shell与shell script 学习总结
文章目录
- shell与shell script 学习总结
- vi
- vim
-
- 可视化区块
- 多文件编辑
- 多窗口功能
- vim环境设置与记录
- 中文编码问题
- 语系编码转换
- Shell的变量功能
-
- 变量的使用与设置
-
- echo(变量的使用)
- 变量设置的规则
- 环境变量的功能
-
- env(观察环境变量)
- set(观察所有变量)
- unset(取消变量)
- locale(语系变量)
- read、declare、数组(变量键盘读取、数组与声明)
-
- read
- declare
- 数组变量类型
- ulimit(与文件系统及程序的限制关系)
- 变量内容的删除、取代与替换
-
- 变量内容的删除与替换
- 变量的测试与内容替换
- 命令别名、历史命令以及命令补全
-
- history(命令历史记录)
- ~/.bash_history(历史命令记录文件)
- TAB(命令与文件补全)
- alias、unalias(命令别名设置功能)
- /etc/issue、/etc/motd(bash的登录与欢迎信息)
-
- /etc/issue
- /etc/motd
- bash的环境配置文件
-
- source(读入环境配置文件的命令)
- stty、set(终端的环境设置)
- 通配符与特殊符号
- 数据流重定向
-
- 使用案例
- ;、&&、||(命令执行的判断根据)
-
- 使用案例
- 管道命令
-
- cut(选取内容)
- grep(搜索内容)
- sort(排序命令)
- uniq(显示重复的数据)
- wc(查看文件内容多少字)
- tee(双向重定向)
- split(划分命令)
- Linux运维三剑客(grep、sed、awk)
- shell脚本
shell与shell script 学习总结
vi
vi共分为3种模式,分别是命令模式、输入模式与底线命令模式
使用【vi filename】进入命令模式
vi csq.txt
下面是比较常用的参数:
i:进入插入模式,允许输入文字ESC:退出插入模式0或[home]键:移动到这一行的最前面$或[end]键:移动到这一行的最后面:wq:保存文件并退出vi:q!:强制退出vidd:删除当前行yy:复制当前行p:粘贴复制的内容/word:在文件内容里查找word字符串shift+g:移动到这个文件的最后一行gg:移动到这个文件的第一行
vim
vim是vi的升级版(vi能用的参数vim一样用),提供了更多功能和更好的性能。
可视化区块
-
ctrl +v:可视化区块,可以用矩形的方式选择数据 -
v:字符选择,会将光标经过的地方泛白选择 -
y:将泛白的地方复制起来 -
d:将泛白的地方删除掉 -
p:将刚刚复制的区块,在光标所在处粘贴
下图就是使用ctrl + v可视化区块,矩形的方式展现

多文件编辑
:n:编辑下一个文件:N:编辑上一个文件:files:列出目前这个vim开启的所有文件
通过【vim csq csqcsq.txt 】来打开两个文件

多窗口功能
- :sp[filename]:打开一个新窗口,如果有加filename,表示在新窗口创建一个新文件,否则表示两个窗口为同一个文件内容(同步显示)
- ctrl + w + ↓:光标可移动到下方窗口
- ctrl + w + ↑:光标可移动到上方窗口
使用【vim csq】然后再划分窗口,打开csqcsq.txt文件

vim关键词补全功能
【ctrl + x】 => 【ctrl + n】 通过目前正在编辑的这个【文件的内容文字】作为关键字,给予补齐
【ctrl + x】=> 【ctrl + f】 以当前目录内的文件名作为关键词,给予补齐
【ctrl + x】=> 【ctrl + o】 以扩展名为语法补充,以vim内置的关键词,给予补齐
vim环境设置与记录
常用的vim环境设置参数:
set nu:显示行号set hlsearch:高亮搜索结果set autoindent:自动缩进
~/.vimrc是Vim的配置文件,其中包含了用户自定义的Vim设置,例如键映射、颜色方案、插件设置等等。每当Vim启动时,它会读取这个文件来初始化用户的配置。
[root@localhost ~]# vim .vimrc
set nu
set autoindent
set hlsearch
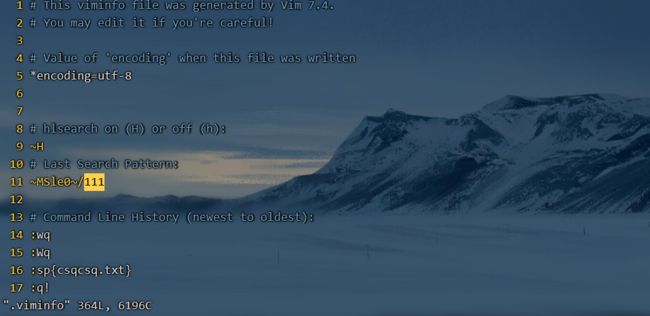
~/.viminfo是Vim的历史记录文件,其中保存了用户在Vim中使用的命令、搜索、缓冲区等等信息。当用户下次启动Vim时,它会读取这个文件来恢复上次的会话,使得用户可以继续上次的编辑工作。用户也可以通过设置来控制Vim保存哪些信息到这个文件中。
[root@localhost ~]# vim .viminfo
中文编码问题
遇到无法正常显示中文可能是编码问题可以使用
LANG=zh_CN.UTF-8
export LC_ALL=zh_CN.UTF-8
语系编码转换
将/root/csq 从BIG-5编码转换为UTF-8编码
iconv -f BIG-5 -t UTF-8 csq
# -f:就是来源的意思,后面接原本的编码格式
# -t:就是后来的新编码是什么格式
最后使用file命令查看是否修改成功
