HBase最佳实践-多租户机制简析
本篇文章转自两篇博客,因为hbase中资源的划分有三种方式,两位老师的文章都只写了其中部分。
背景介绍
在HBase1.1.0发布之前,HBase同一集群上的用户、表都是平等的,没有优劣之分。这种’大同’社会看起来完美,实际上有很多问题。最棘手的主要有这么两个,其一是某些业务较其他业务重要,需要在资源有限的情况下优先保证核心重要业务的正常运行,其二是有些业务在某些场景下会时常’抽风’,QPS常常居高不下,严重消耗系统资源,导致其他业务无法正常运转。
这实际上是典型的多租户问题,社区针对这个问题提出了相应的应对措施,主要有如下三点:
(1)资源限制,主要针对用户、namespace以及表的QPS和请求大小进行限制,详见HBase-11598
(2)资源调度,主要针对任务进行优先级调度,通常会优先调度实时交互而且小的任务,而批量操作任务或者长时间操作任务(大scan)优先级相对较低,详见HBase-10993
(3)资源隔离,将不同表通过物理隔离的方式分布到不同的RegionServer上,详见HBase-6721
本文将会重点介绍HBase中的资源限制方案 – Quotas,主要对其使用方式、实现原理进行介绍,并对其实际效果通过实践进行验证。另外,本文还会对HBase的资源调度原理进行简单介绍,并对主要配置进行讲解。
资源限制-Quotas
Quotas使用条件
(1)HBase版本在1.1.0以上,或者低版本HBase应用了对应的Patch(HBase-11598)
(2)Quotas功能默认是关闭的,需要在配置文件hbase-site.xml中通过设置hbase.quota.enabled为true打开。设置完成之后,需要重启HMaster才能生效。
Quotas语句详解
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => READ, USER => 'u1', TABLE => 't2', LIMIT => '10req/sec'(1)Quotas分别支持表级别以及用户级别资源限制,或者同时支持表级别和用户级别,如示例所示
(2)THROTTLE_TYPE可以取值READ / WRITE,分别对随机读和随机写进行限制
(3)LIMIT 可以从两个维度对资源进行限制,分别为req/time 和 size/time,前者限制单位时间内的请求数,后者限制单位时间内的请求数据量。需要指明的是time的单位可以是sec | min | hour | day,size的单位可以是B(bytes) | K | M | G | T | P,因此LIMIT可以表示为’1000req/min’或者’100G/day’,分别表示’限制1分钟的请求数在1000次以内’,’限制每天的数据量为100G’
常用Quotas语句
hbase> set_quota TYPE => THROTTLE, TABLE => 't1', LIMIT => '1000req/sec'
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => WRITE, USER => 'u1', LIMIT => '10M/sec'注意事项
(1)set_quota命令执行的限制都是针对单个RegionServer来说的,并不是针对整个集群
(2)set_quota命令默认执行后并不会立刻生效,需要等待一段时间才会生效,等待时间默认为5min。可以通过参数 hbase.quota.refresh.period 进行设置,比如可以通过设置
hbase.quota.refresh.period = 60000将生效时间缩短为1min
(3)可以通过命令list_quotas查看当前所有执行的set_quota命令
Quotas – 实现原理
