的卖的;房价的价格;然后呢;我是把2020年的房的湾区还是加州;我都忘了;应该是整个加州的房子给下了下来;然后呢在训练集;其实是应该是1月份到5月份的房子;验证集的;我们的测试集;应该是5月份以后的房子;然后呢我们一个公开的;公开出来的验证集;其实你可认为它就是一个;validation的site;就验证集了;就是应该是6月份到10月份;但是私有的数据集;也就是真正的测试集是后面的;就他确实会有一个分布;就说这里面涉及到一个事情;是说你的测试数据集;很有可能;跟你的验证数据的分布是不一样的;假设我是用过去的数据来训练模型;去预测明天的数据集的话;很有可能这个世界会发生变化;这是一个非常大的一个问题;我们这里没有特别去讲这个问题;会怎么样;这个叫Coverance shift;就说整个分布会发生变化;我们这里;很多时候;你就假设数据是一个独立;同分布的情况下;你的验证数据集;通常来说;就是够大就行了;就没有特别多的区别;比如说经常来说我有一些数据集;我可以选择30%作为测试数据;70%作为训练数据;在70%的数据集上做一个5折交叉验证;就说每一次就拿20%作为验证数据集;然后做5次;这是最常用的办法;
或者是说如果你数据够多的话;那么你可以砍一半;一半作为测试数据;一半作为训练数据;在训练数据上;我还是做k者交叉验证;或者是说;你说对于image net这种做法的是说;我说我有1,000类;我有1,000类;平均每一个类应该是;5,000张样本;还是多少张样本我不记得了;就他的验证数;他的测试数据级或者验证数据级;他的做法是说;对每个类我随机挑50张图片出来;然后这样子的话;那就是;最后得到一个5万的;一个1,000类的话;那就是一个5万大小的;一个验证数据集;剩下数据机全部做为测试;这也是另外一种做法;
问题六;不是用training set和testing set来看overfitting;underfitting吗?
我们等会儿会看一下;给大家演示一下;就是说你其实不应该还是不能;应该叫test set;应该叫validation set;就是说你是用validation来看一下overfitting;
就是说另外一个问题是说;如果持续上;对于持续上的数据集;如果有自相关性;怎么办好?
这是一个挺有意思的问题;就是说你你做股票的时候;你的验证集就持续序列的话;你要保证的是说;你的测试集一定是在去年级之后的;你不能在中间做;那是不行了;就是我要做股票预测;我不能说;我把过去一个月的数据拿出来;然后把中间随机采样一些点来;总结一些天来作为我的验证集;那肯定是不行的;你唯一能干的事情是说;过去一个月的数据;股票数据作为训练集;然后比如说;把中间切一块;就是前一个星期的作为验证集;这个星期以前的作为训练集;这是一般的持续序列的做法;
另外一个是说;验证数据集和训练数据集的数据清理;比如说异常处理;特征构造;是不是要放一起处理?
你应该是要看你怎么样吧;就两种就是说;最简单是说我要做标准化;标准化就是说;把这一数据减去它的均值;除以它的方差;就是你这个均值和方差怎么算;你有两种算法;
一种算法是说;我确实把训练集和测试集;所有的集都拿过来;放在一起;算均值和算方差;这个也问题不大;不大的是说;因为你没有看到标号;你只看到了一些的一些它的值;这很有可能在实际生产中是OK的;
另外一种做法是说;我确实是只在训练集上做;算精算均值;算误差;然后把这个均值和方差作用到我;的验证数据集去;就是说一般来说你后者会保险一点;实际情况下你可以做;你可以看;就是当然前前前面一种会好一点点;就说他对;分布的变化会更加鲁棒一点;所以实际情况;我觉得你应该去看你的实际的应用;假设你在你实际;你要训一个模型去部署的话;你看看你是不是能拿到验证数据;以上的数据;你标号我假设你拿不到;就是你看看能拿不到;能不能;能不能拿到这些验证数据的数据;如果你能拿到;你就可以做;统一做处理;如果你拿不到;那你只能用训练数据集;嗯;
第九个问题是说;深度学习一般训练集比较大;所以k者交叉验证是不是没什么用;训练成本太高?
这个对是是是这样子;就是说;k者交叉验证因为要做k次嘛;就是训练起来比较难;所以在在比较大的数据上;我们很少用;所以我我的前提是说;你做k者交叉验证;是说一定是你的数据集不够;就不够大的情况下你可以做;但是在于传统机器学习;我们一般是做的;
深度学习确实做的不多;因为比较比较贵;
就为什么cross validation会好呢;其实也没有解决数据来源的问题?
而cross validation只是给你选择;超超参数的;它不能解决别的问题;就是数据来源;当然你怎么采样数据;使得它的分布比较好;不要跟去年级和验证集;两个数据长得非常不一样;或者说你怎么采用比较好数据当;然不是cross validation干的事情;这个是整个这一块;是data science要去怎么样去弄数据;就一个data scientist;80%的时间都在都是在搞数据;我们也许也许可以讲一讲;怎么去排排数据;怎么样选择东西;但这里面其实挺挺大挺大一块;就是说可以理解是说;
一共有训练数据及验证数据集;和测试数据集;三种数据集嘛它?
就看你怎么理解;就是说所谓的三种数据集;是说我数据集;其实一个就是理论上说;比如说我做图片分类;我的所有的图片;我所有的图片在一起;比如说1万张;那就是我一个数据集;我会把数据集做分开;不同的数据做不同的事情
k是怎么确定;k最重要的一个;k的确定?
是说你在你的能承受的计算成本里面;你k越大;其实k越大效果越好了;但是你k越大的话;你的计算成本也是线性的增加;所以;你选一个你觉得还能承受的训练的;;代价就行了;
第13;是说模型的参数和超参数不一样吗?
不一样的;模型的参数是讲;w和b里面的那些元素的值;我们整个模型训练量给解决;解决了问题;超参数就是hyperpermeter;是讲你这个模型;我是选用;我是不是选线性模型;还是选我的多层感知机;如果是多层感知机的话;我是选多少层;每层有多大;我训练时候我的学习率选多少;所有那些选择别的就模型;就是说模型参数以外的所;有东西可以我们可以来选的;都是超参数;
cosvalidation;每一块训练时;获得的最终模型参数可能是不同的;;应该选哪个模型?
就其实你cosvalidation的话;你最后报告的是你的平均的进度;但它每一块告诉你的答案不一样;就是你取个平均;这个在统计上是有很多意义的;就大数定理吧;
问题 16是说;所以是出现了overfitting或者under fitting;才需要have a perimeter的training吧?
就是不是training;它其实不是这个意思;就是说;就说所谓的调参;就是要调一个比较好的参数;使得泛化进度比较好;这什么是不好的参数呢;overfitting不好的;underfitting也不好的;所以是说overfitting;underfitting是大概会告诉你说;哪个参数比较好;就是说你调总是要调的;就是说你一般你调一调;就是说;但是你不out;两次你其实你也无法看到;我们等会儿可以直接给大家讲一下;underfitting overfitting到底长什么样子;就是说不是说你出现了才会调;是说这个东西告诉你说;什么样的是好的;什么样是不好的;是这个意思;
如何有效的设计超;超参数是不是只能搜索;最好的搜索是贝叶斯还是网格;还是随机;有没有推荐?
这个是一个挺好的问题;;这个是一大块;就是automail里面有一个大块叫做;hypergrammet tuning叫HPO;我们;这这一块;我们这一堂课;这一节课没有去讲;我也许可以给大家补充一下这一块的;如果大家感兴趣的话;
就是说对面两件事情;一个是说你怎么设计超参数;就是说你到底要我要选;比如说我要10个里面选一个好的;那么这个10个长什么样子;我们昨天有讲过;我们MLP怎么设计;怎么宽一点窄一点;大概多少大;就这个是设计;第二个是说我给你10种;或者一般来;我说我可以给你是一几百;或者上千种做组合;我可以告诉你说;我的学习力可以在0.10.010.001三种选择;那么呢我的;我的MLP我可以一层两层3层三种选项;没乘的话;我可以说;3264128 然后最后你的你是一个乘的;就是说你是3乘以3乘以3;一直乘下去;你一个指数级的爆炸;就是你很有可能设计出一个;超限数的空间有100万种可能;那么说接下来一个问题是说;你不可能把每一个都遍历一次;而你能遍历一次就没问题了;你不能遍历的话;你怎么办;所有的网格就是所有的遍历一次;
随机的话;就是我不能遍历;那我随机的采样做一些东西;或还有可能是做一个在上面;在训练一个模型;我的我的;个人推荐;一个超参数的设计;靠靠专家;的就靠自己的经验;就我们会说;给定一个数据集;我觉得哪样子的模型会比较好;哪样子的超参数比较好;这一般是靠自己来设定;最好不要设太大;也不要太小;太大搜不出来;太小;你有可能错过了很多好的选择;所以这一块目前来看;没有特别好的选项;只有可能自己来设计;我们今后可能会做的好一点;第二个是说;如果怎么样选最好的;搜索有两种做法;一种是;我们昨天说过的;就是自己调吧;就自己试一个;看一看精度;然后再试下一个;然后根据我的上一个;一个是当前的结果;来判断下一个往哪边走;就有点;这老中医;或者是说;另外一个是说;大家我建议就用随机吧;如果你自己不想调的话;就随机随机的意思是说;每一次我随机的选取一个组合;去年一次;看一下;我的验证精度;然后随机个100次;然后最把最好的那一个超参数选出来;就行了这就随机;我推荐用随机;贝叶斯你也可以做;但贝叶斯的话;你得肯定是你得去年个100次;1,000次 1万次;贝叶斯的方法才会好一点;这一块其实很大的;一个一个领域;就HPO;大家可以有兴趣;大家可以再给我讲一讲;我们也许可以做一个专题;来给大家解释一下;
问题18假设我做一个off分类的问题;实际情况是1:9的比例;我的训练集的两个;我的训练集的两种类型;比例应该是1:1还是1:9?
就是说我理解你的意思是说你有个两;份的问题;一类是就是假设你有10个样本;一类是有9个样本;一类是一个样本就是非常不平衡;那你怎么做呢;;我觉得你的验证数据集肯定要保证;是其实都没关系;就是说no;看你多少数据了;假设你数据很多的话;你就是就随便了;就随机;就随便砍一刀都可以;假设你的数据集不那么大的话;那么我的建议是;你的验证数据集上最好是;两类都有差不多样数的多;嗯;原因是说;假设你是;;不然的话;你做的不好的话;那很容易是说;我就是;那我如果是因为这个对分类器来讲;我很容易是;我就怕你所有东西都给正类;假设正类是多的那一类;那我就所有的分类序;不管谁我都给你判正类;那我的精度是90%;那你可能就是从数值上来说哎;我这个我这个模型器90%精度挺好的;所以那么你对于那个小的那一类;你就会忽略掉很多事情;所以你把验证级;你把验证数据集把它平衡一下;那么你至少是50%的精度;对吧在验证数据集上;也也可以避免;是说;你的模型太偏好于多的那一类;你有很多种办法;你可以通过加权重来避免这个事情
问题19是个很好的问题;就是说;k者交叉验证的目的是确定超参数吗;而且用这个超参数再训练一次模;全数据吗
这个问题挺好的;就是说你有两种做法;一种做法是说我的k者交叉验证的;只有n种做法了;第一种是;怎么做呢;第一种;就是你说的那一种k者交叉验证;就是来确定一个超参数;确定好之后;我在整个数据集上;再全部重新训练一次;这个是;几乎是你最常见的一个做法;
第二个做法是说;我不再重新训练了;我就把k者叫他验证中的那一个;选定那个K3 选;选定好的那个超参数里面找出;随便找一个一折里面的那个模型;或者是说找出那个进度最好的那一折;我们的模型拿出来;那你的代价当然是说;你的训练的模型训练可以少一点点;要你的少看了一些训练集;
第三种还有种做法是怎么做呢;就是;你要是把k者交叉验证的k个模型;全部拿下来;然后真的做预测的时候;你把一个测试数据集;全部放到这个k歌模型;每一个都预测一次;然后把它的预测结果去均值;这个其实是一个不错的选择;但是他的代价是说你你的预测的时候;你的代价是变成k倍了;你之前你再过一遍;但现在你要过k遍;但是你的好处是说;这样子能增加你的一些模型的稳定性;因为你做了一个voting;
问题20:validation出现的误差是什么?
误差就是validation误差了;就是验证误差;
问题21为什么SVM打败了多层感知机;后来深度学习又打败了SVM呢;;
简单来讲就是说;它简单来讲它不是打败;是流行就是说你会;你会发现整个学术界;它其实是一个你可以认为是;一个时尚界大家都是赶时髦;然后SVM打败了多层感知机;是两个原因;一个原因它确实比较简单;但它比SVM的精度;并没有比多层感知机要好;但它不那么要调参;这是它的第一个好点;第二个是SVN;他有数学理论;有人推;就是大家就火了;然后深度学习又打败了SVM;就是深度学习打败了SVM;是那就是深度学说我没理论;没理论不要紧;我实实际效果很好;我在image net上拿第一了;我们会之后会讲;这个这个故事;就是说SVM你你;其实在之前image net的冠军都是用SVM的;然后深度学习说;Alex net出来把SVM进度高了很多;那就是实用性更好;另外一块就大家说;也不要太纠结这个事情;这个这个学术界嘛;就是一波又一波的;今天我们深度学习火;火了几年了吧;我们再讲深度学习;可能三年之后;五年之后说不定就不火了;
所有的验证数据上的loss;都是这种先下降后上升的吗?
所以这个这个是;我知道这个东西一定会很很很误解;就是说我们有讲过那一条线;就说验证数据集上的那个验证误差;是往下我给大家讲一下这个东西;我觉得挺挺容易;我讲的时候;我会觉得是;可能会大家会有一点点误解;就这个东西;这个东西首先;x轴是模型理解吗;;就这个东;西是一个模型;就每一个点是一个新的模型;不同的模型;这个比如说是MLP;呃这个比如说是一个MLP1;就是一个最简单的那个MLP;这个可能是一个很深很深的MLP了;这是一个简单MLP;所以我们网上的图;我们的记事本的图;这个图不一样;我们记事本的x;是我的数据的迭代次数;我是一个模型;就是我是一个;我们的网上图是这样子的;我是x是epoch;我数就是讲一个;我们的误差是一个这样子的;这是说我这个模;一个模型在通过不断的学习过程中;我会发现它的误差往下降;这一个点是表示;我给你换个线;这个点;最终这个点会对应到一个这样子的点;我还可以画一个别的;一个这样子的模型;对吧画一个点对到这个地方;就是每一个点是不同的;模型所以你就是;所以就是说你不同的模型;它会有不同的区别;是比较模型用的;它不是一个模型的;训练的那个进度的误差;OK;
模型的容量一般指的是什么?
模型容量就是;就是模型能够拟合函数的能力了;
随机森林在深度学习有常见的用吗?
深度学习有一些做随机森森林的东西;但是它不属于深度学习;我们一般来说特指神经网络这一块;确实是有把神;随机森林做到神经网络里面;但是它的最大的bug是说;随机森林的训练;它不是通过梯度下降的;所以你不好做joint training;所以我们用的也有用;就是说一般来说常见的应用是做enzomb;我给一个数据;我给一个数据;我训练一个随机森林的模型;我再训练一个别的模型;我再训练一个深度学习模型;n个模型;最后做;做average来投票;这是常见的做法;但是把随机森林结合进深度学习;做的比较少;主要是;你那个梯度不好传;
做KK则交叉验证的时候会训练k次;这样子;k次训练出来模型能不能融合在一起;会不会比单个模型有更好的表达能力?
有的;就是我们刚刚有讲过;就是说你有k个;然后做去做测试的时候;我进k个里面;就是5个里面进5个模型;然后把所有的预测的结果做平均;这样子;我的结果可能很有可能会好一点;;还有更更更奇葩的做法是说这个;其实Google他们经常干的事情;为了打比赛;我同样一个模型;然后记记不记得我们是我们;这个模型是有我们的权重的;初始是随机权重的;那我就把这个模型训练5遍;就每一次;用不同的随机值来初始化模型;就得到5个模型;最后做enzombo;就是做average;也效果也挺好的;
标号是什么;标注标号的标注是一个叫label;我经常我中文;其实我也不是那么清楚;反正我也经常混着用;标号标注;label哈哈;就是一个东西;
拥有无限维的算法是什么?
;无限维的算法多了去了;嗯;无限维;其实正常的深度学习的模型都是;都有可能;是无限维的;就是说;你如果不做;就说不做;它的限制不做;比如泛化呀;不做;正则化呀;不做;那些东西很有可能就是无限维的;
k者交叉验出;训训练出来k个模型;最后选择物;验证误差最小的模型嘛?
你也可以这么做吧;就是说我们有提过;你可以选择误差最小的;或者是说;你在整个数据上重新训练一遍;或者每个都做好都可以;
就VC衡量的好坏;没有听懂?
;这个东西我们不特别展开了;就说VC为;就尽量的简单认为是;说我一个模型;我能记住的最大的数据集长什么样子;就是说我给你一个 100;比如说100个样本数据集;每个数据集的样本是;1,000枚的话;那么假设我能记住这个数据集;而且不管你数据集怎么怎么怎么;里面的结果是什么样子;不管是怎么样子;我都能记住它;那么就VC维等于;正好是大于等于100吧;就是说;你就是说你判断一个模型的;capacity的大小的;就是说我能记住多复杂的数据几;就一个人的记忆能力的好坏;我能记住;比如说我记;举个不那么确信的例;确定的例子;就判断一个人的记忆力的好坏;那就解解释;你能记住;比如说圆周率能记100位还是记10位;假设你记100位;那你的VC咱们剩是100;假设你能记10位的话;只能记10万;那就是10;那么当然;记100的记忆力比你记10的好一点;或者是说你记单词你最多能记多少个;记1万个;那么你就with dimension one;那比只能记100个人的话;你的记忆当然会好一点;就可以简单这么理解;OK;我们在这里;我觉得这个就是一个概念上的东西;我们确实;多花点时间搞清楚是没问题的;还有那么多;
嗯k者交叉验证;是第一次放完后就确定分组了吗;如果每一次都随机打烂数据;取出k n分机做验证是另外一种方式;嗯有没有区别;还是说一般来说差不多呢?
就是说一般来说;我们是;做k者的话;一般就是给一个样本;随机打乱一次就把它切好;就不会下次不再切了;你可以说;你可以随机;你下一次可以随机打乱;打乱这个叫backing;它其实跟k者;驾校认证是有一点不一样的地方;就是你可以随意打乱;这个没关系;其实你做back in就是了;做back in的;大家一般做back in的这种做法是说;我就是为了真的;最后就是为了得到k个模型;这样子我做;平均预测;这是大家常见的一种做法;
就说神经网络是一种语言;它是利用神经网络对万事万物见为;就是它理论能力和所有的函数;其实我还不仅仅是讲这个东西;我其实讲的;嗯;我其实是说;理论上来说;你的单层;单隐藏层的MLP能拟合所有的函数;理论上它能拟合所有;不需要我们就基本上昨天就讲完了;理论上;实际上不是的;实际上你你训练不出来;就是说;就是说我觉得就是说;等于是说;我觉得我能做到这个事情;我觉得我;但是我就是实际上我就做不到;成绩做不到;对吧;所以说所有的神经网络;最后的最后;你去cn也好;RN也好什么东西都也好;他其实说我知道MLP能理和你;但是MMLP基本上训练不出来;那我要做一个比较好的结构;使得尽量帮助你来训练;比如说cn尽量的说帮助是你网络好OK;cn它本质上就是一个MLP;本质上没区别;我都给大家讲它是做了一些限制;就把一些等于是一些wait给你;固定住了;就是说我通过设计cn告诉你设计网络;说我觉得这个数据有空间信息;这样子呢;我来告诉你说;你去这样子去去处理这个空间信息;叫RNN也是一样的;我觉得这个数据叫持续信息;我告诉你说;这个东西这么走这么走;这么走来来做这个持续的信息;就是说;整个东西;就是说整个深度神经网络;就是说我是通过神经网络;尽量的去用它的秒的方法;来去描述这个;这个数据的特效;使得你训练起来更好;训练一些;就是你可以;那么是这个意思;就是说所谓的就是说;总结来讲;就是说我通过审计网络;来来描述我对这个问题的理解;但很多时候你就是试一下;很多时候;其实说白了就是你拍拍脑袋;拍5个脑袋;试一下;有发现一个想法不错;然后把它写出;来然后在上面再随便找个理由;但是真正的好的就是;你会发现很多这样子的经典的论文;他他确实效果很好;但是他一开始找的理由都是错的;就是说;所以说嗯;所以神经网络很多时候;扯远一点就是;
就是说;剪枝和蒸馏是可以提高模型性能吧?
;是;就是看你怎么说吧;比如说真正的destination;就是把一个复杂的一个网络;把它变小;使得他的能力跟复杂的网络经量一样;但你看你怎么说;就是说它比对你这个小模型;它比同样另外一个小模型;直接训练出来的小模型可能会效果好;是是提升精度;但很要对你对复杂;对你那个大的开始的复杂模型来说;你的小模型可能精度还会低一点;所以是说;你看你从哪个角度来讲是性能提升;;
就同样模型的结构;同样的训练集;为什么只是随机初始化不一样;最后的集成一定会很好?
所以因为就是说这里;这里要涉及到另外一个概念;一个很大的概念;一个叫统计学;一个叫做优化;就是说我的模型是一个统计学的模型;我的优化是一个数值优化;所以你最后的模型是统计模型;就是模型的定义;加上你怎么优化的结果;就假设模型一样;还就统计模型是一样的情况下;通过随机初始化不一样;最后得到的结果不一样;就是我随机出;就优化就是;反正我就是从一个随机点开始;往前走一走;走一走然后呢;你这个平面够复杂的话;就说你在一个很复杂的山里面;我把你随机丢在一些地方;你每次随机走一走;可能走的地方都不一样;对吧;但是说;所以你你这样子不一样的话;最后的集成都一定会好;不;就一般来说统计上来说会好一点;就是说你每个模型都有一定的;就说你模型都是个;就模型都是个偏的;就模型都是个假的;就模型都不能拟合真实的世界;就说模型都是有一个偏移;偏移是固定的;但他有个方差;就方差是我每次优化或者什么样之后;有一点噪音在里面;我通过做n个模型;把它做放在一起做;做均值我能降低这个方差;这样;你这个方差很有可能会提升你的精度;就他最后没有把模型的偏移给做掉;就是模型他就是不是那么好;就还是不是那么好;但是说每一次训练;因为我都没有拿到这个模型的最好解;就是一个随机减速;所以我做n次的话;我能够降低一些一些呃方差;
问题33数据集中的噪音比例多少;最好还是清清楚所有噪音;这个东西;你数据集的噪音;你当然希望越少越好;只是说我们现在是;我们现在是做人工数据集;就给你加一点噪音;所以当然是清除;实际数据来说能清除噪音最好;我们只是说给一点;我们现在是给点人工数据集;给大家演示一下;所以加一点噪音;如果训练是不平衡的话;是否先考虑测试机也是不平衡的;再是否决定使用一个平衡的验证机;;对;就是说但是你的我觉得正常情况;就是说;你可以不平衡;但是你应该让通过加权来使得它平衡;就是说假设我有两类;还是前面那个例子;假设一类有90%;相反一类就是10%;那么你要去看;你要去想的一个事情是说;一;我是不是真实的世界中;我就是90%的是这样子;10%是那样子;如果是的话;那么你就是应该把主流的做好;对吧把那90%的做好;10%的话尽量做好;所以如果是这样子的话;是没关系;反过来讲;如果你现在这个情况;只是因为你采样没采样好;就是说你觉得那个10%其实挺重要的;只是说你这个数据几;你没有把它那个东西都拿过来;这样子情况下;你就是应该把那个10%;那个小的那一个东西的权重提升;最简单说;你把那个10%的样本全部复制10遍;那就变成1:1了吧;复制9遍吧;变成1:1了吧;就说你你;你不复制的话;你可以通过在lost里面加权;使得他给他更大的权重;小的类给更大的权重;问题35;在训练的时候XOR是迭代次数;在验证数据级上;也会发生这种先下降后上升的;那不是错误;那就是过;敏核;那就是你;你的验证数据级会下降;再上升那就是发生过拟合
No.3 权重衰退
一、权重衰退
1、权重衰退
权重衰退哈;这个叫做weight decay;是我们最常见的来处理;过拟合的一种方法;就说我们在上一;
2、使用均方范数作为硬性限制
而我怎么控制一个模型的容量呢;一个是说我把模型变得比较小;就是里面参数比较少;第二个是说;我使的每个参数;选择的值的范围比较小;权重衰退就是通过;这一个控制你整个值的选择范围;来进行的;具体来说我们是一个这样子的过程;我拿去比;就是说我们还是之前一样的;我们优化的是我们最小化的损失函数;就是l是我们的损失;假设w b是我们的参数的话;w是你的权重;b是你的偏移;但是呢我们在最小化这个的时候;我们加入一个限制;就subject to;使得你这个w就是你的权重;它的l to long是小于一个θ;就小于一个值;就就是说使得你整个w的平方;每个项的平方和;是小于一个特定的值的;那么就意味着说;你的w的每一个元素的值都要小于;θ;开根号;如果θ选的很小;那当然我的值就比较小了;这就是一个;我强行说我的每个值的不能太大;这里的话我们通常不会限制偏移b;就是说;因为b对于我们来讲;其实统计上来讲;你这个偏移;你是对你整个数据在零点的偏移;所以你是不应该限制的;在实际上来讲;其实你限不限制都是一样的;就是大家可以试一下吧;把b也加进去;或者不加进去;可能对;大家的实际结果不会产生太大影响;所以数学上来讲;我们一般是不会将b放进;我们的限制里面;这里一个可以看到是说;你比较小的θ;就意味着我的正则向会比较强;就是我的对你这个值的限制会比较强;最强的情况就是θ等于0;那怎么样所有的w都等于0;那只能选一个偏移;如果一般来说我们会比较选一个;比如说;θ等于一呀;或者0.1呀;0.01呀;这样子的话;使得我们整个;如果你是选择1的话;那么你w里面每一个值;都不应该会超过一;而且随着你的w;如果里面元素很多的话;那么你每个元素;你也就相对来说会变得更小一点;OK;这个就是说我们做人应该硬性限制;我们说硬性;就是我们强行说;你的w一定是小于这个值的;但一般来说;我们不会直接用这一个优化函数;因为它的优化起来相对来说;麻烦一点;我们其实常用的是一个;这样的一个函数;