file
Shell的变量功能
变量的使用与设置
echo(变量的使用)
打印出${PATH}的变量
[root@csq ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
设置PATH的变量
[root@csq ~]# PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:~/shelldir
[root@csq ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/shelldir
变量设置的规则
- 变量名必须以字母或下划线开头,不能以数字开头。
- 变量名只能包含字母、数字和下划线。
- 变量名区分大小写。
- 变量赋值时,等号两侧不能有空格,例如:
name="John" # √ 正确
name = "John" # × 错误
- 如果变量值中包含空格或特殊字符,需要使用引号将变量值括起来。单引号和双引号的作用略有不同:
- 单引号:单引号中的文本会被原样输出,变量不会被解析。例如:
[root@csq ~]# name='csqcsq'
[root@csq ~]# echo ${name}
csqcsq
- 双引号:双引号中的变量会被解析,可以在变量中插入其他文本。例如:
[root@csq ~]# name="chenshiren"
[root@csq ~]# echo "My name is ${name}"
My name is chenshiren
- 变量可以被重新赋值,例如:
[root@csq ~]# name="csq"
[root@csq ~]# echo ${name}
csq
[root@csq ~]# name="zhw"
[root@csq ~]# echo ${name}
zhw
- $()括号中的命令会被执行,并将输出结果返回给变量。
- $()也可以嵌套使用,例如:
[root@csq ~]# name=$(echo "csq")
[root@csq ~]# echo ${name}
csq
- 可以将$()和其他变量组合使用,例如:
[root@csq ~]# dir=$(pwd)
[root@csq ~]# echo ${dir}
/root
# 输出为当前目录的路径
- $(( ))是算数扩展语法,它用于进行数学运算
[root@csq ~]# sum=$((5 * 5 ))
[root@csq ~]# echo ${sum}
25
- 如果你变量中想输入空格可以利用转义字符
[root@csq ~]# name=csq\ zhw
[root@csq ~]# echo ${name}
csq zhw
环境变量的功能
环境变量是一种全局变量,用于存储系统信息或用户配置信息
env(观察环境变量)
列出目前shell环境下所有环境变量与其内容
[root@csq ~]# env
HISTSIZE=1000
USER=root
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/shelldir
LANG=zh_CN.UTF-8
HOME=/root
# 删除了一部分仅列出了常用的环境变量
-
USER:指定当前的用户名
-
HOME:指定当前用户的主目录
-
PATH:指定系统在执行命令的时候需要搜索的路径
-
LANG:指定系统的语言设置
-
HISTSIZE:指内存中记录的历史命令最大条数
-
RANDOM:这个环境变量在/dev/random。我们可以通过${RANDOM}来使用他,系统会随机取出一个介于0~32767的数值。
-
如果我想要取出0~9的数值
[root@csq ~]# suijinu=$((${RANDOM}*10/32768)) [root@csq ~]# echo ${suijinu} 3
-
set(观察所有变量)
set 和env不同的是可以观察环境变量和自定义变量
[root@localhost ~]# set
BASH=/bin/bash # bash的主程序路径
BASH_VERSINFO=([0]="4" [1]="2" [2]="46" [3]="2" [4]="release" [5]="x86_64-redhat-linux-gnu")
BASH_VERSION='4.2.46(2)-release' # 这两行是bash的版本
COLUMNS=109 # 在目前的终端环境下,使用的栏位有几个字符长度
HISTFILE=/root/.bash_history # 历史命令记录的放置文件,隐藏文件
HISTFILESIZE=1000 # 历史命令文件最大记录数1000(存在上面这个变量文件里)
HISTSIZE=1000 # 内存中记录历史命令条数最大1000条
IFS=$' \t\n' # 默认的分隔符号
LINES=24 # 目前终端下的最大行数
MACHTYPE=x86_64-redhat-linux-gnu # 安装的机器类型
OSTYPE=linux-gnu # 操作系统类型
PS1='[\u@\h \W]\$ ' # 命令提示符
PS2='> ' # 如果你使用转义字符(\),这是第二行以后的提示字符
$ # 目前中shell所使用的PID
?