原理很简单,如果请求数超过设置的Quota数,就抛出异常!有同学会说也没在日志中看到任何异常嘛,这是因为这类异常日志级别是debug,而默认的日志输出级别为info,可以通过调整log4j来查看。但是这类异常实在太多,没有必要输出。
Quotas – 实践效果
了解了Quotas的使用方法以及基本原理,是不是很想试一试它的功效,笔者在测试环境做了如下的测试:
1. 测试硬件情况
| 集群规模 | RS JVM内存配置 |
硬盘 |
HBase版本 | YCSB版本 |
| 4台RegionServer |
72G | 12 * 3.6T |
1.1.2 |
0.8.0 |
2. 测试环境新建两张表,分别称为A和B。两张表的数据构成都相同,10亿条数据,每条数据500Bytes,总大小500G左右。
3. 分别使用两个YCSB客户端分别对这两张表执行读写混合操作(读写比为1:1),再然后对B表不断执行set_quota操作,对该表QPS进行限制。再分别观察A表和B表的QPS以及读延迟变化情况。
4. 为了方便理解,下面测试结果中A表称为Unthrottle_Table,B表称为Throttle_Table。测试结果如下:
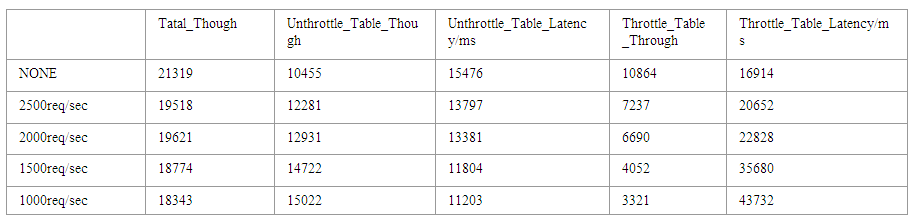
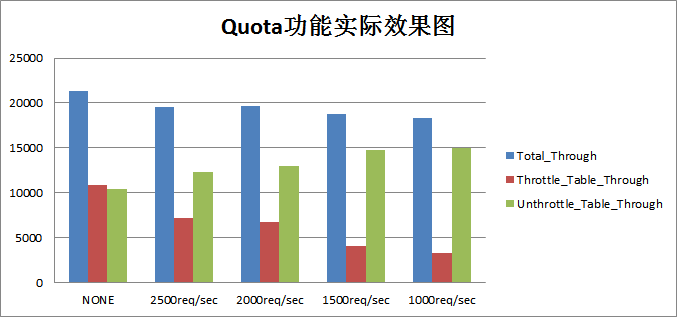
通过测试基本可以看出,随着B表执行的QPS限制越来越严格,上图中Throttle_Table表对应的吞吐量(红色柱状图)越来越小,相应Unthrottle_Table表(紫色柱状图)对应的吞吐量却越来越大,这是因为B表执行QPS限制之后各种硬件资源就会更多地分配给A表。
总体来说,Quotas功能总体看来基本完成了资源限制的职能,达到了资源限制的目的。同时支持用户级别和表级别,另外同时支持请求大小和请求数量两个维度,基本涵盖了常见的资源限制维度;另外,易用性也是一大亮点,比较人性化,只需要在Shell界面上敲一行命令就可以搞定。
资源调度
在 0.99版本之前,HBase只提供了一种请求队列类型:FIFO队列,意为先到的请求会优先被处理,后到的请求需要等待之前的请求被处理完。这样的设计有一个致命的缺陷,就是在线交互式查询有可能会被离线大scan长时间阻塞,而从优先级的角度讲在线交互式查询无疑更加重要。
0.99版本之后,HBase将默认请求队列由FIFO类型改为了Deadline类型,用来解决上述缺陷。提起DeadLine队列,很多对Linux IO调度算法比较了解的同学并不陌生,Linux IO常用调度算法主要有Noop、CFQ(Completely Fair Queuing)以及Deadline,其中Noop调度算法基本可以认为就是FIFO算法,因此同样存在上述弊端;而CFQ算法会按照IO请求的地址进行排序,这样处理的目的在于尽量少地减少磁盘移动,实际效果来看确实极大的提升了IO的吞吐率,但是相比Noop,部分IO请求有可能会一直排到队尾,存在饿死的情况。Deadline算法首先将读写IO队列进行了分离,而且读IO优先级要高于写IO优先级;除此之外,它还会为每一个IO请求设置一个时间戳,用以判断请求是否长时间没有得到处理,进而需要优先处理。需要知道的是,对于常见数据库环境来说(Oracle,MySQL等),Deadline算法总是最佳选择。
那HBase新增的Deadline算法和Linux IO中Deadline算法是否一样呢?答案是肯定的,至少两者实现思路基本是一致的。接下来主要结合HBase请求调度源码对Deadline算法进行深入分析。
Deadline算法基于Deadline类型队列实现,Deadline类型队列和FIFO类型队列不同,属于优先级队列,里面的元素会按照优先级进行排序,优先级高的排在队首,优先级低的排在队尾。很显然,Deadline算法目标是使得在线交互式查询请求优先级更高,而离线长scan请求优先级更低。除此之外还有一个通常不会被注意的目标:不能出现任何请求被饿死!在弄懂具体的实现机制前,需要首先搞清楚一个问题:如何量化一个scan的请求长短?