3、使用均方范数作为柔性限制
对于每一个θ;就是之前我们选定的每一个θ;比如说θ等于0.1呀;一呀 0.01呀都可以;对于每一个这样子的值;我们都可以找到一个number;就是另外一个值;使得它之前的目标函数;等价于下面一个目标函数;就说我把那个限制项目挪掉;但是呢我在整个目标函数里面;加入了二分之number;然后w对一个l two弄就是;然后这一个可以证明;就是说;你可以通过拉格朗日程子来证明;所以就是说他跟我这个就是优化;整个这两项;跟我们之前加那个限制是一样的;我们之所以讲之前的硬性限制;就给大家直观的来理解说;我这个θ;是确实是把w限制在一个值里面了;但实际上来说;我们通常用的是如下这个形式;就是说这是我原始的损失函数;现在我加了一项新的项;这项叫做惩罚罚;通常来做叫做penalty;就是说使得你这个w不会特别大;而且Lambda是一个超参数;Lambda控制了整个正则项的重要程度;就假设number等于0的时候;它当然是没有作用了;就说整个这一项是等于0的;就等价于之前θ;它等于无穷大;当你number渐渐的趋向无穷大的时候;就等价于之前的那个θ趋向0;使得你的最优解w星也会慢慢的变成0;所以就是说;假设我想把模型复杂度控制的比较低;我想让模型不要太复杂的话;我可以通过增加number来满足我的需求;OK这个就是我们的;所以这一块;这个叫做柔性限制;之前呢叫硬性限制;这是因为;这是一个;number不再是一个硬性的时候;你所有的值都给我小于某个值;而是一个更平滑一点的;就是有点像;你比如说Photoshop拉曲线那种感觉;OK;所以给大家演示一下;这个具体是怎么样;