PS1:Shell提示符的格式
PS1常见的参数详解
- \u:目前用户的名称
- @:显示时间,12小时格式的【am:pm】样式
- \t:显示时间,24小时哥哥是的【HH:MM:SS】
- \h:仅取主机名在第一个小数点之前的名字。
- \W:获取正在工作目录的名称
- \KaTeX parse error: Expected 'EOF', got '#' at position 13: :如果是root,就提示#̲,否则是。
简单的设置一下Shell提示符格式
[root@localhost ~]# PS1='[\u \@ \h \W] \$ '
![]()
$(关于本shell的PID)
美元符本身就是个变量,代表的是目前这个shell的进程号
[root 05:37 下午 localhost ~] # echo $$
1963
?(关于上个执行命令的返回值)
例如你执行命令发生错误
[root 05:39 下午 localhost ~] # sl
-bash: sl: 未找到命令
[root 05:39 下午 localhost ~] # echo $?
127
export(自定义变量转成环境变量)
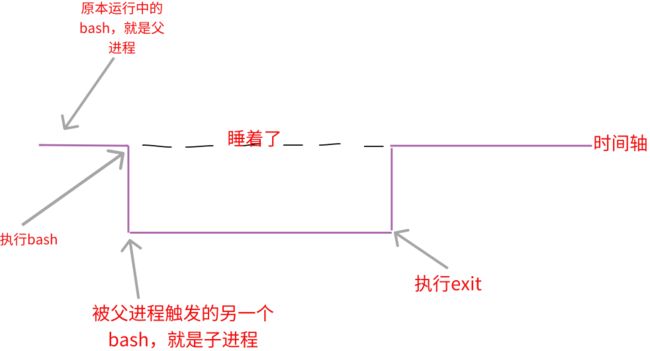
export主要作用就是将自定义变量转换成环境变量。子进程会继承父进程的环境变量,子进程不会继承父进程的自定义变量。我们设置的自定义变量进入子进程后会消失不见,一直到你离开子进程并回到父进程变量才会出现
[root@localhost ~]# name=csq
[root@localhost ~]# bash
[root@localhost ~]# echo ${name}
[root@localhost ~]# exit
exit
[root@localhost ~]# echo ${name}
csq
当我们使用export后将name转换为环境变量就可以在子进程中使用了
[root@localhost ~]# export name
[root@localhost ~]# bash
[root@localhost ~]# echo ${name}
csq
unset(取消变量)
[root@csq ~]# unset name
[root@csq ~]# echo ${name}
# 没有变量就什么也不会输出
locale(语系变量)
Linux支持多少语系呢?
[root@localhost ~ 14:45:43]# locale -a
......
...
zh_CN
zh_CN.gb18030 # gbk 中文编码
zh_CN.gb2312
zh_CN.gbk
zh_CN.utf8 # 简体中文编码
....
....
如何自定义编码?
# 通常来说只用设置 LANG 和 LC_ALL 这两个变量。
[root@localhost ~]# locale
LANG=zh_CN.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=
也可以通过修改系统的默认语系文件,可以自定义语系
[root@localhost ~]# cat /etc/locale.conf
LANG="zh_CN.UTF-8"
read、declare、数组(变量键盘读取、数组与声明)
read
要读取来自键盘输入的变量,就是用read这个命令。
read -pt 变量
选项:
-p:后面接提示字符
-t:后面可以接等待的秒数
使用案例
询问用户是否喜欢Linux
[root@localhost ~]# read -p "我喜欢学习Linux,你呢?" stdin
我喜欢学习Linux,你呢?i like
[root@localhost ~]# echo ${stdin}
i like
询问用户是否喜欢Linux如果3秒钟不回答就退出
[root@localhost ~]# read -p "我喜欢学习Linux,你呢?" -t 3 stdin
我喜欢学习Linux,你呢?[root@localhost ~]#
# 超时了
declare
declare就是命令声明变量的类型的。
declare [-aixr] 变量
选项:
-a:将后面名为 xxx的变量定义为数组类型
-i:将后面名为 xxx的变量定义为整数类型
-x:将后面的xxx变量变成环境变量
-r:将变量设置为只读类型,不能被更改也不能被unset
-p:单独列出变量的类型
使用案例
让变量sum进行300+200+100求和
[root@localhost ~]# declare -i sum=300+200+100
[root@localhost ~]# echo ${sum}
600
将sum变成环境变量
[root@localhost ~]# declare -x sum
[root@localhost ~]# bash
[root@localhost ~]# echo ${sum}
600
将sum变成非环境变量
[root@localhost ~]# declare +x sum
[root@localhost ~]# bash
[root@localhost ~]# echo ${sum}
列出sum的类型
[root@localhost ~]# declare -p sum
declare -i sum="600"
# 仅有-i的参数
数组变量类型
数组的设置方式
var[1]=csq
意思就是数组名为var,第一个数组内容为 csq,可以自行设置第二个第三个…(重点要用中括号来设置)
ulimit(与文件系统及程序的限制关系)
ulimit是Linux系统中用于设置和显示用户进程资源限制的命令。它可以用于限制用户进程使用系统资源的数量,例如CPU时间、内存、打开文件数等。
ulimit [-af] 配额
使用案例
列出你目前身份【假设为一般账号】的所有限制数值
[root@localhost ~]# su - zzh
[zzh@localhost ~]$ ulimit -a
core file size (blocks, -c) 0 # 只要是0就是代表没限制
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited # 可建立单一的文件大小
pending signals (-i) 31116
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited # 同时可开启的文件数量
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
限制使用者仅能建立10MB以下的容量文件
[root@localhost ~]# ulimit -f 10240
[zzh@localhost ~]$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) 10240
pending signals (-i) 31116