如何量化一个scan的请求长短:这个问题的理解需要对scan的流程有一个大体认识,一次scan请求并不会将所有数据查询返回,这一方面是因为在数据量大的场景下诸如带宽之类的系统资源会被严重消耗,另一方面也有可能会因为数据量大导致客户端OOM。因此HBase实际上将一次scan请求分为多次连续的next小请求执行,每次查询纪录数用户可以配置,默认为100条。这样假如一次scan查询总纪录数为1000,每次查询返回100条,就需要10次客户端到服务器端的next请求。看到这里,很多童鞋已经明白,可以通过当前RPC请求次数(即next RPC调用次数)粗略地衡量scan的长短,比如当前scanA的RPC请求次数为10,scanB的RPC请求次数为5,就可以认为scanA长于scanB,那理论上scanA的这次请求优先级就会低于scanB的这次请求。
HBase在具体实现中会为每一个请求设置一个deadline(时间期限),代表这个请求的处理期限,deadline越小,请求优先级越高。

这个deadline参数是理解HBase资源调度的关键,它由两部分构成:后半部分的核心在于vtime,代表当前scan的next请求次数,可见vtime越大(scan越长),对应的deadline越大,优先级越低;因为设定get操作的vtime为0,因此同等条件下get操作优先级最高;可见,通过vtime就可以实现请求优先级功能。那对于长scan,会不会出现因为优先级太低长时间得不到处理饿死的情况呢?这就需要看看前半部分,timestamp表示请求点的绝对时间戳,设置绝对时间戳是为了保证该请求的deadline肯定早于5s(等式后面部分最大就是5s)之后所有请求的deadline,从而能够保证不会被饿死;
好吧,上面不是说Linux IO调度系统中Deadline算法还实现了读IO和写IO的分离,那HBase实现了么?当然,用户只需要通过简单的配置就不仅可以实现读请求和写请求的分离,还可以实现了scan请求的分离。
默认场景下,HBase只提供一个队列,所有请求都会进入该队列进行优先级排序。用户可以通过设置参数hbase.ipc.server.callqueue.handler.factor来设置多个队列,队列个数等于该参数 * handlercount,比如该参数设置为0.1,总的handlercount胃150,则会产生15个独立队列。
独立队列产生之后,可以通过参数 hbase.ipc.server.callqueue.read.ratio 来设置读写队列比例,比如设置0.6,则表示会有9个队列用于接收读请求,6个用于接收写请求;另外,可以通过参数 hbase.ipc.server.callqueue.scan.ratio 设置get和scan的队列比例,比如设置为0.1,表示1个队列用于scan请求,另外8个用于get请求;
总结
本文主要介绍了HBase中多租户实现中的两个重要手段:资源限制以及资源调度,对其工作原理以及使用方法进行了解析。后续再针对资源隔离这个重头戏进行深入解析~(原文链接 http://hbasefly.com/2016/09/26/hbase-mutiltenant-1/)
第三种资源隔离方式见下文
背景
随着 Apache HBase 在各个领域的广泛应用,在 HBase 运维或应用的过程中我们可能会遇到这样的问题:
- 同一个 HBase 集群使用的用户越来越多,不同用户之间的读写或者不同表的 compaction、region splits 操作可能对其他用户或表产生了影响。将所有业务的表都存放在一个集群的好处是可以很好的利用整个集群的资源,只需要一套运维系统。
- 如果一个业务或者一个部门使用一个 HBase 集群,这样会导致 HBase 集群的数量越来越多,直接导致了运维成本的增加。而且集群的分离也会导致资源的浪费,有些集群资源过剩,有些集群资源不足,这种情况我们无法充分利用不同集群的资源。将集群按照业务或部门分开的好处是可以很好的隔离不同表、不同用户之间的影响。
上面两种情况均存在不足,如果我们能够多租户共用一套集群,而且能够使不同用户之间进行隔离,在上层用户看来好像是独享一套 HBase 集群。为了解决这个问题,来自雅虎的 Francis Liu 提出了多租户隔离技术:RegionServer Group,详情请参见 HBASE-6721。这个技术的目标就是只需维护一个 HBase 集群,同时满足各个表在性能上、操作上的互不干扰,又支持访问安全隔离。
RegionServer Group
RegionServer Group 技术是通过对 RegionServer 进行分组,不同的 RegionServer 分到不同的组。每个组可以按需挂载不同的表,并且当组内的表发生异常后,Region 不会迁移到其他的组。这样,每个组就相当于一个逻辑上的子集群,通过这种方式达到资源隔离的效果,降低管理成本,不必为每个高 SLA 的业务线单独搭集群。

从上图可以看出,RegionServer 1 和 RegionServer 2 同属于 iteblog Group 1,而且管理 Table 1 和 Table 3 两张表;RegionServer 3 和 RegionServer 4 同属于 iteblog Group 2,而且管理 Table 2 和 Table 4 两张表。从用户角度上看,RegionServer 1 和 RegionServer 2 看起来是属于一个集群;而 RegionServer 3 和 RegionServer 4 同属于一个集群,这两个组之间均不互相影响。但是对于集群运维人员来说,这就是一个 HBase 集群,我们只需要运维这一个 HBase 集群即可,大大降低了运维成本。
技术简要介绍
在引入 RegionServer Group 技术之前,HBase 默认使用 StochasticLoadBalancer 策略(通过 hbase.master.loadbalancer.class 参数实现,参见HBASE-9555)将表的 Region 移动到 RegionServer 里面去。这种策略被没有考虑到 RegionServer Group 的信息,所以如果要对 RegionServer 分组,我们就需要在移动 Region 的时候考虑到这些信息。
基于这些信息,社区开发出能够识别出 RegionServer Group 信息的 RSGroupBasedLoadBalancer,这个类和上面的 StochasticLoadBalancer都是实现了 LoadBalancer 接口的,详见 HBASE-6721。