4、演示对最优解的影响
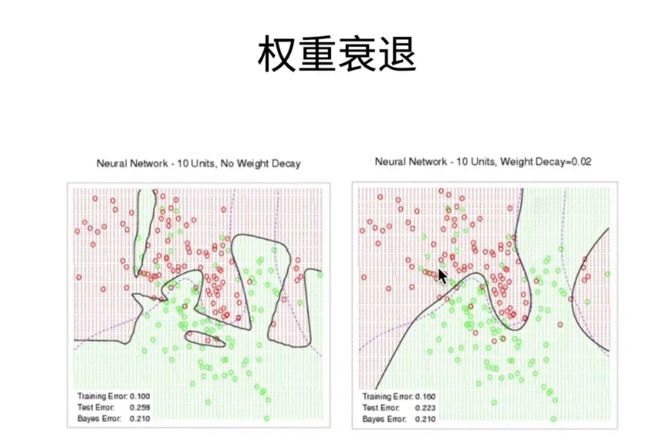
我们看一下;就是说;首先我们假设我们有一个l在这里;假设这个绿线呢;就是一个l;那这个绿线画的是你这个l的等高线;假设我就是想优化;这这个损失l的话;那么呢我的最优点在这个地方;这是我的最优点就是w的波浪号性;因为你l是一个;我假设其这也就是个二次函数了;假设你二次函数长这样子的话;那么它的正中心就是这是最小值;那么就是我的只优化我的损失的情况;那如果我加入了一个2分之number;这个项呢;这个也是一个二次函数;所以在这个这个函数里面;我们其实就是一个w就两个值吧;就是X1和一个X2的话;那么对一个w的二次项的话;你可以认为它其实是;一个在以圆点为中心的一个等高线;长成这样子;那么写首先我们看一下;就是说原始的这个最优解这个点;这个点现在就不会是特别优了;因为这个点对于我的损失项来说;也就是这个黄线来说;它的值非常大;而且我如果沿着这个方向走;如果我沿着这个方向走的话;那么我的l的值会变得大一点;但是我的伐的项值会变小;而且大家记不记得;我们在损失函数的l;to的损失函数讲过;就l to的损失函数;就是你那个平方损失函数的话;在优化点附近的时候;它对于我换一下;干脆就说;假设这是我的l two的一个损失;我在原点附近的时候;我对我的值的拉伸是比较小的;因为它的梯度相对来说比较小;但是我对于;在我的离原点比较远的时候;我的值是很大的;我对我整个往下拉的作用会越大;所以呢;所以在这个点的话;我的阀对这个点的拉动力;会比我这个l会大;所意味着是说我会将它往下拉;举个例子就是;我们可能会拉到这个地方;这个地方就是说形成一个平衡点;如果你往下面再往下面走一点点呢;那你的l就会说;这个你那边减少了项;不足以弥补我的增加项;你往这边走的话;那么因为一样的;我是我的阀的增加项;比你的l的损失项要大;所以在这个点形成一个平衡点;总体上来看;你可以看到是说我的这个阀的引入;使得我的自由节往原点走了;那么对于我的值来上;我的最优解值的话;我这两个点我这个点对呢最优值的话;他的值会变得小一些;就我的绝对值会变小;一旦我绝对值变小的话;如果我都是;把我的赘肉节往这边拉的话;那么对整个模型来讲;我的模型复杂度就变低了;这就是说;如何理解我们加入这个阀;就在这个柔性限制里面;它对我整个损失是怎么影响的

5、参数更新法则
接下来我们来看一下;它的参数更新的法则;就是说就为什么它是叫做一个;撬过了一下;它为什么叫做一个;权重衰退呢;我们可以看一下这个的原因;就我们回忆一下;我们之前是怎么算梯度的;就现在我们有两个项;就我有个l一个项和我的阀;在这个两个项里面我算;我对他算梯度的话;我首先是对我第一个l项算梯度对吧;是这一项;接下来对它算替补的话;因为它是一个二次函数嘛;所以就首先这个平方向没了;然后它只剩一个w在里面;然后2和这个2和这个2抵消;所以就变成了一个number加乘以w;那我们理解是在时间t的更新;我这可以写一下;就是WT加上一;就应该等于WT减去你的学习率;at乘以我的这个这个w项;那么呢;我接下来就把我这个象带进来就行了;带进来你可以看到;首先这一个象就是我们保留住;还是在留在这里;就是a塔乘以这个象;留在这个地方;那么接下来就是说;a它乘以它乘以number;和w就会;这里我再补一下;这是一个t在这个地方;那么就会;我们就把它和第一个这个项;合并在一起;那么它就变成一个一减去a;它乘以number;那么可以看到是说;跟之前不一样的地方在哪里;跟之前唯一的不一样的地方;就是多了一个这样子的像;我不要把它呢画在减号那里;就是大家会显得模糊一点;就这就是维度的像;如果你没有加入二次法像的话;这这个地方是没有的;通常来说;我们的lambda乘以我们的学习率;是小于一的;如果大于当然会那个会抖动比较大;一般来说是会小于;所以你可以看到是说跟之前的区别;减去梯度的负方向;乘以学习率是没有变化的;那么主要的变化在这个地方;这个地方每一次我们对它更新的时候;我先把wt乘以了一个小于一的;一个正常数;那就是把它值先变小了一点点;再在梯度的;沿着梯度的反方向再走一点点;对吧所以呢;为什么这个叫做权重衰退;就是每一次更新的时候;因为number的引入;使得我们在更新前;我们先把当前的权重做了一次放小;所以就是认为这是有一次衰退了;所以这就是;我们的为什么叫做权重衰退;

6、总结
我们总结一下;权重衰退;通过l two的政策下;使得模型参数不会过大;从而控制模型的复杂度;我们可以通过一个刚性的写法;使得知道说我们限制w;two的像比永总是比一个cta要小;但是我们在真正的优化的时候;我们是通过一个number来控制它的;强度而且这个number;因为等价于我们在更新的时候;每一次对权重做了一次放小;所以它就等价于说;它是一个权重的衰退过程;在这个地方;我们的Lambda是我;们控制模型复杂度的一个超参数;;