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[zzh@localhost ~]$ dd if=/dev/zero of=csq bs=1M count=20
文件大小超出限制
变量内容的删除、取代与替换
变量内容的删除与替换
| 变量设置方式 | 说明 |
|---|---|
| ①KaTeX parse error: Expected '}', got '#' at position 4: {变量#̲关键词} ②{变量##关键词} |
①若变量内容从头开始的数据符合【关键词】,则将符合的最短数据删除 ②若变量内容从头开始的数据符合【关键词】,则将符合最长数据删除 |
| ①KaTeX parse error: Expected '}', got 'EOF' at end of input: {变量%关键词} ②{变量%%关键词} |
①若变量内容从尾向前的数据符合【关键词】,则将符合的最短数据删除 ②若变量内容从尾向前的数据符合【关键词】,则将符合的最长数据删除 |
| ① 变量 / 旧字符串 / 新字符串 < b r / > ② {变量/旧字符串/新字符串} ② 变量/旧字符串/新字符串<br/>②{变量//旧字符串/新字符串} |
①若变量内容符合【旧字符串】则【第一个旧字符串会被新字符串替换】 ②若变量内容符合【旧字符串】则【全部的旧字符串会被新字符串替换】 |
使用案例
- #和##
让小写的path自定义变量设置的与PATH内容相同
[root@localhost ~]# path=${PATH}
[root@localhost ~]# echo ${path}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
假设我不喜欢local/bin,所以要将前一个目录删除掉怎么做?
[root@localhost ~]# echo ${path#/*local/bin:}
/usr/sbin:/usr/bin:/root/bin
删除前面所有的目录,仅保留最后一个目录
[root@localhost ~]# echo ${path##/*:}
/root/bin
- %和%%
我想要删除最后面的那个目录,就是从:到bin为止的字符
[root@localhost ~]# echo ${path%:*bin}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
那如果我只想要保留第一个目录?
[root@localhost ~]# echo ${path%%:*bin}
/usr/local/sbin
- /和//
将path的变量内容内的sbin替换成大写的SBIN
[root@localhost ~]# echo ${path/sbin/SBIN}
/usr/local/SBIN:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
将path变量中的所有sbin变成大写
[root@localhost ~]# echo ${path//sbin/SBIN}
/usr/local/SBIN:/usr/local/bin:/usr/SBIN:/usr/bin:/root/bin
变量的测试与内容替换
变量内容的替换可以使用一些特殊符号来进行。
-符号的作用是在变量不存在或为空时使用默认值。
:-符号的作用是在变量不存在或为空时使用默认值,并将其赋值给变量。
=符号将右侧的值赋给左侧的变量。如果变量已经存在,则将其值替换为右侧的值。
?符号用于错误处理。如果变量不存在或为空,则输出错误信息,并退出当前脚本。
测试(-)用法
假设abc不存在(用unset),然后测试一下减号(-)用法
[root@localhost ~]# unset abc; def=${abc-xixixi}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=xixixi,abc=
若abc已经存在,测试一下def会怎么样
[root@localhost ~]# abc=csq; def=${abc-xixixi}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=csq,abc=csq
假设abc为空字符,测试一下def会怎么样
[root@localhost ~]# abc=""; def=${abc-xixixi}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=,abc=
测试:-的用法
-和:- 的区别就是:-能设置空字符,-不能
假设abc为空字符,测试一下def会怎么样
[root@localhost ~]# abc=""; def=${abc:-xixixi}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=xixixi,abc=
测试=的用法
如果你想要将旧变量内容也一起替换掉,就使用【=】
假设abc不存在,然后测试一下【=】的用法
[root@localhost ~]# unset abc; def=${abc=xixixi}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=xixixi,abc=xixixi
如果abc存在,然后再测试一下def会怎么样
[root@localhost ~]# abc=csq; def=${abc=xixixi}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=csq,abc=csq
测试?的用法
如果我只想知道,如果旧变量不存在,整个测试旧告知我【有错误】,此时就用到【?】的帮忙。
若abc不存在时,则def测试结果直接显示"无此变量"
[root@localhost ~]# unset abc; def=${abc?无此变量}
-bash: abc: 无此变量
若abc存在时,则def会与str相同
[root@localhost ~]# abc=csq; def=${abc?无此变量}
[root@localhost ~]# echo "def=${def},abc=${abc}"
def=csq,abc=csq
命令别名、历史命令以及命令补全
history(命令历史记录)
语法
history [n]
history [-c]
history [-r]
n:数字,列出最近n条命令
-c:将目前shell中所有history内容全部清除
-r:将historyfiles 的内容督导目前中国shell的history记录中
使用案例
使用history命令查看历史记录。
history
- 使用【!】来执行历史记录中的命令
!67
# 执行第67行的命令
- 使用【!!】来执行上一条命令
!!