在默认情况下,所有的表和 RegionServer 都属于 default 组。RSGroupBasedLoadBalancer 类具有识别组信息的能力,所以在移动表的 Region 到 RegionServer 的时候会考虑到 RegionServer Group 信息的。为了启用这个特性,我们需要在 master 节点的 hbase-site.xml 文件加入以下的配置:
hbase.coprocessor.master.classes
org.apache.hadoop.hbase.rsgroup.RSGroupAdminEndpoint
hbase.master.loadbalancer.class
org.apache.hadoop.hbase.rsgroup.RSGroupBasedLoadBalancer
设置完之后需要重启 master 节点。
RegionServer Group 技术新引入的命令
RegionServer Group 技术为我们带来了以下13个新的 HBase shell 命令。使用下面的命令一定需要在 master 节点上的 hbase-site.xml 文件配置好上面两个属性。否则将会出现 UnknownProtocolException: No registered Master Coprocessor Endpoint found for RSGroupAdminService 异常。如下所示:
hbase(main):002:0> list_rsgroups
NAME SERVER / TABLE
ERROR: org.apache.hadoop.hbase.exceptions.UnknownProtocolException: No registered Master Coprocessor Endpoint found for RSGroupAdminService. Has it been enabled?
at org.apache.hadoop.hbase.master.MasterRpcServices.execMasterService(MasterRpcServices.java:802)
at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
List all RegionServer groups. Optional regular expression parameter can
be used to filter the output.
Example:
hbase> list_rsgroups
hbase> list_rsgroups 'abc.*'
Took 1.1077 secondslist_rsgroups:列出所有的 RegionServer groups,我们可以在这个命令的后面使用正则表达式来过滤一些我们要的信息。
hbase> list_rsgroups
hbase> list_rsgroups 'iteblog.*'get_rsgroup:获取某个 RegionServer group 的信息。
hbase> get_rsgroup 'default'add_rsgroup:创建一个新的 RegionServer Group。
hbase> add_rsgroup 'iteblog_group'remove_rsgroup:删除某个 RegionServer Group。
hbase> remove_rsgroup 'iteblog_group'balance_rsgroup:对某个 RegionServer Group 进行 balance 操作。
hbase> balance_rsgroup 'iteblog_group'move_servers_rsgroup:将 RegionServers 从一个组移动到另一个组。 RegionServer 中的所有 Region 都将移动到另一个 RegionServer 中。
hbase> move_servers_rsgroup 'dest',['server1:port','server2:port']move_tables_rsgroup:将表从一个 RegionServer Group 移动另一个 RegionServer Group。
hbase> move_tables_rsgroup 'dest',['table1','table2']move_namespaces_rsgroup:将指定命名空间的表从一个 RegionServer Group 移动另一个 RegionServer Group。
hbase> move_namespaces_rsgroup 'dest',['ns1','ns2']move_servers_tables_rsgroup:将 RegionServers 和 Tables 从一个 RegionServer Group 移动另一个 RegionServer Group。
hbase> move_servers_tables_rsgroup 'dest',['server1:port','server2:port'],['table1','table2']move_servers_namespaces_rsgroup:将指定命名空间的 RegionServers 和 Tables 从一个 RegionServer Group 移动另一个 RegionServer Group。
hbase> move_servers_namespaces_rsgroup 'dest',['server1:port','server2:port'],['ns1','ns2']get_server_rsgroup:获取给定 RegionServer 所属的 RegionServer Group。
hbase> get_server_rsgroup 'server1:port1'get_table_rsgroup:获取给定表所属的 RegionServer Group。
hbase> get_table_rsgroup 'iteblog_Table'remove_servers_rsgroup:从 RegionServer Group 中删除已停用的 Region。 处于 Dead/recovering/live 状态的 Region 将无法操作。
hbase> remove_servers_rsgroup ['server1:port','server2:port']如何使用 RegionServer Group