二、D2L代码注意点
三、QA
第一个问题是说;现在pyTORCH是不是支持复数;神经网络;也就是它的;都是复数;LOFT是一个复数到实数的映射?
这个我觉得应该是不支持的;复数我觉得应该是不支持;但是你复数的话;因为复数说白了就是两个;就是两个;把一个数变成两维嘛;你其实可以通过;把它做到两维;就加一个第二维来实现你要的效果;就是你必须一定要搞到复数;
第二个问题是说;如果;为什么参参数不大复杂度就低呢?
它其实不是说参数不大复杂度就低;就是说;我限制你整个模型在优化的时候;只在一个很小的范围里面去去参数;就说如果你在比较小的范围去参数;那么你的整个模型就不会;你的空间就会变小;举一个最简单例子;其实我们有一个画了一个很小的图;但我没有解释的一个图;就是这个图就这个图;那用笔;就是说如果你我要你和这些点的话;这些红色点的话;如果我可以允许我的模型;参数选的比较大;我可以做一个任何的;一个很复杂的一个曲线;使得他你和;就说在模型同样是二次模型;或者三次模型情况下;假设我的权重可以取得很大很小的话;那么;可以造成一个非常不平滑的一个曲线;那么现在是说;我限制你这个weight不能换太大;就是说;你只能在一些比较平滑的曲线里面选;我不让你学;我不让你去学;特别大的一些曲线;那么就意味着是说你的模型;复杂度就变低;就说你选不出特别复杂的模型;如果只要你选择比较简单的模型;是这个意思;
如果是用L1范数的话;如何更新权重?
如果是L1的话;其实你一样的更新;就是说;大家可以试一下;这个是一个很好的练习题;就是说;你就你就把那个之前那个呃;就是;这个地方;你就把它换成一个呃;换成一个touch ABS吧;对吧;然后就换了个东西;然后然后这个就不要除二了;那就当然你这个东西得改成l one penalty;对吧;就大家可以试一下这个;改一下这个东西;一定大家去试;你不要看到我试看;我试有什么用哎;你自己去试一下;看看效果怎么样;很有可能效果差不多;在这个在这个问题上;但是我绝对鼓励大家去;手动试;我只是给大家演示一下就正常怎么做;这里面代码是什么意思;但是说给大家看代码的主要的目的是;大家可以拿去自己玩;
对实际中的权重衰退一般取多少呢?
;其实一般取个一般是取;一;一般是取1 -3 1 -4;就是说;1 -2 1 -3 1 -4就0.010.0010.0001;就是那么几个选项;
之前在跑代码的时候;感觉权重衰退效果并那么好?
;其实群众衰退效果有一点点;但你不要太失望;我们会在之后再介绍更多的手段;给大家来做;模型复杂度控制;权重衰退;确实他就那么一点点效果;所以很有可能你稍微调一下体;一般来说你取个1;-3也就行了;就是你不要觉得;如果就是说如果你的模型真的很复杂;权重衰退它不;会给你带来特别特别好的效果;可能你;特别是对于什么MLP来讲;可能之后我们接下来我们要讲的;drop part可能效果还好一点;所以就是说大家;我就建议大家可以试1-21-3;或者说你就默认开着1-3也就行了;如果效果不好;你就换别的方法;
就是为什么损失函数正则项中的2;为什么使用的是上标而不是下标?
;就是说我在想;你所谓的上标;是讲我这个是怎么写的是吧就是说;就我其实就是说;你说我为什么用的这个地方;这个是个上标是吧;这个上标不是;这个上标是是个平方的意思;就说;其实理论上这里应该有一个下标;我就是偷懒没写了;就这才是l;l too long;就是表示你这是个l to的一个范数;但是呢l two是以默认的范数;所以对项链来讲;l two就是默认的;所以你这里不写是没关系的;就是我只是把它忽略掉了而已;这个平方呢;这个东西不是讲是l two的;项链是是个平方项;就是说我们这里用的是l to;就是l r的那个范数的平方;作为我的发;所以这个2是平方;不是l;to那个里面那个2;OK;
就为什么会要把w往小拉;如果最优解的w就是比较大的数;那么权重衰退是不是;有反作用?
这也是个挺好的问题;就是说;就我还是回到之前那个图;就是说大家一定要理解这个点;是说假设;假设我的;假设这是我的最优解;真的是我真正的最优解;就是说但是你实际上来说;你的数据是有噪音的;就实际上就是说实际你学的时候;你不会学到这个点;你学不到这个点;就这是你的假设;你是你真正最优点;但是你在学真的去学数据;学的时候;因为你没有噪音;所以你的;你学的东西;可能在这个地方可能学的特别大;就你可以看到我们之前那个代码;我们真正的最优解是0.01W;但我们如果不加l two的话;我们学到的是一个特别大的一个;我们的l two long大概是1112啦;那就是根本就学到一个过大了;那是因为;我们的算法看到的是造影;他试图去他;只要模型允许的话;我就会去不断的记住我的选一个;选一个权重;记住我所有的样本;那就是说;那就会尝试记住我的造影;记住那些抖动的东西;他就会学到一个特别大的地方;这就是你真正的学到的;如果没有的是学到的;然后呢;所以你的l初衷就会把这个东西;你如果没有它的往往回拉;就你要通过控制你这个number的大小;来控制number大小来说;你要往回拉多少;就是说假设你number过小;那么你可能就拉到这个地方;你拉到这个地方不够;还是太大了;就number太小;但是如果你number;太大的话;你有可能拉到这个地方;对吧number太大;所以这个地方是说你合适的那么大;可以把你拉到这个地方;所以就是说这里我们写的是最优解;数学的最优解;实际求解;我们求不到最优解的;因为你数学有噪音;所以是说number;就是说处理你的噪音;假设你没有噪音的话;那你就不需要number;你根你就不会;就不会去;overfit到一些奇怪的地方;但是因为实际有噪音;所以这个就是它的原原因;对就;
第七个问题;其实跟之前一样;就是说它是让w值变得更平均?
它其实也不是;它不会让你变得平均;就是往小里拉;就是说防止就当你没有number;你的学的的w是变得很大的情况下;加入这个东西;你就会往回拉;就它不也不是万能的;假设你没有;你的模型;没有去overfit的话;你那你老往回拉是没用;就为了DEK;一般有什么选择;就是反正之前讲过;就是你;1-3吧 1-2吧;1-4吧反正是这么三个选项;选选有效果就行;没效果换一个;换换别的方法;反正那个东西;试起来挺简单的;
就是说作为number达作为一个超参数;是怎么样;调优的那其实是说;就我们也讲过;上一次有讲过;就是说你用;验证集加上;比如说key者加查验证;就是说你去看;就是说;确实你你不知道什么时候是最有;比如说最简单的情况;你就是假设number等于0;你试一下;最最后的验证的精度长长什么样;或者你看一下我们之前那个曲线;我们之前那个代码;也多多少少有点调参的异味在里面;就你看一下你那个训练的线;和一个;测试获得验证者的那个嵌之间的差距;如果你发现那个差的比较大;那么你就把number的0的;如果说你发现差的比较大;那就把它往高调一点点;就调个1-3吧;一-3如果你确定有一定效果;你又渴了;你可以再往上调一点;调个一负2;如果没有效果;那就那就这样吧;那你就留在一-3没事;或者你就觉得一负3有一定效果;你不调了也没关系;就是说;那么呢反过来讲;就是说不会有特别特别大的用;但是呢;会有有那么一点点好处;
就说在解释噪音数据的时候;如果噪音越大;w就会比较大;这是经验所得还是可以证明;噪音越大的时候;你的你;这个可以试一下;这个是可以证明的;这个东西确实是可以证明的;但是我们这里就不讲;你可以试一下嘛;你就就很简单;就是你就是拿这个demo跑一下;你就把噪音调高一点;看看你学的w会不会变大嘛;对吧;;
No.4 丢弃法
一、丢弃法
1、丢弃法
我们接下来讲;另一个非常重要的一个概念;是叫丢弃法;也叫drop out;这个也是;我们在这次深度学习崛起中间;最早提出的一个算法;他可能会比我们之前的;群众衰退效果更好;然后这个图呢;就是这个图是呃;你的high school graduation的drop out rate;就是退学率

2、动机
就它的动机是这样子的;就是说你一个好的模型;需要对你的输入数据的扰动;鲁棒;就假设你看我这个图;这星球大战里面那个盔甲就是说;我不管我的图面加入多少噪音;就加到最大的时候我也能看清;对吧人是没关系的;你花一点虎一点我也是能看清楚的;那么呢;使用有噪音的数据;它等价于一个正则项;叫做不知道怎么念;就T正则吧;就是说正则就跟我们讲过;我们讲讲的要吐正;正则正则就是一个;使得你的权重不要特别大;是个避免过拟合的一个方法;就是正则;你可以都可以认为是一个叫penalty;或者叫regularization;就是说使得你不要权重的;指的范围不要太大;使得它可以避免一定的过拟合;所以在数据里面加入噪音;等价于一个正则;那跟之前我们加的噪音不一样;之前是固定噪音;这个是随机噪音;就不断的随机加噪音;那丢弃法呢;就是说我不在输入加噪音;我在层之间加入噪音;这就丢弃法;所以这里面有的隐含;一个选项是说丢弃法其实是一个正则;

3、无偏差的加入噪音
我们来看一下;就是说;假设x是我们的一个;一个到下一层;就是一层到下一层之间的一个输入;的话;我们希望对于我们这个x加入噪音;得到x撇;然后呢我希望是说;虽然虽然我家的噪音;但不要改变我的期望;就说平均上来上我这个值还是对的;这个;所以这个就是我的唯一的要求;那么丢弃法就是做一个非常;简单的事情;就说X一撇等于什么呢;我给定一个概率p;在p的概率里面;我把x我把输入就x i;就是你真实的原始数变成0;在剩下的地方我把你除以一减p;这说白了就把你变大一点;因为p是一个0-1的东西嘛;所以这个地方就一;就一定概率把你变成0;一定概率把你变大;那它的期望是不变的;为什么呢;我可以稍微写一下;就是说;X一撇的期望;II就是你的这个di个元素啦;因为你的x是一个项量;所以它等于是;首先它第一个是0;这个0 那等于是p乘以0;再加上一减p;就是它的概率乘以它的值;就是X i除以一减p;那么这很简单了;就是这里消掉;这里消掉;那么它就会等于XI;所以就是说XI一撇;它的期望没有发生变化;就是跟之前是一样的;所以这就是说;核心是为什么我们要出个一减p;的这个地方;这就是呃jump out的定义简单吧

4、使用丢弃法
我们来看一下丢弃法用在什么地方;就是说它其实就是说;回忆一下我们之前是怎么讲的;我们假设我们有第一层;第一个隐藏层;就是我们的输入乘以我们的权重w e;加上我们的偏移b e;然后呢拿到我们的;加入我们的激活函数;拿到我们的HH;就是我们第一个隐藏层的输出;然后呢;对第一个隐藏层我们作用drop out;就说白了就是把w把h;中间就每一个元素;每一个元素作用drop out;就作用之前;我们来个函数;使得在p的概率变成0P的概率变成;它除以一减p就变大;然后呢;第二层假设我们是单引行层;单引长层;第二层那就是之前我们是h是吧;之前我们直接来4个h;现在我们就H1撇;H1撇乘以w two;就是我的权重加上我的B2;那就是说;然后当Softmax作为输出嘛;就可以看到是说我的后面一层;他拿到的输入是我们前面一层的;把一些元素变成0;把另外一些就scale掉的一个结果;但你可以从图上来看;这个是原始的情况下;我们要写5个隐藏层;那么你用了drop part;很有可能会变成这样子;很有可能就是说这两个被换成0了;就没了;那就是说他下一层呢;看到就是说我们把中心一些权重都去;掉了下一层;那么就是;这个当这三个元素会会做一些;变大了就说这个;就说你当你下一次跑的时候;可能会变化;就是你再下一次的话;因为是一个随机嘛;下一次我有可能是把那把这两个去掉;或者三个去掉;把这两个保留下来;有可能对吧;下一次我可能是全部保留;或者全部去掉;这就是丢弃法;

5、推理中的丢弃法
训练是这样子的;推理呢就是在inference的过程中;在预测的过程中;我不训练的话;我是不使用drop out的;就是说我的;这是因为dropout是一个正则项;正则项只在训练中使用;就不管我们之前的L2的正则;还是现在正则;只在训练的时候使用;因为它只会对你的权重产生影响;当你在预测的时候;我们权重不需要发生变化的情况下;我们是不需要正则的;所以就是说我在推理中;我是不需用drop out;那就意味着说在推理的时候;我的drop out输出的是我的本身;就不会在他做任何变领;或者那个scale的操作了;这就是能保证我们有一个;确定性的输出;这是推理中的job part;当然反过来讲;我们这里就是教job part的时候;就是教它是一个正则项;最早job part出来的时候;

6、总结
总结一下;drop out就丢弃法;丢弃法将一些输出项;特别是隐藏层的输出项随机变成0;来控制模型的复杂度;它常作用在多层感知机的隐藏层的输出上;就是对于那个全链接层的隐藏层;输出上它很少用;在比如说之后我们的CNN;之类的模型的上面;我们会解释;所以丢弃的概率;是控制模型复杂度的超参数;就丢弃概率假设是一的话;那么全部丢掉;那么w就是等于0了;丢弃值等于0的话就不丢;那就是不会做任何控制;所以丢弃;一般来说p一般是丢弃率;一般取0.5或者0.9或者0.1;这三个是最常见的一个丢弃概;所以这个也是一个控制模型复杂度;一个超参数;而且它的;很有可能效果会比我们之前的L2的no要好一点点;OK;这就是;我们的丢弃法;;