- 使用【!】加上关键字来执行包含该关键字的命令。
!f
# 在历史命令当中执行以f开头的命令
- 使用【Ctrl + R】来搜索历史记录。
(reverse-i-search)`':
# 输入关键字后,系统会搜索包含该关键字的历史记录,
# 并显示搜索结果,用户可以选择需要执行的命令。
~/.bash_history(历史命令记录文件)
这个文件在你的家目录,记录的是前一次登录以前所执行过的命令,而至于这一次登录所执行的命令都被存在内存中,当你注销系统,命令才会记录到【.bash_history】中,至于你【.bash_history】中能存多少数据就和你bash的【HISTFILESIZE】这个变量有关了。
TAB(命令与文件补全)
-
【TAB】接在第一串命令的第一个字后面,则为命令补全
-
【TAB】接在第一串命令的第二个字后面,则为【文件补齐】
-
如果按照【bash-completion】软件,则某些命令后面使用【TAB】按键时,可以进行【选项/参数的补齐】功能
alias、unalias(命令别名设置功能)
命令别名是一种将一个命令或一系列命令绑定到一个自定义名称的方法。这可以帮助用户更快速地输入一些常用的命令,从而提高工作效率。
- 缩短常用命令
例如,将"ls -alh"绑定到"ll"上,每次输入"ll"就相当于输入"ls -alh"。命令别名的设置方法为:
alias ll='ls -alh'
- 避免误操作
例如,将"rm"命令绑定到"rm -i"上,每次执行"rm"命令时都会提示用户是否确认删除。命令别名的设置方法为:
alias rm='rm -i'
- 取消命令别名rm
[root@csq ~]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
[root@csq ~]# unalias rm
[root@csq ~]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
# 可以看到rm命令别名已经没了
/etc/issue、/etc/motd(bash的登录与欢迎信息)
/etc/issue
/etc/issue文件是在用户登录时显示的信息,通常包括Linux发行版名称、版本号和系统架构等。该文件可以用于自定义登录信息,例如添加公司logo、联系方式等。
查看issue文件中的内容
[root@localhost ~]# cat /etc/issue
\S
Kernel \r on an \m
下面就是系统默认的登录信息

| issue内的各代码意义 |
|---|
| \d 本地端时间的日期 \l 显示第几个终端 \m 显示硬件等级 \n 显示主机的网络名称 \O 显示domain name \r 操作系统的版本 \t 显示本地端时间 \S 显示操作系统的名称 \v 显示操作系统的版本 |
我们来设置一下
[root@localhost ~]# vim /etc/issue
Name of operating system: \S
Logged in terminals: \l
Network name of host: \n
operating system version: \v
Time: \t
显示如下

还有个/etc/issue.net,是提供给telnet这个远程登录程序用的。当我们使用telnet连接到主机,主机的登录画面会显示【/etc/issue.net】而不是【/etc/issue】
/etc/motd
/etc/motd文件是在用户登录后显示的信息,通常用于向用户传达一些系统公告或提示信息。该文件可以用于向用户提供有用的信息,例如系统更新、安全漏洞等。
查看文件内容
[root@localhost ~]# vim /etc/motd
欢迎使用Centos 7操作系统
当前用户为root用户
# 上面内容是我自己写入进去的并非默认内容
也可以放入一些比较有意思的ascii画
[root@csq ~]# cat /etc/motd
i ,
_,,)\.~,,._
(()` ``)\))),,_
| \ ''((\)))),,_ ____
|6` | ''((\())) "-.____.-" `-.-,
| .'\ ''))))' \)))
| | `. '' ((((
\, _) \/ |))))
`' | (((((
\ | ))))))
`| | ,\ /((((((
| / `-.______.< \ | )))))
| | / `. \ \ ((((
| / \ | `.\ | (((
\ | | | )| | ))
| | | | / | | '
| | /_( /_(/ /
/_(/__] \_/_(
/__] /__]
bash的环境配置文件
Bash shell的环境配置文件包括以下几个:
-
/etc/profile:这是系统级别的Bash配置文件,在系统启动时会自动加载。该文件通常包含一些全局的环境变量、系统级别的命令别名等。它会在用户登录时被执行。
-
/.bash_profile:这是用户级别的Bash配置文件,仅适用于当前用户登录时要执行的命令和环境变量设置。该文件通常包含一些个人的环境变量、个人级别的命令别名等。如果该文件不存在,Bash会尝试加载/.bash_login或~/.profile文件。该文件会在用户登录时被执行。