我们前面说了,如果没有创建 RegionServer Group 的话,HBase 默认的组只有 default,而且所有的表和 RegionServer 都属于 default 组,如下:
hbase(main):001:0> list_rsgroups
NAME SERVER / TABLE
default server 192.168.1.103:16020
server 192.168.1.103:16021
table hbase:meta
table hbase:namespace
table hbase:rsgroup
2 row(s)
Took 1.4986 seconds现在我们使用 add_rsgroup 命令创建了一个名为 iteblog_group 的组:
hbase(main):020:0> add_rsgroup 'iteblog_group'
Took 0.0444 seconds
hbase(main):021:0> list_rsgroups
NAME SERVER / TABLE
iteblog_group
default server 192.168.1.103:16020
server 192.168.1.103:16021
table hbase:meta
table hbase:namespace
table hbase:rsgroup
2 row(s)
Took 0.0101 seconds下面命令我们将 192.168.1.103:16021 RegionServer 移到了名为 iteblog_group 组里面:
hbase(main):022:0> move_servers_rsgroup 'iteblog_group', ['192.168.1.103:16021']
Took 1.0220 seconds
hbase(main):023:0> list_rsgroups
NAME SERVER / TABLE
iteblog_group server 192.168.1.103:16021
default server 192.168.1.103:16020
table hbase:meta
table hbase:namespace
table hbase:rsgroup
2 row(s)
Took 0.0102 seconds我们已经看到了地址为 192.168.1.103:16021 的 RegionServer 已经移到名为 iteblog_group 的组了。现在我们来创建一张表 iteblog_table,并且把这张表移到名为 iteblog_group 的组里面。为了演示 RegionServer Group 的作用,这里我现在创建一张名为 iteblog_table 的表,并且设置了预分区,如下:
hbase(main):011:0> create 'iteblog_table', 'cf', SPLITS=>['10','20','30','40']
Created table iteblog_table
Took 1.3884 seconds
=> Hbase::Table - iteblog_table
hbase(main):013:0> get_table_rsgroup 'iteblog_table'
default
1 row(s)
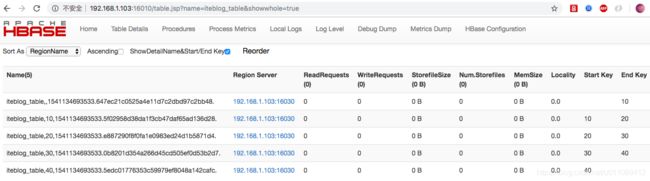
Took 0.0281 seconds从上面的输出可以看到,创建表的时候,默认是属于 default 组,虽然我们有两个 RegionServer,而且设置了预分区,按正常情况, iteblog_table 的 Region 应该是会分布在这两个 RegionServer 上的。但实际上因为这两个 RegionServer 的组不一样,而且 iteblog_table 的组属于 default,所有 iteblog_table 的 Region 全部位于 192.168.1.103:16020 上。正如下图所示:
现在我们将表 iteblog_table 移到名为 iteblog_group 的组里面,那属于 iteblog_table 的 Region 也应该全部移到 iteblog_group 里面的:
hbase(main):007:0> move_tables_rsgroup 'iteblog_group', ['iteblog_table']
Took 5.6177 seconds
hbase(main):008:0> get_table_rsgroup 'iteblog_table'
iteblog_group
1 row(s)
Took 0.0202 seconds我们已经看到 iteblog_table 所属的组为 iteblog_group,从下图也可以看到,iteblog_table 的所有 Region 全部移到了 192.168.1.103:16021 上。

我们还可以为命名空间设置 RegionServer 组,这样属于这个命名空间的表都属于这个 RegionServer 组:
hbase(main):012:0> create_namespace 'iteblog_namespace', {'hbase.rsgroup.name'=>'iteblog_group'}
Took 0.3406 seconds
hbase(main):013:0> create 'iteblog_namespace:mytable', 'f'
Created table iteblog_namespace:mytable
Took 0.8126 seconds
=> Hbase::Table - iteblog_namespace:mytable
hbase(main):014:0> get_table_rsgroup 'iteblog_namespace:mytable'
iteblog_group
1 row(s)
Took 0.0080 seconds好了,到这里我们已经了解了 HBase RegionServer Group 技术,已经如何使用了。剩下的命令我就不再介绍,感兴趣的同学可以自己再去学习。
上文转载自过往记忆(https://www.iteblog.com/,原文链接https://www.iteblog.com/archives/2435.html)
没办法,英文不好,即使在issues上看了hbase的原特征说明,也看的不是太懂,所以把两篇博客转过来,后面如果忘记了以供参考