二、D2L代码注意点
三、QA
、
第一个问题就是drop out;随机置0;对求梯度和反向梯度的影响是什么?
如果你被随机置0;那么你的梯度也会变成0;所以就是说;但是你没有支点的地方;你会乘了一个数对吧;梯度也会在相应的乘乘一个数;就说drop part;你可以认为这个函数对于求梯度;其实是差一个对称的一个函数;而且所以就意味着说等;就是你drop part的那一些;输出它对应的那些权重;它就这一轮就不会被更新;
丢弃法的丢弃依据是什么;如果丢弃不合理;对输出的结果会影响很大?
你可以简单认为它就是一个正则项;就跟我们之前的是一样的;就是说你丢;所谓的丢弃不合理;就是说你那个丢弃率没设好;要要么太小了;太小了就是说你对模型的;那个正则效果不好;不不大;不够所以你还是over feeling;就还是过拟合;就要么就太大了;那就是欠拟合;对吧就是合适比较好;所以就是一个超参数;就是你可以调;
问题13 drop out的随机丢弃;如何保证结果的正确性和可重复性?
哎这个是个正确性和可重复性;是两个问题;所谓的正确性;这没有正确;这是机器学习没有正确性;机器学效果好不好;哪有正确不正确;比如说;所以机器学习;特别是神经网络;因为他那个网络很复杂;稳呃用随机梯度下降;他的稳定性很好;所以;所以说假设你代码有bug;很有可能你是看不出来的;很有可能你你代码写错了一个;可能是个很大的bug;就是你的精度;可能会丢那么一个点;零点几个点;或一个点;所以;所以就是说你不知道结果的;你就算你代码没写错;或者就怕了怎么样;你也不知道结果是不是正确;所以没有没有;没有正确性可言;就说只有说;精度好不好;可以但;我是说从实际上来说;统计上来说就不一样了;但是统计这东西;你在实际上也验证不了;所以呢;所以你可能唯一注意的是可重复性;所谓的可重复性;就是说你下一次运行的时候;因为dropper的每次随机丢丢值嘛;你下次做的时候;你下次跑的时候;你结果就不一样了;所以这个是一个整个神经网络的;可重复性;一直就是一个非常难的事情;但job part还好一点;就job part它的bug不是那么明显;是说你只要固定你的随机种子;所谓的随机种子;大家可以去试一下;我固定住那个随机种子的话;我每一次我run 10次;就说我我就我那个函数就drop out;我就把那个random seat固定住;就是random的那个函数的;random seat固定住的话;那么我drop out 10次;然后我再重复的run 10次;结果是应该是一样的;所以就是说;如果你真的想重复性的话;你可以把你的随机总是固定住;就是说;你可以保证下一次应该是差不多了;当然了;但是你整个神经网络的随机性;也挺大的;你的权重的初始是随机的;对吧;如果你真的要做可重复的训练的话;你的随机种子得重复著;然后你的job part里面是要重复著;应该;这是两大主要的随机数的来源;第三大数就是你很难控制的;就是假设你用的是CODA的话;media的cool DN这个library就是;它是用来加速你整个矩阵运算的;你不用cool DN的话;基本上所有的主流函数;主流firework都是用了cool DN;但你可以禁掉它;就只要用了;用cool DN;会给你带来比如说50%或者80%的加速;你不用cool DN的话;你会慢一些;就GPU的话;但是cool DN它每次算的;矩算乘法算出来结果是不一样的;这个是涉及到一个;计算机体系结构的问题;就是说你把;n个数相加;加的顺序不一样;结果会不一样;理解吗就是因为你的精度不够;所以就是说你在codn;它就是尽量的要尽量好的做并行;一旦做并行的话;加的一些数相加的顺序不一样;导致的结果不一样;所以codn出来的结果随机性挺大的;几乎不能重复;所以如果你想可重复的话;要禁掉QDN;然后drop out和random seat的叫random;就是权重初随机;初始化那个seat;要将这个种子要固定住;应该就你可以可重复了;但反过来讲;你也没必要可重复;就是说最后的最后;就是说你只要保证我训练个100个100轮;或者多少一个EPOK之后;我的精度差不多在按那个范围就行了;就是说;这就是通常来说大家的做法;而且我们虽然有随机性;随机性它不是个坏事情;随机性让你更稳定;就是随机;它就是你可以认为随机这个事情;就是把你整个东西变得很平滑;就说你一旦随机性一高;你的稳定性也会增加;比如说你呀;你要这么想;我整个神经网络;我都能在你给我把所有东西都给我;里面东西全部置0;各种CG的情况下;我还能收留;我还能到这个地方;下次我也行;
就是这个问题;是说;丢弃法是在训练中把神经元丢弃后;训练在预测中神经元没有丢弃?
是的;就是说丢弃法只是在训练的时候;随机把一些隐藏层的;或者说或者说你把随机神经元;在这一轮不参加计算而不参加;更新但是在预测的时候;是大家一起的;
丢弃法;是每次迭代一次随机丢一次吗?
是的就每;就是说它是每一个层;在调用那个前项运算的时候;就随机丢一次;又会如果你有三个隐藏层;那你用了三个;Jopart layer的话;那么它会那就有要扩三次了;就是说;所以我觉得应该是;你所谓的每次迭代一次;就是一个batch;你要重新丢一次;
请问在用BN的时候;会有必要用job part吗?
我们还没讲BN;BN是之后我们接下来要讲的;也是一个;beyond有一点点;有一点点政策的意思在里面了;但是;beyond是作用在卷积神卷基层上的;就BN是给卷基层用的;dropod是给全链接层用的;不一样;所以dropod和BN没有太多相关性;所以我们现在还没讲CNR;所以我们也没讲BN;所以dropout;你可以认为它就是在全链接层用的;不会在剪卷基层我们是不会用dropod;
dropout会不会让训练loss的曲线;方差变大;不够平缓?
其实dropout会让曲线变得;看你怎么说;有可能是你就说有可能是不够平滑;你我觉得我大概理解你的意思;就是说看你怎么画这个曲线了;我们这个曲线画是;我们这个曲线画的是每一次;每一次;每一个数据扫完之后我算一个平均;它其实很平化的;但是你真正的做硬算的话;你扫一遍数据那么贵;所以你可能就每每算个10个bash;我就画一;下10个bash画一下;它就可能会让你的;如果你这么画的话;你会发现;整个曲线抖动很大;其实你不care;抖动大就抖动大呗;谁care所以;你不要担心曲线;它有可能让你曲线不平滑;有可能但我没有真正的去看过;但是我们不care这个事情;就是说曲线平不平滑;对最后的;就是说一开始平;就一开始不平滑;最后都得平滑;如果你最后不公平的话;就比较信你;收敛很麻烦;
问题18他叫推理的drop out;是直接返回输入吗?
为什么;这个对这个是drop out最大的一个;经常大家容易误解的地方就是;在做预测的时候;假设你预所谓的预测;就是不对我的权重做更新的时候;dropout是不用了;就不用dropout;为什么是因为dropout是一个正则项;正则项唯一的作用;是让你在更新你的权重的时候;让你的模型复杂度变低一点点;当你在做推理的时候;你不会更新你的模型复杂度;而不会更新你的模型;所以你是不需要drop out的;你可以用drop out也可以;但是可能对你;如果你用了job part;那就有随机性;所以;你要避免你随机预测的时候出问题;那你肯定得多算;多算几次;就我给一个样本过来;假设我开了;我在推理可以开;drop out你可以开;就是说;反正推理就是说对权重更新没影响嘛;但是你可以开cat;代价是说你因为你开了它;所以导致你预测的时候;我给你一;只猫的图片;第一次预测成猫;第二次预测成狗;对吧因为交付丢掉东西了嘛;就所以说你可能要得多算几次推理;做一下平均;才能使得把这个方差给降下来;但训练没问题;训练为什么没问题;因为训练我要跑很多很多次drop out;我就不断在跑drop out;我可能跑个;我们在这个地方就是;每一次我都跑了;对吧我跑个几十万次呢;所以在几十万次的随机的丢在里面;对整个系统的稳定性是没问题的;但是在推理的时候;如果就关心某一个样板他的结果的话;你可能做平均;就是在我们部署的时候;你拿张图片过来;我给你出了一个坏结果;怎么办对吧;我尽量不要出坏结果;但但是你如果反过来讲;如果你就是关心一个;在一个测试级上的;一个精度的话;可能开drop out不会给你带来很多影响;你可以试一下;很简单吧;你就把前面那个函数;把那个if圈里等于一;使用交叉的把它删掉不就行了吗;注掉不就注视掉就行了
drop out;函数返回值的表达是没有被丢弃的;输入值会因为分母的一减p而改变;而训练数的标签还是原来的值?
是的是的;就是说就抓怕的;就是说你要么就把那个输出变成0;不然的话要除一个一减p;这是为了保证我的就随;因为随机性;保证我的期望就我的;均值还是不会变的;但是标签还是原来的值;对标签我不改变;我们为job part唯;一改变的是我的job;我的隐藏层的那个输出;你可以改标签;改标签是别的算法;就是说你可以;你可以改标签;改标签也是一种正则化;我们我们这个客户一定会讲;就你可以改标签嘛;就你把;这改标签还是一个正常;挺常用的一个正传话;我在想有;说不定我可以给大家讲一讲;就是我可能会在最后讲CV的时候;给大家大概提一下;还真有就是说我可以把标签也改了;也是一个随机嘛;就是说我们之所以只讲drop out;就是它是最早最早的一个;在神经网络中间引入随机;向来做正则化的一个东西;但实际上在之后;在之后你大家发现drop out吗;我drop out隐藏成书;我什么都可以drop out;我可以drop out wait;我可以drop out我的;我我可以把我的输入给变上联;我可以把我的label变上联;就都可以;都可以没关系的比如说;最后在过去的;
是就是说训练时使用drop out;推理时不用;会不会导致推理输出结果翻倍了;比如说drop part等于0.5;推理的是输出式训练;是两个神技元叠加翻倍?
所以大家记得我们除了个一减p对吧;就是说假设你在训练的时候;你drop part等于0.5;就是说我把一半的神技元就成0;剩下的我要除以0.5;就乘了2;所以你输出和输入;就是说在训练时;你的方差是不会发生变化的;所以这就是为什么要除一个一减p;为什么我给大家算一下;说期望没有发生变化;就是说导致说你的;就是要避免你的输出的结果;是训练的时候f翻倍的结果;OK;
Drop out每次随机选几个子网络;最后做平均的做法;是不是类似于随机森林;多角色速度投票的思想?
是的就最早最早;Hinton就Hinton;大家应该知道;Hinton老爷子就是神经网络的;奠基人之一吧;就是最大的山头;他们做Drop out的时候确实就是这么说的;就说我Drop out的干嘛;我就是每次在训练的时候;随机踩了一个子网络训练一下;然后那我做预测的时候我也可以做;预测的时候我也可以说;那就是预测的时候我也可以用;Drop out嘛;就是做n下嘛;就是每一次;比如说预测的时候我就重复5次;然后每次踩一个姿网络做一下预测;然后做平均;就你可以这么说;就是说但是实际上像我没什么用;就是说实际上你就是说;你当然可以这么说了;但是;实际上大家发现他更像一个正则;像如果有兴趣;我就可以把那个那几有几篇paper;就是说去讲你Drop out是一个;你可以去;so Drop out is a regularization;就是这个;这个title应该就长这个样子;
请问丢弃的是前一层还是后一层》?
是怎么说呢;它就是都一样;就是说;你可认为它丢弃前一层的输出;和丢弃后一层的输入是一个东西;对吧本质的嘛;就他;或者你可以认为drop out它其实是一层;就是一个层;输入是一个东西;输出就丢掉一个东西了;dropout的和权重衰退都属于正则;为什么dropout的效果更好;而现在更常用呢;呃其实dropout没有权重衰退常用呢;就是权重衰退其实是说大家都在用;就是说一般都会用开权重衰退;这drop part主要是对于全连接层使用;那权重衰退这个东西;权重衰退对于卷基层;对于之后的transformer都可以用;就是说;大家是统一用;drop out为什么效果更好;drop out其实我觉得就是更好调参一点;就权重short这个number呀;这不是很好调;drop out好调一点;drop out很直观嘛;就我丢多少;我;丢一半就捉炮子;就三个值;0.50.10.9 就三个值;丢一半就表示就是说;就是说;你你可以这么简单这么觉得;我假设去年一个单隐藏城的全链接;MLP然后这个隐藏城大小是64;我劝了一下觉得还行;就说不用job part问题不大;觉得没那么过离合;那么接下来你可怎么办呢;接下来你就把它变成128;开job part等于0.5;对吧就等效;你感觉上等效就等于是;反正一半的丢掉了;就等效于是我的隐藏层被;减半嘛但很有可能128开job part的;等0.5 效果比你直接是64要好;就还是养深度学;就说我可以过礼盒;但是我通过别的来让你训练的时候;不要就我需要让模型够强我;然后通过我的正则来使得你不要学偏;就是说你跟小孩一样的;就是说我;我想你智商高一点没问题吧;你性格差一点不要紧;我我们想办法来;或者说你说大家;就一个人吧;你就说一个人的能力是你的;魔性复杂度;一个人的性格是你的;或者说;性格这种东西是你的;你容易学歪的一个东西;那么大家是愿意跟性格好的;能力不强的人做事情呢;还是跟性格差的;但是能力很强的人做事情呢;很有可能是性格好的;不性格差一点的;能力强一点的人;然后你尽量去废掉他的性格;对吧那最好的是说你能力有强;性格也好;当然是极少数了;我们也有这样子的模型;嗯但是;MLP不属于那种MLP;属于能力强性格不好的那种;所以现尽量也不要使用MLP;就是说一般大家用的越来越少;所以就为什么我们之后要讲CNN;讲叫Transformer;叫cn你可认为就是一个special的一个;一个特别的一个MLP;所以就是说;我就回答这个问题;我说;我觉得drop out主要是调起来比较方便;就是说你就;如果你就可以调个0.9;如果你觉得这个隐藏层特别大;模型特别复杂;我就搞高一点;搞个0.9就百分90;的丢掉就是强回归;如果是;小一点的话;我取个0.1就随便回归一点点;改标签是一种mask嘛;改标签;就是说我们之后会讲怎么改标签;也是一种常用的技巧;但是;也不是简简单单的就把随机改一下了;不是这样子改的;会有一点别的技术在里面;如果你强行改的话;可能效果不那么好;但有一些别的技巧可以让你更好;在同样的最后一个问题;在同样的我们事件差不多了;在同样的学习率下;dropout的介入会造成参数收敛更慢;需要比dropout情况适大调大linearate嘛;dropout;还有真有可能使得你收敛会变慢;这个是有可能的;因为你等于是说你每次权重就剃度;跟就说你更少的一些在更新梯度嘛;但是我好像没有听说过;说你因为有了job part;能力rate变大;因为从从期望上来讲它们是差不多的;就job part不改变期望;能力rate就学习率;主要是对那个期望会;期望和方差敏感一点点;嗯这我没有听说过;要适当调的;你可以调;但是我没有听说过;有大家说有;经验上总结说就是drop the;那我就把then ret改到两遍;没有听说过这个事情;但我觉得会瘦脸变慢是有可能的;
Transformer可以看作是一种特殊的MLP吗;目前还没有;目前还没有这么看;Transformer可以看作是一个connormation;就是一个合合方法;比如这个是可以;这个是大家可以看的;就是还没有看成是特殊;的一个MLP;;
No.5 数值稳定性+模型初始化和激活函数
一、数值稳定性
1、神经网络的梯度
-
数值的稳定性
-
这个是机器学习里面比较重要的一点;当你的神经网络变得很深的时候;你的数值非常容易不稳定;
-
假设有一个低层的神经网络;层记在t;就t不要搞成时间;之前也用t表示时间;这里表示层;
-
假设我的H(t-1);是第t-1层的隐藏层的输出;然后经过一个ft;得到我们的第t层的输出HT;
-
然后y可以表示成为;就是x进来第一层;一直到第d层最后一个损失函数;就是我们的预测的;我们要进行优化的那个目标函数;
-
但y这里不是预测;y还包括了损失函数;就是之前有讲过梯度怎么算;如果计算损失关于某一个乘Wt的一个梯度的话;先把它一直写开;有链式法则;
-
损失函数;对最后一层的求导,然后最后一层的隐藏层;对于倒数第二层的隐藏层求导;一直一直求;求求求到第一层的输出;第一层的输出;关于第一层的权重的求导;就是依次类积下来;
-
所有的h;都是一些向量;向量关于向量的导数是一个矩阵;所以这里的是一个(d-t)次的矩阵乘法;这里一共有(d-t)次的矩阵;所以我们是对它相乘;所以我们主要问题来自于这个地方;因为我们做了太多的矩阵乘法;