-
~/.bashrc:这是用户级别的Bash配置文件,用于设置个人的命令别名、环境变量等。该文件会在每次新开一个终端时加载,并且可以通过source命令重新加载。该文件通常包含一些个人的命令别名、环境变量等。
-
/etc/bashrc:这是系统级别的Bash配置文件,用于设置全局的命令别名、环境变量等。该文件会在每次新开一个终端时加载,并且可以通过source命令重新加载。该文件通常包含一些全局的命令别名、环境变量等。
需要注意的是,在修改这些配置文件时,应该小心谨慎,以免影响系统的正常运行。如果您不确定如何修改,请先备份原始文件,然后进行修改。
source(读入环境配置文件的命令)
source 配置文件文件名
使用案例
假如我在【.bashrc】中修改了一些命令别名,我想让他立即生效怎么办
[root@csq ~]# cat .bashrc
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
[root@csq ~]# source ~/.bashrc
# 或者
[root@csq ~]# . ~/.bashrc
stty、set(终端的环境设置)
stty命令
stty命令用于设置和显示终端的各种属性。它可以设置终端的行为、字符集、键盘映射等。
stty [-a]
选项:
-a:将目前所有的stty参数列出来
使用案例:
列出所有的按键与按键内容
[root@csq ~]# stty -a
speed 38400 baud; rows 17; columns 132; line = 0;
intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>; eol2 = <undef>; swtch = <undef>; start = ^Q; stop = ^S;
susp = ^Z; rprnt = ^R; werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0;
...
.....
上述部分关键词意义是:
- intr:终止正在运行的程序。^C 就是Ctrl + C
- quit:退出正在运行的程序
- erase:向后删除字符
- kill:删除目前命令行上的所有文字
- eof:代表【结束输入】
- start:代表程序停止后,重新启动他
- stop:停止屏幕输出
- susp:软件挂起,后台运行
如果我们想改一下intr 不使用默认^C了,可以这样修改
[root@csq ~]# stty intr ^K
[root@csq ~]# stty -a | grep intr
intr = ^K; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>;
set命令
set命令不仅能够查看自定义变量和环境变量,还可以帮我们设置整个命令输出/输入的环境。例如记录历史命令,显示错误呢内容。
语法
set [-uvCHhmBx]
选项:
-u:默认不启用,若启用后,当使用未设置变量时,会显示是错误信息
-v:默认不启用,若启用后,在信息被输出前,会先显示信息的原始内容
-x:默认不启用,若启用后,在命令被执行前,会显示命令内容(前面有++符号)
-h:默认启用,与历史命令有关。
-H:默认启用,与历史命令有关。
-m:默认启用,与任务管理有关。
-B:默认启用,与中括号[]的作用有关。
-C:默认不启用,若使用>等,则若文件存在时,该文件不会被覆盖。
使用案例
显示所有环境变量和自定义变量的值
set
设置若未定义变量时,则显示错误信息
[root@csq ~]# set -u
[root@csq ~]# echo ${adwdadw}
-bash: adwdadw: unbound variable
通配符与特殊符号
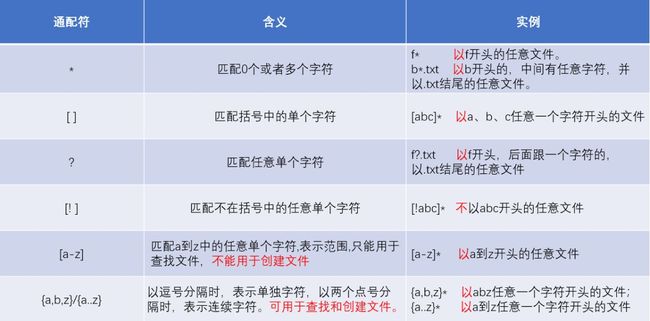
常用的通配符
常用的特殊符号
| 符号 | 内容 |
|---|---|
| # | 注释符号 常常在脚本中使用,视为说明,#号后面的数据均不执行 |
| \ | 转义符 将【特殊字符或通配符】还原成一般的字符 |
| | | 管道:分隔两个管道命令的符号 |
| ; | 连续命令执行分隔符:连续性命令的界定(注意,与管道符并不相同) |
| ~ | 用户的家目录 |
| $ | 使用变量前导符:就是变量之前需要加的变量替换值 |
| & | 任务管理:将命令变成后台任务 |
| ! | 逻辑运算意义上的【非】not的意思 |
| / | 目录符号:路径分隔的符号 |
| >、>> | 数据流重定向:输出重定向,分别是【替换】与【累加】 |
| <、<< | 数据流重定向:输入定向 |
| ’ ’ | 单引号,不具有变量替换的功能($ 变为纯文本) |
| " " | 具有变量替换的功能,($ 可保留相关功能) |
| ` ` | 两个 【`】中间为可以先执行的命令,也可以使用$( ) |
| ( ) | 在中间为子 shell的起始于结束 |