2、数值稳定性的常见两个问题
-
矩阵乘法带来的主要的两个问题是;一个叫做梯度爆炸;一个叫做梯度消失
-
梯度爆炸;假设我的梯度都是一些比1大一点的数;然后对1.5做100次;假如说有100层的话;做100次;就会得到一个4乘以10的17的一个数;当然这个数浮点是能表示的;但是很容易这个数字会带来我们的浮点的上限的一些问题;因为浮点其实是有一个合理的范围的;
-
同样的话;如果我的梯度的值是小于1的话;就算不会太小;就算是0.8;如果是100层的话;那么0.8的100次方;那也是2的-10次方;也是个非常非常小的数了;就表示说;这里基本上就梯度就不见了;

3、例子:MLP
-
MLP;就是一个多层感知机的模型来讲述(d-t)次的矩阵的形式
-
先假设就把那个偏移那个b给省略掉了;
-
这个是第t层的输入H(t-1);也就是t-1层的输出;然后这个函数;就会表示成一个第t层的权重;wt乘以输入H(t-1);然后假设省略掉偏移的话;就直接在输出上做激活函数;叫做Sigma;
-
链式法则进行求导:第t层的输出;关于输入的导数
-
然后求导;就是说首先要对激活函数进行求导;它是一个按元素的一个函数;它的求导其实很简单;因为他是一个对元素;而且是个向量的话;它就变成一个对角矩阵;
-
假设Sigma撇是Sigma的导数;就是这个激活函数的导数的话;那就是把它的输入放进来;它就输入这个向量;它的输出也是一个向量;然后把它做成一个对角矩阵;然后这个地方就是一个Wt;就是t还是说这个小t;小t是有那个层的意思;然后大T是它的转质;
-
然后回忆下前面;前面要对(d-t)次这样子的乘法;就是说要从最后一层开始一直乘乘乘;乘到当前层;如果把它累乘的话;会发现是说;那就是每一次就是一个对角矩阵乘以另外一个矩阵;然后做(d-t)次 这样子的乘法;所以我们知道;就是说;假设我们是一个多层感知机的话;我们会关于t层的导数是这样子的形状。

4、梯度爆炸
-
使用relu;作为激活函数;
-
relu回忆下就是一个Max(0,x);所以它的导数是说如果x大于0;那就是1;不然的话就是0;所以可以看到是说那么这里面;这里面就是一堆1或者0;所以一些1和0的一个对角圆;做成的对角矩阵;跟它相乘的话;那么就意味着说要么就把某一列给留住了;要么就是把它全变成0;
-
那么这个地方意味着是说;因为这个函数里面全是1和0;那么它的最后的值;就这个的值的一些元素;就是来自于;那些没有被变成0的那一些列的乘法;就是来自于你把这个所有的WI;就是第那一个当前层的;第i层的那个权重做导数;然后做乘法;就它的一些元素来自这里;当另外一些元素是0;
-
这里的问题是说如果d-t很大;就是这个网络比较深的话;那么它的值就会比较大;因为里面这里全部是一些w的元素;假设我每一个w的元素;都是大于1的话;而且层数比较大的话;那么这里面就会有非常非常大的值;这就是梯度爆炸;那剃度爆炸有什么问题呢

5、梯度爆炸的问题
-
存储问题
-
我的值可能太大了;如果值超过我的浮点运算的话;就变成了一个Infinity;就是个无穷大;对于16位浮点数尤为严重;
-
现在很多时候用GPU的时候;我们会使用16位浮点数;这样子通常来说;现在media的GPU在16位浮点数;比32位浮点数要快个两倍;所以很多时候我们会采用16位浮点数;16位浮点数的最大的问题是说;它的数值区间其实很低的;它就是一个6e负到6e正4的一个区间;那么就是说;意味着说我这个区间其实很小;如果你超出了我的值的区间;那我就变成了无穷大;所以就会给我带来问题;
-
对学习率敏感问题
-
假设是没有到无穷大;但是还是会有很多问题;最大的一个问题是说;对于学习率非常敏感;就是说如果我们的学习率调的太大;就稍微大一点点;那么就会带来比较大的参数的值;因为我每一步走的比较远;那么我对权重的更新;就会权重会变得比较大;那么权重一大;对应的记得我们那个梯度;就是我们的权重的乘法;那么就会带来更大的梯度;那么更大的梯度;会导致更大的参数值;那就一直一直也带个几回;你就会整个梯度就炸掉了;就变成无穷大了
-
假设学习率太小呢;问题是说你就训练就没有进展了;就说学习率太小;每一次对w的那个增加就比较小;再次导致我整个训练是跑不动了;
-
很有可能是说;需要在训练过程中不断地调整学习率;就是说在一开始;可能整个权重的比较小的时候;可能学习率要稍微大一点点;到后面的话可能学习率的减少;或者甚至你要做很动态的一些调整;根据你的当前的梯度来做;所以这个就是整个这一块就导致说;
-
假设你没要到infinity的话;不是说他真的完全就不能训练;只是说他会给你调学习率这个事情调的比较难调;就是你的大一点点就炸掉了;小一点点就不动;所以在一个很小的一个学习率;只有一个很小的范围是比较好的;这个给你之后的模型训练调参了带来很大的麻烦;这是剃度爆炸的问题;

6、梯度消失
-
梯度如果会消失会怎么样;
-
举一个具体的例子;假设用sigmoid函数作为激活函数;那么它的导数可以算一下;就是这个地方;可以看到是说这个蓝色;是它的那个值的一个函数;就是说它是在0和1之间;
-
它的梯度是黄色这根线;可以看到是说当你这个值很大;就是说你的输入是6的话;它梯度就很小了;基本上是到0了对吧;那就是说当你的对于这个激活函数;当你的输入稍微大一点点的时候;那么它的输它的导数它就会变成0;再来看一下会什么问题

7、梯度消失
-
问题
-
如果这个输入;相对来说稍微大一点的话;那么这个东西就会变成0;那么就意味着说:这里面可能有;它也不是变成0;它就变成很小;那么这意味着说;
-
你可能会有d-t个小数值的乘积;就是说;那么每一个数可能都比较小的话;如果你的输入比较大;那么的梯度就变得很小;那么它的比如说之前讲过;就算是0.8做100次;那也变成2的-10次方;那么你的梯度就很小了;

8、梯度消失的问题
-
梯度值变成0;
-
因为16位浮点数;如果是小于一个;比如说51-4的话;那基本上可以把它当0了;就是就*0.0005的时候;那么你浮点数就基本上把它当0看;
-
如果梯度值变成0;那么不管怎么学;你的学习率都不会有进展;只是学习率不管趋居多多大;因为你的权重就是学习率乘以你的梯度;你的梯度已经是0的话;那么你就训练就不会有进展;(w基本不会变)
-
而且是说对于比较深的网络的时候;对底层的尤为严重;这是因为;当神经网络比较深的时候;记得做梯度翻转的时候;是从顶开始的;那么顶部因为有一些;比如说顶部第一层就是1次之间乘法;那么你的梯度可能是正常的;
-
越到下面那么你就一直乘乘乘;那么你的梯度会变得特别小;可能就是0;那么底部那些层;就是靠数据进的那些层;如果你的梯度是0的话;那你不管怎么样做学习率;你都不会有进展;那么这个意味着什么问题;意味着是说;不管把神经网络加的多深;底部那些层你跑不动;你就把顶部那些层训练好;那就意味着说;你跟一个很浅的神经网络;是没有本质区别的;这就是提速消失的问题

9、总结
-
====
-
当数值太大或者太小的时候;都会导致数值问题;这个常发生在深度神经网络里面;因为有很多层;你的梯度其实就是对n个层做累乘;
-
如果你的权重稍微大一点点;或者你的前向的输出稍微大一点点;那么就会导致梯度会炸掉;
-
如果你的那个值比较小;或者你激活函数;使得你的值变得比较小;那就变成n个很小的数做乘法;那就导致很小;
-
就是说这个是我们常见的两类问题;就是说我们要既要避免;我们的梯度不要太大;我们也要避免我们的梯度不能太小;

二、模型初始化和激活函数
1、让训练更稳定
-
一个核心问题是说;如何让训练更加稳定;就是梯度不要太大也不要太小;
-
乘法变加法
-
让训练更加稳定;目标是让我的梯度值在合理的范围里;可以说我尽量使梯度;在1-6到1-3这个区间里面;那么几个常见的方法是:
-
让乘法变加法;不管是在CNN里面使用的最多的现在Resnet;还是在RNN里面使用的最多的LSTM。
-
Resnet核心是说当你很多层的时候;那么会加入一些加法;就是说一些加法在里面;如果你很多层从乘法变成有加入加法进去;
-
LSTM也是一个持续的;如果你的持续序列很长的话;如果你的持续序列是100的话;就说输入一个长了100的一个句子;那么原始的持续神经网络;它就是对这个每一个持续做乘法;如果你太长就不行了;LSTM就是说把它这些乘法也变成加法;这样子的话;不管是Resnet还是LSTM;它都把100次的乘法变成100次加法;加法当然出问题的概率就很小了;所以这个是一个核心的思想;乘法变加法;
-
归一化和梯度剪裁
-
另外一个核心思想是说;把梯度变成一个比如均值为0;方差为1的一个数;所以不管有多大;都把你拉回来;
-
说梯度剪裁;就是clipping;就是说如果你的梯度大于5了;大于5我就把它变成5;如果你小于-5的话;我把你变成负;就是强行把你的梯度;减在一个范围里面;
-
本节笔记重点
-
第三个其实是今天要讲的;前面两个在之后会不断的去提及;如何做合理的权重的初始化;和使用合理的激活函数;我们看到;这两个对于我们的梯度;是有很大影响的;

2、让每层的方差是一个常数
-
====
-
其中一个想法是说;让每一层的输出和梯度;都可以看成是一个随机变量;假设一层输出100维的话;那么就是说;把它看成100个随机变量;如果让他那个随机变量;他的均值和方差;都能一直保持一致的话;那我就是会比较好;
-
举个例子就是说;第一层假设输出的话;如果把它当成一个均值为0;方差为1的一个随机变量;那就是整个值的区域就比较好;那么第二层;第二层;那就跟第一层保持一致;那一样的是一个均值为0;方差为1;如果不管有多深;都说最后一层和第一层都差不多;都是一个;均值为是为0;方差为某个特定值的话;那么不管加多深;都没有什么太多问题;我希望的话;我的输出和我的梯度;都在这个值区间里面;那就会比较好了;
-
如果数学上来讲;假设ht是t层的输出的话;i是我的第i个元素;所以它就是一个标量;我把它当做随机变量;所以我们正向的话;那就是说我的输出;那我们的期望为0;就均值为0;方差我们假设是a;就是一个常数;就不管你是对哪一样的t;对所有的i和t都是这样子;就是说;
-
对反向我们是一样的;我们希望我们的梯度;就是说这个是损失函数;关于我们第t层的输出的那一个;第i个元素的梯度;我一样的希望它的方差为0;均值为0;方差为b;
-
这里a和b都是一个常数;所以你不管哪一个层;你不管每一个层的哪一个输出;我希望你们都是a和b的话;那么我的不管你做多多多深;我这样子都可以保证我的;数值都在一个合理范围里面;这是我们的一个假设;我们希望设计我们的神经网络;使得我们满足这个性质;我们接下来看我们要满足什么样的条件使得可以达到这一个要求;