| { } | 在中间为命令区块的组合 |
数据流重定向
- 标准输入(STDIN):代码为0,使用<或<<
- 标准输出(STDOUT):代码为1,使用>或>>
- 标准错误输出(STDEER):代码为2,使用2>或2>>
- 1>:以覆盖的方法将【正确的数据】输出到指定文件或设备上
- 1>>:以累加的方法将【正确的数据】输出到指定文件或设备上
- 2>:以覆盖的方法将【错误的数据】输出到指定的文件或设备上
- 2>>:以累加的方法将【错误的数据】输出到指定的文件或设备上
使用案例
测试文件内容
[root@localhost ~]# cat csq
I am csq
[root@localhost ~]# cat zhw
I am zhw
将csq文本中的内容输出到 zhw文件中
[root@localhost ~]# cat csq > zhw
[root@localhost ~]# cat zhw
I am csq
将csq文本中的内容累加到zhw文件中
[root@localhost ~]# cat csq >> zhw
[root@localhost ~]# cat zhw
I am zhw
I am csq
将zhw文本中的内容输入到csq文件里
[root@localhost ~]# cat > csq < zhw
[root@localhost ~]# cat csq
I am zhw
将csq中的内容添加上到此一游
[root@localhost ~]# cat >> csq << "eof"
> 到此一游
> eof
[root@localhost ~]# cat csq
I am csq
到此一游
输入sl错误命令将错误的信息输入到 error.txt文件中
[root@localhost ~]# sl 2> error.txt
[root@localhost ~]# cat error.txt
-bash: sl: 未找到命令
输入sl错误命令将错误的信息累加输入到 error.txt文件中
[root@localhost ~]# sl 2>> error.txt
[root@localhost ~]# cat error.txt
-bash: sl: 未找到命令
-bash: sl: 未找到命令
将正确的信息和错误的信息都输入到黑洞文件中去
[root@localhost ~]# sl >/dev/null 2>&1
;、&&、||(命令执行的判断根据)
-
分号(;):表示顺序执行,即先执行前面的命令,然后再执行后面的命令,不管前面的命令执行成功还是失败。
例如,
command1 ; command2表示先执行command1,然后再执行command2。 -
双竖线(||):表示逻辑或,即如果前面的命令执行失败,则执行后面的命令;如果前面的命令执行成功,则不执行后面的命令。
例如,
command1 || command2表示如果command1执行失败,则执行command2,否则不执行command2。 -
双与号(&&):表示逻辑与,即如果前面的命令执行成功,则执行后面的命令;如果前面的命令执行失败,则不执行后面的命令。
例如,
command1 && command2表示如果command1执行成功,则执行command2,否则不执行command2。
使用案例
以ls 测试/tmp/csq 是否存在,若存在则显示 “yes” 不存在则显示 “no”
[root@localhost ~]# ls /tmp/csq && echo "yes" || echo "no"
ls: cannot access /tmp/csq: No such file or directory
no
管道命令
cut(选取内容)
cut -d '分隔字符' -f 字段
cut -c 字符区间
选项:
-d:后面接分隔字符,与-f一起使用
-f:根据-d分隔字符将一段信息划分成为数段,用-f取出第几段的意思
-c:以字符的单位取出固定字符的区间
使用案例:
将PATH变量取出,我要找出第五个路径
[root@localhost ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
1 2 3 4 5
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 5
/root/bin
# 如同上面数字显示,我们是以【:】作为分隔,因此会出现/root/bin
grep(搜索内容)
grep [-acinv] [--color=auto] '查找字符' filename
选项:
-a:将二进制以文本文件的方式查找数据
-c:计算找到'查找字符'的次数
-i:忽略大小写的不同,所以大小写视为相同
-n:顺便输出行号
-v:反向选择,就是显示出没有'查找字符'内容的那一行
--color=auto:可以将找到的关键字的那一行加上颜色显示
使用案例:
在last的输出信息中,只要有root就取出,并且仅取第一栏
[root@localhost ~]# last |grep 'root'|cut -d ' ' -f 1
root
root
root
root
root
.......
....
# 在last输出信息中,利用cut命令的处理,就能够仅取第一栏
sort(排序命令)
sort [-fbMnrtuk] [file 或 stdin]
选项:
-f:忽略大小写的差异,例如A与a视为编码相同
-b:忽略最前面的空格字符部分
-M:以月份的名字来排序,例如JAN、DEC等排序方法
-n:使用【纯数字】进行排序(默认是以文字形式来排序的)
-r:反向排序
-u:就是uniq,相同的数据中,仅出现一行代表。
-t:分隔符号,默认是使用[TAB]键来分隔
-k:以哪个区间来进行排序的意思。
使用案例:
/etc/passwd内容是以【:】分隔的,我想以第三栏来排序
[root@localhost ~]# cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
csq:x:1000:1000::/home/csq:/bin/bash
zhw:x:1001:1001::/home/zhw:/bin/bash
zzh:x:1002:1002::/home/zzh:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
....
......
..
# 发现了吗sort默认是以文字形式来排序的,如果想要数字排序
# cat /etc/passwd | sort -t ':' -k 3 -n 这样才行 加上-n来告知sort是以数字来排序
uniq(显示重复的数据)
uniq [-ic]
选项:
-i:忽略大小写字符的不同
-c:进行计数
使用案例:
使用last将账号列出,列出每个账户的登录次数
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq -c
1
7 reboot
34 root
1 wtmp
# 1.先将所有的数据列出来 2.再将人名独立出来 3.经过排序 4.只显示一个
# 从上述案例得知可以发现reboot出现了7次,root登录则有34次,大部分都是root在登录
# wtmp与第一行的空白都是last的默认字符,两个可以忽略
wc(查看文件内容多少字)
wc [-lwm]
选项:
-l:仅列出行
-w:仅列出多少字
-m:多少字符
使用案例:
man_db.conf里面到底有多少行、字数、字符数呢?
[root@localhost ~]# cat /etc/man_db.conf | wc
131 723 5171
# 输出的三个数字中,分别代表:【行、字数、字符数】
tee(双向重定向)
tee [-a] file
选项:
-a:以累加的方式,将数据加入file当中
使用案例:
将ls -l /home 的数据存一份到~/homefile,同时屏幕也有输出信息
[root@localhost ~]# ls -l /home | tee ~/homefile
total 0
drwx------. 2 csq csq 162 Apr 25 14:48 csq
drwx------. 2 zhw zhw 62 Apr 25 09:52 zhw
drwx------. 2 zzh zzh 62 Apr 25 09:52 zzh
# 如果信息很多的话在后面可以加一个【 | less】
split(划分命令)
split [-bl] file PREFIX
选项:
-b:后面可接欲划分成的文件大小,可加单位,例如b、k、m等
-l:以行数来进行划分
PREFIX:代表前缀字符的意思,可作为划分文件的前缀文字
使用案例:
我的/etc/services 有600多K,若想要分成300K一个文件时
[root@localhost ~]# cd /tmp/;split -b 300K /etc/services services
[root@localhost tmp]# ll -k services*
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesaa
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesab
-rw-r--r--. 1 root root 55893 Apr 26 16:10 servicesac
# 这个文件名可随意取,我们只要写上前缀文字,小文件就会以xxxaaa,xxxab,xxxac等方式来建立小文件
Linux运维三剑客(grep、sed、awk)
Linux运维三剑客参考笔记
shell脚本
Shell 脚本是一种编程语言,其语法和其他编程语言类似,包含以下几个基本部分:
- 注释:
在 Shell 脚本中,注释以 # 开头,可以用于对代码进行说明或者临时禁用某些代码。
如何编写第一个shell脚本 ⇐ 参考笔记 - 变量:
Shell 脚本中的变量和其他编程语言类似,使用 $ 符号来引用变量。变量名必须以字母或下划线开头,不能以数字开头,变量名中不能包含空格和特殊字符。 - 条件语句:
Shell 脚本中的条件语句包括 if、else、elif,用于根据不同的条件执行不同的代码块。
shell脚本的条件判断式 ⇐ 参考笔记 - 循环语句:
Shell 脚本中的循环语句包括 for、while、until,用于重复执行某个代码块,直到满足某个条件为止。
shell脚本的循环 ⇐ 参考笔记 - 输入输出:
Shell 脚本中的输入输出包括 echo、read等命令,用于输出文本和读取用户输入。 - 命令执行:
Shell 脚本中的命令执行包括使用反引号或 $() 符号来执行命令,并将命令的输出作为变量或参数传递给其他命令。 - 管道:
Shell 脚本中的管道符号 | 可以将一个命令的输出作为另一个命令的输入,用于将多个命令组合在一起执行。