3、权重初始化
-
====
-
第一个是说权重初始化;怎么样通过合理的权重初始化;就这个想法是说;需要在一个合理的值区间里面;随机初始我们的参数;这是为什么呢;是因为在训练开始的时候;更容易有数值不稳定;
-
举一个简单例子;这个是一个画的例子;就说显示一下会怎么样子;就可以看到;是说最优解在这个地方对吧;这是最小值;就假设我们是随机初始的话;很有可能你不会运气好;刚好在最优解的附近;那你有可能在很远的地方;一般来说;很离比较远的地方;很有可能你的表面是不那么平滑的;就可能在一个比较复杂的一个地方;就在这个地方;那么你可以看到这个地方就比较陡;一陡会出什么问题;一陡就是说越陡的地方;你的梯度就越大;讲过梯度就指向最陡的方向;
-
而且在这个地方的话;如果你初始在这个地方;那么有可能你算出来梯度特别大;导致你就不断的;你的w就可能会变得更加大;然后就出问题;同样的话;如果在最优解附近的话;附近的话一般来说你会比较平;那这个例子;我们这我们这里画的例子就是比较;
-
也希望找到这样子平的地方;所以比较平的问题是什么;平的地方你的梯度就比较小;就比较变成0;我们之前一直有说;我们用一个正态分布均值为0;方差为0.01来随机出示我们的权重;它有可能对一个小网络是没问题的;但它对于很深的网络它确实不能保证;就是说它有可能这个值可能太小;或者有有可能这个值太大;这个是;我们不能保证的;所以我们要来看一下说;我们假设要使得满足我们之前的假设;所有的输出和梯度的均值和方差;都在一个常数的话;那我们应该怎么办;我们还是回到之前的这一个例子;

4、例子MLP
-
MLP的这个例子
-
假设我们的权重;是一个独立的同分布;你的权重第t层的第i行第j列;就是独立同分布;就可以又说;我们的均值那就等于0;我们的方差就每一个元素的方差就等于个伽玛T;T是你的层数;
-
那么接下来是说我的这一层的输入;h i t减1;它也是独立于我当前的权重;我的当前层的权重;和我的当前层的输入;是一个独立的一个事件;
-
那么假设我们没有激活函数会怎么样;首先看一下;假设我们没有激活函数的话;那么的HT那就等于w t乘以h t减1;这里我们的WT是一个;当前层的输出的维度是NT;输入维度是NT减1;
-
那我们来看一下;我们做了这些假设之后;我们的计算是怎么样子的;
-
我们的HTi它的均值就等于;可以把它展开;就第二个;第二第二个元素;就等于是说我的第一行乘以我的输入;就是对于j;然后求和;就是w i j乘以h j对j进行求和;那我们知道;WT和HT减一是一个独立的;随随机变量;那么我们这个乘法我们就是;一可以写进去;首先均值对于加法是可以累加的;然后因为它是独立的;所以它我可以把它直接写开;那就是对于;他的均值就等于是他的;均值乘以他的均值;然后再求和;我们知道说;之前我们假设这两个均值都是0;所以我的输出都是0的;这个是没问题的;

5、正向方差
那么对于方差呢;继续来算一下方差;方差你可认为是;说大家知道;它的方差就等于它的平方项的均值;减去它的均值的平方;因为它的均值已经是0了;所以这一项是0;那么就只要考虑这一项;那么同样道理是说;这一项刚刚我们怎么展开的;就是展开的;就是WTIJ乘以ht减1J乘以开;然后当然这里有个平方项;带回一下;平方项是n个平方项;n个项求和;平方它可以写成每一个项的平方;加上交叉项;交叉项就是说对于所谓的j不等于k;然后每一个这个i j;kj k;但我们知道是说所有的这个均值;因为对它来讲它是一个0;为什么是因为;这些都是独立统分布;所有独立统分布;所以而且它的均值等于0;所以这一项就是我写一下;这一项就可以化掉了;它等于0;那就我们知道;就是说;期望对是可加的;所以期望可以写进去;那就是对于所有的j;它的每一个元素的平放的期望;和它的平放的期望值;因为我们知道;他们两个的均值等于0;所以他这个项就等价于;这个权重的方差;这一项;同样的话等于第t层输入的方差;而且我们要对j求和;那就是n减一;求和就n减一这样子的项;而且我们知道;这一项它的我的假设是;它的是等于大码t的;所以就是n n t减一乘以大码t;然后这个就是它的输入的一个期望;假设我们的目标;是说;输入的方差和输出的方差;是一样的情况下;那么可以推出;那么我的要求就是n t减一;乘以伽马t要等于一;这就是我们需要满足的;意味;这个项是不能改的;这个就是我的输入的维度;伽玛t就是我的;初始可以选择的一个方差;那就意味着说;这一项要满足等于1

6、反向均值和方差
看一下反向会怎么样;反向;其实是跟正向是差不多的一个事情;因为可以看一下;就反向;我们知道;这一项可以写成WT的这个地方;那么它的;转置就等于WT的转置乘以它;那么;很容易同样;我就不特别的去仔细给大家介绍;为什么会这样子;因为其实你写过来其实是一样的;就是说;你的梯度转之后;之后跟之前其实是正向的;情况是一样;都是乘一个w在里面;所以同样的话;我们可以推出它的;因为我们的前提条件满足了我的期望等于0;同样的话;我要使得方差相等的话;我会的我的要求就是NT;就是第t层的输出的那个数;乘以伽马t r等于一;就说因为我们的假设;导致了我们的均值都是等于0的;但是我们要方差都是一样的话;我们要满足两个条件;就是我们要满足这两个条件;

7、Xavier初始化
第一个条件;使得我的每次的前向的输出的方差是一致的;
第二个条件是使得我的梯度是一样的;那么这个两个条件很难同时满足;
为什么呢是因为;这个项NT减一和NT是我们不能控制的;NT减1是第t层的输入的维度;NT是输出的维度;除非你的输入刚好等于输出;那不然的话;你无法同时满足这两个条件;对吧;
那么怎么做呢;我们可以做一点权衡;就是有一个叫做XV的一个方法;那么他的想法是说我不能满足同时;那我就取个折中嘛;那我就说我满足;我选取我的伽玛t;记得;伽玛t就是第梯层的权重的那个方差;它满足于输入加纬度加上输出除以2;满足它等于1;那么就是说;意味着是说;给定我这个选用;当前层的输入和输出的大小;那我就能确定我的;我这个权重需要满足的方差的大小;那么它怎么用呢;它的用就是说;我对当前层;第t层它的权重的初始的时候;我要采用一个什么样的随机分布;就说我如果使用正态分布的话;那我的均值当然是等于0呢;但是我的方差;那就不再是前面我们的0.01了;还是一个根据我的输入和输出的维度;然后加起来;被2除一下;然后开根号的值;所以这个值是可以算出来的;同样的话;因为因为他的;你可知道正态分布;他的这个取的话;他的方差就会等于是这样子的一个;因为他是平方嘛;如果你取均匀分布的话;类似但是2就变成了6;它是取一个正的;正负对称的一个区域;使得均值为0;然后方差呢;就要保持在这个区间里面;这是一枚均匀分布的;如果你在负a到a之间;那么它的方差是a的平方除以3;就是这么过来的;所以就x Ver;也是我们常用的;一个权重初始化的一个方法;那么它的意思是说;我的权重;初始化的时候;那个方差;是根据我的输入和输出维度来定的;意味着说我就可以适配;这个尤其重要的是;当你的输入;一个层的输入和输出;长得不那么一样的时候;或者你这个;每个网络变化比较大的时候;他就可以说;我可以根据你那个输入输出;来适配我的权重的形状;使得我希望我的梯度和方差;输出的方差都在一个;恒定的范围里里面;所以通常来说;XVA也是我们非常常用的一个权重;权重初始化的方法;OK所以这个就是说;怎么样再满足我们的;再尽量满足我们的;比较合适的一个随机分布的情况下;我们应该怎么样做权重数字化;好那接下来我们再看一个是说;


8、假设线性的激活函数
对于激活函数会怎么样;我们刚刚假设我们的激活函数;就是一个没有激活函数;那么现在我们假设什么呢;假设我们有一个线性激活函数;大家知道线性激活函数是不会用的;因为线性激活函数是不会让你产生;非线性性;但是我们为了简单起讲我;们;假设我们的激活函数是一个线性函数;就为了理论分析方便;那就是说;假设基础函数是一个f x加上一个Beta;那么这个是一样的;那么同样的话;我们可以考虑之前;之前那么就是说;我的期望那面是一个线性变化嘛;所以它的;它就等于b;就说它我们知道这个已经它的输;它已经是输入;已经是均值为0了;我们刚刚的分析有;那么阿法乘以0=0;然后加上一个倍的;那就意味着说我要使得期望等于0;那我们这个激活函数;那一定是过圆点的a;它就一定要等于0;同样道理;假设我们分析它的方差的话;那就是平方减去它均值的平方;然后把它展开;把它展开;展开展开;展开之后这些项基本上都没了;那最后是说它等于阿法平方次差;就说激活函数的输入和输出的方差;它是有个阿法平方次;那么理解;就是说你激活函数;把那个东西放大阿法倍的话;那么你的方差会放大阿法平方倍;那如果我想;使得计物函数不改变我的输入;输出的方差的话;那么我唯一能做的就是;阿法平方要等于一;那就意味着是说;我的阿法必须要等于1;OK所以;这个的意思是说;我的为了;使得我的前项的输出的均值和方差;都是均值为0;方差为固定的话;那我的激活函数只能是Beta等于0;阿尔法等于;就是激活函数必须是等于本身;同样的话;反向反向其实是一样的;反向我们也不;

9、反向
仔细讲了;反向其实;基本上你可以得到一样的;结论大家可以去推一下;反向是怎么怎么样;跟前面是一样的;所以最后得到结论是说;如果你想梯度也一样的;均值为0;方差为固定数的话;那么;你的阿尔法和贝塔都必须要这样子选;那么则意味着什么;

10、检查常用激活函数
意味着是说你这个激活函数;它必须是f x等于x;那我们检查查一下我们的激活函数;检查一下我们的激活函数什么样呢;我们使用泰勒展开;我们知道泰勒展开的东西;希望大家还记得住;泰勒展开是说我用一个;理项式一项式;一直把它来逼近;做一个地阶近似;就可以看老师说sigmoid;它的问题是说它是等于1/2加上4分;x减去那个;然后time h的话还好一点;它就是它还是一个0加上x;然后减去那个;relue也OK;就是说如果是大于0的话;它也是个0加x;所以这意味着是什么意思;意味着是说对于;sygamoid来讲;先不说sigmoid吧;对于探h和real来讲;它在零点附近;它确实是近似到一个;f x等于x;就是一个;identity函数;就是说我别的地方先不管;至少是说在一个这个值的区间里面;那么它可以近似的看成是一个;就是一个;这个我不知道;其实我不;知道中文叫什么;应该叫我反正一般叫identity function;那就是当你外面我先管不了;但是在值附近是OK的;而且你神经网络通常来说;你的权重;那些值通常也是在0点附近的;一个比较小的数;所以至少这两个函数是问题不大的;就满足至少在0点附近;满足于我们之前的要求;但sigmoid有问题;sigmoid这里不满足;它不过原点对吧;所以你可以调整;怎么样调整它呢;你可以把sigmoid乘个4;然后减个2;那么就是说;这个是调整之后的sigmoid;就这根线是调整之后的;那么可以看到它也是过圆点;而且这个线就基本上等于是;f x等于x了;OK;那就意思其实大家可以去试一下;就是说;如果你对于sigmoid做了这个调整之后;其实你会发现;之前大家说sigmoid会有什么问题;其实你这个调整后的sigmo;也能基本上在;实际问题中;能解决掉你那些看到的问题;而且p h Relu为什么;效果不错;这也是大概;能够从数据稳定性来解释一下;为什么它在还可以;OK这也是一个;怎么选取激活函数;使得我们的数值尽量的稳定;你看总结一下


11、总结
-
====
-
可以合理的对权重;初始值和激活函数的选取;来提升我们的数值稳定性
-
具体来说;我们使得我们的每一层的输出;和我们每一层的梯度;它都是一个均值;为0;方差为一个固定数的一个随机位量;
-
在这个目标下;我们可以说;权重初始的话可以使用XV;然后激活函数的话;你选relu或者选T h都没有问题
-
如果你选sigmoi的话;你可以对它做一下;重新变化也会;解决掉sigmoi的以前带来的很多问题;

三、QA
-
第一个问题是说;可以讲一下;nan和Infinity是怎么产生的;以及怎么解决的吗
-
一般来说;Infinity大家好理解;就是说你就是太大了;通常来说;Infinity;通常是你学习率调的太大了造成的;或者你的权重初始的时候;你还没更新呢;你权重初始的时候那些值太大了;就导致你基本上就炸掉了;
-
nan是怎么出现的;nan一般就是除0;就把一个数除以一个0;那就是通常来就是说你;比如说你的梯度已经是很小了;然后你把梯度除了一个0;所以产生not number;
-
以及怎么解决解决的问题;其实怎么说呢;他要解决的话;一般来说;就通过我们今天介绍的一些技术有合理的初始化你的权重;然后你的激活函数你也不要选错;然后你的学习率也不要选太大;或一般来说你的学习率不要选太大;所以你如果碰到这个问题;你其实我建议最简单的做法是说;你把学习率调到比较小;一直往下调;直到你的infinity;或者nan不出现了;
-
第二个是说;你可以看一下你的权重的初始;不要选择那个;均值当然是等于0嘛;不要方差那个区间取的比较小一点;你一直往小走;走到你能够正确的出一些值;然后再慢慢的把它调大;使得它有训练有进展;
-
问题2∶使用ReLU激活函数是如何做到拟合x平方或者三次方这种曲线的?
-
其实我们不是用Relue来拟合一个东西;是Relu加上我们那些可以学的权重;来拟合平方或三次曲线;Relu唯一的干的事情;就是把线性给破坏掉了;大家可以去比如说B站上;重新看一下;我们在讲MLP的时候;多层感知机的时候讲过的;
-
问题3:老师,如果训练一开始,在验证集上准确率在提升,但是训着两个epoch之后,突然验证集上准确率就变成50%左右了之后稳定在50%,这是为什么呢?
-
一般是你的权重就坏掉了;就是说基本上50%就是权重;可能里面都是一些乱七八糟的词了;一般来说;你的就是数值稳定性出了问题;你怎么办呢;你可以尝试把学习率变小一点;但我觉得可能更本质的问题;如果你不能通过调学习率来解决;把学习率调小一点;不能通过解决问题的话;通常这个模型数值稳定性不行;很容易就跑歪了;就说我们之后会讲大量的模型;怎么样来使得更稳定;就是说大家说大家为什么用Resnet;为什么用为什么要这个;为什么要那个;其实绝大部分的;就是让你的训练更加稳定;就不会出现这个情况;
-
问题4∶老师,在训练的过程中,如果网络层的输出的中间层特征元素的值突然变成nan了,是发生了梯度爆炸了吗?还是有什么可能的原因?
-
对一般来说;lotter number就是因为梯度太大造成的;如果你去太小的话;就保证你根根本就称不动;就是发现就会平的;就没什么进展;所以一般;是一般是梯度的问题;
-
问题5:老师您好,我是初学者,当遇到一些复杂的数学公式,看文字描述也没有什么感觉,这个怎么突破一下呢?
-
这是个好问题;就是说;就深度学习的好处;就是说让你不要懂数学;也能够用很多东西;传统的机器学习像SVM也好;像别的也好;就是你需要有很多数学优化也好;有很多数学;深度学习说;你不用数学;你神经网络;反正可导就行了;可导我都可以给你求解;但是反过来讲;我觉得;虽然深度学习对数学要求低了;但是我觉得这东西你还是得学的;就是说你可以打个比方;你把人的数学能力和代码能力;代码能力就是说你深度学习你能调参会调;写代码很快;实现搞数据很快;做事情很快;就我们把这个称为代码能力的话;那么你的数学能力就是你的理解能力;
-
问题6∶老师,为什么对16位浮点影响严重? 32位或者64位就好了吗?那就是说所有通过fp16加速或者减小模型的方法都存在容易梯度爆炸或者消失的风险?
-
那就是说通过对是说你32位就会好一些;64位当然就更好了;所以传统的高性能计算;他们都是用64位的;就像Python;它的默认的数据类型是64位;32位是大家常用的;但是就说这是一个权衡
-
问题7︰梯度消失可以说是因为使用了sigmoid激活函数引起的对吗?所以我们可以用ReLU替换sigmoid解决梯度消失的问题?
-
sigmoid容易引起梯度消失;Relu确实对于这个东西解决比较好;但是;梯度消失不一定是指由sigmoid产生的;梯度消失可能有别的地方产生的;就是说sigmoid能引起但是它是一个;不是一个;充分必要的关系;tigmoid不仅仅是有sigmoid;可以让剃度消失的概率变低;但是我无法说;你一定是可以解决这个问题;
-
问题8:梯度爆炸式由什么激活函数引起的?
爆炸不会有激活函数;激活函数它的;相对来说它的梯度还行;就说激活函数它的梯度;因为它是一个平滑的;比较平滑的一个曲线;它梯度都不会有太大问题;梯度爆炸一般是就是因为你的;你的那些每一个层的输出的值太大;n个很大的值;内层会导致梯度爆炸;就LSTM里面;就是说LSTM通过指数和log和这种;这种操作单元;使得里面的;不不再是一个累成的一个东西了;my成我们之后会讲这个;这个东西;大家不一定要我就提到这个事情;我们之后肯定会讲;为什么会这样子;就是说为什么说乘法变加法;可以让训练更稳定;就我们之前有讲过;100个1.5乘在一起;梯度会炸;太大了但100个1.5加起来没问题;就150;就是说你那个100是等于你的乘的个数;假设你100乘的话;你全用乘法来算;题做的话很容易就出;要么就太大;要么就太小;假设你100乘;你的梯度是用加法来做的话;那你你不管你你的你;甚至你的你的输出都是1,0001万;你都没关系;1万乘以100也没没问题;对吧 100万;对于计算机来讲;100万不是问题;所以就是说;为什么说乘法变加法可以让;数学更加稳定;让每层的方差是一个常数;是;跟Bachelor没有太多关系;Bachelor sound what能够做一点东西;但是确实;我们之后会讲到;Bachelon到底是怎么回事;Bachelon可以让你的输出;它确实变成一个均值为0;方差为一个差不多;是有固定值的东西;但是它;我想想它不一定能保证你的梯度;所以Bachelon就是说;大家没有从这个角度来看过;Bachelor是干是不是干这个事情;我们之后讲到Bachelor时候;我们再回过头来看这个事情;就输出或者参数符合正态分布;有利学习;其实其实不是说;你需要是一个正态分布;从纯粹是说;我需要你的输出值;它在一个合理的区间里面;就说怎么你模拟怎么去;就怎么样去使得我的输出好去;用公式推理呢;就是我假设它是一个正态;我假设它是一个随机分布;随机分布比较容易算;均值和期望;所以我们就是说;假设你是个随机分布;但是你不一定是要正态;没关系就说只要你的;均值为0;方差为一个固定值就行了;就随便什么分布都行;大家之所以用正态分布;或者均匀分布的话;纯粹是因为;那个东西算起来比较容易;数学做比较容易;但实际上来说;你用什么都没关系;就随机初始化;XVA是一个不错的方案;不能说是最好;但是确实是很常用的方案;就说你;我不知道有最好或者最推荐的是什么;但我觉得大家如果没有更好的想法的;时候就用XVA就行了;梯度规划不是batch normalization;这个其实是不一样的东西;我们之后可以去再来讲这个事情;问题15是说;我们这个等高线;是不是可以可视化;哎这个东西也是个很好玩的问题;就是说对一个损失函数;可视化它那个面积是一个很难的问题;确实真的有research来做这个事情;大家如果感兴趣的话;可以就是早一点这个paper;但我确实没看到;特别特别好的方法;真的能把一个很复杂的一个函数;给你画出来;最简单情况下;我们就能画一个二维输入你;三维输入;你就就比较难画了;对吧你高维就没戏了;这是第一点;所以;这一块没有特别特别好的方法;但是确实有一些工研究工作;来可视化你这个损失函数的;一个一个等高线曲线;大家可以去搜一下;但是也还还比较原始;对就是说为;问题16是说;为什么我们要假设独立同分布;哎没没;就简单一点;就是为了简单起见;就是说如果你不是独立统分部;会怎么样;会不会相互影响;对不是独立同分布的话;一般来说还真的是;嗯;就是说它是条件;独立同分布;还真的可以这么假设;这个地方;虽然你就是说;内部协变量偏移;当然是说你其实之间有一定关系;但我觉得没必要在这个简单情况下;没必要做这个假设;反过来说一句就是bachelorminization;其实是说;就是有一个;他就是想说oh what;里面神经;网络里面有一个类;就是说类变的;有一个偶像性;我想把你解偶;就是Bachelor要干的事情;为什么假设每一层的权重是一个俯冲;一个独立统分布呢;因为这个是我们初始化;就我们其实说白了;刚刚说的;就是说;我在权重一开始的时候应该怎么做;就假设;我是觉得我这个是手动初始化出来的;结果就是说;刚刚那个分析;只能分析到在权重一开始的时候;怎么样;中间当然是不能;不能说是一个;独立统分布了;正态分布的假设有什么缺陷;为什么看上去是万能的;也不是万能的吧;正态分布做推导比较容易点;就这么点事情还写大数定理嘛;对吧大数定理;最后一切的一切都变成一个正态分布;就是说有另外问题20是说;有用一些很复杂的算法来进行;初始化权重或预值;其实我不知道;我不知道这个是什么样东西;就你可以研究嘛;这一块有很多工作;就我们就不这一展开了;就是说问题21是说;强制使得每一层的输出均值为0;方差为一;是不是损失了网络的表达能力;改变了数据的特征;降低了科学系的准确率;而这也没也没有;要其实也没有;就是说数值;就是说是一个区间;你把他拉到什么地方都没关系;就是说理解吗;就是说我的一个神经网络;我想让就是说;我只是让那个数值;在一个合理的区间里面表达;使数嘛;反正你你压小一点压大一点都没关系;这个区间是;使得我这个硬件处理起来比较容易;就是合适硬件的区间;从数学上来讲;我不管用什么区间;我做任何变化;都不会影响我的算;我的模型的课表达性;问题22为什么它可以;这个变化可以提高稳定性;它和就它其实没有它;其实是说做完这个变化之后;在零点附近;它近似于它的曲线;近似于呃;f x等于x这个函数;我们来另外一个;是要具体讲解下XV的初始化;针对于;这个是个好问题;这个这个是说你;其实我我理解你是想说;我们要实现一下这个函数吧;我今天肯定没有空来实现;我可以考虑一下;哪一天我们来回过头来讲一下我们;这个怎么实现;就反过来讲;如果我们就算不实现;你可以去看一下实;框架的实验;其实挺简单;就这么几句话;24激活函数有什么选择;那激活函数你叫redo吧;就是简单;一般权重是在每个epoch之后更新的嘛;权重是每一次迭代;每一个batch要更新;每个iterate要更新;epoch是说每次扫完数据;那个是已经更新过很多次了;我用的是Resnat;为什么还是会出;还是会出现数值稳定性问题;当然会出现了;就是说所有的这些技术是来缓解它;从来不是解决;就是resonator;你把能力read调到很大;一样的会出问题;因为我们有很多很多的方法;来缓解数字文的性能问题;你可认为整个深度学习这个进展都;;都是在让;数值更加稳定;你可以从这个很简单的;观点来考虑;所以;Resnet没有解决数值稳定性的问题;只是说;它确实比别的稳定性要好一点点;就是27是说;数值稳定性可能是模型结构引起的;如果觉得孪盛网络;孪盛网络什么;是那个two tower那个嘛;就两个嘛;两路输入不一样;会不会引起数值稳定性;会的就是说这也是个很好问题;我们没讲;就是说你有两类不一样的数据;然后呢你一类;比如说文本加图片嘛;文本进一个升级网络;图片进另外一个升级网络;最后我们要把它合起来;这里这里面最容易的;你是说你的文本和图片;你的数值区间不一样;你怎么做对吧;可能文本的输出很大数;图片输出很小;这时候你有很多种办法;bashlong是我们可以做的事情;但是确实这一块;通常来做的方法是通过于;两个两头通过一个权重;就说这一个的权重加一个权重;就说文本乘一个权重;加上图片;可能图片就不用权重;没关系然后调这个权重;使得这两块比较一样;我们可能会在呃style transformation;就是那个样式迁移里面会大概会讲到;这一块就是它里面也是有两步输入;强输入的话;一般是通过一个权重来使得每两类;两路的那个数值都在差不多的范围里;里面;问题28是说;我们主要做的是算法移植这种工程化;怎么样在模型设计和模型精度方面;有所突破呢;模型设计和模型精度;嗯;就我觉得模型的精;设计这是一个很大的问题;我觉得我在这里肯定是解决不了;讲不了太多事情;然后嗯我们来;嗯;我们今后会来;讲就是说不同的;这个这个很大的问题;我们只能说今后再碰到实际的;我们再讲;Resnat呀讲Transformer;讲RN也好;就说我们尽量去解释;他背后的设设计思路会怎么样;就尽量去解释;但是说;希望给大家会带来一些想法;但是说你问我说要要要怎么设计;这个太大了;我觉得这里回答不了;就是说;问题29;把每一层的输入的均值方差作限制;是不是可以理解成;限制各层输入值;出现极大或极小的异常值;他其实你也可以这么认为;就是说我把均值和方差做限值;可以理解成;如果你的方差;确实在一个很小的区间里面;那么出现几大值的概率就会变低;但是还是会有;但是会贬低;通常这些一两额外出现的极大致;不会影响太多;确实可以这么认为;;